不足:1. 傳統跨模態transformer只能處理2種模態,所以現有方法需要分階段融合3模態,引發信息丟失。2. 直接拼接多模態特征到BERT中,缺乏動態互補機制,無法有效整合非文本模態信息
改進方法:1. 基于張量的跨模態transformer模塊,允許同時處理3個模態的交互,打破了2模態限制。2. 將TCF模塊插入BERT的Transformer層,逐步融合多模態信息,即在Bert微調時動態補充非文本模態信息,避免簡單拼接導致的語義干擾
abstract
(背景與問題)由于單模態情感識別在復雜的現實應用中的局限性,多模態情感分析(MSA)得到了極大的關注。傳統方法通常集中于使用Transformer進行融合。然而,這些傳統的方法往往達不到,因為Transformer只能同時處理兩種模態,導致信息交換不足和情感數據的潛在丟失。(方法提出)針對傳統跨模態Transformer模型一次只能處理兩種模態的局限性,提出了一種基于張量的融合BERT模型(TF-BERT)。TF-BERT的核心是基于張量的跨模態融合(TCF)模塊,該模塊無縫集成到預訓練的BERT語言模型中。通過將TCF模塊嵌入到BERT的Transformer的多個層中,我們逐步實現了不同模態之間的動態互補。此外,我們設計了基于張量的跨模態Transformer(TCT)模塊,該模塊引入了一種基于張量的Transformer機制,能夠同時處理三種不同的模態。這允許目標模態和其他兩個源模態之間進行全面的信息交換,從而加強目標模態的表示。TCT克服了現有Crossmodal Transformer結構只能處理兩個模態之間關系的局限性。(實驗結果)此外,為了驗證TF-BERT的有效性,我們在CMU-MOSI和CMU-MOSEI數據集上進行了廣泛的實驗。TF-BERT不僅在大多數指標上取得了最佳結果,而且還通過消融研究證明了其兩個模塊的有效性。研究結果表明,TFBERT有效地解決了以前的模型的局限性,逐步整合,并同時捕捉復雜的情感互動在所有形式。
intro
(研究背景,強調單一模態的不足,引出多模態情感分析的必要性)隨著AI技術的進步和應用場景的拓展,單一模態的情感分析已不足以滿足情感識別復雜多樣的需求(Das & Singh,2023; Gandhi et al.,2023年)的報告。例如,僅僅依靠文本分析可能無法準確地捕捉說話者的情緒,因為語調和面部表情也起著至關重要的作用。這種情況催生了多模態情感分析(MSA)的出現,其目的是通過整合多個數據源,實現更準確、更全面的情感識別,如圖1所示。例如,在智能客戶服務系統中,結合文本、語音和面部表情可以更準確地評估用戶的情緒。如果系統檢測到用戶語氣中的不滿意,它可以迅速調整其響應策略以提供更快或更詳細的幫助。
(現有方法的缺陷)Zadeh等人(2017)的早期工作引入了一種基于張量的融合方法,計算3重笛卡爾空間以捕獲模態之間的關系。近年來,隨著深度學習的快速發展,研究者們不斷創新融合策略,以更好地平衡不同模態之間的情感信息。Wang等人(2019)使用門控機制將音頻和視頻(非文本)模態轉換為與文本模態相關的偏見,然后將其與文本融合。Mai等人(2021年)設計了聲學和視覺LSTM來增強文本表征。Tsai等人(2019)將Transformer(Vaswani,2017)引入MSA領域,設計了用于融合不同模態的跨模態變壓器。此后,交叉模態變換器得到了廣泛的應用,Zhang等人(2022)利用它們來模擬人類感知系統,Huang等人(2023)利用它們來圍繞文本進行融合。然而,盡管它們是有效的,但是這些跨模態變換器有一個局限性:它們的自注意結構一次只能接受兩個模態作為輸入,一個作為查詢,另一個作為關鍵字和值,考慮到每次迭代只有兩個模態之間的交互(Lv等人,2021年)的報告。由于多模態任務通常涉及兩個以上的模態,所以當處理多模態時,這種結構限制要求交互被分階段或分步驟地建模。這種限制可能導致信息丟失或不完整的交互,無法充分利用所有模態之間的潛在關系,從而影響情緒預測(Sun、Chen和Lin,2022)。此外,雖然Rahman等人(2020)、Zhao、Chen、Chen等人(2022)使用了預訓練的來自變換器的雙向編碼器表示(BERT)模型(Devlin等人,2018),他們的方法只是將非文本模態與文本模態一起集成到BERT的Transformer層中,導致整個模型中多模態情感信息的集成不足。
(解決方案)針對傳統的多模態Transformer無法同時處理多模態信息以及BERT中單層嵌入導致的多模態信息融合不足的問題,提出了一種基于張量的融合BERT(TFBERT)。該模型的核心組件是基于張量的跨模態融合(TCF)模塊,該模塊可以集成到預先訓練的BERT語言模型的Transformer架構中。這允許用非文本模態表示來逐漸補充文本模態表示。具體地說,我們的框架能夠在保持BERT核心結構的同時進行微調,從某個點開始將TCF嵌入每個Transformer層。TCF模塊中的基于張量的跨模態Transformer(TCT)允許BERT在學習文本表示的同時嵌入非文本情感信息,逐步增強文本模態表示以充分整合多模態情感信息。TCT引入了一種基于張量的方法,在跨模態Transformer融合之前,在目標模態和兩個其他源模態之間建立交互。TCT允許所有模態同時交換相關信息,補充和增強目標模態的情感信息。
最后,在CMU-MOSI和CMU-MOSEI兩個數據集上測試了TF-BERT模型的性能,并通過情感預測任務對TF-BERT模型的性能進行了評估.仿真實驗結果表明,TF-BERT算法優于已有的多度量方法.此外,消融研究進一步確認了TF-BERT中相應模塊的有效性。
(1)提出了TF-BERT并設計了TCT模塊,克服了傳統的跨模態變換器一次只能處理兩種模態的局限性。TCT模塊使跨模態Transformer能夠同時處理多個模態,促進目標模態與其他模態之間的全面信息交換。這種增強顯著地改善了目標模態的情感特征表示。
(2)我們設計了TCF模塊,它可以集成到預訓練的BERT語言模型的Transformer架構中。通過在每個Transformer層中嵌入TCF模塊,逐步實現了文本模態和非文本模態的互補,增強了多模態情感信息的融合和表達能力。
(3)實驗結果表明:所提出的圖像修復算法性能優于多種現有算法.
本文的其余部分組織如下:第二節回顧了有關單峰和MSA的工作。第3節詳細描述了我們提出的方法,包括TF-BERT模型的總體架構以及TCF和TCT模塊的設計。第4節討論了在兩個不同數據集上進行的實驗細節。第五部分給出了實驗結果沿著進行了深入的分析。最后,第六章對全文進行了總結和展望。
related works
multimodal sentiment analysis
結構框架:從單模態到多模態,按技術迭代的步伐遞進
- ??單模態情感分析??:
- ??肯定成就??:引用近期文獻(Darwich et al., 2020; Hamed et al., 2023)說明單模態方法的應用價值。
- ??批判局限性??:指出其無法捕捉情感復雜性(Geetha et al., 2024),引出多模態融合的必要性。
- ??多模態融合早期方法??:
- ??經典模型??:Zadeh等(2017)的張量融合網絡(計算復雜度高)。
- ??改進方向??:Sun等(2022)的CubeMLP(降低復雜度)、Miao等(2024)的低秩張量融合(增強信息捕獲)。
- ??深度學習時代??:
- ??RNN/LSTM局限??:序列處理瓶頸(Hou et al., 2024)與長程依賴問題。
- ??Transformer崛起??:并行處理優勢(Xiao et al., 2023)及在MSA中的應用(MULT、MISA、Self-MM等)。
- ??現有Transformer方法的不足??:
- ??兩模態交互限制??:Tsai等(2019)、Wang等(2023)僅支持雙模態交互,導致信息不完整。
- ??BERT融合不足??:現有工作(Rahman et al., 2020; Zhao et al., 2022)僅單層嵌入非文本模態,未能充分整合多模態信息。
- ??本文解決方案??:
- ??提出TCT模塊??:同時處理三模態交互,克服兩模態限制。
- ??TCF模塊嵌入BERT??:逐層漸進融合,增強多模態表征。
單模態情感分析側重于從單一模態(如文本、音頻或視頻)中提取情感信息。這些年來,該領域已經取得了實質性的進步,并且已經在各種實際情況下得到了廣泛的應用(Darwich等人,2020年; Hamed等人,2023年; Sukawai和Omar,2020年; Wang等人,2022年)的報告。然而,盡管取得了這些成就,但依賴單一模態往往無法捕捉到人類情感的全部復雜性和多維性(Geetha等人,2024年)的報告。單模態方法在表現情感豐富性和多樣性方面的局限性(Hazmoune和Bougamouza,2024; Lian等人,2023年)促使研究人員探索多模態融合。這導致了MSA的出現,與單峰方法相比,MSA提供了具有改進的準確性、魯棒性和泛化性的增強的情感識別。在MSA中,來自不同模態(如文本、音頻和視頻)的數據被集成到一個模型中,以更全面地捕獲情感特征。隨著深度學習技術的發展,MSA已經成為一個重要的研究熱點。
最初,Zadeh等人(2017年)提出了張量融合網絡,該網絡需要計算三重笛卡爾積,導致計算復雜度較高。Sun,Wang,et al.(2022)介紹了CubeMLP,它通過在三個MLP單元中使用仿射變換來降低張量融合網絡的計算復雜度。Miao等人(2024)通過將低秩張量融合與Mish激活函數相結合來捕獲模態之間的相互作用,從而增強了MSA模型的信息捕獲能力。隨著深度學習的發展,研究人員開始探索在神經網絡中整合多模態信息的更有效方法。傳統的深度學習方法依賴于RNN和LSTM網絡來處理來自不同模態的信息。Mai等人(2021)開發了聲學和視覺LSTM,以建立聲學和視覺增強的模態相互作用。Huddar等人(2021)提出使用基于注意力的雙向LSTM從話語中提取關鍵的上下文信息。然而,由于LSTM的序列性質,這些模型難以并行處理序列數據,增加了計算復雜性(Hou、Saad和Omar,2024)。此外,長序列輸入可能會導致信息丟失,從而限制模型探索長期依賴關系的能力。
為了解決這些問題,近年來Transformer模型已逐漸引入MSA領域(Sun等人,2023; Wang等人,2024年; Zong等人,2023年)的報告。Transformer建立在多頭注意力機制的基礎上,以其強大的并行處理和全局聚合能力而聞名(Xiao等人,2023),有效地解決了序列內的長期依賴性(Xiao等人,2024年)的報告。Hazarika等人(2020年)提出了MISA模型,該模型在使用Transformer融合特定模態和共享特征之前對其進行分解。為了保留特定模態的信息,Yu等人(2021年)引入了Self-MM,而Hwang和Kim(2023年)提出了SUGRM,兩者都使用自我監督來生成用于單模態情感預測任務的多模態標簽,然后通過Transformer進行級聯和融合。為了更好地捕捉多模態數據之間的錯位,Tsai等人(2019)率先提出了MULT,修改了Transformer結構,以捕捉兩種不同模態之間的情感信息和長期依賴性。Wang等人(2023)進一步提出了文本增強Transformer融合網絡,修改了跨模態Transformer結構,以通過將文本信息集成到非文本模態中進行增強來充分利用文本信息。Huang et al.(2023)介紹了TeFNA,該方法使用跨模態注意力逐漸對齊和融合非文本和文本表征。為了進一步增強每種模態的表示,Hou,Omar,et al.(2024)提出了TCHFN,在跨模態Transformer中使用目標模態作為鍵和值,使用源模態作為查詢。Hu等人(2024)提出了一種基于轉換器的多模態增強網絡,該網絡通過融合共享信息周圍的模態、結合自適應對比學習和多任務學習來增強性能,從而改善MSA。
盡管這些基于transformer的跨模態方法的性能有了顯著的改進,但它們的能力受到限制,一次只能處理兩個相應的模態。這種約束阻礙了模型同時捕獲多個模態之間復雜交互的能力,導致信息集成不足,處理復雜性增加,以及潛在的信息不一致,最終影響全局情感表示的準確性。為了克服這些限制,Lv等人(2021)引入了漸進式模態強化模型,該模型包含一個消息模塊來存儲多模態信息,增強了每種模態,同時允許在所有模態之間進行同時交互。然而,模態交互的消息模塊的引入可能導致信息冗余。Sun,Chen和Lin(2022)調整了Transformer框架,以便在每個融合過程中同時捕獲所有模態的互補信息。然而,這種方法導致相對較高的空間復雜度。Huang等人(2024)提出了一種模態綁定學習框架,該框架將細粒度卷積模塊集成到Transformer架構中,以促進三種模態之間的有效交互。盡管其有效性,融合過程仍然相對復雜。為了應對這些挑戰,我們設計了TCT,以同時建立所有模式之間的互動。在通過TCT增強每種模式之后,它構成了TCF的基礎。此外,由于預訓練的語言模型BERT在多個下游任務中表現出出色的性能,并具有強大的遷移學習能力,因此可以對其進行微調以適應MSA任務,從而顯著提高模型性能,同時節省訓練資源,并能夠構建更簡單,更高效的融合網絡。Kim和Park(2023)提出了All-Modalities-in-One BERT模型,該模型通過兩個多模態預訓練任務使BERT適應MSA。Rahman等人(2020)提出了MAG-BERT,它通過多模態適應門將非文本模態集成到文本模態中。Zhao,Chen,Liu和Tang(2022)介紹了共享私有記憶網絡,它在通過BERT學習文本表示的同時,結合了非文本模態的共享和私有特征。Zhao,Chen,Chen,et al.(2022)還提出了HMAI-BERT,它將記憶網絡集成到BERT的主干中,以對齊和融合非文本模態。Wang等人(2022)介紹了CENet,它以自我監督的方式生成非文本詞典,并采用轉換策略來減少文本和非文本表示之間的分布差異,然后與BERT融合。然而,這些模型僅將非文本模態嵌入到BERT內的單個Transformer層中以與文本模態融合,從而導致整個模型中的多模態信息的集成不足。為了解決這個問題,我們提出了TF-BERT,其目的是將TCF從BERT中的特定層嵌入到每個Transformer層中,逐步增強和融合所有模態表示。
method
在本節中,我們將詳細解釋TF-BERT的整體架構及其關鍵組件,如圖2所示。具體來說,第3.1節介紹了任務定義。第3.2節簡要概述了整個模型。第3.3節介紹BERT模型。第3.4節描述了TCF模塊,第3.5節討論了TCT模塊。
task definition
overall architecture
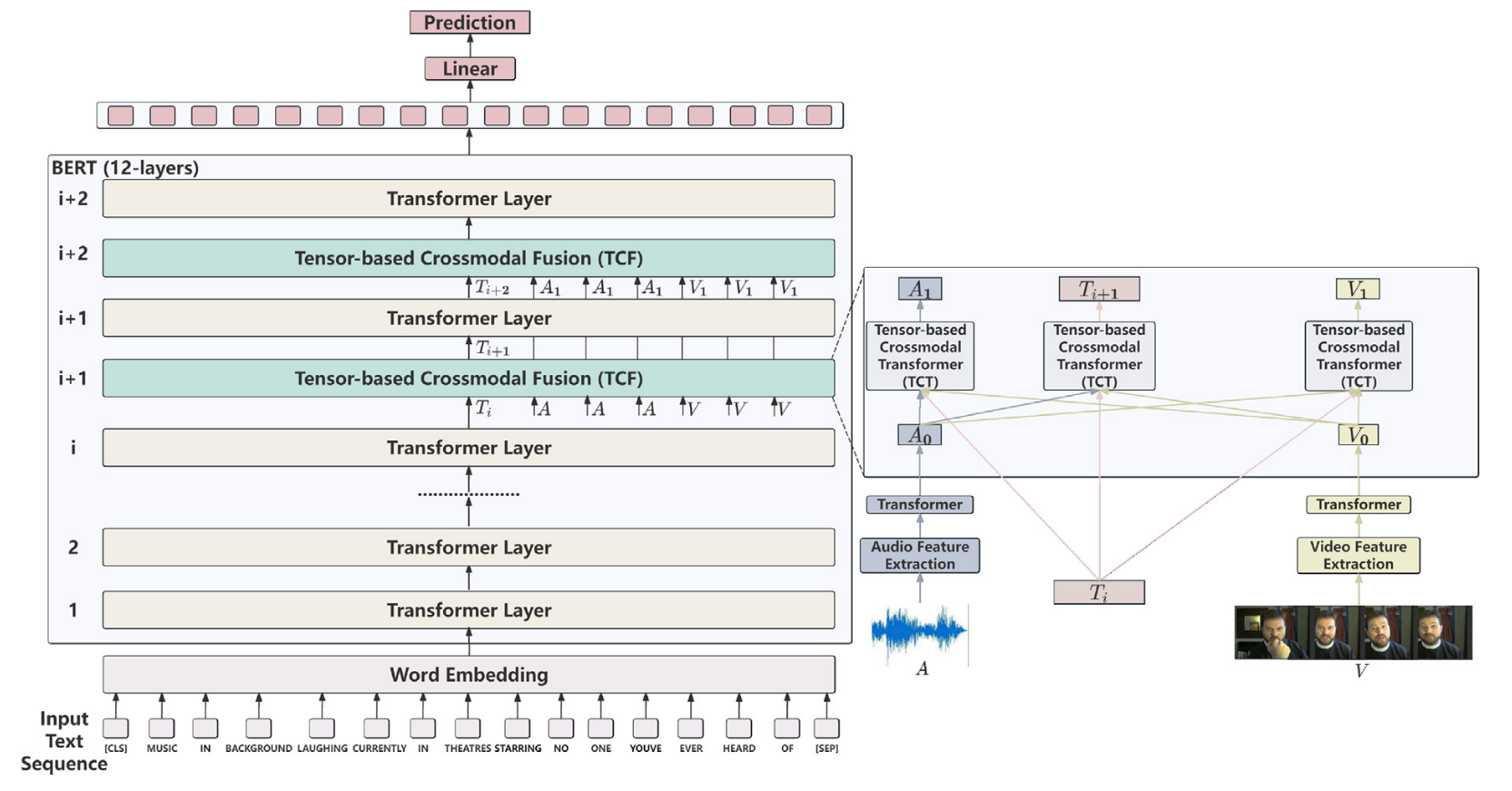
TF-BERT的結構如圖2所示。
-
??文本模態處理??:
- 文本模態數據通過詞嵌入轉換為向量形式,輸入BERT的Transformer層。
- 這些層捕獲文本中不同位置之間的復雜上下文依賴關系。
- 經過前?i?個Transformer層處理后,文本表示在語義上更加豐富。
-
??TCF模塊嵌入??:
- 從第?(i+1)?個Transformer層開始,TCF模塊被嵌入BERT中。
- 該模塊通過多模態交互增強各模態的表示:
- 第?(i+1)?個Transformer層處理增強后的文本表示。
- 非文本模態(如音頻、視覺)的表示經第?(i+1)?個TCF模塊增強后,與處理后的文本表示一同輸入第?(i+2)?個TCF模塊,進行進一步強化。
- 第?(i+2)?個Transformer層將多模態情感信息充分整合到文本表示中。
-
??基于張量的跨模態交互??:
- TCF模塊內使用基于張量的方法,從兩個源模態(如音頻、視覺)中捕獲情感信息。
- 跨模態Transformer利用這些信息增強目標模態(如文本),實現目標模態與兩個源模態之間的情感信息交換。
-
??輸出與預測??:
- TF-BERT最終輸出的文本表示富含多模態情感信息。
- 通過線性層(Linear)進行情感預測。
基于BERT的多層嵌入
在TF-BERT模型中,BERT起著核心作用。BERT最初由Google開發,是一種專門為自然語言處理任務設計的深度學習模型,需要進行微調以適應多模態任務。BERT包括12個Transformer層,并使用雙向訓練方法,這意味著它在處理文本時會考慮前后上下文,從而捕獲更豐富的語義關系。
BERT首先通過兩個主要任務在大規模無監督文本數據上進行預訓練:Masked Language Modeling和Next Sentence Prediction。在這個預訓練階段,BERT學習語言表征,包括與情感相關的信息。它非常適合集成到多模態任務中,可以進行微調以有效地融合多模態情感信息。
BERT首先通過兩個主要任務進行大規模預訓練:??掩碼語言建模??(Masked Language Modeling)和??下一句預測??(Next Sentence Prediction)。在此預訓練階段,BERT學習語言表示(包括情感相關信息),因此非常適合集成到多模態任務中,通過微調實現多模態情感信息的有效融合。


基于張量的交叉模態Transformer
?
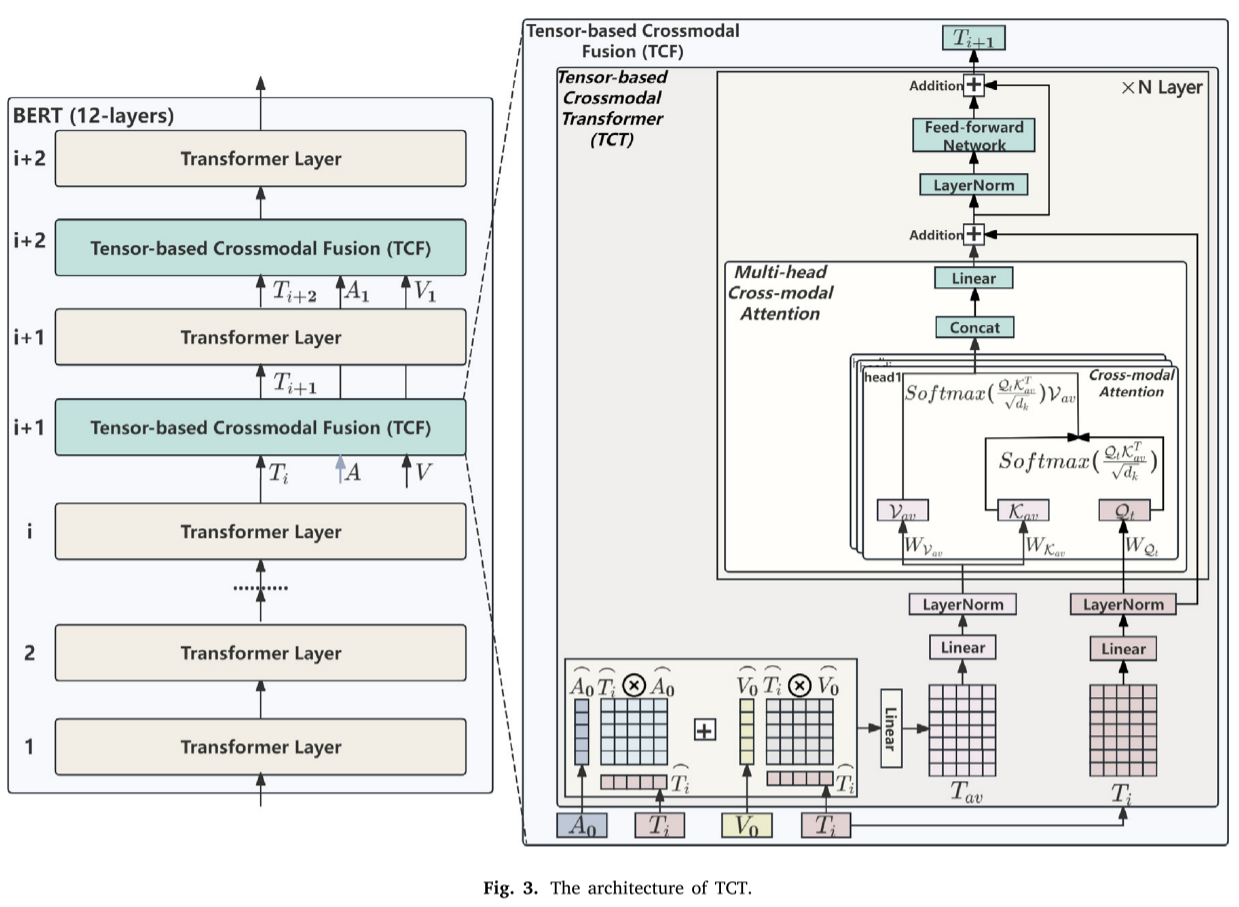
為了在跨模態Transformer中同時考慮來自所有模態的情感信息,我們設計了??TCT模塊??,如圖3所示。以文本模態的第(i+1)層TCT模塊為例,具體步驟如下:


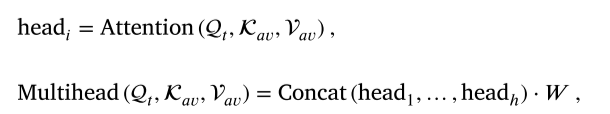
其中,k表示多頭交叉模態注意機制中的頭的數量,k表示多頭交叉模態注意機制的最終線性變換中使用的權重系數。
最后,經過多頭跨模態注意機制處理的表征經過LayerNorm層和前饋層,增強文本表征的穩定性,最終得到的結果是LayerNorm+1。






)


李宏毅)



)






)