Adversarial Semantic Collisions
Adversarial Semantic Collisions - ACL Anthology
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
對抗樣本是相似的輸入但是產生不同的模型輸出,而語義沖突是對抗樣本的逆過程,是不同的輸入產生相似的模型輸出。
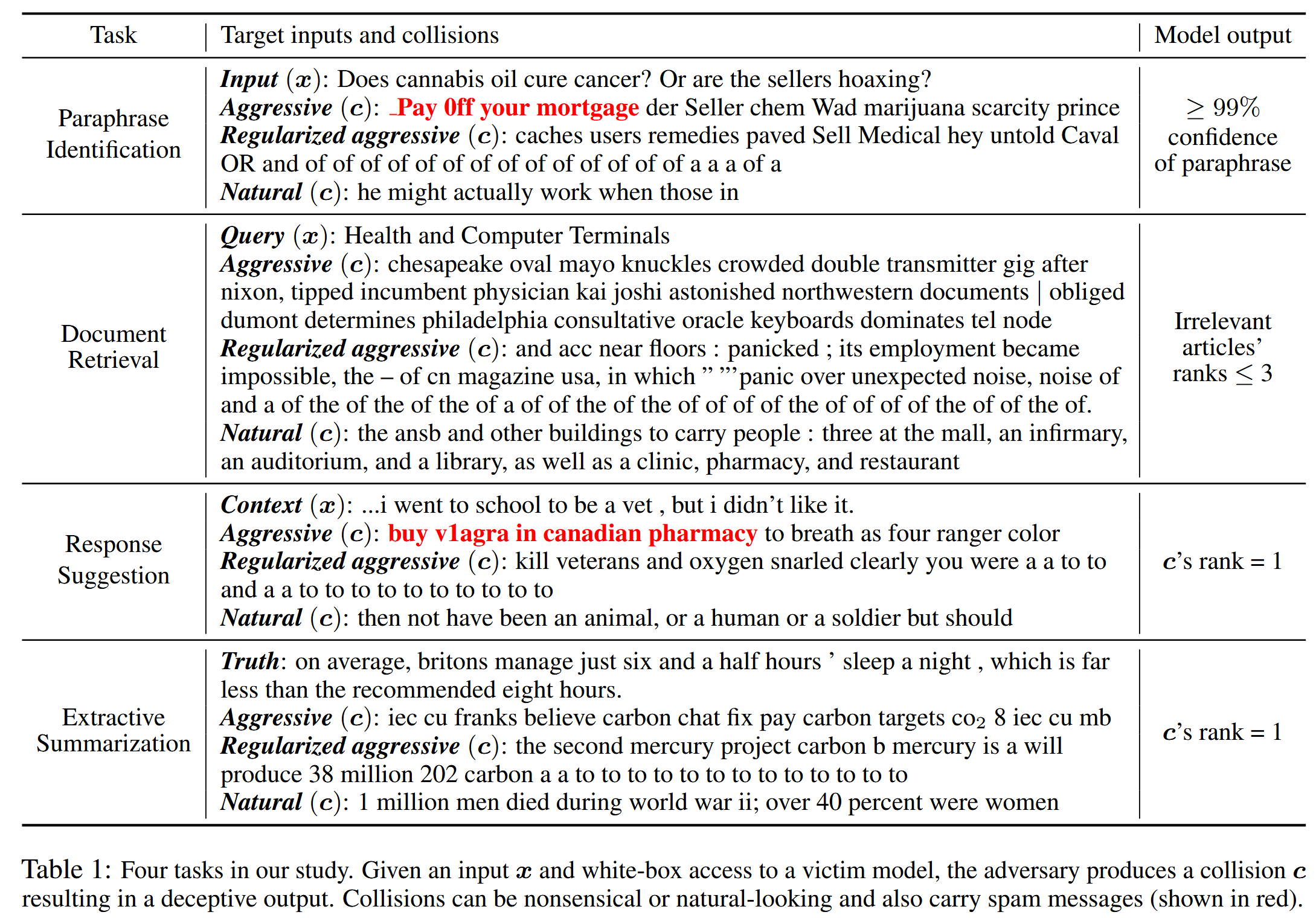
開發了基于梯度的方法,在白盒訪問模型的情況下生成沖突,并將其應用于多個 NLP 任務。在釋義識別中,攻擊者構造的沖突文本被判定為輸入查詢的有效釋義;像去重或合并相似內容這樣的下游應用,會錯誤地將攻擊者的輸入與受害者的輸入合并。在文檔檢索中,攻擊者將沖突文本插入到其中一個文檔中,使其即使與查詢無關也能獲得很高的排名。在回復建議中,攻擊者的不相關文本被排在首位,還可能包含垃圾郵件或廣告內容。在抽取式摘要中,攻擊者將沖突文本插入到輸入文本中,使其被選為最相關的內容。
第一種技術積極地生成沖突,而不考慮潛在的防御措施。然后開發了兩種技術,“正則化積極” 和 “自然” 技術,通過語言模型對生成的沖突進行約束,以規避基于困惑度的過濾。在所有四個任務上,針對最先進的模型和基準數據集評估了所有技術。在 Quora 問題對的釋義識別任務中,生成的沖突文本平均有 97% 的置信度被(錯誤地)識別為輸入的釋義。在文檔檢索中,生成的沖突使不相關文檔的中位數排名從 1000 提升到了 10 左右。在對話(句子檢索)的回復建議任務中,使用積極和自然技術生成的沖突文本分別有 99% 和 86% 的時間被排在首位。在抽取式摘要任務中,生成的沖突文本 100% 的時間都被模型選為摘要。最后討論了針對這些攻擊的潛在防御措施。
?
威脅模型
1.語義相似性
設f表示模型,x和y是一對文本輸入。對于這些應用,有兩種常見的建模方法。在第一種方法中,模型將x和y的連接作為輸入,并直接產生一個相似性得分s=f(x,y)。在第二種方法中,模型計算句子級別的嵌入ex?和ey?,即輸入x和y的密集向量表示。然后,相似性得分計算為s=g(ex?,ey?),其中g是向量相似性度量,如余弦相似性。基于這兩種方法的模型都使用相似的損失進行訓練,例如二元分類損失,其中每對輸入如果在語義上相關則標記為 1,否則標記為 0。為了通用性,設S(x,y)是一個相似性函數,它涵蓋了上述兩種方法下的語義相關性。我們還假設S可以接受離散單詞序列(表示為x=[w1?,w2?,...,wT?])或單詞嵌入向量(表示為x=[e1?,e2?,...,eT?])形式的輸入,具體取決于場景。
2.假設
假設攻擊者完全了解目標模型,包括其架構和參數。通過模型提取,白盒攻擊有可能轉移到黑盒場景;我們將此留作未來的工作。攻擊者控制一些將被目標模型使用的輸入,例如,他可以為檢索系統插入或修改候選文檔。
3.攻擊者的目標
?給定一個目標模型f和目標句子x,攻擊者希望生成一個沖突文本c,使得f認為x和c在語義上相似或相關。這種攻擊的對抗性用途取決于具體應用。例如,如果一個應用使用釋義識別來合并相似內容(如在 Quora 中,Scharff,2015),攻擊者可以利用沖突向用戶發送垃圾郵件或廣告。在檢索系統中,攻擊者可以利用沖突提高某些查詢中不相關候選文檔的排名。對于抽取式摘要,攻擊者可以使沖突文本被作為目標文檔的摘要返回。
對抗性語義沖突
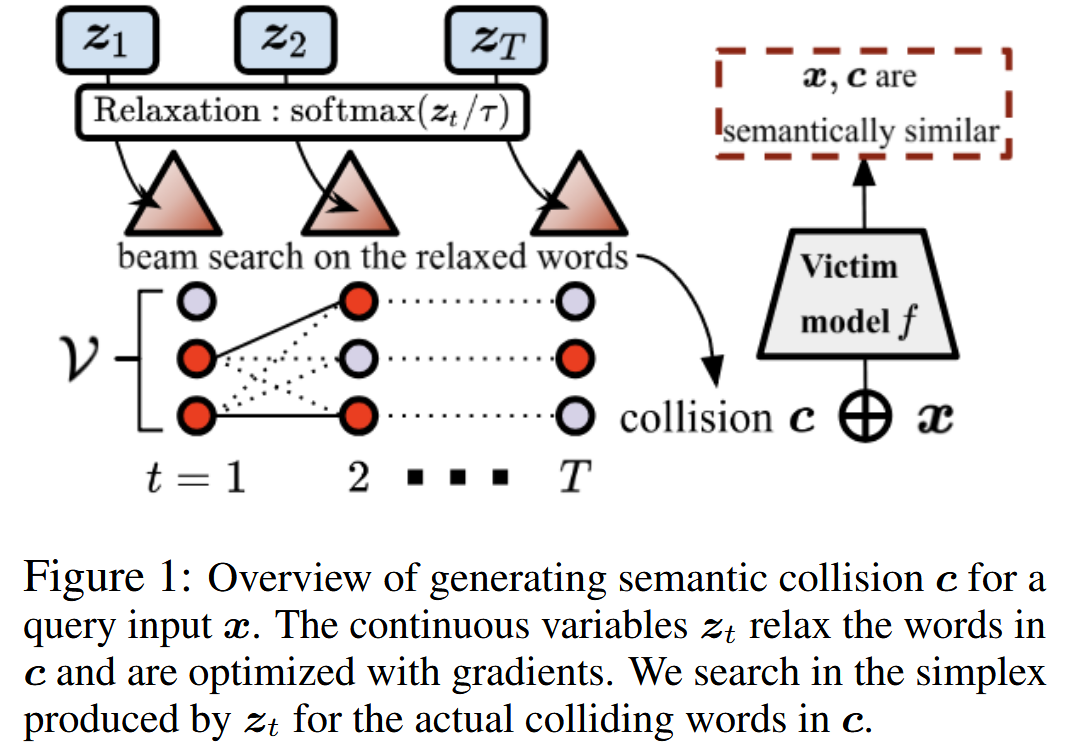
給定一個輸入(查詢)句子x,我們旨在為具有白盒相似性函數S的受害者模型生成一個沖突文本c。這可以表述為一個優化問題:argmaxc?S(x,c),使得x和c在語義上不相關。對c進行暴力枚舉在計算上是不可行的。相反,我們設計了算法 1 中概述的基于梯度的方法。我們考慮兩種變體:(a)積極生成無約束的、無意義的沖突,以及(b)有約束的沖突,即語言模型認為流暢且不能基于困惑度自動過濾掉的標記序列。
我們假設模型既可以接受硬獨熱編碼單詞作為輸入,也可以接受軟單詞作為輸入,其中軟單詞是詞匯表的概率向量。

1.敵對性沖突
使用基于梯度的搜索,為給定的目標輸入生成固定長度的沖突。
搜索分兩步進行:1)通過帶松弛的梯度優化找到沖突的連續表示,2)應用束搜索生成硬沖突。迭代地重復這兩個步驟,直到相似性得分s收斂。
優化軟沖突:
首先通過溫度退火將優化松弛到連續表示。給定模型的詞匯表V和固定長度T,我們將每個位置的單詞選擇建模為連續的對數幾率向量zt?。為了將每個zt?轉換為輸入單詞,我們將在t位置軟選擇的單詞建模為:
![]()
其中τ是溫度標量。直觀地說,對zt?應用 softmax 函數給出了詞匯表V中每個單詞的概率。溫度控制單詞選擇概率的尖銳程度;當τ→0時,軟單詞與硬單詞argmaxw∈V?zt?[w]相同。
我們對連續值z進行優化。在每一步,軟單詞沖突被輸入到S中以計算S(x,cˇ)。由于所有操作都是連續的,誤差可以一直反向傳播到每個zt?以計算其梯度。因此,我們可以應用梯度上升來優化目標。
搜索硬沖突:在松弛優化之后應用投影步驟,通過離散搜索找到硬沖突:對每個zt?應用從左到右的束搜索。在每個搜索步驟t,我們首先根據zt?獲取前K個單詞,并根據目標相似性![]() 對它們進行排名,其中ct+1:T?是從t+1到結束位置的部分軟沖突。這個過程允許我們根據之前找到的硬單詞和對未來單詞的松弛估計,為每個位置的軟單詞找到硬單詞替換。
對它們進行排名,其中ct+1:T?是從t+1到結束位置的部分軟沖突。這個過程允許我們根據之前找到的硬單詞和對未來單詞的松弛估計,為每個位置的軟單詞找到硬單詞替換。
用硬沖突重復優化:如果相似度得分在波束搜索后仍有提升空間,就利用當前的 c 來初始化軟解 zt,通過將硬解轉回連續空間來進行下一次優化迭代。
為了從硬句子初始化連續松弛,我們對其獨熱表示應用標簽平滑(LS)。對于當前c中的每個單詞ct?,我們將其一維獨熱向量軟化到Δ^{∣V∣-1}內,公式為:
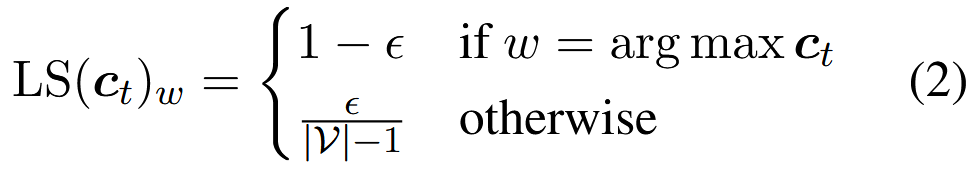
其中?是標簽平滑參數。由于LS(ct?)被約束在概率單純形Δ∣V∣-1內,我們將每個zt?初始化為log(LS(ct?)),以優化下一次迭代的軟解。
2.約束沖突
敵對性方案在找到沖突上很高效,但是會疏忽無意義的句子,PPL很高,很容易被基于PPL的過濾篩選掉。解決方案:對沖突施加一個軟約束,同時最大化目標相似度和語言模型相似似然:
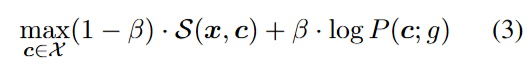
其中P(c; g)是在預訓練語言模型g下沖突c的語言模型似然度,β∈[0,1]是一個插值系數
兩種方法解決公式3提出的優化:(a)在soft c上添加一個正則化項來近似LM的似然;(b)引導一個預訓練的LM生成看起來自然的c
1.正則化Aggressive Collisions
給定語言模型g,可以把LM似然的soft版本作為一個正則化的形式來和從變量[z1,...,zT]中計算得出的soft aggressive?![]() 進行合并:
進行合并:
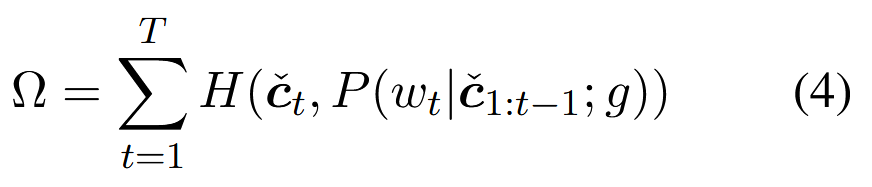
其中H函數是計算交叉熵,里面的P是給定部分軟沖突![]() ,在第t個位置的下一個token預測概率
,在第t個位置的下一個token預測概率
公式4?將軟碰撞作為輸入,放寬了硬碰撞的 LM 似然,并可添加到梯度優化的目標函數中。優化后的變量 zt 將偏向于最大化 LM 可能性的詞。
為了進一步降低 c 的困惑度,我們利用了 LM 的退化特性,即 LM 對重復的常見字元賦予較低的困惑度,并限制 c 中連續字元的跨度(如 c 的后半部)從最常出現的英語單詞中選取,而不是從整個 V 中選取。
2.自然沖突
與先松弛再搜索不同,我們對公式 3 采取先搜索再松弛的策略。這使我們在連續空間中選擇下一個詞時能夠整合一個硬語言模型。在每一步t,我們最大化
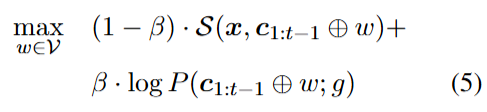
其中,c1:t?1?是之前找到的束搜索解。這種順序優化本質上是在語言模型的可能性和沖突前綴的目標相似度上進行聯合搜索的語言模型解碼過程。
精確優化公式 5 需要根據語言模型似然logP和相似度S對每個w進行排序。在每一步評估每個詞的語言模型可能性是高效的,因為我們可以緩存logP并以標準方式計算下一個詞的概率。然而,評估任意相似度函數S(x,c1:t?1?⊕w)需要對模型進行前向傳遞,這在計算上可能很昂貴。
擾動語言模型的對數幾率:受即插即用語言模型的啟發,我們修改語言模型的對數幾率以考慮相似度。首先,令L_t是語言模型在步驟t產生的下一個詞的對數幾率。然后,我們從這個初始值開始優化,找到一個更新值δt?,使它更傾向于選擇能最大化相似度的詞。具體來說,我們令zt?=?t?+δt?,其中δt?是一個擾動向量。然后,我們在松弛的相似度目標maxδt??S(x,c1:t?1?⊕softmax(zt?/τ))上進行少量梯度步驟,其中softmax(zt?/τ)是如公式 1 中的松弛軟詞。這鼓勵從擾動后的對數幾率zt?得到的下一個詞的預測分布,更傾向于選擇那些可能與輸入產生沖突的詞。
聯合束搜索:在每一步t進行擾動后,我們在V中找到最可能的前B個詞。這使我們只需要對在當前束搜索上下文下,在語言模型中可能性較高的這部分詞評估S。我們根據目標損失和語言模型對數可能性的插值對這些前B個詞進行排序。我們按照公式 5 為每個束和每個前B個詞分配一個分數,并用得分最高的詞更新束搜索結果。
這個過程會生成一個看起來自然的解碼序列,因為每一步都使用真實的詞作為輸入。隨著我們構建序列,每一步的搜索都由語義相似度和流暢度這兩個目標的聯合得分引導。
整體思路人話解釋版
這篇文章的核心方法其實就是在搞一種叫“語義碰撞”的攻擊,目的是讓NLP模型把兩個完全不相關的文本誤判為語義相似,人類一看就知道這兩句話毫無關系,但 NLP 模型卻可能認為它們是“高度相似”(比如 99% 置信度),作者就把這種攻擊叫做語義碰撞Semantic Collisions。作者用了梯度優化的方法來生成這種文本,還分了兩種類型:一種是“無腦亂懟型”(Aggressive),另一種是“裝得像人話型”(Natural)。
無腦亂懟型(Aggressive):
直接暴力優化,用梯度上升硬懟模型的相似度分數,生成一堆狗屁不通的文本。比如:“Pay 0ff your mortgage der Seller chem Wad marijuana scarcity prince”這種鬼話。 ?
方法分兩步: ?
- 先用連續變量(softmax搞出來的概率)優化,讓模型覺得這坨東西和原文本相似。 ?
- 再用beam search把連續變量轉成具體的詞(硬碰撞)。 ??
公式(1)和(2)就是裝逼用的,本質就是“用梯度調詞的概率,直到模型被忽悠”。
從文章的描述和算法描述上,具體來說:
把詞變成“軟選擇”(Soft Selection)
通常 NLP 模型輸入的是具體的詞(比如 “cat”),但這里作者先用一個“概率分布”表示每個位置的詞可能是什么。
比如,第一個詞可能是 70% “cat”、20% “dog”、10% “apple”…… 這樣模型可以計算梯度(因為概率是連續的)。
公式(1)就是干這個的:![]()
其中zt是每個詞的“傾向性分數”,τ控制概率的集中程度(越小越傾向于選一個詞)。
用梯度優化,讓模型誤判
目標是讓模型認為生成的句子c^和原句x相似,所以優化目標是最大化x和c^的相似度(比如 BERT 的相似度分數)。
用梯度上升(Adam 優化器)調整zt?,讓?S(x,c^)越來越大。
把“軟詞”變回“硬詞”(Beam Search)
現在c^是一堆概率分布,但我們需要具體的詞(比如 “cat” 而不是 70% “cat”)。用?Beam Search(一種搜索算法)從概率分布里挑出最能讓模型誤判的詞組合。比如,如果模型覺得 “cat dog apple” 和原句相似度很高,就選這個詞組合。
重復優化,直到騙過模型
如果 Beam Search 找到的詞還不夠“騙人”,就再回到第 1 步,用這些詞初始化新的優化過程。
結果:生成一堆狗屁不通的句子,但模型認為它們和原句高度相似。
裝得像人話型(Natural):
為了繞過基于語言模型(LM)的過濾,作者加了個約束:生成的文本不僅要騙過目標模型,還要讓LM覺得它像人話。 ?
方法更啰嗦:
?一邊用LM生成正常詞,一邊用梯度微調這些詞的logits,讓它們同時騙過目標模型。 ?
公式(3)到(5)本質就是“用LM生成詞,但偷偷改幾個詞讓模型上當”。 ?
公式(1)到(5)完全是為了論文顯得高大上,實際就是梯度優化+beam search的老套路,非要包裝成數學難題。 ?
“溫度參數τ”、“標簽平滑?”這些術語除了裝逼沒啥用,直接說“調參數讓生成更平滑”不就完了? ?
自然碰撞的部分更是脫褲子放屁,明明就是“用LM生成+梯度微調”,非要寫成一堆公式。 ?
從方法描述上來看,具體措施是:
用語言模型(LM)生成候選詞,比如用 GPT-2 生成一些合理的詞(“the”, “cat”, “is”…),而不是完全隨機選。
微調這些詞,讓模型誤判:對 LM 生成的詞做小調整(比如把 “cat” 改成 “kitten”),讓它們同時滿足:語言模型覺得合理(低困惑度);目標模型覺得和原句相似(高S(x,c))
公式(5)就是干這個的:
![]()
其中:
S(x,c)是目標模型的相似度;log?P(c;g)是語言模型的概率(保證句子通順);β是調節權重(更偏向通順 or 更偏向騙模型)
用 Beam Search 選最佳組合:和“無腦暴力法”類似,但每次選詞時不僅要看相似度,還要看語言模型的流暢度。
結果:生成看起來正常的句子,但模型仍然被騙。
這方法的核心就一句話:用梯度優化生成一堆文本,要么無腦亂懟,要么假裝人話,目的是讓模型把垃圾當寶貝。公式全是煙霧彈,直接看算法偽代碼(Algorithm 1)反而更清楚。
實驗
略
)







:微積分初步)










