目錄
- 前言
- 1 讀取數據的流程
- 1.1 檢查緩存是否命中
- 1.2 從數據庫讀取數據
- 1.3 更新緩存
- 1.4 返回數據
- 2 寫入數據的流程
- 2.1 更新數據庫
- 2.2 更新或刪除緩存
- 2.3 緩存失效
- 3 緩存與數據庫的一致性問題
- 3.1 寫穿(Write-through)策略
- 3.2 寫回(Write-back)策略
- 3.3 緩存失效策略
- 4. 總結與實踐
- 4.1 性能提升
- 4.2 一致性挑戰
- 4.3 實踐中的注意事項
- 結語
前言
隨著互聯網應用的快速發展,數據訪問的效率成為了許多系統設計中的核心問題之一。在大規模分布式系統中,數據庫往往成為了性能瓶頸,尤其是當應用需要頻繁地讀取相同的數據時。為了提升系統性能,減少數據庫的壓力,緩存技術應運而生。緩存通過將頻繁訪問的數據存儲在內存中,顯著降低了讀取延遲,提升了響應速度。但緩存的引入也帶來了數據一致性的問題,需要精心設計緩存與數據庫的交互流程。
本文將深入探討緩存和數據庫的讀寫流程,并分析它們的協作模式,幫助開發者更好地理解如何通過合理的緩存策略來提升系統性能和穩定性。
1 讀取數據的流程
在引入緩存之后,讀取數據的過程通常包括檢查緩存、訪問數據庫和更新緩存等幾個關鍵步驟。以下是緩存讀取的詳細流程。
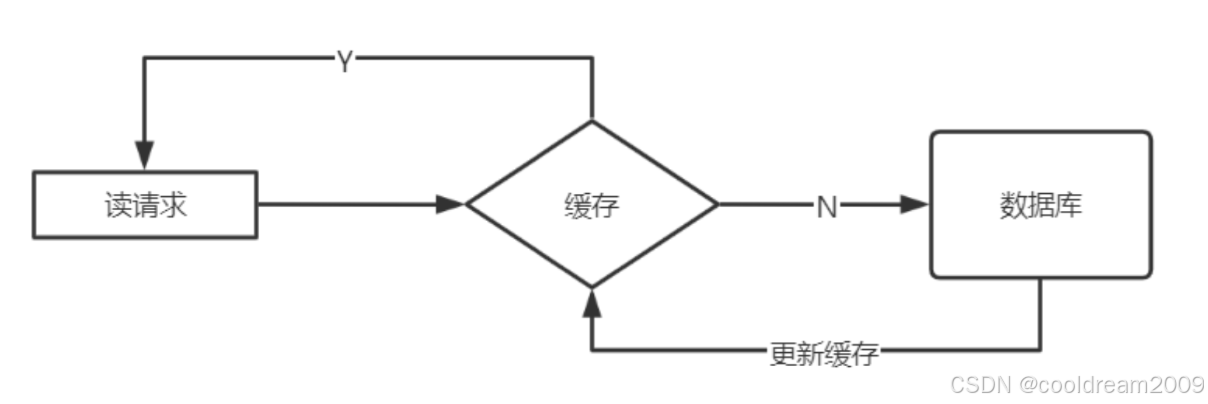
1.1 檢查緩存是否命中
當應用程序需要讀取某一數據時,首先會去檢查緩存中是否存在這條數據。緩存是一個快速的內存存儲系統,它比傳統的硬盤數據庫訪問速度快得多。常見的緩存技術包括 Redis、Memcached 等。在緩存中,每一條數據通常會根據某個唯一標識符(如數據的主鍵或唯一 ID)存儲,這樣在讀取時只需通過標識符即可快速定位。
緩存的命中與否直接影響到讀取的效率:
- 緩存命中:如果緩存中已經存在所需數據,那么應用直接從緩存中取出數據并返回。此時,數據庫并未被訪問,響應速度非常快。
- 緩存未命中:如果緩存中沒有所需數據,那么應用需要訪問數據庫來獲取數據。
1.2 從數據庫讀取數據
如果緩存未命中,系統會查詢數據庫獲取數據。此時,系統會根據請求的數據標識符向數據庫發起查詢。數據庫查詢通常會涉及 SQL 查詢語句的執行,雖然數據庫的查詢性能相對較高,但由于其底層是硬盤存儲,讀寫速度通常比內存緩存要慢。因此,頻繁的數據庫查詢可能會導致系統的性能瓶頸。
1.3 更新緩存
從數據庫成功讀取到數據后,為了提高下次讀取的效率,系統會將數據存儲到緩存中。這樣,下一次相同的請求就可以直接從緩存中獲取,避免了再次訪問數據庫。緩存更新的策略可以是直接寫入,也可以選擇根據一定的規則對緩存進行更新。例如,可以選擇為每條緩存數據設置一個過期時間,定期更新緩存中的數據。
1.4 返回數據
在數據成功讀取并緩存后,系統將最終的數據返回給客戶端,完成一次讀取請求的處理。需要注意的是,緩存中的數據并不一定是最新的,尤其在寫操作后,緩存可能會存在短時間的不一致。因此,在設計時需要特別注意緩存的一致性問題。
2 寫入數據的流程
與讀取數據的流程相比,寫入數據的流程相對復雜,尤其在需要確保數據一致性時。寫入數據時,緩存和數據庫的更新必須同步進行,否則可能會出現緩存與數據庫之間的數據不一致問題。寫操作的主要流程可以分為以下幾個步驟。
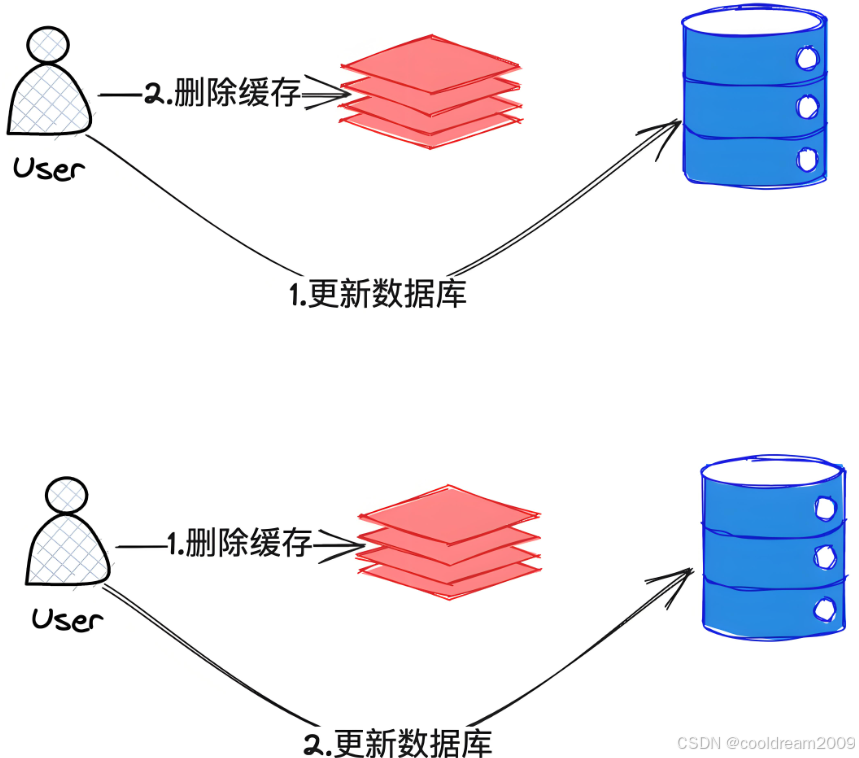
2.1 更新數據庫
無論數據是否在緩存中,寫操作的首要任務是確保數據庫中的數據始終保持一致。因此,所有的數據修改都首先會寫入數據庫,確保數據的持久化。這是因為緩存并非持久化存儲,可能會因服務器重啟等原因丟失數據,而數據庫通常是唯一的數據持久化存儲。
2.2 更新或刪除緩存
在更新完數據庫之后,接下來就需要考慮如何更新緩存。對于緩存的更新,有兩種常見的策略:
- 直接更新緩存:當數據更新完成后,直接將新的數據寫入緩存。這樣做可以確保緩存中的數據與數據庫中的數據始終保持一致,適用于那些更新頻繁、需要保證高一致性的場景。
- 刪除緩存:如果不需要立即更新緩存,或者希望通過重新計算來獲取最新的數據,可以選擇刪除緩存中的數據。這樣,當下一次請求相同數據時,系統會重新從數據庫中讀取數據并更新緩存。這種方式在某些場景下能夠減少緩存更新的復雜性。
2.3 緩存失效
另一種常見的處理方式是使用緩存過期機制。緩存中的數據通常會設置一個有效期(TTL),當數據過期后,緩存會自動失效,下一次請求時會重新從數據庫中獲取數據并更新緩存。這種方式在更新不頻繁或對數據一致性要求不那么嚴格的場景下非常有效。
3 緩存與數據庫的一致性問題
緩存和數據庫的交互雖然能夠顯著提升系統性能,但在大規模應用中,緩存與數據庫之間的一致性問題是不可忽視的。為了保持緩存與數據庫的數據一致性,常見的解決策略有以下幾種:
3.1 寫穿(Write-through)策略
寫穿策略是指每次數據寫入時,都會同時更新數據庫和緩存。這意味著,無論何時進行寫操作,都會確保緩存和數據庫的數據始終保持一致。寫穿策略簡單且易于實現,但其缺點是每次寫操作都需要訪問數據庫,可能會導致一定的性能開銷。
3.2 寫回(Write-back)策略
寫回策略與寫穿策略不同,寫回策略首先會將數據寫入緩存,而數據庫的更新則延遲一段時間,通常是異步的。這樣,系統在高頻寫操作下能夠提高性能,但也帶來了數據一致性問題。為了確保最終一致性,通常需要定期將緩存中的數據同步到數據庫,或者在數據寫入后通過后臺任務來更新數據庫。
3.3 緩存失效策略
緩存失效策略是在數據更新時,主動將緩存中的數據標記為失效,或者刪除緩存中的數據。這樣,下一次請求時,數據就會重新從數據庫中讀取并更新緩存。這種策略相對簡單,但需要保證緩存和數據庫之間的數據同步和時效性。
4. 總結與實踐
緩存技術在提高系統性能、減少數據庫負擔方面具有重要作用,但它也引入了緩存與數據庫之間的一致性問題。在設計緩存和數據庫的交互時,需要綜合考慮性能、數據一致性、復雜度等因素。
4.1 性能提升
緩存的最大優勢在于提升讀取性能。通過將熱點數據存儲在內存中,緩存能夠顯著減少數據庫的查詢次數,從而降低延遲和響應時間,提高系統的整體吞吐量。在高并發場景下,緩存的引入能夠有效分擔數據庫的負載,提升系統的可擴展性。
4.2 一致性挑戰
盡管緩存能大幅提升性能,但緩存與數據庫之間的數據一致性問題依然是不可忽視的挑戰。在高并發場景中,緩存和數據庫的同步更新往往是一個復雜的問題。開發者在選擇緩存策略時,需要根據業務需求和實際場景做出權衡。例如,對于一些數據更新不頻繁的應用,緩存失效策略可能是一個不錯的選擇;而對于需要高一致性的場景,寫穿策略則可能更加適合。
4.3 實踐中的注意事項
在實際開發中,緩存與數據庫的協作是一個非常常見的場景。在實現時,開發者需要關注以下幾個方面:
- 緩存的粒度:緩存的數據粒度不宜過大,否則會導致內存浪費。應根據業務需求合理規劃緩存的粒度。
- 緩存的過期策略:合理的過期時間可以幫助保持數據的新鮮度,防止過期數據對系統性能產生負面影響。
- 緩存與數據庫的同步策略:在寫操作中,如何確保緩存和數據庫的數據一致性,應該根據具體的業務需求和數據更新頻率來選擇合適的策略。
結語
緩存與數據庫的交互是一個高效系統設計的核心部分,通過合理的緩存策略可以大大提升應用的性能。然而,緩存與數據庫的同步、數據一致性等問題也需要開發者在設計時仔細考慮。隨著技術的發展,我們可以借助各種工具和策略來優化這一過程,確保系統在提供高性能的同時,也能保持數據的一致性和可靠性。在未來的應用開發中,緩存技術仍將發揮越來越重要的作用。

李宏毅)



)






)
---java版)





