????????前面在討論專家系統時曾經說過,為了使計算機具有自動獲取知識的能力,除了應使它具有學習能力外,還應使它具有能識別諸如文字、圖形、圖象、聲音等的能力,計算機的這種識別能力是模式識別研究的主要內容。當然,模式識別的研究并不僅僅只是為了實現知識的自動獲取,這只是它的應用之一。模式識別作為人工智能的一個重要研究領域,其研究的最終目標在于實現人類識別能力在計算機上的模擬,使計算機具有視、聽、觸等感知外部世界的能力。就目前而言,主要是開展機器視覺及機器聽覺的研究,逐步提高計算機的識別能力。模式識別的研究涉及到數學、圖象處理等多個學科,同時它又正處于發展之中,新的研究不斷充實著它的內容,本文先只對其基本概念及主要的實現技術進行討論。
????????全文需要線性代數基礎,可以看我文章:人工智能中的線性代數基礎詳解-CSDN博客?
一、什么是模式識別
????????從字面上就可以看出,模式識別(pattern?recognition)是研究如何對模式進行識別的一門學科。下面首先討論模式、模式類的有關概念,然后再給出模式識別的一般描述。
(一)模式(Pattern)
1. 基本思想與定義
????????物都具有不同的特征,包括物理特征及結構特征。由此使人們想到,如果能把事物的關鍵特征抽取出來,以不同的特征組合代表不同的事物,并且用適當的形式表示出來,這樣就有可能使計算機具有識別能力,使它能區分不同的事物。像這樣用事物的特征所構成的數據結構就稱為相應事物的模式,或者說模式是對事物定量的或結構的描述。
????????基本思想:模式是對客觀事物特征的結構化描述,其核心在于通過可觀測的特征集合刻畫事物的本質屬性。模式識別的核心問題是如何從復雜數據中提取具有區分性的模式,并利用這些模式實現對未知樣本的分類或描述。
????????定義(基于王永慶《人工智能原理與方法》拓展):設?X?為樣本空間,![]() ?為單個樣本,其中
?為單個樣本,其中為第?i?個特征。模式是一個映射
![]() ,將樣本映射到特征空間P中的一個結構化表示,滿足:
,將樣本映射到特征空間P中的一個結構化表示,滿足:
![]()
其中為特征提取函數,m?為特征維度。模式的本質是通過特征變換實現數據降維與語義抽象。
2. 模式分類
????????從不同角度進行劃分,模式可有不同的分類方法。例如,可根據其特征值是數值型數據還是非數值型數據,把模式分為數值式的模式及非數值式的模式;可根據其特征值是否為精確表示,把模式分為精確表示的模式與不精確表示的模式(對于用非數值量表示的特征值,在進行識別時可進行適當的變換,例如對“高”、“甜”等這些模糊概念可用模糊集把它們表示出來);可根據相應事物是簡單的還是復雜的,把模式分為簡單模式與復雜模式。所謂簡單模式,是指它所對應的事物可被作為一個整體看待,無須對其作進一步的細分就可根據其特征對它進行識別,對于這樣的模式,一般用上述的特征向量就可對它進行表示。所謂復雜模式,是指它所對應的事物是由若干部分組成的,各部分間存在確定的結構關系。當然,簡單與復雜是相對的,兩者之間并不存在一個明確的界限,在確定一個模式是簡單模式或復雜模式時,一方面可根據相應事物的屬性,另一方面還可根據應用的實際需要以及應用時所采用的處理方法。
????????另外,若按事物的性質劃分,模式又可分為具體模式和抽象模式這兩類。文字、圖象、聲音等都是具體的事物,它們通過對人們的感覺器官的刺激而被識別,相應的模式稱為具體模式;思想、觀念、觀點等是抽象的事物,相應的模式稱為抽象模式。模式識別主要是研究對具體模式的識別,關于抽象模式的研究被歸人哲學、心理學等的范疇。就具體模式而言,按其獲取的途徑不同又可分為以下幾類:
(1)視覺模式。這是通過視覺器官及視覺系統獲得的模式,主要有圖象(指二維映象,如
圖片等)、圖形(指由線條構成的視覺形象,如三角形、圓等幾何圖形)、物景(指三維視覺對象,如房子、樹木等)。
(2)聽覺模式。這是通過聽覺器官及聽覺系統獲得的模式,主要有語音模式(主要指人類
的自然語言)、音響模式(指由樂器、車輛、機器發出的音響等)。
(3)觸覺模式。這是通過觸覺器官所獲得的感覺模式,如形體、光滑度等。
????????其它還有味覺、嗅覺等感覺模式。由于條件的限制,目前它們還未被作為研究對象。鑒于人們對外部信息主要是通過視覺器官及聽覺器官獲得的,所以當前模式識別主要是開展對視覺模式及聽覺模式識別的研究。
3. 表示形式與實現過程
模式的表示形式于識別方法有關。
表示形式:
(1)向量表示:最常見形式,如![]() ,適用于統計模式識別(如圖像灰度向量)。
,適用于統計模式識別(如圖像灰度向量)。
(2)結構化表示:樹、圖等(如句法模式識別中的符號串?表示正則語言)。
(3)張量表示:高維數據(如圖像立方體![]() )。
)。
實現過程(以圖像模式為例):
(1)數據采集:獲取圖像像素矩陣![]() 。
。
(2)特征提取:
1)統計特征:灰度均值![]() ,方差
,方差![]() 。
。
2)結構特征:邊緣檢測(如Sobel算子)得到邊緣圖?E。
(3)模式構建:將特征級聯為向量![]() ,其中vec(·)?表示矩陣向量化。
,其中vec(·)?表示矩陣向量化。
4. 算法描述
模式構建的核心算法可分為兩類:統計模式算法和結構模式算法。
統計模式算法:通過概率分布建模特征空間。
示例:主成分分析(PCA)
輸入:樣本矩陣![]() (n?個樣本,d?維特征)
(n?個樣本,d?維特征)
(1)標準化:![]() ,其中
,其中![]() 。
。
(2)計算協方差矩陣:![]() 。
。
(3)特征分解:![]() ,取前?m?個主成分?U_m。
,取前?m?個主成分?U_m。
(4)模式變換:![]() 。
。
結構模式算法:通過形式語言理論建模模式結構。
示例:正則文法模式生成
文法![]() ,其中
,其中![]() ,起始符?S,規則
,起始符?S,規則![]() 。生成模式集合為
。生成模式集合為![]() 。
。
5. 具體示例:手寫數字 “5” 的模式表示
流程說明:
(1)圖像輸入:28×28像素灰度圖I。
(2)預處理:二值化(閾值τ=128)得到?![]() 。
。
(3)特征提取:
1)統計特征:前景像素占比![]() 。
。
2)幾何特征:重心坐標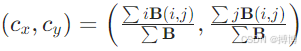 。
。
3)方向特征:邊緣方向直方圖(8 個方向)。
(4)模式向量:![]() 。
。
(二)模式類(Pattern Class)
1.定義:
具有相同本質屬性的模式集合,記為?ω_k,其中?k=1,2,...,K?為類別標號。數學上,模式類是特征空間P?的一個劃分:![]()
例如:“桌子”就是有方桌、圓桌、課桌、辦公桌等這些具體模式所構成的模式類。
2.分類依據:
(1)統計相似性:同類模式在特征空間中服從相近的概率分布![]() 。
。
(2)結構等價性:同類模式滿足相同的句法規則(如正則語言中的等價類)。
3.示例:手寫數字分類的模式類
ω_0: 所有表示“0”的模式集合,特征空間中表現為中心空洞、環形結構。
ω_5: 所有表示“5”的模式集合,特征空間中表現為上半部分折線、右下彎勾。
(三)模式識別(Pattern Recognition)
1.定義:
通過對已知模式類的學習,構建分類器或描述器,實現對未知模式的類別判定或結構分析。形式化表示為映射![]() ,滿足:
,滿足:![]()
其中![]() ?為后驗概率(統計方法),或?h(p) =?符合句法規則的類別(結構方法)。
?為后驗概率(統計方法),或?h(p) =?符合句法規則的類別(結構方法)。
2.核心任務:
(1)分類(Classification):離散類別判定(如垃圾郵件分類)。
(2)回歸(Regression):連續值預測(如語音信號參數估計,廣義模式識別)。
(3)聚類(Clustering):無監督模式類發現(如用戶行為分群)。
3.衡量模式識別的主要性能指標
????????衡量模式識別的主要性能指標是正確識別率和識別速度。從實用角度考慮,還有系統的復雜性、可靠性等。但是,要使這幾方面都達到最優是非常困難的。這是因為世界上的事物是很復雜的,種類繁多,結構千變萬化,再加上各種因素的干擾、影響,就使得正確的識別十分困難。另外,人們對模式識別的研究雖已有較長的歷史,但至今仍沒有能夠全面地適用于分析和描述各種模式的嚴謹理論。某些技術可能在某些情況下識別效果較好,但在其它情況下就不一定能夠達到同樣的效果,而且一個識別效果好的方法往往是以較高的復雜性及較大的時間、空間開銷為代價的。
????????由于各種隨機干擾、噪聲等造成的觀察特征的隨機性及不確定性,以及事物本身所具有的模糊性等,致使模式類別與模式特征之間的對應關系經常具有某種程度的不確定性。因此,模式識別通常都是在一定誤差的條件下實現的,我們的任務是盡可能地減小這種誤差,使其滿足一定的閾值條件,但很難完全消除它。
二、模式識別的一般過程
(一)模式信息采集
1.定義:
通過傳感器獲取目標對象的原始數據,形成觀測空間X。
2.技術手段:
(1)視覺采集:攝像頭(圖像?![]() )、3D 掃描儀(點云
)、3D 掃描儀(點云![]() )。
)。
(2)聽覺采集:麥克風(語音信號![]() )。
)。
(3)多模態融合:同時采集圖像、語音、慣性數據(如自動駕駛傳感器組)。
3.數學模型:
設傳感器響應函數為![]() ,其中Ω為物理世界觀測對象,采集過程可表示為:
,其中Ω為物理世界觀測對象,采集過程可表示為:
![]() ,這里n?為噪聲向量,滿足
,這里n?為噪聲向量,滿足![]() (高斯噪聲假設)。
(高斯噪聲假設)。
4.示例:人臉識別的圖像采集
攝像頭接收人臉反射光,生成 RGB 圖像![]() 。
。
同步采集深度信息(如有),形成點云C。
(二)預處理(Preprocessing)
目標:改善數據質量,消除噪聲和無關變異,形成標準化特征空間。
1. 降噪處理
(1)均值濾波:![]() ,其中
,其中![]() 為?M×N?鄰域窗口。
為?M×N?鄰域窗口。
(2)中值濾波:![]()
2. 歸一化
(1)尺度歸一化:![]()
(2)標準化(Z-score):![]()
3. 幾何校正(圖像為例)
(1)旋轉校正:通過霍夫變換檢測直線,計算旋轉角度θ,應用仿射變換:
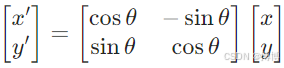
4.示例:手寫數字預處理流程
(1)二值化:![]() ?若
?若![]() ,否則 0。
,否則 0。
(2)尺寸歸一化:將任意大小圖像縮放至固定尺寸(如28×28)。
(3)重心對齊:平移圖像使重心位于中心?(14,14)。
(三)特征或基元抽取(Feature/Primitive Extraction)
1. 特征抽取(統計模式)
定義:從預處理后的數據中提取最具區分性的特征子集,形成特征空間F。
(1)特征選擇(Feature Selection)
從?d?維原始特征中選擇?m ??d?維子集,常用方法:
1)過濾法(Filter):基于統計指標(如信息增益):![]()
其中?H(C)?為類別熵,![]() 為條件熵。
為條件熵。
2)包裹法(Wrapper):以分類器性能(如準確率)為評價指標,搜索最優子集。
(2)特征提取(Feature Extraction)
通過變換生成新特征:
1)線性變換:主成分分析(PCA), Fisher 線性判別(FLD):
最大化類間散度![]() ,
,
最小化類內散度![]() ,
,
最優變換矩陣![]() 。
。
2)非線性變換:核主成分分析(KPCA),通過核函數![]() 將數據映射到高維特征空間。
將數據映射到高維特征空間。
2. 基元抽取(結構模式)
定義:將復雜模式分解為最小組件(基元,Primitive),如句法模式識別中的符號(a, b, ...)或圖像中的邊緣段(→, ↑, ↙)。
基元定義流程:
(1)邊緣檢測:Canny算子生成邊緣圖E。
(2)基元分類:根據邊緣方向(0°, 45°, 90°, 135°)定義4種基元?{e_1, e_2, e_3, e_4}。
(3)基元編碼:將每個邊緣段映射到對應基元符號,形成符號串?e_2 e_1 e_4 e_3 ...。
示例:字符“A”的基元表示
基元集合:{水平線段, 左斜線, 右斜線},結構規則:右斜線在左斜線右側,水平線段連接兩斜線頂端。
(四)模式分類(Pattern Classification)
目標:利用訓練數據構建分類器![]() ,實現對測試樣本的類別判定。
,實現對測試樣本的類別判定。
1. 分類器設計范式
(1)統計分類器
貝葉斯分類器:
1)基于貝葉斯定理:![]()
若假設特征獨立(樸素貝葉斯):![]()
2)支持向量機(SVM):尋找最大間隔超平面![]() ,滿足:
,滿足:
![]()
?為類別標簽。
(2)結構分類器
句法模式識別:
通過文法推斷構建自動機,如有限狀態機(FSM),輸入基元符號串,若被FSM接受則屬于某類。
示例:正則語言分類器 識別符號串是否符合?(ab)*:
1)狀態:q_0(初始),?q_1(接收 a),?q_2(接收 b)
2)轉移:![]() (錯誤狀態)
(錯誤狀態)
3)終止狀態:q_0(空串有效),?q_2(無效)
2. 分類流程示例:基于SVM的手寫數字分類
訓練階段:
(1)數據準備:MNIST數據集,60000個訓練樣本,每個樣本784維特征(28×28像素灰度值)。
(2)特征預處理:標準化至?[0,1]。
(3)模型訓練:
1)核函數選擇:徑向基函數(RBF)![]()
2)超參數優化:網格搜索γ?和懲罰因子?C。
(4)決策函數:![]()
測試階段:
(1)輸入未知數字圖像,預處理為784維向量x。
(2)計算與支持向量的RBF核值,代入決策函數。
(3)輸出類別標簽(0-9)。
三、理論拓展:模式識別的數學基礎
1. 特征空間的度量理論
設![]() ,常用度量:
,常用度量:
(1)歐氏距離:![]()
(2)馬氏距離:![]() ,考慮特征相關性。
,考慮特征相關性。
2. 分類錯誤率的理論下限
貝葉斯錯誤率![]() ,滿足:
,滿足:![]()
其中?P_e(h)?為任意分類器?h?的錯誤率。
3. 結構模式的形式語言理論
喬姆斯基文法層次中,模式識別常用:
(1)3 型文法(正則文法):對應有限狀態機,處理符號串模式(如DNA序列分類)。
(2)2 型文法(上下文無關文法):對應下推自動機,處理樹形結構(如蛋白質二級結構分析)。
四、應用與挑戰
1. 典型應用
(1)計算機視覺:目標檢測(YOLO模型,結合統計特征與深度學習)。
(2)自然語言處理:句法分析(結構模式識別,依存樹解析)。
(3)生物醫學工程:心電圖分類(特征提取結合隱馬爾可夫模型)。
2. 核心挑戰
(1)小樣本學習:如何在少量訓練數據下構建魯棒分類器(元學習、遷移學習)。
(2)可解釋性:深度學習模型(如神經網絡)的“黑箱”問題,需結合結構模式的符號解釋。
(3)抗干擾性:對抗樣本攻擊下的模式識別魯棒性(對抗訓練、防御性蒸餾)。
五、總結
????????模式識別作為人工智能的核心技術,通過“信息采集 - 預處理 - 特征抽取 - 分類”的標準流程,實現從數據到知識的轉化。統計方法與結構方法的結合、傳統算法與深度學習的融合,正推動模式識別在復雜場景中的應用。未來研究需聚焦于魯棒性、可解釋性和小樣本學習,以應對現實世界的多樣化挑戰。

:組網邏輯)


)





)



--文件與文件描述符fd)




————芯片鎖死問題及成功解鎖流程)