1, 主成分分析PCA
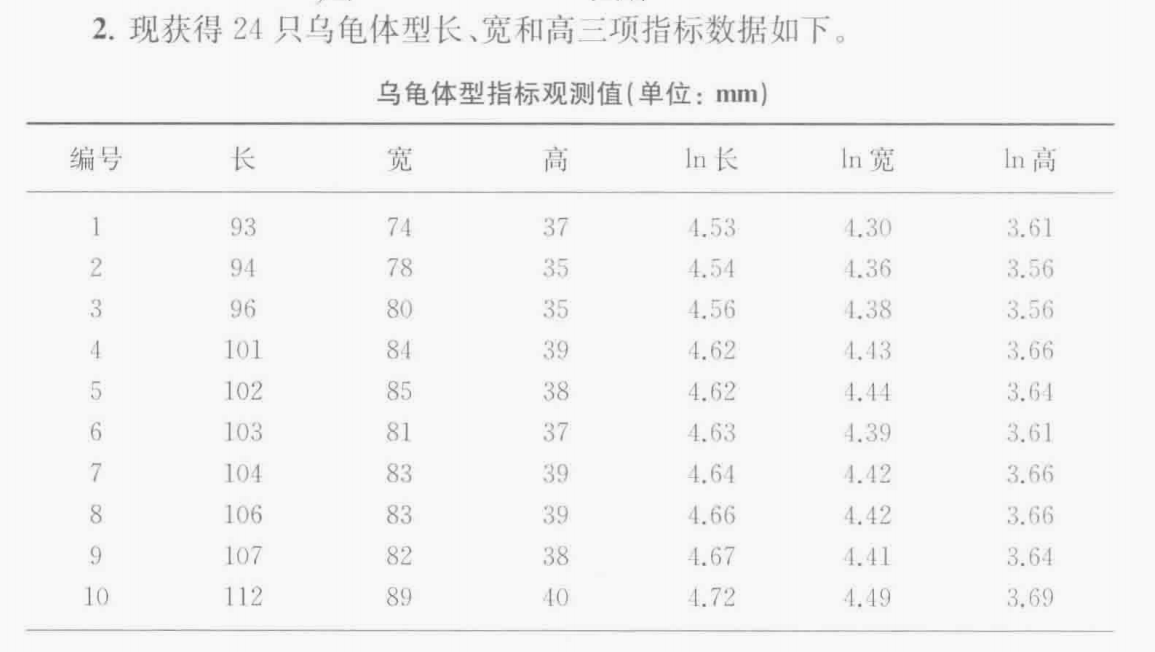
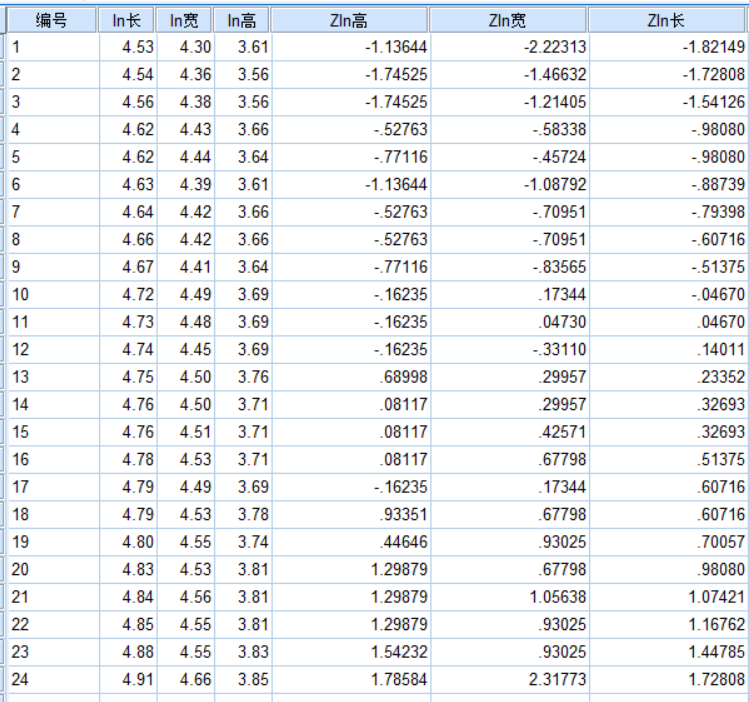
我們只要對數化的變量數據:
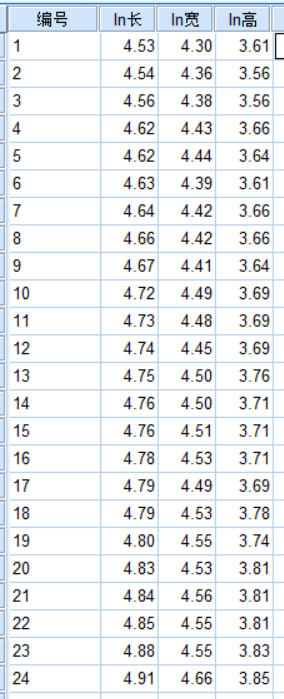
(1)對數據進行標準化處理:
選擇【分析】—【描述統計】—【描述】
添加要標準化的變量,勾選【將標準化值另存為變量(Z)】,再點確定
SPSS軟件本身不提供主成份分析,我們的操作是利用因子分析的一些功能完成主成分分析,操作如下:
選擇【分析】—【降維】—【因子】
將標準化后的變量選入變量框中:
點擊【描述】進入描述框,勾選【系數】,再點擊【繼續】【確定】

此處多做的KMO檢驗以及巴特利特球形度檢驗:



結果如下:
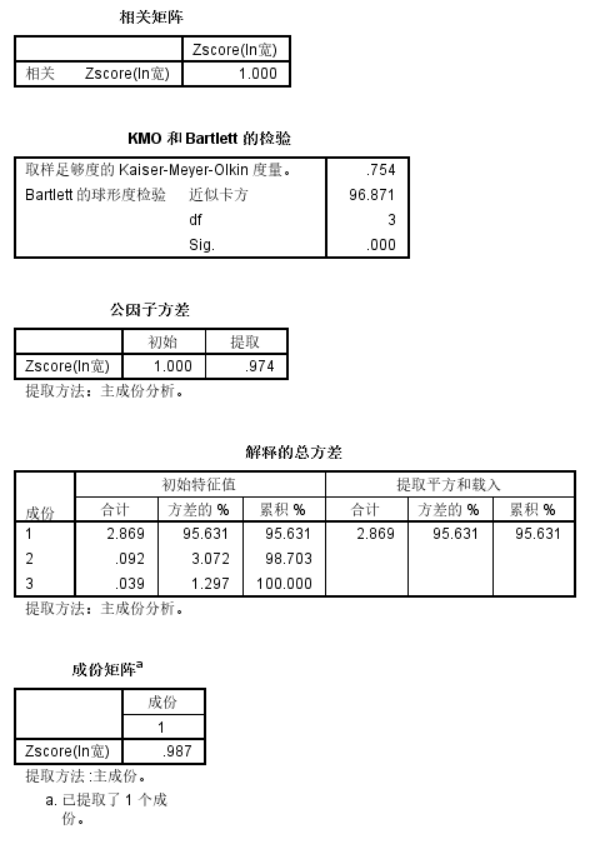
我們的數據在做了KMO檢驗以及巴特利特球形度檢驗之后發現:
數據質量一般,但是相關。
相關性分析上只有1個ln寬對數寬變量:
主成分個數提取原則主要包括兩個標準,第一個是為主成分對應的特征值大于1的前m個主成分,第二個是前m個主成分累計貢獻率大于85%。
對于第一個原則:特征值在某種程度上可以被看成是表示主成分影響力度大小的指標,如果特征值小于1,說明該主成分的解釋力度還不如直接引入一個原變量的平均解釋力度大,因此一般可以用特征值大于1作為納入標準。對于第二個原則,累計貢獻率反映了前m個主成分,反映了原來總體樣本85%以上的信息,基本反應了原來數據的總體情況。
如果是堅持特征至大于1的原則,那么我們只選擇主成分1,
如果堅持累計貢獻率大于85%的原則,那么我們還是選擇主成分1,
所以我們只選擇1個主成分,也就是看ln寬也就是對數寬就可以就夠決策
參考:https://blog.csdn.net/My_daily_life/article/details/121333063
2,判別分析
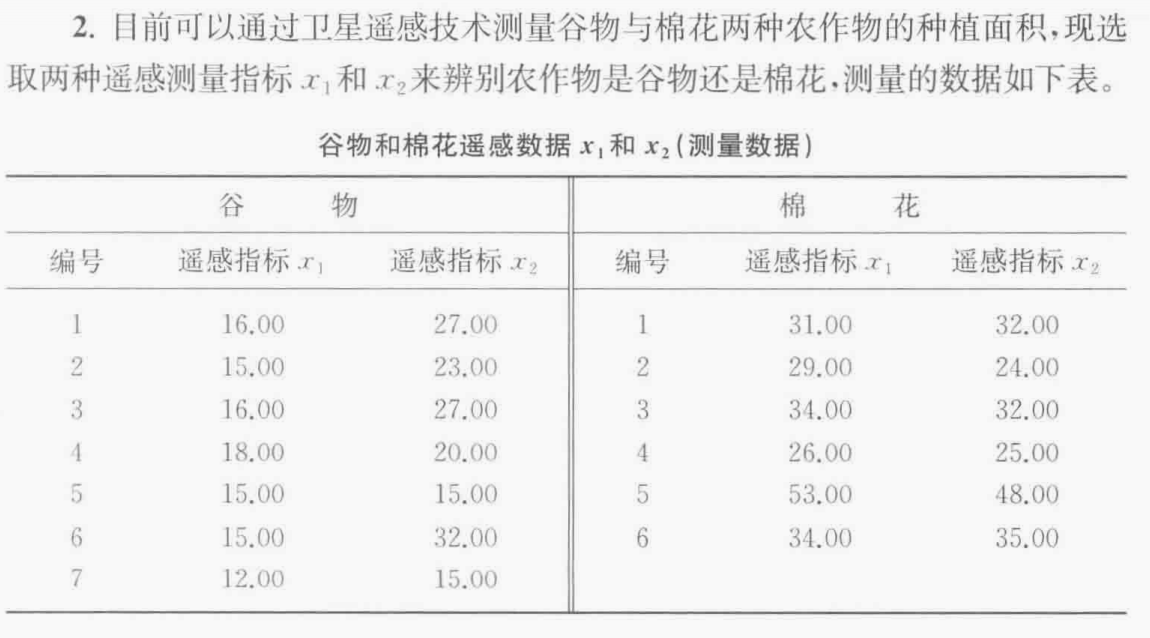

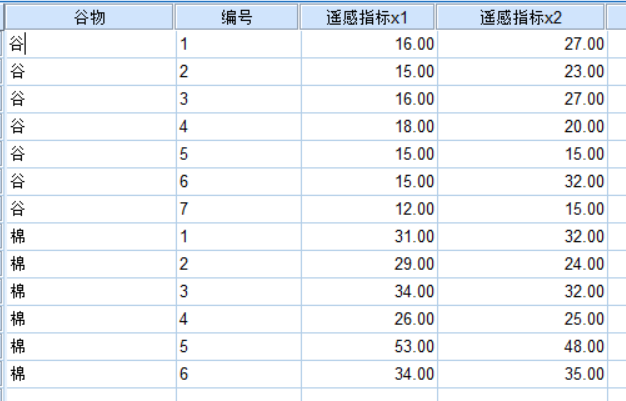
注意:名義自變量必須被重新編碼為啞元變量或對比變量!

點擊分析,進入分類,選擇判別分析
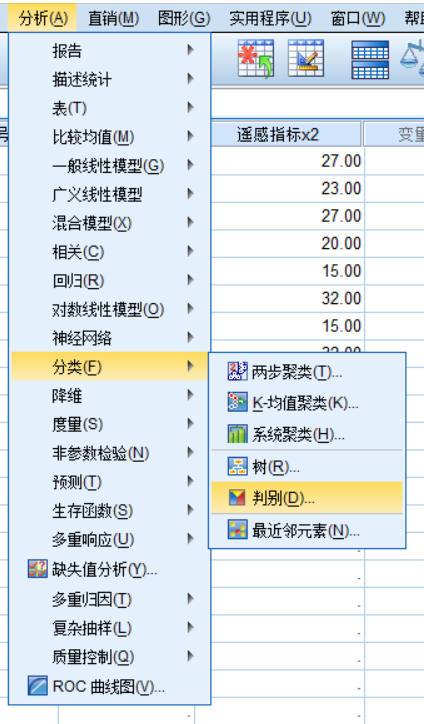
因變量選入分組變量,自變量選入。同時選擇變量選擇的方法。
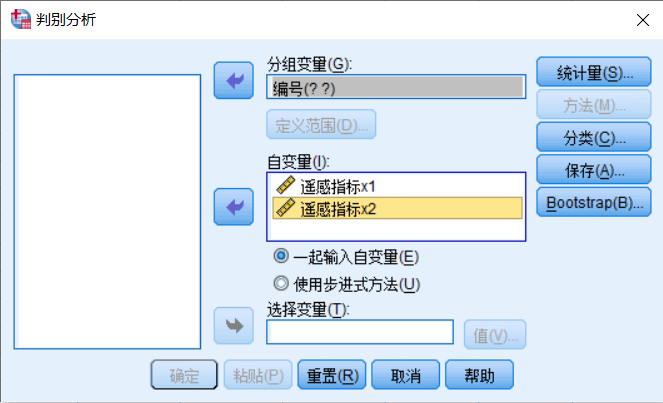
編號部分還是要定義范圍,最大1,最小0
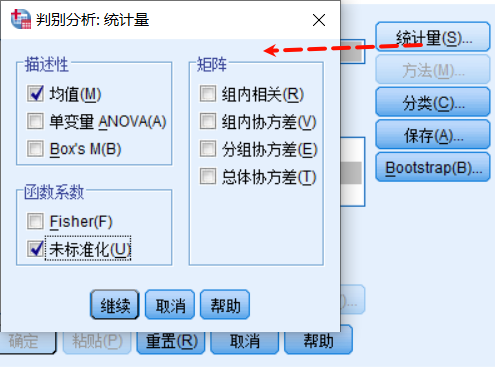
統計部分暫時選擇:
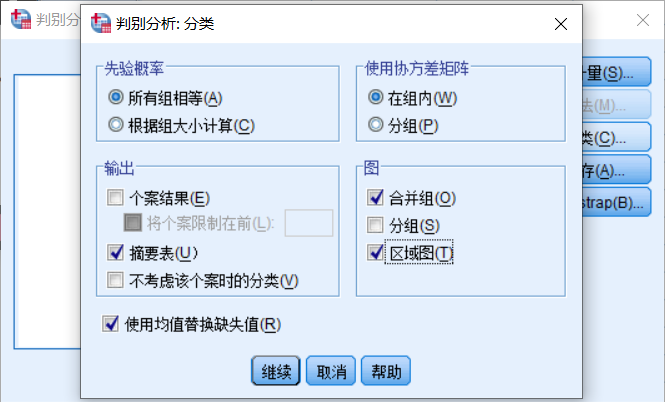
分類部分暫時選擇:
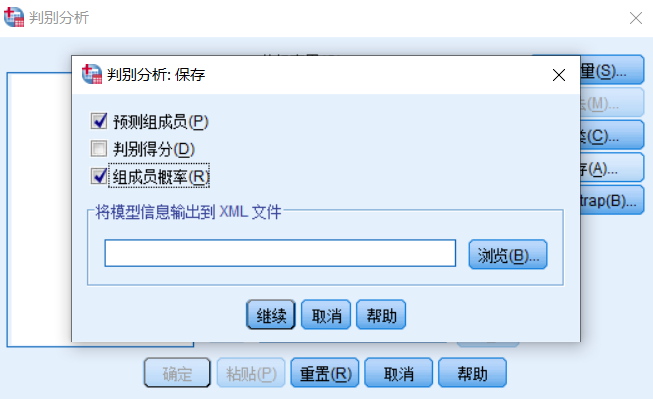
保存部分選擇:
結果部分:
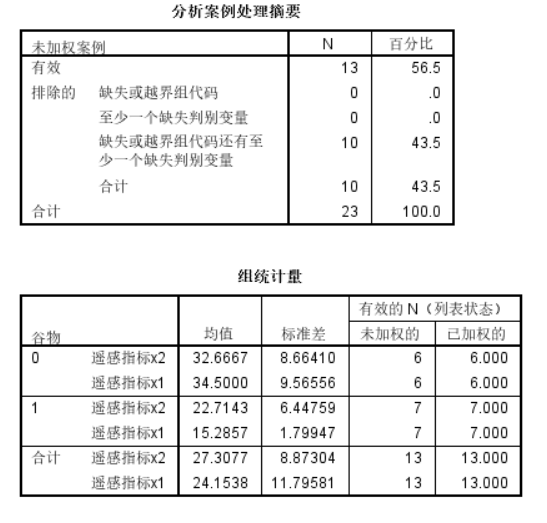
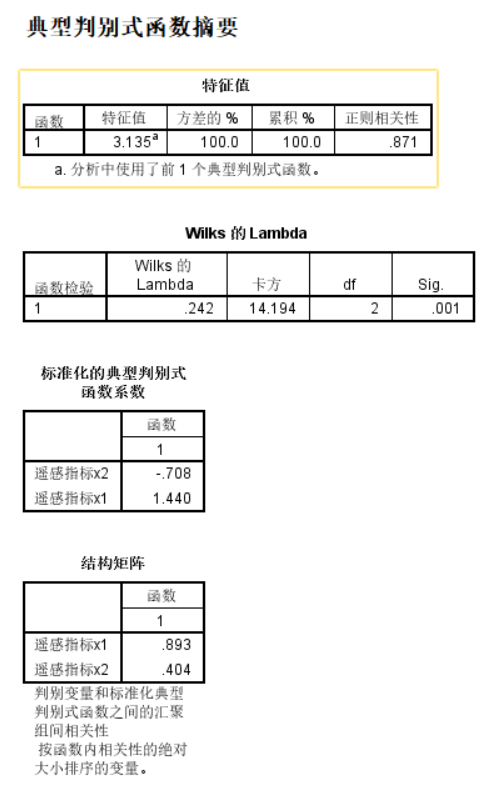
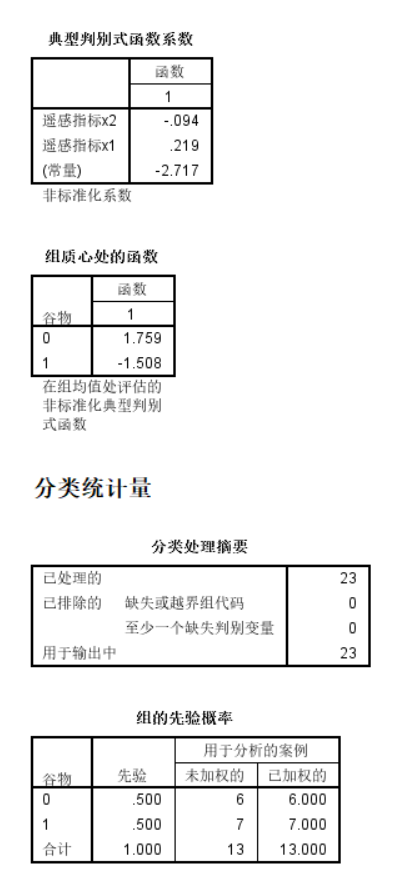
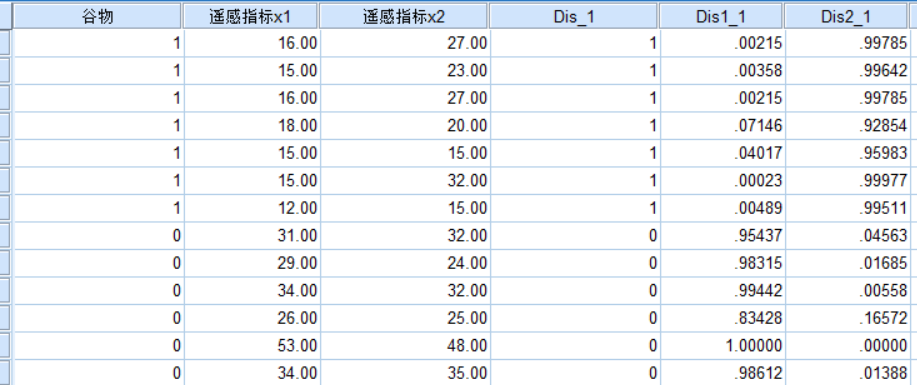
主要是分類結果:
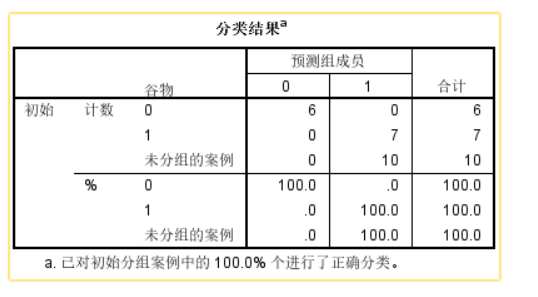
回到數據表格,可以看到新增的三列。第一列為預測的組別,第2、3為每個個案的分組概率。
 參考:https://www.iikx.com/news/statistics/7818.html
參考:https://www.iikx.com/news/statistics/7818.html
)





)



--文件與文件描述符fd)




————芯片鎖死問題及成功解鎖流程)

)
)
python中jupyter lab使用python虛擬環境)