Multi-Query 多路召回
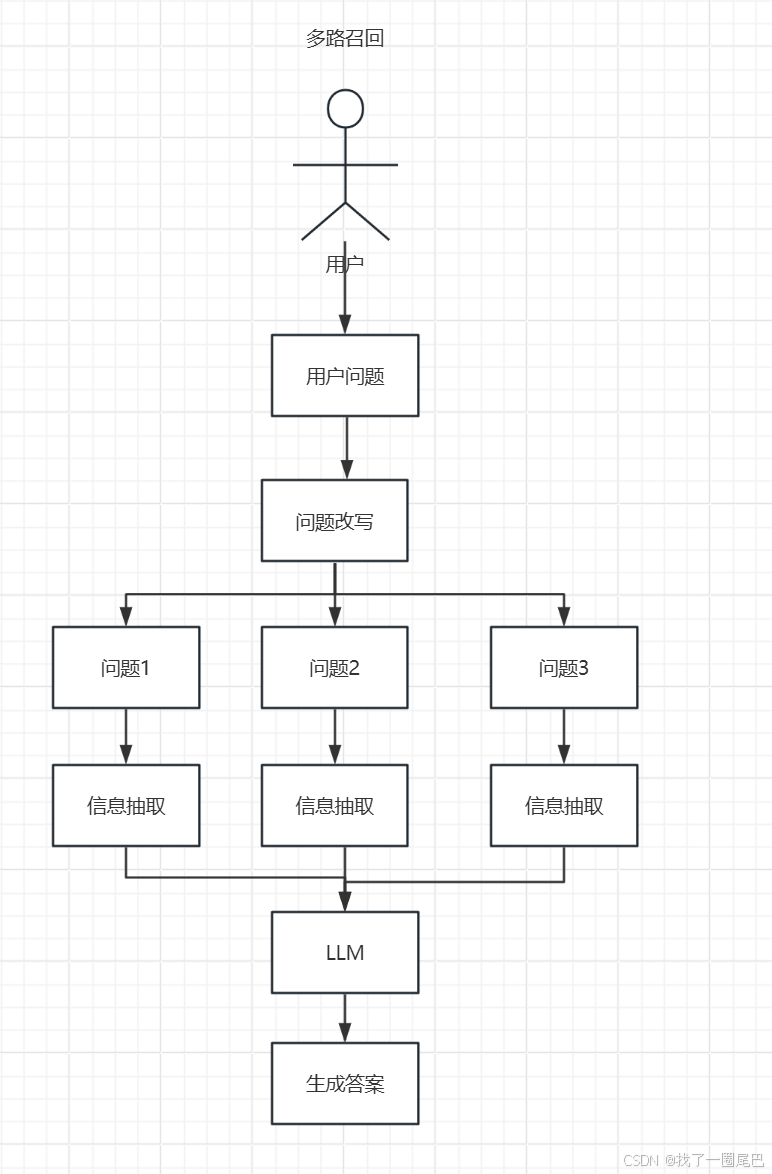
多路召回流程圖
? ? ? ? 多路召回策略利用大語言模型(LLM)對原始查詢進行拓展,生成多個與原始查詢相關的問題,再將原始查詢和生成的所有相關問題一同發送給檢索系統進行檢索。它適用于用戶查詢比較寬泛、模糊或者需要從多個角度獲取信息的場景。當用戶提出一個較為籠統的問題時,通過多路召回可以從不同維度去檢索相關信息,以全面滿足用戶需求。
多路召回的實現流程
-
利用 LLM 生成相關問題?:當用戶輸入原始查詢時,LLM 會對查詢進行深度語義解析,識別其中的關鍵詞、主題和潛在需求。
-
將所有問題發送給檢索系統?:完成相關問題的生成后,原始查詢與 LLM 生成的 N 個相關問題會一同被發送至檢索系統。
-
獲取更多檢索文檔?:通過 Multi-Query 多路召回,檢索系統能夠從向量庫中獲取到更多與用戶需求相關的文檔。傳統單一查詢檢索受限于用戶輸入的表述方式和詳細程度,可能會遺漏一些關鍵信息。而 Multi-Query 多路召回利用多個問題進行多次檢索,每個問題都能檢索到一批相關文檔,這些文檔集合相互補充,涵蓋了更廣泛的內容和角度。?
基于LangChain 框架的多路召回代碼實現
import logging
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import MultiQueryRetriever
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI# 加載文檔
def load_documents(file_path):try:loader = TextLoader(file_path, encoding='utf-8')return loader.load()except FileNotFoundError:print(f"錯誤:未找到文件 {file_path}")return []except Exception as e:print(f"加載文件時出現錯誤: {e}")return []# 分割文檔
def split_documents(docs, chunk_size=600, chunk_overlap=100):text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)return text_splitter.split_documents(docs)# 創建向量數據庫
def create_vectorstore(chunks, embedding_model):return Chroma.from_documents(documents=chunks, embedding=embedding_model, collection_name="multi-query")# 初始化檢索器
def initialize_retriever(vectorstore, llm):retriever = vectorstore.as_retriever()QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""You are an AI language model assistant. Your task is to generate 5 different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""")return MultiQueryRetriever.from_llm(prompt=QUERY_PROMPT,retriever=retriever,llm=llm,include_original=True)# 打印文檔
def pretty_print_docs(docs):for doc in docs:print(doc.page_content)if __name__ == "__main__":# 定義文件路徑TXT_DOCUMENT_PATH = "your_text_file.txt"# 初始化日志logging.basicConfig()logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)# 初始化嵌入模型embeddings_model = HuggingFaceEmbeddings()# 初始化大語言模型,這里使用 ChatOpenAI 作為示例,你可以根據需要替換llm = ChatOpenAI()# 加載文檔docs = load_documents(TXT_DOCUMENT_PATH)if docs:# 分割文檔chunks = split_documents(docs)# 創建向量數據庫vectorstore = create_vectorstore(chunks, embeddings_model)# 初始化檢索器retrieval_from_llm = initialize_retriever(vectorstore, llm)# 執行檢索unique_docs = retrieval_from_llm.invoke("詳細介紹DeepSeek")# 打印文檔pretty_print_docs(unique_docs)? ? ? ? 在 LangChain 框架中,MultiQueryRetriever 是實現多路召回功能的強大工具。它的核心原理是通過與精心設計的多路召回提示詞相結合,突破傳統單一檢索的局限。
????????具體來說,當用戶輸入查詢時,MultiQueryRetriever 會將該查詢傳遞給語言模型,在多路召回提示詞的引導下,語言模型會從多個維度和視角對原始查詢進行拓展,生成一系列相關的衍生問題。這些衍生問題與原始查詢一同組成查詢集合,隨后被發送至檢索系統。檢索系統基于這個查詢集合,在向量數據庫中執行多次檢索操作,每次檢索都對應一個查詢,如同從不同方向探索信息寶庫,從而從向量庫中召回更多與用戶需求潛在相關的文檔。這種方式能夠有效彌補用戶原始查詢可能存在的表述模糊、語義局限等問題,極大地豐富了檢索結果的數量和多樣性,為后續的信息處理和答案生成提供更全面、充足的素材,顯著提升了整個檢索增強生成系統的性能和用戶體驗,尤其適用于復雜、模糊或需要深度信息挖掘的查詢場景。
Decomposition 問題分解
????????問題分解(Decomposition)策略通過將復雜、模糊的用戶查詢拆解為多個更易處理的子問題,能夠顯著提升檢索的準確性與全面性,進而為生成高質量答案奠定基礎。問題分解策略的核心目標是:
-
提升召回率:通過子問題覆蓋更多相關文檔片段
-
降低處理難度:每個子問題聚焦單一語義單元
-
增強可解釋性:明確展示問題解決路徑
典型適用場景:
-
多條件復合問題("同時滿足A和B的方案")
-
多步驟推理問題("實現X需要哪些步驟")
-
對比分析問題("A與B的優劣比較")
常見分解策略
邏輯結構分解
????????將問題拆分為邏輯關聯的子模塊:
示例:
原問題:
"如何設計一個支持高并發支付的電商系統?"子問題分解:
電商支付系統的核心組件有哪些?
高并發場景下的數據庫選型建議
支付接口的限流熔斷方案
分布式事務一致性保障方法
時間序列分解
????????按時間維度拆分階段性問題:
示例:
原問題:
"從立項到上線的APP開發全流程"子問題分解:
移動應用立項階段的需求分析方法
敏捷開發中的迭代管理實踐
APP上線前的測試驗收標準
應用商店發布審核注意事項
多視角分解
????????從不同角度生成互補性問題:
示例:
原問題:
"深度學習在醫療影像中的應用"子問題分解:
(技術視角)醫療影像分析的常用深度學習模型架構
(臨床視角)三甲醫院實際部署案例中的準確率數據
(合規視角)醫學AI模型的法律監管要求
分解流程
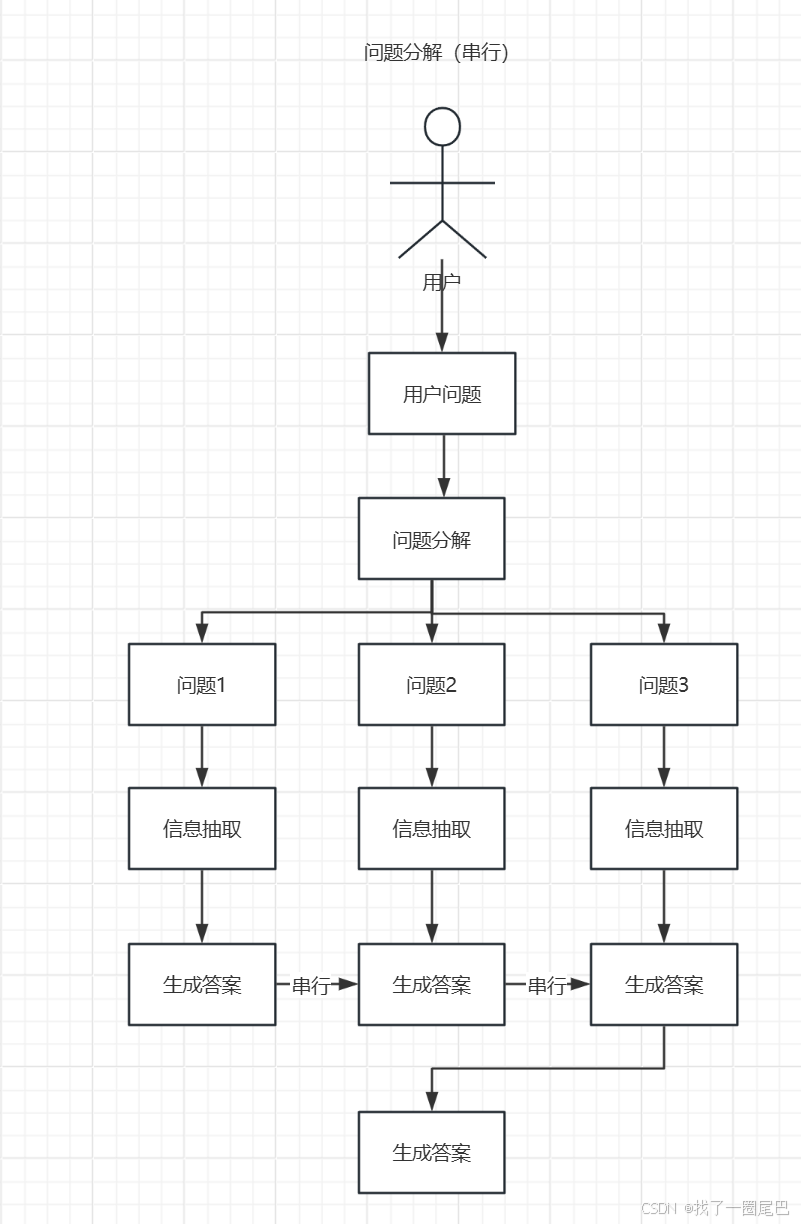
串行分解流程
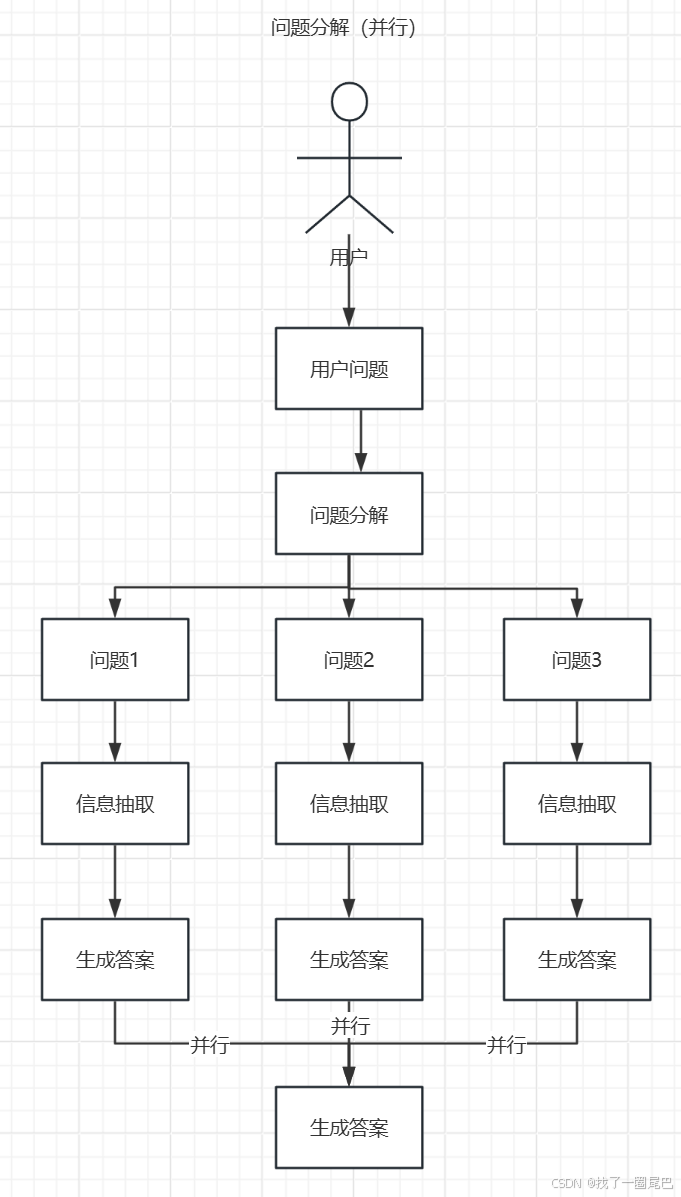
并行分解流程
技術實現方案
基于規則模板的分解
????????根據不同領域和問題類型,預先制定規則和模板。這種方式適用于結構化程度高、問題模式相對固定的場景,優點是簡單直接、執行效率高,但靈活性較差,難以應對復雜多變或新型的問題。
# 定義分解規則模板
DECOMPOSE_RULES = {"設計類問題": ["核心組件", "架構模式", "技術選型"],"比較類問題": ["優勢分析", "劣勢分析", "適用場景"]
}def rule_based_decompose(query, category):return [f"{query}的{aspect}" for aspect in DECOMPOSE_RULES.get(category, [])]基于LLM的智能分解
????????借助自然語言處理(NLP)技術,尤其是深度學習模型(如 Transformer 架構),對用戶問題進行深度語義分析。這種方法能夠處理復雜語義,適應性強,但對模型的訓練和計算資源要求較高。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplatedecompose_prompt = PromptTemplate.from_template("""將復雜問題拆分為3-5個原子子問題:要求:1. 每個子問題可獨立檢索2. 覆蓋原始問題的所有關鍵方面3. 使用明確的問題句式4. 你的目標是幫助用戶克服基于距離的相似性搜索的一些局限性輸入問題:{query}生成子問題:"""
)decompose_chain = LLMChain(llm=llm, prompt=decompose_prompt)# 執行分解
sub_questions = decompose_chain.run("如何構建企業級數據中臺?").split("\n")
# 輸出:["數據中臺的核心架構組成?", "數據治理的最佳實踐?", "..."]混合分解策略
????????結合規則與LLM的優勢:
def hybrid_decomposition(query):# 第一步:分類問題類型classifier_chain = LLMChain(...) category = classifier_chain.run(query)# 第二步:根據類型選擇策略if category in DECOMPOSE_RULES:return rule_based_decompose(query, category)else:return decompose_chain.run(query)層次化多階段分解
????????對于極其復雜的問題,采用分層次、多階段的分解策略。首先進行宏觀層面的初步分解,得到幾個主要的子問題方向,然后針對每個子問題再進行進一步細化分解。通過這種逐步細化的方式,確保問題的每個方面都能得到充分考慮,檢索也更加精準。
? ? ? ? 在這里,我讓DeepSeek 幫我生成了一個基于LangChain ,構建小說的代碼,使用的就是層次化多階段分解的策略。具體代碼如下:
from langchain.chains import SequentialChain, TransformChain
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
from typing import Dict, List# 第一階段:生成小說大綱
def create_outline_chain(llm):outline_template = """你是一個專業小說家,根據用戶需求創作小說大綱。
用戶需求:{user_input}
請按以下格式生成包含5個章節的小說大綱:
1. 章節標題:章節核心事件
2. 章節標題:章節核心事件
...
輸出示例:
1. 命運相遇:主角在拍賣會意外獲得神秘古劍
2. 真相初現:發現古劍與失傳王朝的關聯"""return LLMChain(llm=llm,prompt=PromptTemplate.from_template(outline_template),output_key="outline")# 第二階段:章節分解器
def chapter_decomposer(outline: str) -> List[Dict]:"""將大綱解析為章節結構"""chapters = []for line in outline.split("\n"):if "." in line:num, rest = line.split(".", 1)title, event = rest.split(":", 1) if ":" in rest else (rest.strip(), "")chapters.append({"chapter_num": num.strip(),"title": title.strip(),"core_event": event.strip()})return chapters# 第三階段:分章節內容生成
def create_chapter_chain(llm):chapter_template = """根據以下大綱創作小說章節內容:
整體大綱:
{outline}當前章節:{chapter_num} {title}
核心事件:{core_event}
要求:
1. 包含3個關鍵場景
2. 保持文學性描寫
3. 字數800-1000字章節內容:"""return LLMChain(llm=llm,prompt=PromptTemplate.from_template(chapter_template),output_key="chapter_content")# 構建完整工作流
class NovelGenerator:def __init__(self, llm):self.outline_chain = create_outline_chain(llm)self.chapter_chain = create_chapter_chain(llm)# 定義轉換鏈處理章節分解self.decompose_chain = TransformChain(input_variables=["outline"],output_variables=["chapters"],transform=chapter_decomposer)# 構建主流程self.master_chain = SequentialChain(chains=[self.outline_chain,self.decompose_chain,self._build_chapter_expansion()],input_variables=["user_input"],output_variables=["final_novel"])def _build_chapter_expansion(self):"""構建章節擴展子鏈"""def expand_chapters(inputs: Dict) -> Dict:full_novel = []for chapter in inputs["chapters"]:# 合并上下文context = {"outline": inputs["outline"],**chapter}# 生成單章內容result = self.chapter_chain(context)full_novel.append(f"## {chapter['chapter_num']} {chapter['title']}\n{result['chapter_content']}")return {"final_novel": "\n\n".join(full_novel)}return TransformChain(input_variables=["outline", "chapters"],output_variables=["final_novel"],transform=expand_chapters)def generate(self, user_input: str) -> str:"""執行完整生成流程"""return self.master_chain({"user_input": user_input})["final_novel"]# 使用示例
if __name__ == "__main__":from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model="gpt-4", temperature=0.7)generator = NovelGenerator(llm)novel = generator.generate("創作一部以民國古玩商人為背景的懸疑愛情小說")# 保存生成結果with open("novel_draft.md", "w", encoding="utf-8") as f:f.write(novel)基于知識圖譜的分解
? ? ? ? 我們可以利用知識圖譜中實體與關系的結構化信息,輔助問題分解。借助知識圖譜的語義關聯,使分解結果更具邏輯性和針對性。代碼示例如下:
from langchain.chains import LLMChain, TransformChain
from langchain.prompts import PromptTemplate
from typing import Dict, List# 示例知識圖譜(實際應用時可替換為Neo4j等圖數據庫接口)
MEDICAL_KNOWLEDGE_GRAPH = {"nodes": {"糖尿病": {"type": "疾病","properties": {"別名": ["消渴癥"],"分類": ["代謝性疾病"]},"relationships": [{"type": "治療方法", "target": "胰島素治療", "properties": {"有效性": "高"}},{"type": "并發癥", "target": "糖尿病腎病", "properties": {"概率": "30%"}},{"type": "檢查項目", "target": "糖化血紅蛋白檢測"}]},"胰島素治療": {"type": "治療方法","properties": {"給藥方式": ["注射"],"副作用": ["低血糖"]}}}
}class KnowledgeGraphDecomposer:def __init__(self, llm):# 實體識別鏈self.entity_chain = LLMChain(llm=llm,prompt=PromptTemplate.from_template("""從醫療問題中提取醫學實體:問題:{question}輸出格式:["實體1", "實體2", ...]"""),output_key="entities")# 子問題生成鏈self.decompose_chain = LLMChain(llm=llm,prompt=PromptTemplate.from_template("""基于知識圖譜關系生成子問題:原始問題:{question}相關實體:{entities}知識關聯:{kg_info}請生成3-5個邏輯遞進的子問題,要求:1. 覆蓋診斷、治療、預防等方面2. 使用明確的醫學術語3. 體現知識圖譜中的關聯關系輸出格式:- 子問題1- 子問題2"""),output_key="sub_questions")def query_kg(self, entity: str) -> Dict:"""知識圖譜查詢"""return MEDICAL_KNOWLEDGE_GRAPH["nodes"].get(entity, {})def build_pipeline(self):"""構建處理管道"""return TransformChain(input_variables=["question"],output_variables=["sub_questions"],transform=self._process)def _process(self, inputs: Dict) -> Dict:# 步驟1:實體識別entities = eval(self.entity_chain.run(inputs["question"]))# 步驟2:知識圖譜查詢kg_info = {}for entity in entities:node_info = self.query_kg(entity)if node_info:kg_info[entity] = {"屬性": node_info.get("properties", {}),"關聯": [rel["type"]+"→"+rel["target"] for rel in node_info.get("relationships", [])]}# 步驟3:子問題生成return {"sub_questions": self.decompose_chain.run({"question": inputs["question"],"entities": str(entities),"kg_info": str(kg_info)})}# 使用示例
if __name__ == "__main__":from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)decomposer = KnowledgeGraphDecomposer(llm)pipeline = decomposer.build_pipeline()# 執行問題分解result = pipeline.invoke({"question": "糖尿病患者應該如何進行治療?"})print("生成的子問題:")print(result["sub_questions"])混合檢索
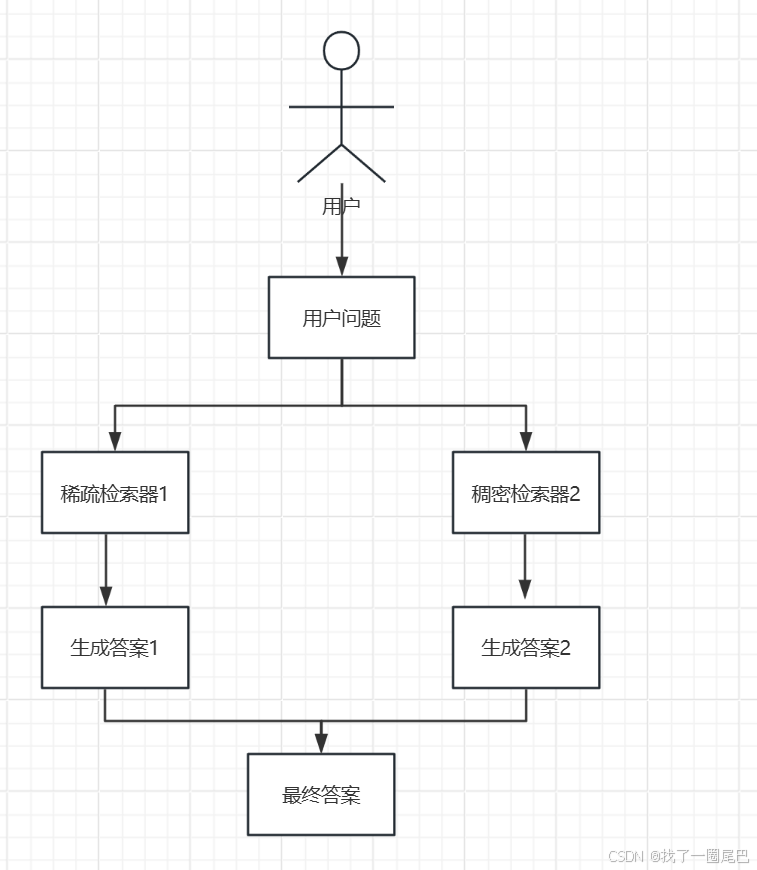
? ? ? ? 混合檢索流程? ? ? ?
????????混合檢索策略是一種將不同檢索方式優勢相結合的檢索方法,在實際應用中展現出強大的靈活性與高效性。其核心在于融合向量檢索(稠密檢索)和關鍵字檢索(稀疏檢索),常見的是以 BM25 關鍵詞檢索等稀疏檢索策略與向量檢索搭配使用。
????????向量檢索(稠密檢索)基于深度學習模型,將文本轉化為高維向量,通過計算向量之間的相似度,檢索出語義相近的文本。它擅長捕捉文本的語義信息,能理解用戶查詢背后的含義,即使查詢語句與文檔表述不完全一致,只要語義相似,也能實現精準檢索,適合處理語義復雜、模糊的查詢場景。而關鍵字檢索(稀疏檢索),如 BM25 關鍵詞檢索,依據用戶輸入的關鍵詞在文本中進行匹配,通過統計關鍵詞在文檔中的出現頻率、位置等信息,評估文檔與查詢的相關性。這種方式簡單直接,對結構化數據、精確匹配的檢索需求有很好的效果,能夠快速定位包含特定關鍵詞的文檔。
????????以下是一段基于BM25 檢索結合向量檢索的代碼示例:
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever# 假設這些函數和變量已經定義
def pretty_print_docs(docs):for doc in docs:print(doc.page_content)def perform_hybrid_retrieval(chunks, vector_retriever, query):try:# BM25關鍵詞檢索BM25_retriever = BM25Retriever.from_documents(chunks, k=3)BM25Retriever_doc = BM25_retriever.invoke(query)print("BM25關鍵詞檢索結果:")pretty_print_docs(BM25Retriever_doc)# 向量檢索vector_retriever_doc = vector_retriever.invoke(query)print("\n向量檢索結果:")pretty_print_docs(vector_retriever_doc)# 向量檢索和關鍵詞檢索的權重各0.5,兩者賦予相同的權重retriever = EnsembleRetriever(retrievers=[BM25_retriever, vector_retriever], weights=[0.5, 0.5])ensemble_result = retriever.invoke(query)print("\n混合檢索結果:")pretty_print_docs(ensemble_result)except Exception as e:print(f"檢索過程中出現錯誤: {e}")????????在這里,我們運用EnsembleRetriever方法實現了高效的混合檢索策略。具體而言,通過將基于 BM25 算法的關鍵詞檢索器BM25_retriever與向量檢索器vector_retriever相結合,并為二者賦予相等的權重 0.5,使得檢索過程既能發揮 BM25 關鍵詞檢索在精確匹配方面的優勢,快速定位包含目標關鍵詞的文檔;又能借助向量檢索在語義理解層面的特長,捕捉語義相近的相關內容。這種強強聯合的方式,最終整合出兼具準確性和全面性的混合檢索結果,有效提升了檢索系統對復雜查詢的處理能力和響應質量。









省賽回憶)
)








