回歸任務(Regression)與分類任務(Classification)是機器學習的兩大核心任務類型,其根本區別在于輸出變量的性質和任務目標。以下是系統性對比:
1. 本質區別:輸出變量類型
| 任務類型 | 輸出(Target) | 數學表達 | 示例 |
|---|---|---|---|
| 回歸任務 | 連續值(Continuous) | 實數域 | 房價(如325.7萬元)、溫度(36.5℃) |
| 分類任務 | 離散值(Discrete) | 有限類別集合? | 圖像類別(貓/狗)、郵件類型(垃圾/正常) |
2. 模型輸出形式對比
| 任務類型 | 輸出層設計 | 激活函數 | 輸出含義 |
|---|---|---|---|
| 回歸任務 | 單神經元 | 無 或 Linear | 直接預測連續值 |
| 分類任務 | -?二分類:1個神經元 -?多分類:K個神經元 | Sigmoid (二分類) Softmax (多分類) | 預測概率分布(各類別概率) |
📌?關鍵區別:
分類任務輸出概率(如?[0.1,0.9] 表示90%概率為“狗”),回歸任務輸出具體數值(如?25.325.3?表示溫度值)。
3. 損失函數(Loss Function)
| 任務類型 | 常用損失函數 | 數學形式 | 優化目標 |
|---|---|---|---|
| 回歸任務 | 均方誤差(MSE) | 最小化預測值與真實值的平方距離 | |
| 平均絕對誤差(MAE) | 最小化絕對誤差 | ||
| 分類任務 | 交叉熵(Cross-Entropy) | 最小化預測分布與真實分布的差異 |
為什么不同?
-
回歸:需量化預測值與真實值的數值差距(物理意義明確)。
-
分類:需衡量概率分布的相似性(交叉熵源于信息論)。
4. 評估指標(Evaluation Metrics)
| 任務類型 | 常用評估指標 | 解釋 |
|---|---|---|
| 回歸任務 | MSE / RMSE | 均方誤差 / 均方根誤差(越小越好) |
| MAE | 平均絕對誤差(魯棒性強) | |
| R2 (決定系數) | 模型解釋方差的比例(0~1,越大越好) | |
| 分類任務 | 準確率(Accuracy) | 正確預測樣本比例 |
| 精確率(Precision) | 正例預測中真實正例的比例 | |
| 召回率(Recall) | 真實正例中被預測正確的比例 | |
| F1-Score | 精確率和召回率的調和平均 | |
| AUC-ROC | 模型區分正負樣本的能力(0.5~1) |
💡?注意:分類任務中若類別不平衡(如99%負例),準確率會失效(全預測負例即99%準確),需用F1或AUC。
5. 典型算法對比
| 任務類型 | 經典算法 |
|---|---|
| 回歸任務 | 線性回歸、決策樹回歸、隨機森林回歸、梯度提升樹(GBRT)、支持向量回歸(SVR) |
| 分類任務 | 邏輯回歸、決策樹分類、隨機森林分類、支持向量機(SVM)、樸素貝葉斯 |
神經網絡架構差異:
-
回歸任務:輸出層為線性神經元(如?
nn.Linear(hidden_size, 1)) -
分類任務:輸出層為?Softmax/Sigmoid + 交叉熵損失(如?
nn.CrossEntropyLoss())
6. 決策邊界可視化
| 任務類型 | 決策邊界特點 | |
|---|---|---|
| 回歸任務 | 擬合連續曲線/曲面 | |
| 分類任務 | 劃分離散區域的邊界(線性/非線性) |
7. 特殊案例:二者相互轉化
(1) 回歸 → 分類(離散化)
-
場景:預測年齡(回歸)→ 判斷年齡段(分類)
例:
<18歲?→ 類別0,?18-35歲?→ 類別1,?>35歲?→ 類別2
(2) 分類 → 回歸(概率輸出)
-
場景:疾病診斷(分類)→ 輸出患病概率(連續值,可視為回歸)
例:邏輯回歸輸出概率?𝑃(癌癥)=0.73
???注意:轉化需謹慎,可能損失信息或引入偏差!
總結:核心差異全景圖
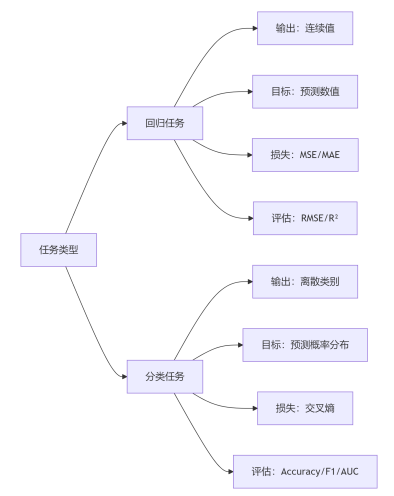
一句話記憶
回歸預測“多少”,分類判斷“是否”
—— 連續值是回歸的戰場,離散類別是分類的舞臺!
)



)
)


)





--8000字硬核解析 | 騰訊/阿里/字節真題實戰)




