集成學習及隨機森林
集成學習概述
泛化能力的局限
每種學習模型的能力都有其上限
- 限制于特定結構
- 受限于訓練樣本的質量和規模
如何再提高泛化能力?
- 研究新結構
- 擴大訓練規模
提升模型的泛化能力
創造性思路
- 組合多個學習模型
集成學習
集成學習不是特定的學習模型,而實一種構建模型的思路,一種訓練學習的思想
強可學習和弱可學習
強可學習:對于一個概念或者一個類,如果存在一個多項式學習算法可以學習它,正確率高,則該概念是強可學習的。
弱可學習:如果能學習,但正確率只比瞎猜略好,則稱為弱可學習。
也已證明,強可學習和弱可學習等價:
如果一個問題存在弱可學習算法,則必然存在強可學習算法
為集成學習奠定了基礎
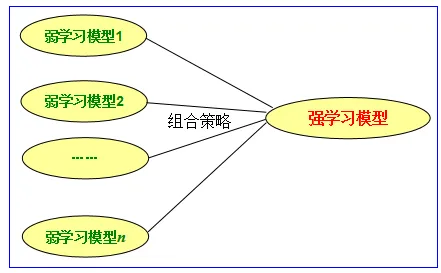
集成學習的基本問題
如何建立或選擇弱學習模型
弱學習模型通常是單個的模型,是被集成的成員
如何制定組合策略
如何將多個學習模型的預測結果整合在一起
不同的組合策略會帶來不同的結果
構建弱學習模型的策略
通常弱學習模型都是同類學習模型
同類模型之間的關系
-
無依賴關系
- 系列成員模型可以并行生成
- 代表算法:bagging,隨機森林
-
強依賴關系
- 系列成員模型可串行生成
- 代表算法:boosting、梯度提升樹
-
平均法
-
處理回歸問題
-
對弱學習模型的輸出進行平均得到最終的預測輸出
H ( x ) = 1 n ∑ i = 1 n h i ( x ) H(x)=\frac{1}{n}\sum_{i=1}^nh_i(x) H(x)=n1?i=1∑n?hi?(x)
-
也可以引入權重
H ( x ) = 1 n ∑ i = 1 n w i h i ( x ) H(x)=\frac{1}{n}\sum_{i=1}^nw_ih_i(x) H(x)=n1?i=1∑n?wi?hi?(x)
-
-
投票法
-
處理分類問題
少數服從多數,最大票數相同則隨機選擇
也可以新增加要求,例如票數過半
也可以給每個成員不同的投票權重
-
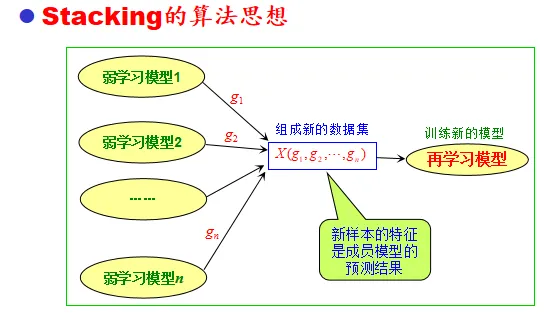
再學習法
平均法和投票法可能帶來大學習誤差
- 再學習
-
建立新的學習模型:再集成學習的組合端增加一個學習模型
-
成員學習的模型輸出作為新的學習模型的輸入,集成模型的數量為n,新數據集維度為n
-
代表方法:stacking
-
- 再學習
Bagging
——Bagging Aggregating的縮寫
Bootstrap是一種有放回操作的抽樣方法
- 抽取的樣本會有重復
在這里,用來指導構建弱分類器
-
使用同類學習模型時采用的策略
-
可降低模型過擬合的可能性
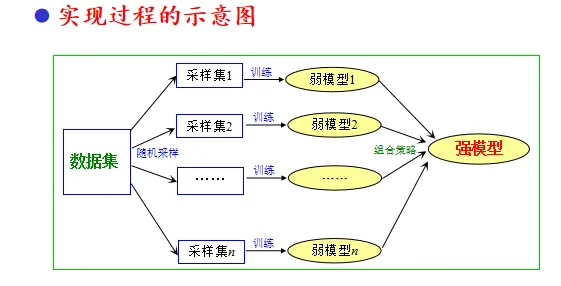
采樣過程說明
-
樣本集規模為M,采樣集規模也為M
- 樣本集的樣本不減少,每次采集后還要放回,因此同一樣本可能會多次采集到。
- 每次隨機采集一個樣本,隨機采集M次,組成采樣集
- 隨機采樣,組成規模為M的n個采樣集
- 由于隨機性,n個采樣集不完全一樣
- 訓練出的弱學習模型也存在差別
-
采樣集中不被選中樣本的概率
每次采樣,每個樣本不被選中的概率為:
p ( x ) = 1 ? 1 M p(x)=1-\frac{1}{M} p(x)=1?M1?
M次不被選中的概率為:
p ( x ) = ( 1 ? 1 M ) M lim ? M → ∞ ( 1 ? 1 M ) M = 1 e ≈ 0.368 p(x)=(1-\frac{1}{M})^M\\ \lim_{M\to\infty}(1-\frac{1}{M})^M=\frac{1}{e}\approx0.368 p(x)=(1?M1?)MM→∞lim?(1?M1?)M=e1?≈0.368
這些數據稱為袋外數據,大約36.8%的樣本可以用作測試集
弱學習模型的選擇
- 原則上沒有限制,通常選擇決策樹或神經網絡
組合策略
回歸問題用平均法,分類問題用投票法
算法描述
隨機森林
——Bagging算法的一個具體實現
- 采用CART作為弱學習模型
- 特征選擇也引入了隨機性
- 隨機選擇特征的子集 d s u b < d d_{sub}<d dsub?<d
- 在子集中選擇最優的分割特征
- 該操作可以進一步增強學習模型的泛化能力
極端隨機樹(ExtraTrees)
極端隨機樹的弱分類器不依賴于訓練的改變
- 不抽樣,也就不使用Bootstrap方法
- 也不像Boosting那樣,改變訓練樣本權重
它的隨機性體現在樹結點分裂時的兩個隨機過程
- 隨機選擇一小部分樣本的特征
- 隨機在部分屬性隨機選擇使結點分裂的屬性
- 因為不考慮分裂的是不是最優屬性,因此有些“極端”。
極端隨機樹的優勢
算法復雜度
- 對比RandomForest,Extratree更快
- 不抽樣,不選擇最優特征
擬合效果
因為不選擇最優特征,預測結果的方差大,不易過擬合
基本不用剪枝
泛化能力
在某些領域ExtraTree比RandomForest好些
對于那些訓練集分布與真實差別比較大的數據,ExtraTree更有優勢
如果弱學習模型引入Bootstrap,隨機性會進一步增大





測試全方位全流程實戰【2025最新版!!】)

詳解)


)





?)


----動態規劃·背包模型(一))