樹的序列化可以有很多種類:可以變成 dfs 序,可以變成歐拉序,還有什么括號序的科技。
但是除了第一個以外其他的都沒什么用(要么也可以被已有的算法給替代掉)。所以表面上是講樹的序列化,實際上還是講的 dfs 序的運用(dfs 序的基礎知識沒什么,但是其運用可以變得相當毒瘤)。
Q:為什么要把樹序列化呢?
A:因為有些時候直接在樹上面做可能會很復雜,甚至很難做,這是因為樹的結構過于錯綜復雜了。如果把樹變成一個簡單的序列,那么線性 dp、區間 dp 等在樹上不能搞的東西都可以搞了。
dfs 序
dfs 序,顧名思義就是 dfs 的順序,更加具體的來說,就是在樹上 dfs 搜索到的結點順序(顯然如果不加任何約束條件的話 dfs 序不唯一,因為這和搜索的順序有關)。如果不會 dfs 的話左轉出門。
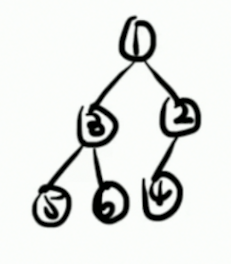
假若我們有這樣的一棵樹。很容易根據 dfs 將其標號:
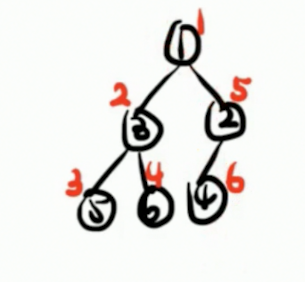
把每一個 dfs 序對應的結點記錄下來,就會得到一個數組: { 1 , 3 , 5 , 6 , 2 , 4 } \{1,3,5,6,2,4\} {1,3,5,6,2,4}。注意是 dfs 對應的結點,而不是每一個結點對應的 dfs 序,它們倆是順序不同的!
于是 dfs 序的定義就被講完了,很簡單是不是!(?
實際上 dfs 序的一個運用我們早就見過了:tarjan 全家桶。
時間戳
為什么我一定要強調這是順序對應結點呢?這是因為 dfs 序是由兩個東西構成的,一個是正宗的 dfs 序,一個是時間戳。
時間戳的定義貌似只可意會不可言傳,具體是這么一個東西:
對于每一個結點,dfs 剛遍歷到這個結點時,把這個點加入到時間戳的數組末尾的位置;要回溯的時候,也要把這個點加入到時間戳的數組末尾的位置。
還是沿用上面的樹,很容易地出來時間戳: { 1 , 3 , 5 , 5 , 6 , 6 , 3 , 2 , 4 , 4 , 2 , 1 } \{1,3,5,5,6,6,3,2,4,4,2,1\} {1,3,5,5,6,6,3,2,4,4,2,1}。也就是每一個點剛被遞歸到的時候加一遍,回溯的時候也加一遍。
那么它有著怎樣的性質呢?
對于每一個結點 u u u 為根的子樹,這個子樹在序列中會對應一個區間,且這個區間一定是 [ u 剛被遍歷到的時候加入數組的位置 , u 回溯的時候加入數組的位置 ] [u \ 剛被遍歷到的時候加入數組的位置,\ u\ 回溯的時候加入數組的位置] [u?剛被遍歷到的時候加入數組的位置,?u?回溯的時候加入數組的位置]。
這個性質有一些顯然,因為一個點子樹里面的所有點進入一定比這個點進入的晚,出來一定比這個點出來的早,所以就構成了一個區間的包含關系。
于是借助這個結論,就可以很容易的完成整個子樹的遍歷,也可以很快速的獲取整個子樹里面所有的結點。
例如 { 3 , 5 , 6 } \{3,5,6\} {3,5,6} 這個結點的子樹,很容易在里面找到 { 3 , 5 , 5 , 6 , 6 , 3 } \{3,5,5,6,6,3\} {3,5,5,6,6,3} 這個區間,恰好就對應的整個子樹。這樣會使很多的問題都處理地簡單一些,尤其是關于子樹的問題。
當我們遇到一些大力的 ds 題目的時候,例如需要快速修改子樹里面的東西,可以不使用樹鏈剖分,而是直接使用時間戳 + 線段樹就行了。
另一個性質:如果把每一個點回溯時加入的數都刪掉,剩余的數組成的就是 dfs 序。
這個東西很簡單,由定義就可以很容易的證明。
void dfs(int u, int pre) {lpos[u] = ++dfn, id[dfn] = u;//剛剛遍歷了這個結點,第一次加入for (auto i : v[u])if (i != pre)dfs(i, u);rpos[u] = dfn;//快要回溯了,第二次加入
}
代碼很好理解。lpos 表示的是子樹區間的左邊界,rpos 表示的是子樹區間的右邊界。
CF877E Danil and a Part-time Job
我前面說過,這兩個東西的定義和求解都是簡單的,但是套到題目中就不一定簡單了。所以我們現在開始講題。
雖然這道題也是很簡單的。
顯然這個就是區間修改,有點像開關那道題目,直接先套上一個時間戳然后再線段樹區間修改即可。
因為如果直接使用時間戳的話一個點會被計算兩次,所以最后要 /2.
#include <bits/stdc++.h>
using namespace std;
const int N = 400010;
int val[N];
int c, a, b;
int n, m;int l[N], r[N], to[N], dfn;
vector<int> v[N];struct tree {int l, r, sum, add;
} t[N * 4];void build(int u, int x, int y) {t[u].l = x;t[u].r = y;if (x == y) {t[u].sum = val[to[x]];return ;}int mid = (x + y) >> 1;build(u * 2, x, mid);build(u * 2 + 1, mid + 1, y);t[u].sum = t[u * 2].sum + t[u * 2 + 1].sum;
}void tag(int u) {if (t[u].add == 0)return;t[u * 2].sum = t[u * 2].r - t[u * 2].l + 1 - t[u * 2].sum;t[u * 2 + 1].sum = t[u * 2 + 1].r - t[u * 2 + 1].l + 1 - t[u * 2 + 1].sum;if (t[u * 2].add == 0)t[u * 2].add = 1;elset[u * 2].add = 0;if (t[u * 2 + 1].add == 0)t[u * 2 + 1].add = 1;elset[u * 2 + 1].add = 0;t[u].add = 0;
}void change(int u, int l, int r) {if (l <= t[u].l && t[u].r <= r) {t[u].sum = t[u].r - t[u].l + 1 - t[u].sum;if (t[u].add == 0)t[u].add = 1;elset[u].add = 0;return ;}tag(u);int mid = (t[u].l + t[u].r) >> 1;if (a <= mid)change(u * 2, l, r);if (b > mid)change(u * 2 + 1, l, r);t[u].sum = t[u * 2].sum + t[u * 2 + 1].sum;
}int ask(int u, int l, int r) {if (l <= t[u].l && r >= t[u].r)return t[u].sum;tag(u);int mid = (t[u].l + t[u].r) / 2;int ans = 0;if (a <= mid)ans += ask(u * 2, l, r);if (b > mid)ans += ask(u * 2 + 1, l, r);return ans;
}void dfs(int u) {l[u] = ++dfn, to[dfn] = u;for (auto i : v[u])dfs(i);r[u] = ++dfn, to[dfn] = u;
}int main() {cin >> n;for (int i = 2; i <= n; i++) {int f;cin >> f;v[f].push_back(i);}for (int i = 1; i <= n; i++)cin >> val[i];dfs(1);build(1, 1, n * 2);cin >> m;for (int i = 1; i <= m; i++) {string c;int x;cin >> c >> x;a = l[x], b = r[x];if (c == "pow")change(1, l[x], r[x]);elsecout << ask(1, l[x], r[x]) / 2 << endl;}return 0;
}
代碼長,思維簡單。
CF1891F A Growing Tree
給定一棵樹,一開始只含了 1 1 1 個結點,編號為 1 1 1,初始權值為 0 0 0。設樹的大小為 s z sz sz。
有 q q q 次操作:
-
1 x 1\ x 1?x,在 x x x 下面掛一個結點,編號為 s z + 1 sz+1 sz+1,初始的權值為 0 0 0。
-
2 x v 2\ x\ v 2?x?v,將當前 x x x 子樹中所有結點的權值加上 v v v。
乍一看好像無從下手:你這個加入會影響到很多結點的時間戳的值啊!于是正著在線處理操作是不行的。
這個時候有一個很重要的思想:正難則反。你正著加點不行,我反著來不行嗎!
考慮離線處理操作。于是我們一開始就可以得出來把點全部加完之后的樹。
如果遇到了 2 2 2 操作,就像上一道題目一樣使用區間修改維護即可。
如果遇到了 1 1 1 操作,那么這個點先前的東西全部應該不算(到了這個時候這個點才加進來!它的整個子樹也是一樣!),所以要把整個子樹都減去自己現在的權值。
所以就只需要一個支持區間加單點查詢的數據結構即可,很容易想到使用樹狀數組加上差分,因為線段樹 lazytag 還是太難寫了。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int t;
int n;
const int N = 1000010;struct node {int op, x, v;
} a[N];
vector<int> v[N];
int ans[N], x[N];
int l[N], r[N], dfn;void dfs(int u) {l[u] = ++dfn;for (auto i : v[u])dfs(i);r[u] = ++dfn;
}struct BIT {int tree[N];void clear() {for (int i = 1; i <= n * 2; i++)tree[i] = 0;}void add(int pos, int val) {for (; pos <= n * 2; pos += pos & -pos)tree[pos] += val;}int query(int pos) {int ans = 0;for (; pos; pos -= pos & -pos)ans += tree[pos];return ans;}
} st;signed main() {cin >> t;while (t--) {cin >> n;dfn = 0;int sz = 1;for (int i = 1; i <= n; i++) {cin >> a[i].op;if (a[i].op == 2)cin >> a[i].x >> a[i].v;elsecin >> a[i].x, v[a[i].x].push_back(++sz), x[i] = sz;}dfs(1);st.clear();for (int i = 1; i <= n; i++) {if (a[i].op == 2) {st.add(l[a[i].x], a[i].v);st.add(r[a[i].x] + 1, -a[i].v);} else if (!ans[x[i]]) {int a = st.query(l[x[i]]);st.add(l[x[i]], -a), st.add(r[x[i]] + 1, a);}}for (int i = 1; i <= sz; i++)cout << st.query(l[i]) << " ";cout << endl;for (int i = 1; i <= sz; i++)v[i].clear(), l[i] = r[i] = 0, ans[i] = 0, x[i] = 0;}return 0;
}
AT_abc294_g [ABC294G] Distance Queries on a Tree
給定一棵 n n n 點的樹,帶邊權,進行 Q Q Q 次操作,共有兩種:
-
1 i w將第 i i i 條邊的邊權改為 w w w。 -
2 u v詢問 u , v u,v u,v 兩點的距離。
設 1 1 1 為樹根。
很顯然,第二個詢問可以使用 LCA 來求解(因為樹的形態始終不變,LCA 也不會變)。設 d i d_i di? 表示 1 → i 1 \to i 1→i 的邊權和,那么 u , v u,v u,v 的距離為 d u + d v ? 2 × d l c a ( u , v ) d_u + d_v - 2\times d_{lca(u,v)} du?+dv??2×dlca(u,v)?。所以第二個詢問可以 O ( log ? n ) O(\log n) O(logn) 快速求解。
考慮如何處理第一個詢問。很顯然,設 i i i 為 u → v u \to v u→v 的邊(不妨讓 u u u 的深度比 v v v 淺),則當 u → v u\to v u→v 的邊權改變的時候(設相比原來多了 w w w),有且僅有 v v v 子樹里面的 d d d 值會發生改變,具體地,改變幅度就是 w w w。
所以就是子樹修改,可以直接序列化。
好久之前做的了,可能和現在的碼風略有不同。
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int MAX_N = 2e5 + 5, LOG_MAX_N = 19;int n;
struct Edge {int u, v, w;
};
Edge edge[MAX_N];
vector<int> adj[MAX_N];
int q;int n_ind, start_ind[MAX_N], end_ind[MAX_N];
int anc[MAX_N][LOG_MAX_N];
void dfs(int u) {start_ind[u] = ++n_ind;for (auto& v : adj[u]) {if (start_ind[v]) anc[u][0] = v;else dfs(v);}end_ind[u] = n_ind;
}bool is_anc(int u, int v) {return start_ind[u] <= start_ind[v] && start_ind[v] <= end_ind[u];
}
int lca(int u, int v) {if (is_anc(u, v)) return u;if (is_anc(v, u)) return v;for (int i = ceil(log2(n)); i >= 0; i--) {if (anc[u][i] == 0 || is_anc(anc[u][i], v)) continue;u = anc[u][i];}return anc[u][0]; }int segtree[4 * MAX_N];
void update(int l, int r, int x, int u = 1, int lo = 1, int hi = n) {if (l <= lo && hi <= r) {segtree[u] += x;return;}int mid = (lo + hi) / 2;if (l <= mid) update(l, r, x, 2 * u, lo, mid);if (r > mid) update(l, r, x, 2 * u + 1, mid + 1, hi);
}
int query(int i, int u = 1, int lo = 1, int hi = n) {if (lo == hi)return segtree[u];int mid = (lo + hi) / 2;if (i <= mid) return segtree[u] + query(i, 2 * u, lo, mid);else return segtree[u] + query(i, 2 * u + 1, mid + 1, hi);
}signed main() {// freopen("dist.in", "r", stdin);// freopen("dist.out", "w", stdout);cin >> n;for (int i = 1; i < n; i++) {int u, v, w; cin >> u >> v >> w;edge[i] = {u, v, w};adj[u].push_back(v);adj[v].push_back(u);}cin >> q;dfs(1);for (int i = 1; i <= ceil(log2(n)); i++) {for (int j = 1; j <= n; j++) {anc[j][i] = anc[anc[j][i - 1]][i - 1];}}for (int i = 1; i < n; i++) {int u = edge[i].u, v = edge[i].v;if (start_ind[u] > start_ind[v]) swap(u, v);update(start_ind[v], end_ind[v], edge[i].w); } for (int xq = 1; xq <= q; xq++) {int t, a, b; cin >> t >> a >> b;if (t == 1) {int u = edge[a].u, v = edge[a].v;if (start_ind[u] > start_ind[v]) swap(u, v);update(start_ind[v], end_ind[v], b - edge[a].w);edge[a].w = b;} else {int ans = query(start_ind[a]) + query(start_ind[b]) - 2 * query(start_ind[lca(a, b)]);cout << ans << '\n';}}
}
CF1328E Tree Queries
接下來開始講藍紫題,坐穩了!
前情提要:
我很好奇為什么 CF 要搞這么多測試點。
進入正題。給你一個 1 1 1 為根的有根樹,每次詢問 k k k 個結點 v 1 , v 2 , ? , v k v_1,v_2,\cdots,v_k v1?,v2?,?,vk?,求是否有一條以根結點為一端的鏈使得詢問的每一個結點到這條鏈的距離都是 ≤ 1 \le 1 ≤1。
這道題看似很不友善,實際上全部的過程就只有兩句話。
個人感覺這道題還是很妙的,可能是我太菜了吧。
首先,考慮如何判斷多個點在同一條一端為根的鏈上。
這個任務非常的簡單,好像有一萬種方法,這也使得選擇較為困難。
考慮挖掘性質。首先,這一條鏈上面的每一個深度都最多出現一次,這是顯然的。所以對深度排序。
排序完了之后咋辦呢?顯然,這樣的一條鏈上的相鄰兩個點都是由祖先的關系。所以如果這堆點在同一條鏈上面的話,排序之后相鄰的點一定存在祖孫關系。
這個時候又有了一萬種方法,但是我們要選擇最快的。既然都出現祖孫關系了,那么還不夠啟發嗎?顯然,祖先的子樹里面一定包含子孫,所以直接使用時間戳判斷區間包含即可。
也可以使用 lca 來判斷。
但是,上面的東西和題目只有一點關聯。因為題目要我們求的是距離 ≤ 1 \le 1 ≤1。
**繼續挖掘性質!**這個鏈的一端是根結點,所以可以得出兩個結論:
-
如果一個結點在這條鏈上,則其父親也一定在鏈上,也就是距離 = 0 =0 =0 一定在鏈上。(廢話)
-
如果一個結點的父親不在鏈上,則它也一定不會在鏈上,則就是距離 > 1 >1 >1 的時候一定不在鏈上。
也就是,一個點距離這條鏈的距離是否 ≤ 1 \le 1 ≤1,和它的父親是不是在鏈上有關。
所以每一個點變成它的父親,然后再判斷是不是在一條鏈上面即可。
注意,這里設根結點的父親是它自己,要不然就出問題了。
#include <bits/stdc++.h>
using namespace std;
int n, m;
const int N = 200010;
int fa[N];
vector<int> v[N];
bool fg[N];
int f[N][30];
int cnt;
int a[N], dep[N];
bool ok;void dfs(int u, int pre) {f[u][0] = pre;dep[u] = dep[pre] + 1;for (int i = 1; i <= 20; ++i)f[u][i] = f[f[u][i - 1]][i - 1];for (auto i : v[u])if (i != pre)dfs(i, u);
}int lca(int x, int y) {if (dep[x] > dep[y])swap(x, y);for (int i = 20; i >= 0; --i)if (dep[f[y][i]] >= dep[x])y = f[y][i];if (y == x)return x;for (int i = 20; i >= 0; --i)if (f[y][i] != f[x][i])y = f[y][i], x = f[x][i];return f[x][0];
}void get_fa(int u, int pre) {fa[u] = pre;for (auto i : v[u])if (i != pre)get_fa(i, u);
}bool cmp(int x, int y) {return dep[x] < dep[y];
}int main() {cin >> n >> m;for (int i = 1; i < n; i++) {int x, y;cin >> x >> y;v[x].push_back(y);v[y].push_back(x);}get_fa(1, 0);dfs(1, 0);while (m--) {int k;cin >> k;int tot = 0;for (int i = 1; i <= k; i++) {int x;cin >> x;if (x != 1)a[++tot] = fa[x], fg[fa[x]] = 1;}sort(a + 1, a + tot + 1, cmp);cnt = unique(a + 1, a + tot + 1) - a - 1;ok = 1;for (int i = 1; i < cnt; i++)if (lca(a[i], a[i + 1]) != a[i])ok = 0;for (int i = 1; i <= cnt; i++)fg[a[i]] = 0;if (ok)cout << "YES\n";elsecout << "NO\n";}return 0;
}
CF383C Propagating tree
有一棵樹,上面有 n n n 個結點。它的根是 1 1 1 號節點。
這棵橡樹每個點都有一個權值,你需要完成這兩種操作:
1 1 1 u u u v a l val val 表示給 u u u 節點的權值增加 v a l val val。
2 2 2 u u u 表示查詢 u u u 節點的權值。
它還有個神奇的性質:當某個節點的權值增加 v a l val val 時,它的子節點權值都增加 ? v a l -val ?val,它子節點的子節點權值增加 ? ( ? v a l ) -(-val) ?(?val)… 如此一直進行到樹的底部。
很顯然直接把樹的深度分成奇偶性,每一個開一個線段樹再記錄一下 dfs 序,然后分類討論即可。
有一些細節。
// LUOGU_RID: 168542341
#include <bits/stdc++.h>
#define ls(x) (x<<1)
#define rs(x) (x<<1|1)
#define mid ((l+r)>>1)
using namespace std;
const int N = 200010;
int n, m;
int val[N];
int dd[N * 2][2]; //兩個dfs序,一個是奇數層,一個是偶數層的
int tot;
vector<int> v[N];
int dep[N];//深度void dfs(int u, int pre) { //求dfs序dep[u] = dep[pre] + 1;tot++;dd[tot][dep[u] % 2] = u;for (auto i : v[u])if (i != pre)dfs(i, u);tot++;dd[tot][dep[u] % 2] = u;
}struct segment_tree {int seg[N * 4 * 2], lazy[N * 4 * 2];void pushup(int now) {seg[now] = seg[ls(now)] + seg[rs(now)];}void pushdown(int now, int l, int r) {if (lazy[now] != 0) {lazy[ls(now)] += lazy[now];lazy[rs(now)] += lazy[now];seg[ls(now)] += (mid - l + 1) * lazy[now];seg[rs(now)] += (r - mid) * lazy[now];lazy[now] = 0;}}void build(int now, int l, int r, int wh) {lazy[now] = 0;if (l == r) {seg[now] = val[dd[l][wh]];return ;}build(ls(now), l, mid, wh);build(rs(now), mid + 1, r, wh);pushup(now);}void update(int now, int l, int r, int ql, int qr, int val) {if (l >= ql && r <= qr) {lazy[now] += val;seg[now] += (r - l + 1) * val;return ;}pushdown(now, l, r);if (ql <= mid)update(ls(now), l, mid, ql, qr, val);if (qr > mid)update(rs(now), mid + 1, r, ql, qr, val);pushup(now);}int query(int now, int l, int r, int pos) {if (l == r)return seg[now];pushdown(now, l, r);if (pos <= mid)return query(ls(now), l, mid, pos);elsereturn query(rs(now), mid + 1, r, pos);}
} sg1, sg2;
int pot[N][2];int main() {ios::sync_with_stdio(0);cin >> n >> m;for (int i = 1; i <= n; i++)cin >> val[i];for (int i = 1; i < n; i++) {int x, y;cin >> x >> y;v[x].push_back(y);v[y].push_back(x);}dfs(1, 0);sg1.build(1, 1, 2 * n, 0);sg2.build(1, 1, 2 * n, 1);for (int i = 1; i <= 2 * n; i++) {if (pot[dd[i][0]][0] == 0)pot[dd[i][0]][0] = i;elsepot[dd[i][0]][1] = i;if (pot[dd[i][1]][0] == 0)pot[dd[i][1]][0] = i;elsepot[dd[i][1]][1] = i;}while (m--) {int op;cin >> op;if (op == 1) {int x, y;cin >> x >> y;sg1.update(1, 1, 2 * n, pot[x][0], pot[x][1], (dep[x] % 2 == 1 ? -y : y));sg2.update(1, 1, 2 * n, pot[x][0], pot[x][1], (dep[x] % 2 == 0 ? -y : y));} else {int x;cin >> x;if (dep[x] % 2 == 0)cout << sg1.query(1, 1, 2 * n, pot[x][0]) << endl;elsecout << sg2.query(1, 1, 2 * n, pot[x][0]) << endl;}}return 0;
}
:組網邏輯)


)





)



--文件與文件描述符fd)




————芯片鎖死問題及成功解鎖流程)
