一、引言
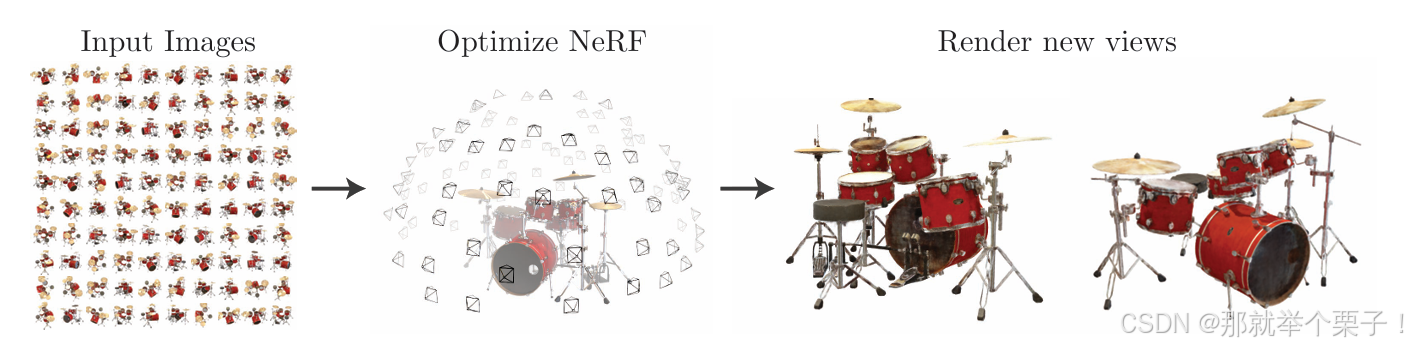
神經輻射場(Neural Radiance Fields,簡稱NeRF)是近年來計算機視覺和圖形學領域的一項革命性技術,它能夠從2D圖像中學習復雜的3D場景表示。然而,NeRF技術的實現和應用門檻較高,需要較為專業的計算機視覺和深度學習知識。
Nerfstudio作為一個開源框架,極大地簡化了NeRF技術的使用流程,使研究人員和開發者能夠更輕松地構建、訓練和測試NeRF模型。本文將詳細介紹如何在Ubuntu 20.04和CUDA 11.8環境下配置Nerfstudio,并使用自有圖片和視頻數據集進行訓練和測試,最終導出為點云和網格等多種格式。
二、Nerfstudio簡介
Nerfstudio是由加州大學伯克利分校的研究人員開發的一個模塊化NeRF開發框架,旨在提供一個更加用戶友好的環境來探索NeRF技術。它的主要優勢包括:
- 模塊化設計:將NeRF的各個組件模塊化,便于理解和定制
- 完整工作流:提供從數據采集、處理到訓練、渲染的完整工作流
- 可視化界面:內置基于Web的3D可視化工具,支持實時交互
- 多種算法支持:集成了多種NeRF變體算法,如nerfacto、instant-ngp等
- 社區支持:活躍的開發者社區和詳盡的文檔
無論是初學者還是研究人員,Nerfstudio都能滿足你對NeRF技術的探索需求。
三、環境配置
3.1 硬件要求
Nerfstudio需要一定的硬件配置才能正常運行:
- GPU:NVIDIA GPU,顯存至少8GB(推薦12GB以上)
- CPU:多核處理器,至少8GB RAM(推薦16GB以上)
- 存儲:至少50GB可用空間(數據集大小視情況而定)
本文將在以下環境中進行測試: - Ubuntu 20.04 LTS
- CUDA 11.8
- NVIDIA GeForce RTX 4090 GPU (24GB 顯存)
3.2 軟件環境準備
首先,我們需要確保系統已經安裝了適當的NVIDIA驅動和CUDA 11.8。讓我們檢查當前的CUDA版本:
nvidia-smi
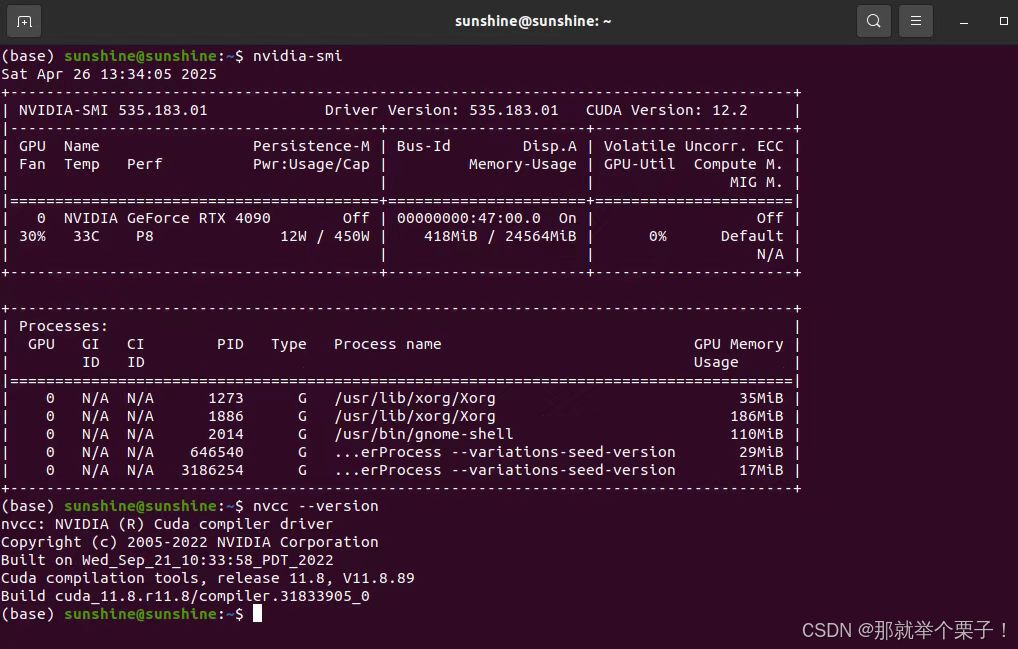
如果CUDA版本不是11.8,您需要安裝對應版本的CUDA工具包。可以從NVIDIA官網下載CUDA 11.8安裝包。
接下來,我們需要配置Python環境。Nerfstudio要求Python版本至少為3.8。我們將使用Conda創建一個獨立的環境:
# 安裝Miniconda(如果尚未安裝)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b
source ~/miniconda3/bin/activate# 創建名為nerfstudio的環境
conda create --name nerfstudio python=3.8 -y
conda activate nerfstudio# 更新pip
pip install --upgrade pip
為了確保與CUDA 11.8兼容,我們需要安裝特定版本的PyTorch:
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
接下來,我們需要安裝CUDA工具包和tiny-cuda-nn,這是NeRF實現中常用的庫:
# 安裝CUDA工具包
conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit -y# 安裝tiny-cuda-nn
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
3.3 Nerfstudio安裝
現在,我們可以開始安裝Nerfstudio。我們將從GitHub克隆最新的代碼:
# 克隆Nerfstudio倉庫
git clone https://github.com/nerfstudio-project/nerfstudio.git
cd nerfstudio# 安裝Nerfstudio
pip install --upgrade pip setuptools
pip install -e .
此外,我們還需要安裝COLMAP,這是一個用于從圖像中恢復相機參數的結構運動(Structure from Motion,SfM)工具:
# 安裝COLMAP依賴項
sudo apt-get update && sudo apt-get install -y \git cmake build-essential \libboost-program-options-dev \libboost-filesystem-dev \libboost-graph-dev \libboost-system-dev \libboost-test-dev \libeigen3-dev \libsuitesparse-dev \libfreeimage-dev \libgoogle-glog-dev \libgflags-dev \libglew-dev \qtbase5-dev \libqt5opengl5-dev \libcgal-dev \libcgal-qt5-dev# 克隆COLMAP倉庫
git clone https://github.com/colmap/colmap.git
cd colmap
git checkout dev# 編譯安裝COLMAP
mkdir build
cd build
cmake ..
make -j $(nproc)
sudo make install# 返回之前的目錄
cd ../..
具體內容也可也參考我之前的博客
基于NVIDIA RTX 4090的COLMAP 3.7安裝指南:Ubuntu 20.04 + CUDA 11.8環境配置【2025最新版!!】
3.4 安裝驗證
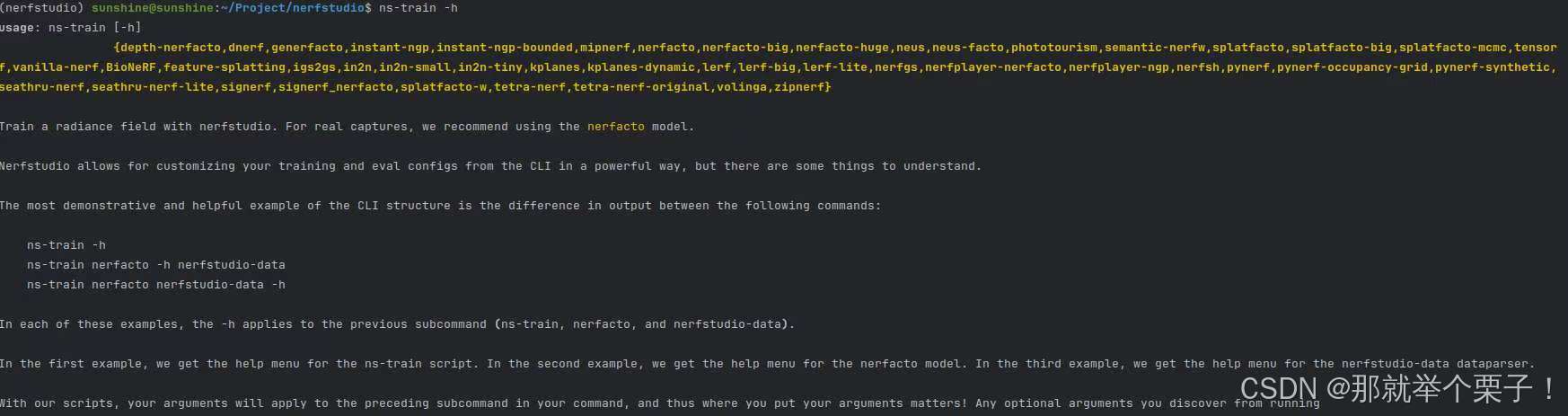
完成安裝后,我們可以運行以下命令來驗證安裝是否成功:
# 檢查Nerfstudio是否安裝成功
ns-train -h
如果安裝成功,應該能看到Nerfstudio的幫助信息。
四、預置數據集測試
在使用自己的數據集之前,可以先使用Nerfstudio提供的預置數據集進行測試,以確保所有組件正常工作。
4.1 下載測試數據
Nerfstudio提供了多個預置數據集,我們可以使用ns-download-data命令下載這些數據集:
# 使用nerfacto模型訓練poster數據集
ns-train nerfacto --data data/nerfstudio/poster
這將在當前目錄下創建一個data/nerfstudio/poster目錄,其中包含了poster數據集的所有圖像和相機參數文件。
4.2 訓練模型
現在,我們可以使用下載的數據集訓練一個NeRF模型。Nerfstudio提供了多種模型實現,在此我們選擇nerfacto,這是一個性能較好的通用模型:
# 使用nerfacto模型訓練poster數據集
ns-train nerfacto --data data/nerfstudio/poster
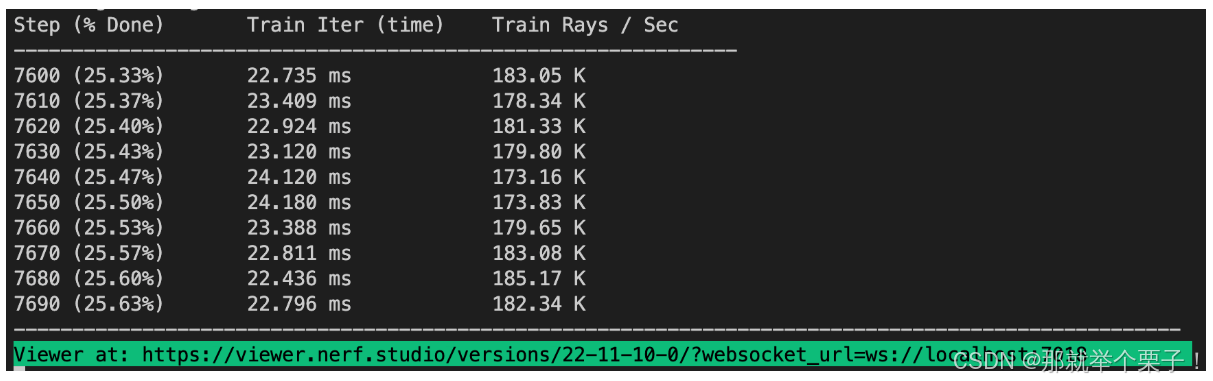
在訓練過程中,終端會顯示訓練進度、損失值等信息。訓練通常需要數小時到數天不等,具體取決于數據集大小、選擇的模型和硬件配置。默認情況下,訓練結果會保存在outputs目錄下,目錄名為訓練開始的時間戳。
如果一切正常,你應該會看到如下所示的訓練進度:
4.3 可視化結果
Nerfstudio提供了一個基于Web的可視化工具,可以實時查看訓練進度和結果。在訓練開始后,終端會輸出一個本地Web服務器地址,通常是http://localhost:7007。您可以在瀏覽器中打開這個地址來查看訓練進度和實時渲染結果。
如果您是在遠程服務器上運行Nerfstudio,需要進行端口轉發才能訪問可視化工具:
# 本地端口轉發(在本地終端中運行)
ssh -L 7007:localhost:7007 <username>@<server-ip>
然后,在本地瀏覽器中訪問http://localhost:7007。

五、自有圖片數據集處理
現在,可以嘗試使用自己的圖片數據集來訓練NeRF模型。
5.1 拍攝建議
拍攝用于NeRF的圖像需要遵循一些建議,以確保能夠獲得良好的重建結果:
- 拍攝角度:從不同角度拍攝物體,覆蓋盡可能多的視角
- 重疊度:相鄰圖像之間應有足夠的重疊(約60-80%)
- 光照條件:保持一致的光照條件,避免強烈的陰影或高光
- 物體靜止:確保場景中的物體保持靜止
- 數量:通常需要30-100張圖像,具體取決于場景復雜度
- 清晰度:避免模糊的圖像,使用三腳架或高速快門
5.2 數據準備
首先,我們需要創建一個目錄來存放我們的圖像數據:
# 創建目錄
mkdir -p data/custom/input
然后,將你的圖像復制到這個目錄中:
# 假設您的圖像在~/my_images目錄下
cp ~/my_images/*.jpg data/custom/input/
5.3 數據處理
接下來,我們需要使用ns-process-data命令處理這些圖像,以便Nerfstudio能夠使用它們:
# 處理圖像數據集
ns-process-data images \--data data/custom/images \--output-dir data/custom/processed_images
此命令將使用COLMAP估計圖像的相機參數,并生成Nerfstudio所需的格式。處理過程可能需要一些時間,具體取決于圖像數量和計算機性能。
如果你的圖像具有特殊特性(如全景圖像),可以使用其他參數:
# 處理全景圖像
ns-process-data images \--data data/custom/images \--output-dir data/custom/processed_images \--camera-type equirectangular
如果COLMAP處理失敗,可以嘗試使用不同的特征提取和匹配參數:
# 使用更全面的特征匹配方法
ns-process-data images \--data data/custom/images \--output-dir data/custom/processed_images \--matching-method exhaustive \--feature-type sift \--verbose
5.4 訓練自定義數據集
處理完成后,我們可以使用處理好的數據集訓練NeRF模型:
# 使用nerfacto模型訓練自定義數據集
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images
你可以根據需要調整訓練參數,如學習率、批量大小等:
# 使用更高的學習率和更多的訓練步數
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_high_lr \--optimizers.fields.optimizer.lr 1e-2 \--optimizers.fields.scheduler.max-steps 30000
如果你的GPU顯存較小,可以減少批量大小:
# 減小批量大小
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_small_batch \--pipeline.datamanager.train-num-rays-per-batch 1024
六、自有視頻數據集處理
除了圖像,我們還可以使用視頻作為數據源來訓練NeRF模型。
6.1 視頻拍攝建議
拍攝用于NeRF的視頻也需要遵循一些建議:
- 相機移動:緩慢移動相機,避免劇烈抖動
- 場景覆蓋:盡量圍繞物體一圈,從不同角度拍攝
- 光照條件:保持一致的光照
- 幀率:使用較高的幀率(至少30fps)
- 分辨率:使用較高的分辨率(至少1080p)
- 持續時間:視頻長度約為30-60秒
6.2 視頻數據準備
首先,創建一個目錄來存放視頻數據:
# 創建目錄
mkdir -p data/custom/video
然后,將你的視頻復制到這個目錄中:
# 假設您的視頻在~/my_video.mp4
cp ~/my_video.mp4 data/custom/video/
6.3 視頻數據處理
接下來,我們使用ns-process-data命令處理視頻數據:
# 處理視頻數據集
ns-process-data video \--data data/custom/video/my_video.mp4 \--output-dir data/custom/processed_video
此命令將視頻分解為幀,并使用COLMAP估計相機參數。默認情況下,它會提取約300幀,您可以通過參數調整幀數:
# 提取更多幀
ns-process-data video \--data data/custom/video/my_video.mp4 \--output-dir data/custom/processed_video \--num-frames-target 500
如果你的視頻具有特殊特性(如全景視頻),可以使用相應的參數:
# 處理全景視頻
ns-process-data video \--data data/custom/video/my_video.mp4 \--output-dir data/custom/processed_video \--camera-type equirectangular
6.4 訓練自定義視頻數據集
處理完成后,我們可以使用處理好的視頻數據集訓練NeRF模型:
# 使用nerfacto模型訓練自定義視頻數據集
ns-train nerfacto \--data data/custom/processed_video \--experiment-name custom_video
由于視頻幀之間的變化通常較小,我們可以使用順序采樣來提高訓練效率:
# 使用順序采樣
ns-train nerfacto \--data data/custom/processed_video \--experiment-name custom_video_sequential \--pipeline.datamanager.train-num-images-to-sample-from 25
七、訓練失敗排查
如果你在訓練過程中遇到問題,這里有一些常見的故障排除方法:
(1)CUDA內存不足:
CUDA out of memory
解決方法:減小批量大小或模型復雜度
ns-train nerfacto \--data data/custom/processed_images \--pipeline.datamanager.train-num-rays-per-batch 1024 \--pipeline.model.num-proposal-samples-per-ray 64
(2)COLMAP失敗:
COLMAP failed to reconstruct the scene
解決方法:嘗試使用不同的特征提取和匹配參數
ns-process-data images \--data data/custom/images \--output-dir data/custom/processed_images \--matching-method exhaustive \--feature-type sift \--colmap-gpu True
(3)訓練不收斂:
如果模型訓練不收斂,可以嘗試調整學習率或使用不同的優化器:
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_adam \--optimizers.fields.optimizer.type Adam \--optimizers.fields.optimizer.lr 5e-4
八、模型優化技巧
以下是一些優化NeRF模型性能的技巧:
(1)使用相機優化:
允許模型微調相機參數可以提高重建質量:
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_camera_opt \--pipeline.model.camera-optimizer.mode SO3xR3
(2)調整網絡架構:
嘗試不同的網絡大小和復雜度:
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_large_net \--pipeline.model.field-network.num-layers 8 \--pipeline.model.field-network.hidden-dim 256
(3)嘗試不同的模型:
Nerfstudio提供了多種模型實現,如instant-ngp(速度更快)、vanilla-nerf(原始實現)等:ns-train instant-ngp \--data data/custom/processed_images \--experiment-name custom_images_instant_ngp
九、性能調優
以下是一些提高訓練和渲染速度的技巧:
(1)使用混合精度訓練:
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_mixed_precision \--mixed-precision True
(2)減少評估頻率:
ns-train nerfacto \--data data/custom/processed_images \--experiment-name custom_images_less_eval \--pipeline.datamanager.eval-num-rays-per-chunk 1024 \--steps-per-eval 500
(3)使用更高效的模型:
ns-train instant-ngp \--data data/custom/processed_images \--experiment-name custom_images_instant_ngp
七、總結
在本文中,我們詳細介紹了如何在Ubuntu 20.04和CUDA 11.8環境下配置Nerfstudio,并使用自有圖片和視頻數據集進行訓練和測試,通過Nerfstudio,我們可以輕松地將2D圖像轉換為3D模型,并生成新視角的渲染效果。這一技術在虛擬現實、增強現實、游戲開發、建筑可視化等領域都有廣泛的應用。

詳解)


)





?)


----動態規劃·背包模型(一))


)


