PCIE協議理解
提示:這里可以添加系列文章的所有文章的目錄,目錄需要自己手動添加
PCIE學習理解。
文章目錄
- PCIE協議理解
- @[TOC](文章目錄)
- 前言
- 零、PCIE掌握點?
- 一、PCIE是什么?
- 二、PCIE協議總結
- 物理層
- 切速
- 鏈路層
- 事務層
- 6.2 TLP的路由
- 電源管理
- 虛擬化
- 三、疑難雜癥
- PCIE4到PCIE5變化點
- PCIE5到PCIE6變化點
- Pcie bar 空間寄存器
- ATS機制
- 參考資料
- 總結
文章目錄
- PCIE協議理解
- @[TOC](文章目錄)
- 前言
- 零、PCIE掌握點?
- 一、PCIE是什么?
- 二、PCIE協議總結
- 物理層
- 切速
- 鏈路層
- 事務層
- 6.2 TLP的路由
- 電源管理
- 虛擬化
- 三、疑難雜癥
- PCIE4到PCIE5變化點
- PCIE5到PCIE6變化點
- Pcie bar 空間寄存器
- ATS機制
- 參考資料
- 總結
前言
本文內容:PCIE協議理解和總結。
PCIE理解和總結。
提示:以下是本篇文章正文內容
零、PCIE掌握點?
PCIE是什么?
PCIE的優缺點是什么?
PCIE協議與其他協議的不同點是什么?
PCIE有什么應用場景?
PCIE控制器上游對接什么模塊,下游對接什么模塊?
PCIE驅動是什么?
PCIE芯片如何測試?
一、PCIE是什么?
PCIE是一種外圍組件接口協議。
二、PCIE協議總結
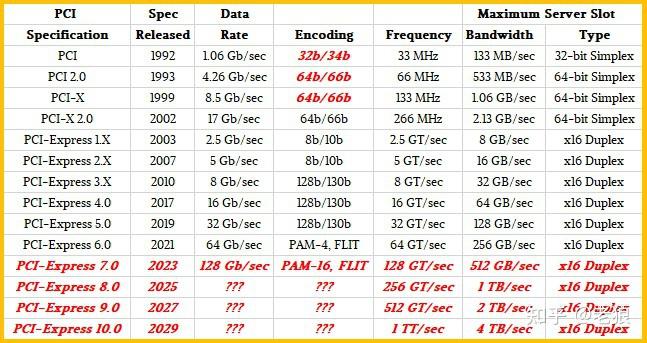
物理層
切速
PCIE6下支持怎樣的切速?
鏈路層
事務層
6.2 TLP的路由
基于地址的路由:
存儲器讀寫和I/O讀寫使用此方式。
基于ID的路由:
主要用于配置讀寫請求TLP、Cpl、CplD報文和Vender_Defined消息報文。
隱式路由:
消息請求使用隱式路由方式。
電源管理
虛擬化
SR-IOV
SR-IOV介紹
SR-IOV 技術是一種基于硬件的虛擬化解決方案,可提高性能和可伸縮性。
SR-IOV 標準允許在虛擬機之間高效共享 PCIe(Peripheral Component Interconnect Express,快速外設組件互連)設備,并且它是在硬件中實現的,可以獲得能夠與本機性能媲美的 I/O 性能。SR-IOV 規范定義了新的標準,根據該標準,創建的新設備可允許將虛擬機直接連接到 I/O 設備。SR-IOV 規范由 PCI-SIG 在 http://www.pcisig.com 上進行定義和維護。單個 I/O 資源可由許多虛擬機共享。共享的設備將提供專用的資源,并且還使用共享的通用資源。這樣,每個虛擬機都可訪問唯一的資源。因此,啟用了 SR-IOV 并且具有適當的硬件和 OS 支持的 PCIe 設備(例如以太網端口)可以顯示為多個單獨的物理設備,每個都具有自己的 PCIe 配置空間。
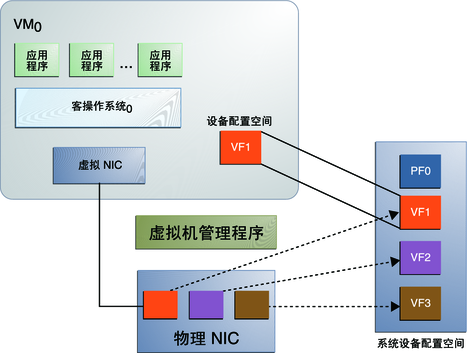
PF 包含 SR-IOV 功能結構,用于管理 SR-IOV 功能。PF 是全功能的 PCIe 功能,可以像其他任何 PCIe 設備一樣進行發現、管理和處理。PF 擁有完全配置資源,可以用于配置或控制 PCIe 設備。虛擬功能 (Virtual Function, VF)是與物理功能關聯的一種功能。VF 是一種輕量級 PCIe 功能,可以與物理功能以及與同一物理功能關聯的其他 VF 共享一個或多個物理資源。==VF 僅允許擁有用于其自身行為的配置資源。==一個 具備SR-IOV能力的設備可以被配置成被枚舉出多個Virtual Functions(數量可控制),而且每個Function 都有自己的完整有BAR的配置空間。VMM可以把一個或者多個VF 分配給VM。
三、疑難雜癥
PCIE4到PCIE5變化點
除了 PCI Express Gen 5 版本附帶的更嚴格的抖動要求、信道損耗預算約束以及通道電壓和時間裕度要求外,速度提高還需要額外的物理層更改,同時還包括其他改進,以保持與以前的 PCIe 版本所需的向后兼容性。
有序集更改是 PCI Express 5.0 規范版本附帶的一項重要修改。EIEOS 有序集用于幫助退出電氣空閑狀態。在 PCIe Gen 5 慣例中,用于每個 PCIe 4.0 有序對的熟悉的 16 個 0 和 1 的模式變成了對每個通道重復的 32 個 0 和 1。背靠背(重復)EIEOS 信號是 PCIe 5.0 協議的額外更改。數據流起始有序集 (SDS) 也已更新,因此接收方可以清楚地區分 PCI Express Gen 5 數據流起始點。
訓練序列 (TS1/TS2) 受益于旨在促進 PCIe Gen 5 速度倍增的創新新選項。訓練序列是鏈路建立和均衡 (EQ) 的必要先導,但隨著有序集通過每個速度支持增量(從 2.5 GT/秒開始并逐步移動到 32.0 GT/秒 PCIe Gen 5 速度),訓練序列也可能導致延遲。為了解決這個難題,提供了EQ 旁路選項,以基本上“跳過”中間速度均衡級別,或者通過使用“無 EQ”選項立即轉換到 L0 活動數據傳輸狀態來完全省略均衡。
PCIe Gen 5 的改進型 TS1 和 TS2 也增加了新的字段,用于替代協議標識和增強的預編碼支持。一旦系統和設備之間的協商成功,鏈路就可以立即以支持的最高速度進入 L0 狀態,并開始使用協商的備用協議傳輸數據。如果替代協議協商失敗,系統可以快速恢復到主干 PCIe 5.0 協議。
PCIE5到PCIE6變化點
開發者需要考慮的PCIe 6.0的三個主要變化如下:
● 數據速率從32GT/s翻倍至64GT/s
● 從NRZ編碼轉換到PAM-4編碼,以及由此帶來的糾錯影響
● 從傳輸的可變大小TLP到固定大小FLIT
● 除了速度,PCIe 6.0還引入了L0p鏈路狀態,關于它的內容,我們將在介紹鏈路ASPM(L0,L1,L0s和L0p)中介紹。
Pcie bar 空間寄存器
如下圖標紅的兩部分是bar寄存器。
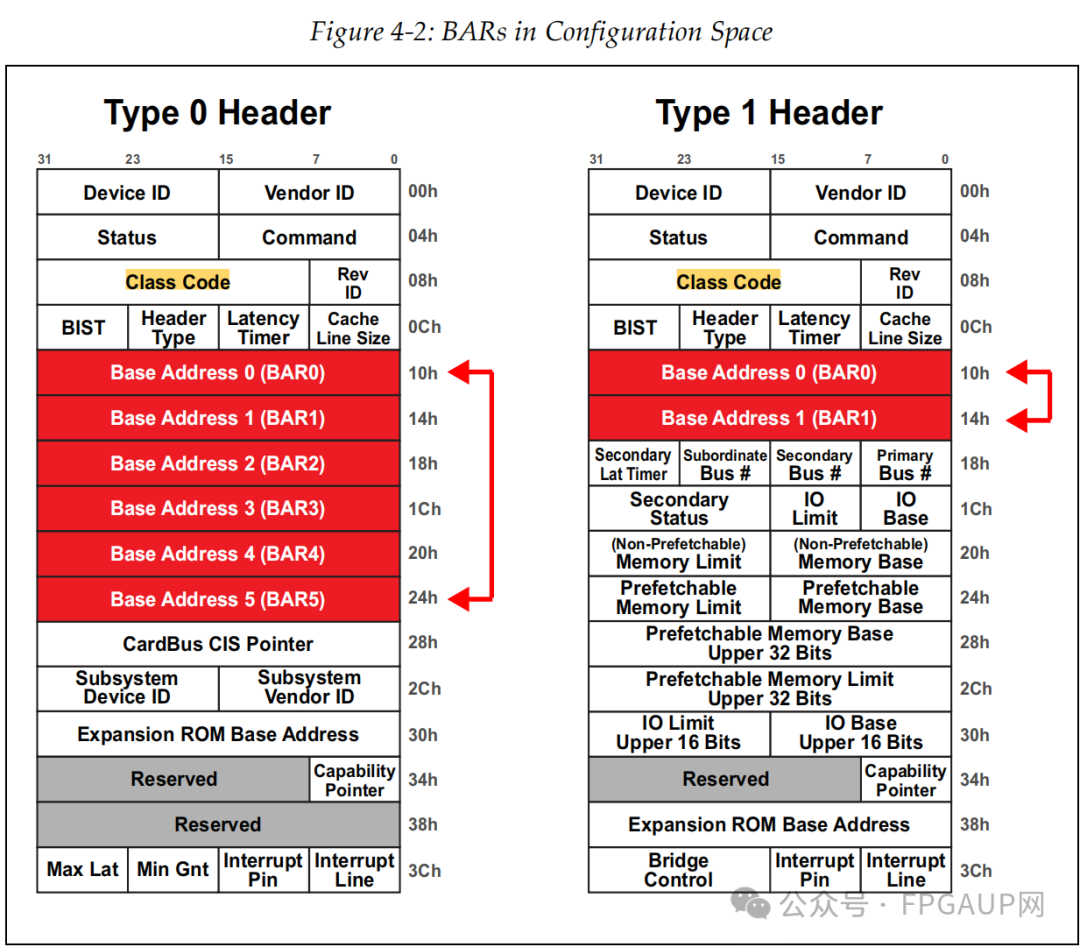
為什么需要bar寄存器:
一方面這還是和CPU、操作系統的機制有關,它們不允許PCI設備自己在內存中劃拉片地方供自己使用,而是必須由系統統一分配。
另一方面PCI設備需要一定內存空間來存儲自身需要的些數據,例如功能相關的配置數據,而且不同設備不同功能的情況下需要的空間大小還不一致,所以就有了bar寄存器了,用于對不同設備進行量身定制內存空間。
PCI設備有6個bar寄存器,可以啟用全部或其中幾個,一旦啟用,這個bar寄存器就與內存建立了關系,主機就可以根據BARs中所寫入的地址范圍進行訪問。任何時候,當設備發現一個請求事務的地址是映射到自己的一個BAR時,它就會接收這個請求事務,因為它自己就是這個請求的目標設備。
02bar寄存器如何使用:
根據上圖可知,type0和type1擁有的bar數量是不一樣的,為什么不一樣放在后面說,bar在使用上可分為三種,分別是
1、32bit內存地址空間請求
2、64bit內存地址空間請求
3、IO地址空間請求
但在配置機制上是一致的,均是分為三個步驟,
Step 1
主機發起配置請求向目標PCIE設備的目標bar寄存器,對這個bar寄存器進行寫 1操作。
Step 2
主機發起讀配置請求讀取目標PCIE設備的目標bar寄存器的值,由于有些bit 位主機是無法改寫的,在上電就強制為固定值了,所以主機回讀的值部分不是1。
Step 3
主機根據讀取的值判斷bar請求內存空間的大小并為其分配,并將起始地址寫入目標bar寄存器,這就完成了兩個功能,一是確定基地址,二是確定了尋址范圍。具體是如何實現的呢?接下來以32bit內存地址空間請求為例詳細看下bar寄存器的結構

這里提到了預取和非預取,對于PCI來說,預取功能能提升性能,但在PCIE上不是很明顯,只不過將此繼承了過來,所以可以先忽略,等后面用到了再說了。
03拿32bit的bar空間申請舉例:
bar寄存器的存在的目的是告訴使用者我需要多大的空間,在訴說之前自身肯定得先知道并做一定設置,這種設置呢就是將某些位寫0,且不可更改。
如下圖是32bit非預取內存請求的申請過程描述,申請4KB大小的空間。
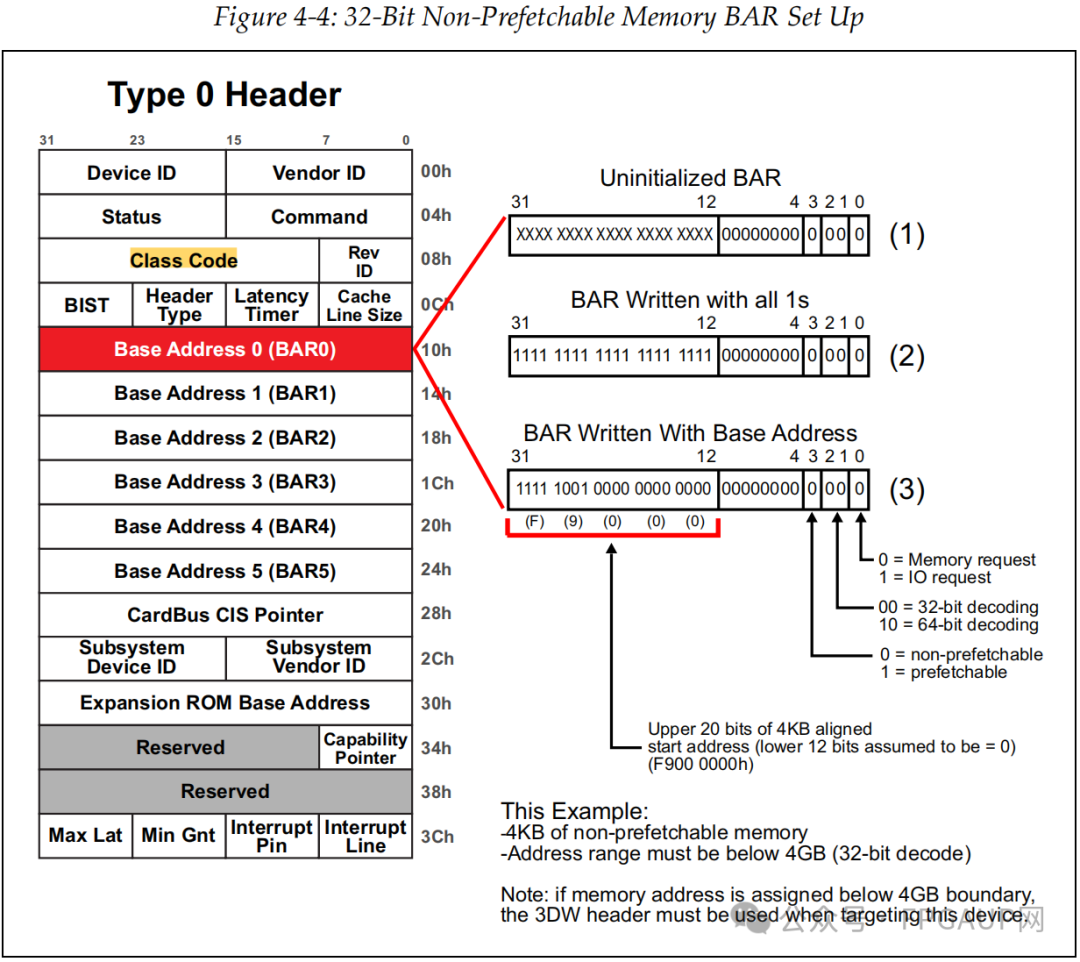
如上圖(1)所描述的“Uninitialized bar”,bit0bit3是固定內容,bit11bit4的預設0就是表示申請內存大小的,12bit寫0表示申請內存空間為4KB,因為2^12=4096嘛,如果bit13也是0,那就表示想要申請8KB的內存空間。
那么為啥要這樣搞呢?主機又是怎么知道的呢?首先說主機是怎么知道的,主機會對bar寄存器各個bit位都寫1(0XFFFFFFFF)然后再回讀。對于我們這個例子回讀內容就是0XFFFFF000,通過bit3~0知道了申請內存空間的屬性,又因為bit12是1,所以知道了申請內存大小位4KB。
隨后主機再把內存基地址寫入bar寄存器,例如下圖的0xF9000000,如此主機就知道了這個設備的對應功能的bar0申請4KB內存。
最后說,為什么要這樣做,在我看來,這樣做即實現了我們的目的,也節省了需要的配置字。我們需要告知主機需要多大的空間和屬性,可以單獨占一個字段,讓主機讀就行了。但再發TLP包時,主機尋址也需要知道目的地址,這樣還需要一個字段。現在將兩字段合一的,而且目的還實現了。
04另外兩種bar寄存器的使用
如下圖是對64bit的設置,申請一個64MB內存大小的過程,與32bit相比就是基地址更大些。
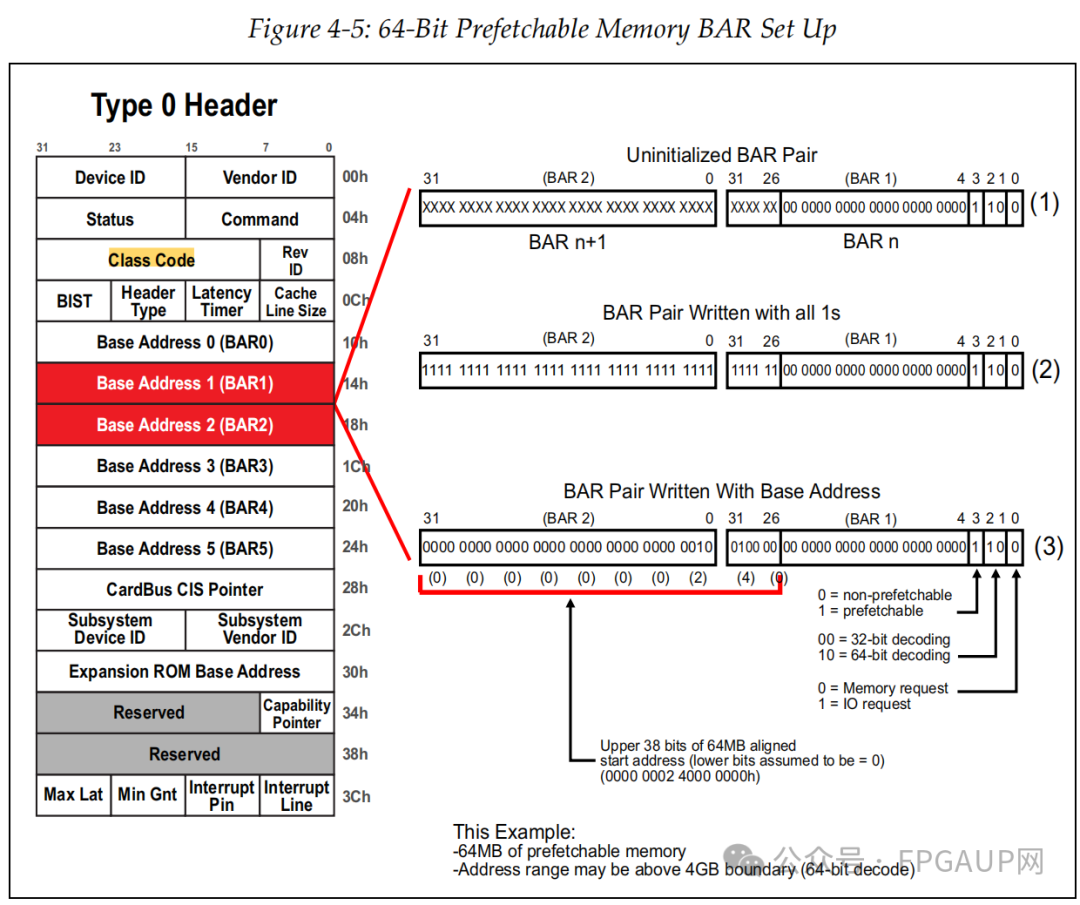
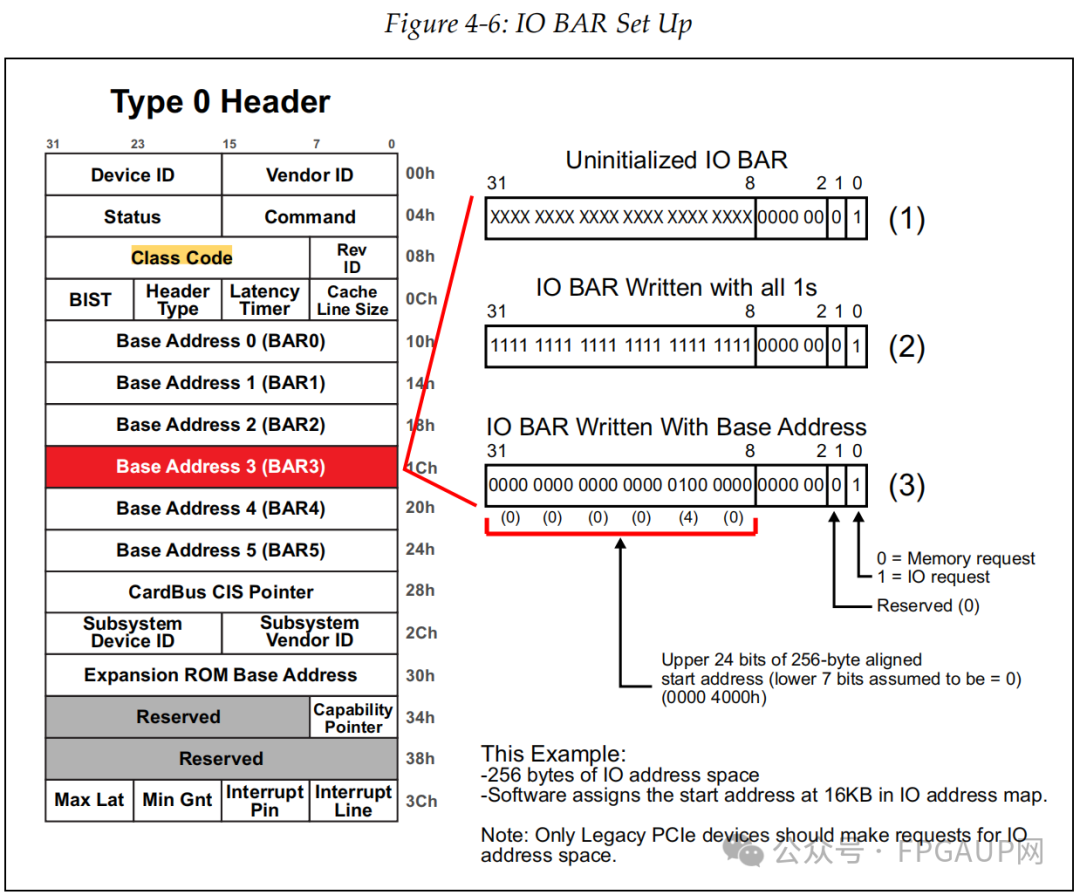
入下圖是申請一個256Byte大小的過程,也就是bit8~2是固定為0,其中bit0為1表示是IO請求。
參考資料:bar空間介紹
ATS機制
ATS全稱是Address Translation Service,顧名思義,就是一個地址翻譯服務機制。PCIe下的ATS是以CPU為中心,PCIe總線上的各個設備可以通過ATS機制向主機申請未翻譯地址對應的物理地址映射以及響應的屬性、權限等信息。
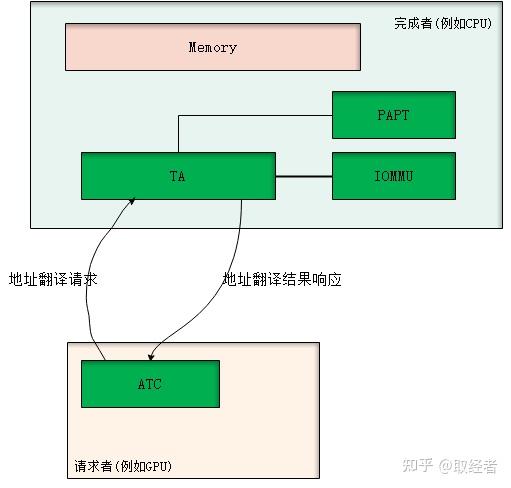
一般地,在PCIe體系下,發起地址翻譯請求的設備叫請求者,也叫client,而處理地址翻譯請求的(即CPU)叫完成者,也叫home。因此,對于地址翻譯請求的流程如下:
1、client有數據訪問需求(或者是prefetching引入的需求);
2、client發出翻譯請求給home側,攜帶需要訪問的虛擬地址空間塊和響應屬性、提示信息;
3、home側進行翻譯,之后返回翻譯結果給client;
4、client在本地cache翻譯結果;
5、client引擎發出數據訪問,查本地cache,直接發出查完后的結果訪問home側;
6、home側直接bypass TA,訪問home本地內存。

ATS機制想要解決的問題(優勢):
1、能夠分擔主機(CPU)側的查表壓力,特別是大帶寬、大拓撲下的IO數據流,CPU側的IOMMU/SMMU/VT-d的查表將會成為性能瓶頸,而ATS機制正好可以提供將這些查表壓力卸載到不同的設備中,對整個系統實現“who consume it, who pay for it”。
2、對于IO設備往CPU的數據流,其IOMMU/SMMU/VT-d的查表性能在整個IO性能中顯得極為關鍵,查表性能的好壞至今影響IO性能的好壞。而根據現今大量學術界和工業界的研究表明,決定查表性能的好壞的一個最為關鍵的點是TLB的預測。而像傳統PCIe IO數據流,在CPU側集中式做IOMMU/SMMU/VT-d的查表,對于其TLB的預測(prefetch)是很困難,極為不友好的。因為,很多不同workload的IO流匯聚到一點,對于TLB的預測的沖擊很大,流之間的干擾很大,很難做出準確的預測,從而TLB的命中率始終做不到太高,從而影響IO性能。而ATS的機制恰好提供了一個TLB的預測卸載到源頭去的機制,讓用戶(設備)自己根據自己自身的業務流來設計自己的預測策略,而且用戶彼此之間的預測模型不會受到彼此的影響,從而大大提高了用戶自己的預測的準確性。抽象來看,這時候的設備更像是CPU核,直接根據自身跑的workload來預測本地的TLB,從而提升預測性能,進而提升整系統的預測性能。
ATS機制就是一個分布式的地址翻譯系統,對于異構架構的地址問題也起到了很好的支持效果。例如,NVIDIA和IBM最近搞的NVLINK互聯CPU和GPU,其就是用了ATS來實現SVM,這個后續我想詳細介紹一下。
當然,ATS也會帶來如下兩個比較嚴重的問題:
1、安全問題。也就是有了ATS后,設備會直接發出PA來訪問CPU的內存空間,而CPU這邊將不再查頁表,從而也不再有地址訪問權限的檢查。因此,對于malicious設備,或者是被入侵的設備,又或者是設備自身設計的bug,其會發出PA訪問那些其沒有權限訪問或者是不屬于其的物理地址空間,從而帶來系統的isolation的破壞,系統安全的威脅等安全問題。現有機制下,目前還沒有解決辦法。但,本人有專利可以解決,而且本人也有更好的機制可以解決,目前保密,暫時不能公布。本人的專利的話,后面有時間可以寫一下。
2、無效化問題。也就是,在CPU側被cache的頁表發生變化(例如權限發生了變化,對應的PA需要回收SWAP等)的時候,此時CPU需要發出無效化指令給對應cache過的設備(ATC)來通知這件事,這會影響CPU回收頁表/物理空間的性能。這就意味著CPU側要實時跟蹤頁表被誰cache走了,維護這些信息也帶來了成本的開銷增長。
3、對設備的設計要求比較高,可以看到,ATS在某些時刻勢必增加了延時。而為了減少甚至消除影響,就需要設備設計出具有良好的ATC機制,包括ATC的預測、地址翻譯請求的長度、發送翻譯請求的時機等,這里的設計空間都比較大,對設備的要求都比較高。
前面的問題1和2是系統需要解決的功能問題,后者3是一個趨勢。我想象中的設備將會越來越智能,設備和CPU之間將會是點對點的平等計算地位,在異構體系下,它們是平等的計算關系。它們之間SVM、具有cache coherence等,從而第3看起來不是問題,而是趨勢。
ATS機制
參考資料
PCIE6.0差異點基礎介紹:
《PCIe 6.0概述》
NRZ編碼和PAM4編碼介紹:
《學會“NRZ”、“PAM4”,僅僅需要三分鐘!》
總結
提示:這里pcie bar總結:
以上就是今天要講的內容。








省賽回憶)
)









