PETR和位置編碼
petr檢測網絡中有2種類型的位置編碼。
正弦編碼和petr論文提出的3D Position Embedding。transformer模塊輸入除了qkv,還有query_pos和key_pos。這里重點記錄下query_pos和key_pos的生成
- query pos的生成
先定義reference_points, shape為(n_query, 3),編碼部分有兩部分構成,經過pos2posemb3d編碼(sin編碼)后,再用FFN(query_embed)編碼一次后用作transformer的query_pos. 至于為什么多了個一次FFN編碼,GPT這么解釋的:
這種兩步編碼的設計實際上是將固定的位置編碼(pos2posemb3d)和可學習的位置編碼(query_embedding)相結合,既保留了位置的幾何信息,又允許模型學習任務相關的位置表示。這種設計在3D視覺任務中特別有效,因為它既考慮了空間的周期性特征,又保持了位置編碼的可學習性。
- pos2posemb3d(sin編碼)
標準的正弦編碼
def pos2posemb3d(pos, num_pos_feats=128, temperature=10000):scale = 2 * math.pipos = pos * scale # map pos from [-1, 1] to [-2pi, 2pi]dim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_z = pos[..., 2, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)pos_z = torch.stack((pos_z[..., 0::2].sin(), pos_z[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x, pos_z), dim=-1)return posemb
- query_embed(FFN)
self.query_embedding = nn.Sequential(nn.Linear(self.embed_dims*3//2, self.embed_dims),nn.ReLU(),nn.Linear(self.embed_dims, self.embed_dims),)
-
key_pos的生成
對于二維目標檢測來說,對像素位置做編碼就行了(sin_embed), 如下圖的backbone這個分支,對于三維目標檢測,petr對每個像素還做了三維位置編碼(coords_position_embeding), 下圖最下面一個分支。
最終給transformer的key_pos = 3d位置編碼+ 2d像素位置編碼
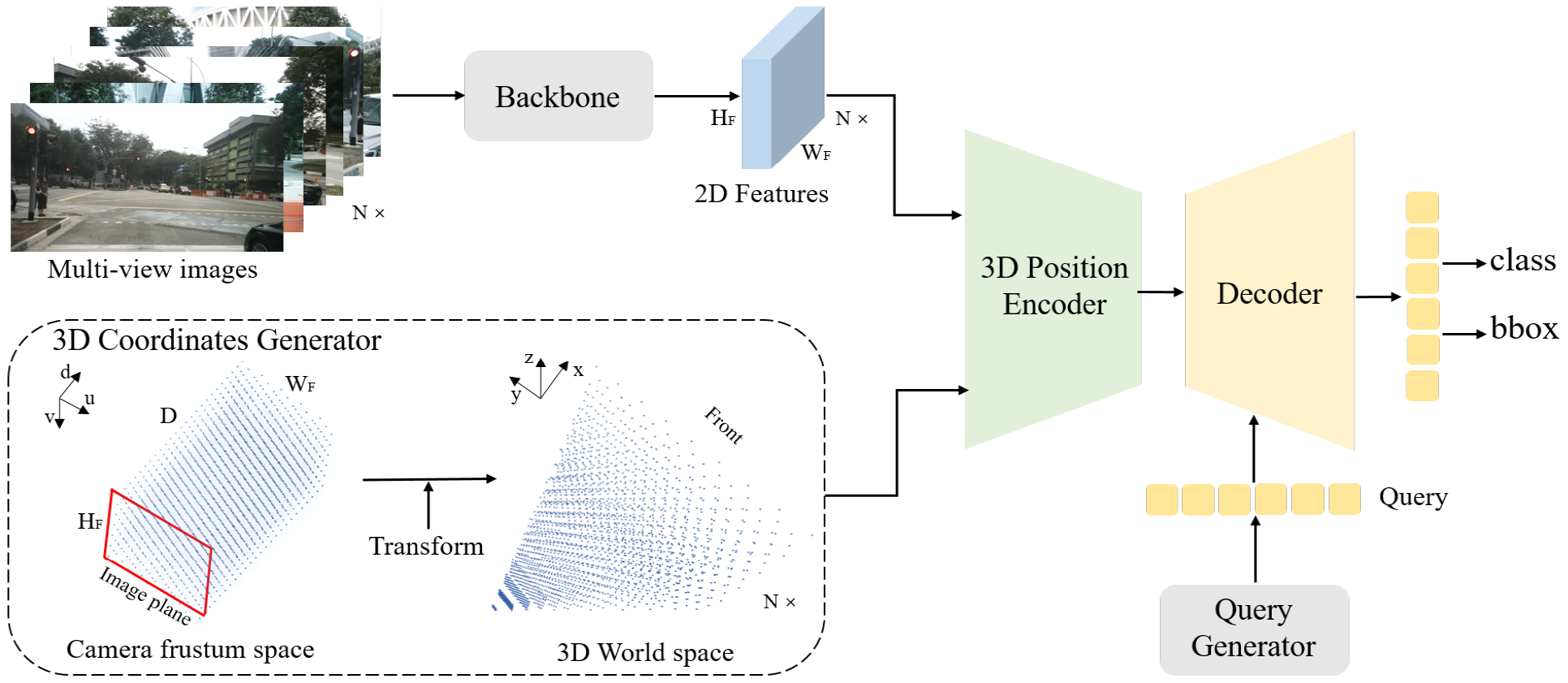
- 像素的3d位置編碼
根據圖像尺寸定義一個視錐空間(coords),每個點用(u, v, d)表示,結合相機內參,可以將其轉為世界坐標系下的點(coords3d),在用position_encoder(卷積)處理得到位置編碼。
def position_embeding(self, img_feats, img_metas, masks=None):eps = 1e-5pad_h, pad_w, _ = img_metas[0]['pad_shape'][0]B, N, C, H, W = img_feats[self.position_level].shapecoords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / Hcoords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / Wif self.LID:index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()index_1 = index + 1bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))coords_d = self.depth_start + bin_size * index * index_1else:index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()bin_size = (self.position_range[3] - self.depth_start) / self.depth_numcoords_d = self.depth_start + bin_size * indexD = coords_d.shape[0]coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1)coords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps)img2lidars = []for img_meta in img_metas:img2lidar = []for i in range(len(img_meta['lidar2img'])):img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i]))img2lidars.append(np.asarray(img2lidar))img2lidars = np.asarray(img2lidars)img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4)coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1)img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1)coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3]coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0])coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2])coords_mask = (coords3d > 1.0) | (coords3d < 0.0)coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5)coords_mask = masks | coords_mask.permute(0, 1, 3, 2)coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W)coords3d = inverse_sigmoid(coords3d)coords_position_embeding = self.position_encoder(coords3d) # position_encoder:conv+relu+convreturn coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask- 像素的2d正弦編碼
通過圖像的寬高,可以對每個像素坐標生成位置編碼
#SinePositionalEncoding3D def forward(self, mask): """Forward function for `SinePositionalEncoding`.Args:mask (Tensor): ByteTensor mask. Non-zero values representingignored positions, while zero values means valid positionsfor this image. Shape [bs, h, w].Returns:pos (Tensor): Returned position embedding with shape[bs, num_feats*2, h, w]."""# For convenience of exporting to ONNX, it's required to convert# `masks` from bool to int.mask = mask.to(torch.int)not_mask = 1 - mask # logical_notn_embed = not_mask.cumsum(1, dtype=torch.float32)y_embed = not_mask.cumsum(2, dtype=torch.float32)x_embed = not_mask.cumsum(3, dtype=torch.float32)if self.normalize:n_embed = (n_embed + self.offset) / \(n_embed[:, -1:, :, :] + self.eps) * self.scaley_embed = (y_embed + self.offset) / \(y_embed[:, :, -1:, :] + self.eps) * self.scalex_embed = (x_embed + self.offset) / \(x_embed[:, :, :, -1:] + self.eps) * self.scaledim_t = torch.arange(self.num_feats, dtype=torch.float32, device=mask.device)dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats)pos_n = n_embed[:, :, :, :, None] / dim_tpos_x = x_embed[:, :, :, :, None] / dim_tpos_y = y_embed[:, :, :, :, None] / dim_t# use `view` instead of `flatten` for dynamically exporting to ONNXB, N, H, W = mask.size()pos_n = torch.stack((pos_n[:, :, :, :, 0::2].sin(), pos_n[:, :, :, :, 1::2].cos()),dim=4).view(B, N, H, W, -1)pos_x = torch.stack((pos_x[:, :, :, :, 0::2].sin(), pos_x[:, :, :, :, 1::2].cos()),dim=4).view(B, N, H, W, -1)pos_y = torch.stack((pos_y[:, :, :, :, 0::2].sin(), pos_y[:, :, :, :, 1::2].cos()),dim=4).view(B, N, H, W, -1)pos = torch.cat((pos_n, pos_y, pos_x), dim=4).permute(0, 1, 4, 2, 3)return posdef __repr__(self):"""str: a string that describes the module"""repr_str = self.__class__.__name__repr_str += f'(num_feats={self.num_feats}, 'repr_str += f'temperature={self.temperature}, 'repr_str += f'normalize={self.normalize}, 'repr_str += f'scale={self.scale}, 'repr_str += f'eps={self.eps})'return repr_str - 像素的3d位置編碼
順便記錄下未使用的可學習編碼
@POSITIONAL_ENCODING.register_module()class LearnedPositionalEncoding3D(BaseModule):"""Position embedding with learnable embedding weights.Args:num_feats (int): The feature dimension for each positionalong x-axis or y-axis. The final returned dimension foreach position is 2 times of this value.row_num_embed (int, optional): The dictionary size of row embeddings.Default 50.col_num_embed (int, optional): The dictionary size of col embeddings.Default 50.init_cfg (dict or list[dict], optional): Initialization config dict."""def __init__(self,num_feats,row_num_embed=50,col_num_embed=50,init_cfg=dict(type='Uniform', layer='Embedding')):super(LearnedPositionalEncoding3D, self).__init__(init_cfg)self.row_embed = nn.Embedding(row_num_embed, num_feats)self.col_embed = nn.Embedding(col_num_embed, num_feats)self.num_feats = num_featsself.row_num_embed = row_num_embedself.col_num_embed = col_num_embeddef forward(self, mask):"""Forward function for `LearnedPositionalEncoding`.Args:mask (Tensor): ByteTensor mask. Non-zero values representingignored positions, while zero values means valid positionsfor this image. Shape [bs, h, w].Returns:pos (Tensor): Returned position embedding with shape[bs, num_feats*2, h, w]."""h, w = mask.shape[-2:]x = torch.arange(w, device=mask.device)y = torch.arange(h, device=mask.device)x_embed = self.col_embed(x)y_embed = self.row_embed(y)pos = torch.cat((x_embed.unsqueeze(0).repeat(h, 1, 1), y_embed.unsqueeze(1).repeat(1, w, 1)),dim=-1).permute(2, 0,1).unsqueeze(0).repeat(mask.shape[0], 1, 1, 1)return pos
參考鏈接:
https://blog.csdn.net/qq_16137569/article/details/123576866

)

redis)

(下))









省賽回憶)
)


