之前寫過——Google Guava Cache簡介
本文系統學習一下多級緩存
目錄
- 0.什么是多級緩存
- 商品查詢業務案例導入
- 1.JVM進程緩存
- 初識Caffeine
- 實現JVM進程緩存
- 2.Lua語法入門
- HelloWorld
- 數據類型、變量和循環
- 函數、條件控制
- 3.Nginx業務編碼實現多級緩存
- 安裝OpenResty
- OpenResty快速入門
- 請求參數處理
- ☆實現OpenResty查詢Tomcat
- Redis緩存預熱
- ☆實現OpenResty查詢Redis緩存
- ☆實現Nginx本地(OpenResty)緩存
- 4.☆緩存同步
- 緩存同步策略
- Canal初識與配置
- 監聽Canal實現緩存同步
0.什么是多級緩存
傳統的緩存策略一般是請求到達Tomcat后,先查詢Redis,如果未命中則查詢數據庫,如圖:
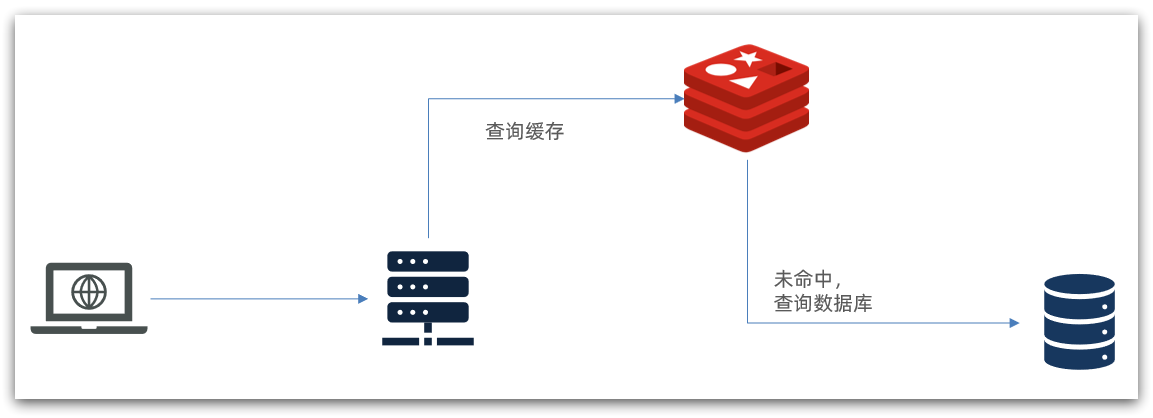
存在下面的問題:
-
請求要經過Tomcat處理,Tomcat的性能成為整個系統的瓶頸
-
Redis緩存失效時,會對數據庫產生沖擊
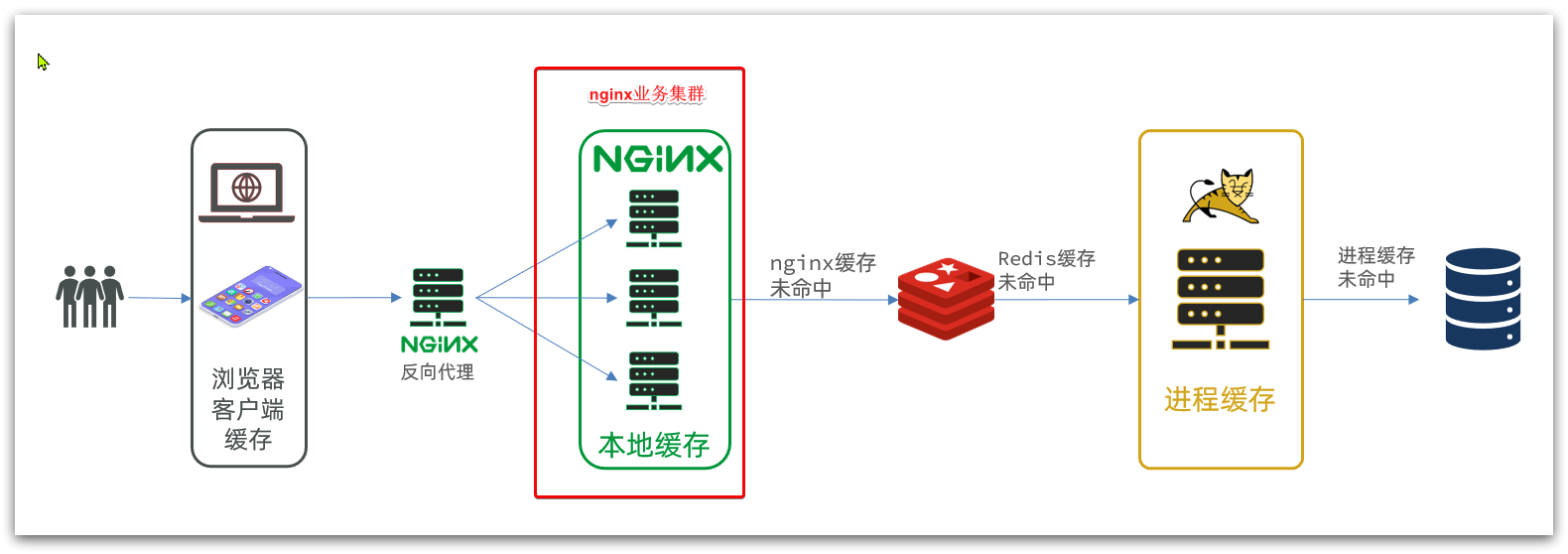
多級緩存就是充分利用請求處理的每個環節,分別添加緩存,減輕Tomcat壓力,提升服務性能:
- 瀏覽器訪問靜態資源時,優先讀取瀏覽器本地緩存
- 訪問非靜態資源(ajax查詢數據)時,訪問服務端
- 請求到達Nginx后,優先讀取Nginx本地緩存
- 如果Nginx本地緩存未命中,則去直接查詢Redis(不經過Tomcat)
- 如果Redis查詢未命中,則查詢Tomcat
- 請求進入Tomcat后,優先查詢JVM進程緩存
- 如果JVM進程緩存未命中,則查詢數據庫
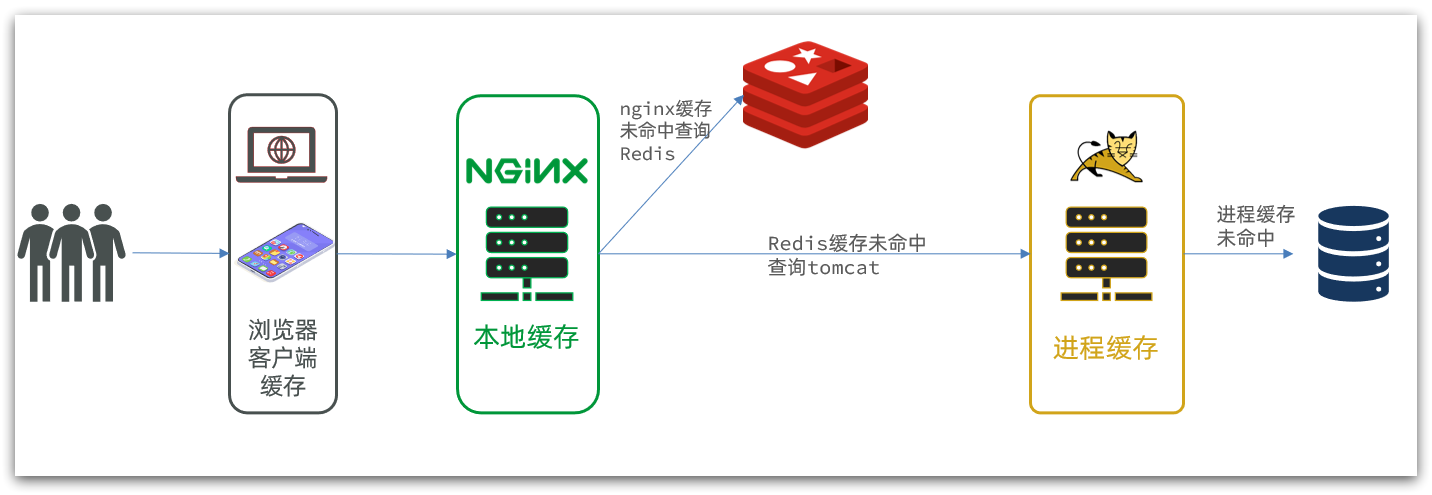
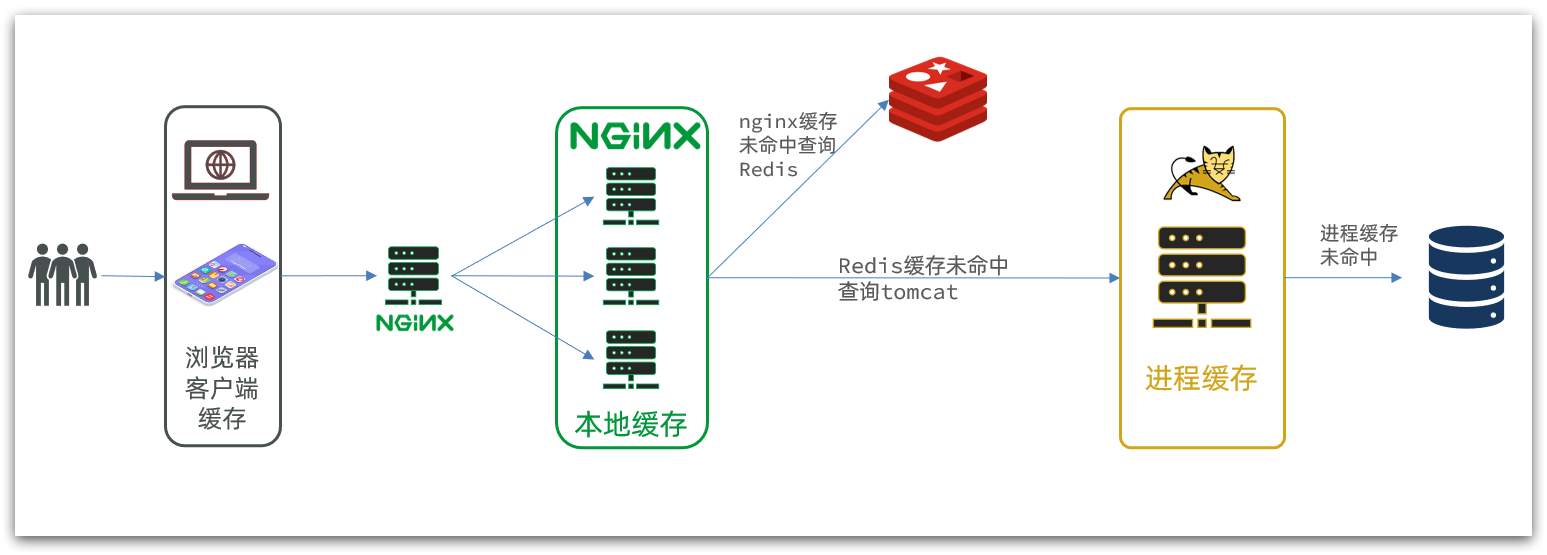
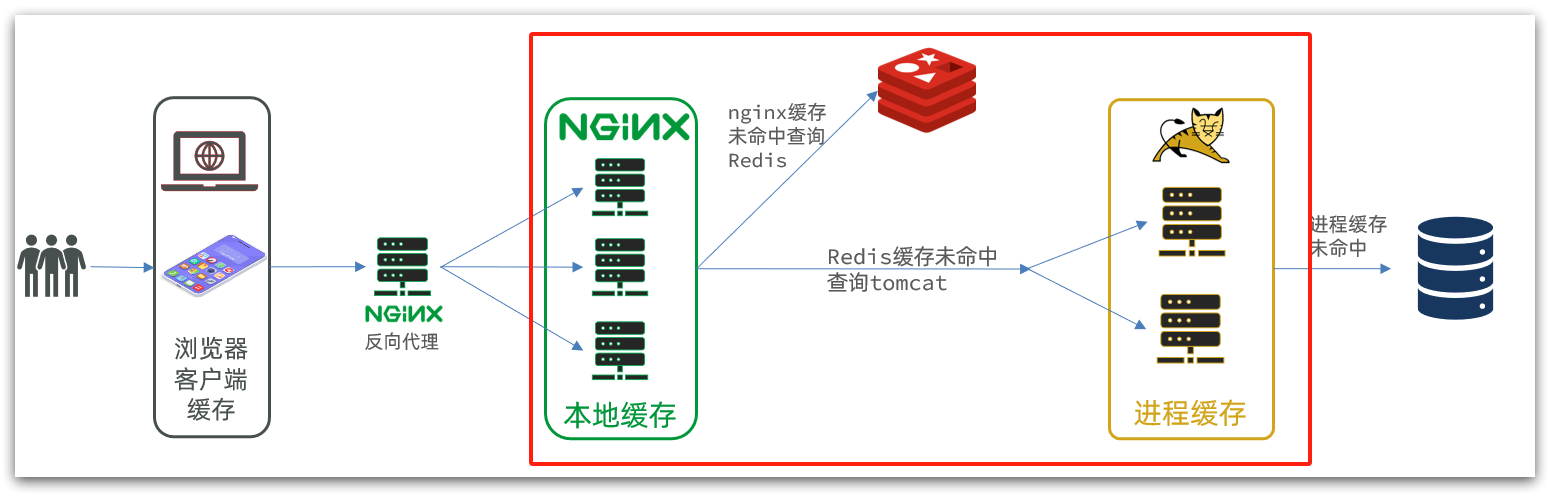
在多級緩存架構中,Nginx內部需要編寫本地緩存查詢、Redis查詢、Tomcat查詢的業務邏輯,因此這樣的nginx服務不再是一個反向代理服務器,而是一個編寫業務的Web服務器了。
因此這樣的業務Nginx服務也需要搭建集群來提高并發,再有專門的nginx服務來做反向代理,如圖:
另外,我們的Tomcat服務將來也會部署為集群模式:
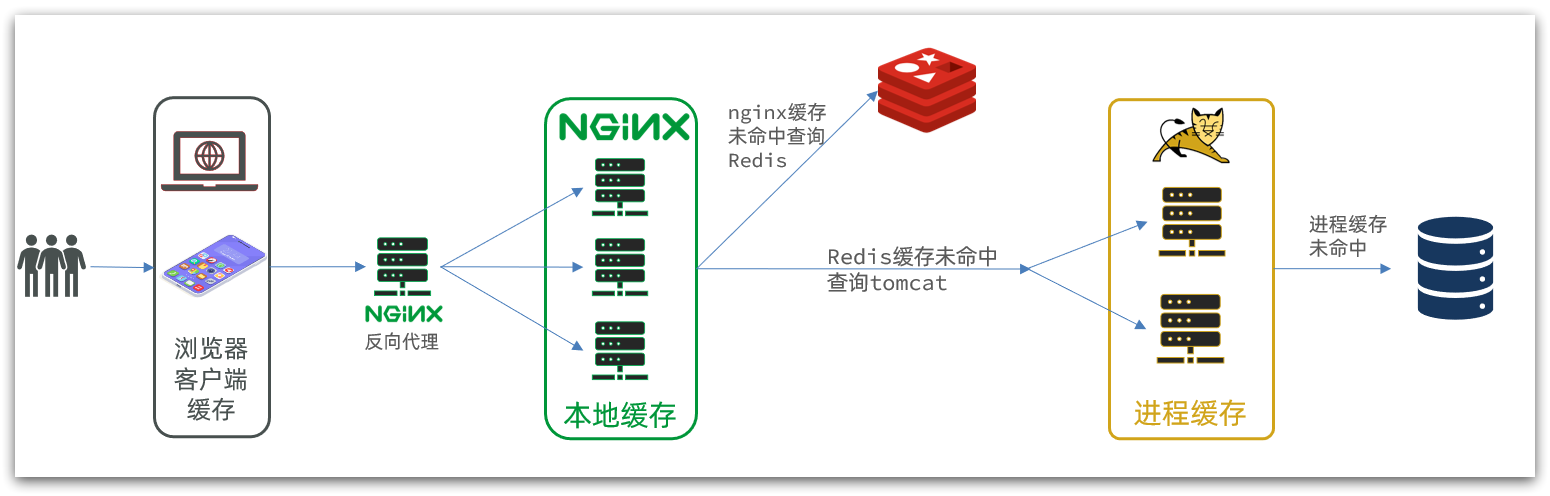
可見,多級緩存的關鍵有兩個:
-
一個是在nginx中編寫業務,實現nginx本地緩存、Redis、Tomcat的查詢
-
另一個就是在Tomcat中實現JVM進程緩存
其中Nginx編程則會用到OpenResty框架結合Lua這樣的語言。
這也是今天學習的難點和重點。
商品查詢業務案例導入
為了演示多級緩存,我們先導入一個商品管理的案例,其中包含商品的CRUD功能。我們將來會給查詢商品添加多級緩存。
1.安裝MySQL
后期做數據同步需要用到MySQL的主從功能,所以需要大家在虛擬機中,利用Docker來運行一個MySQL容器。
1.1.準備目錄
為了方便后期配置MySQL,我們先準備兩個目錄,用于掛載容器的數據和配置文件目錄:
# 進入/tmp目錄
cd /tmp
# 創建文件夾
mkdir mysql
# 進入mysql目錄
cd mysql
1.2.運行命令
進入mysql目錄后,執行下面的Docker命令:
docker run \-p 3306:3306 \--name mysql \-v $PWD/conf:/etc/mysql/conf.d \ # 掛載mysql配置文件目錄-v $PWD/logs:/logs \ # 掛載mysql日志文件目錄-v $PWD/data:/var/lib/mysql \ # 掛載mysql數據文件目錄-e MYSQL_ROOT_PASSWORD=123 \ # 指定root賬號和密碼--privileged \-d \mysql:5.7.25
1.3.修改配置
在/tmp/mysql/conf目錄添加一個my.cnf文件,作為mysql的配置文件:
# 創建文件
touch /tmp/mysql/conf/my.cnf
文件的內容如下,都是mysql的默認配置,主要配的就是字符的編碼改成utf-8
[mysqld]
# 跳過域名解析,速度加載可以更快
skip-name-resolve
# 字符編碼
character_set_server=utf8
# 指定數據庫的目錄 與我們掛載的目錄保持一致
datadir=/var/lib/mysql
# 服務id
server-id=1000
1.4.重啟
配置修改后,必須重啟容器:
docker restart mysql
2.導入SQL
接下來,利用Navicat客戶端連接MySQL,創建新的數據庫,然后導入課前資料提供的sql文件:
/*Navicat Premium Data TransferSource Server : 192.168.150.101Source Server Type : MySQLSource Server Version : 50725Source Host : 192.168.150.101:3306Source Schema : heimaTarget Server Type : MySQLTarget Server Version : 50725File Encoding : 65001Date: 16/08/2021 14:45:07
*/SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for tb_item
-- ----------------------------
DROP TABLE IF EXISTS `tb_item`;
CREATE TABLE `tb_item` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '商品id',`title` varchar(264) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品標題',`name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '商品名稱',`price` bigint(20) NOT NULL COMMENT '價格(分)',`image` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品圖片',`category` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '類目名稱',`brand` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌名稱',`spec` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '規格',`status` int(1) NULL DEFAULT 1 COMMENT '商品狀態 1-正常,2-下架,3-刪除',`create_time` datetime NULL DEFAULT NULL COMMENT '創建時間',`update_time` datetime NULL DEFAULT NULL COMMENT '更新時間',PRIMARY KEY (`id`) USING BTREE,INDEX `status`(`status`) USING BTREE,INDEX `updated`(`update_time`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 50002 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '商品表' ROW_FORMAT = COMPACT;-- ----------------------------
-- Records of tb_item
-- ----------------------------
INSERT INTO `tb_item` VALUES (10001, 'RIMOWA 21寸托運箱拉桿箱 SALSA AIR系列果綠色 820.70.36.4', 'SALSA AIR', 16900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp', '拉桿箱', 'RIMOWA', '{\"顏色\": \"紅色\", \"尺碼\": \"26寸\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10002, '安佳脫脂牛奶 新西蘭進口輕欣脫脂250ml*24整箱裝*2', '脫脂牛奶', 68600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t25552/261/1180671662/383855/33da8faa/5b8cf792Neda8550c.jpg!q70.jpg.webp', '牛奶', '安佳', '{\"數量\": 24}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10003, '唐獅新品牛仔褲女學生韓版寬松褲子 A款/中牛仔藍(無絨款) 26', '韓版牛仔褲', 84600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t26989/116/124520860/644643/173643ea/5b860864N6bfd95db.jpg!q70.jpg.webp', '牛仔褲', '唐獅', '{\"顏色\": \"藍色\", \"尺碼\": \"26\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10004, '森馬(senma)休閑鞋女2019春季新款韓版系帶板鞋學生百搭平底女鞋 黃色 36', '休閑板鞋', 10400, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/29976/8/2947/65074/5c22dad6Ef54f0505/0b5fe8c5d9bf6c47.jpg!q70.jpg.webp', '休閑鞋', '森馬', '{\"顏色\": \"白色\", \"尺碼\": \"36\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10005, '花王(Merries)拉拉褲 M58片 中號尿不濕(6-11kg)(日本原裝進口)', '拉拉褲', 38900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t24370/119/1282321183/267273/b4be9a80/5b595759N7d92f931.jpg!q70.jpg.webp', '拉拉褲', '花王', '{\"型號\": \"XL\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');-- ----------------------------
-- Table structure for tb_item_stock
-- ----------------------------
DROP TABLE IF EXISTS `tb_item_stock`;
CREATE TABLE `tb_item_stock` (`item_id` bigint(20) NOT NULL COMMENT '商品id,關聯tb_item表',`stock` int(10) NOT NULL DEFAULT 9999 COMMENT '商品庫存',`sold` int(10) NOT NULL DEFAULT 0 COMMENT '商品銷量',PRIMARY KEY (`item_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;-- ----------------------------
-- Records of tb_item_stock
-- ----------------------------
INSERT INTO `tb_item_stock` VALUES (10001, 99996, 3219);
INSERT INTO `tb_item_stock` VALUES (10002, 99999, 54981);
INSERT INTO `tb_item_stock` VALUES (10003, 99999, 189);
INSERT INTO `tb_item_stock` VALUES (10004, 99999, 974);
INSERT INTO `tb_item_stock` VALUES (10005, 99999, 18649);SET FOREIGN_KEY_CHECKS = 1;
其中包含兩張表:
- tb_item:商品表,包含商品的基本信息
- tb_item_stock:商品庫存表,包含商品的庫存信息
之所以將庫存分離出來,是因為庫存是更新比較頻繁的信息,寫操作較多。而其他信息修改的頻率非常低,如果放在一起,每次修改整條數據作廢,那么緩存失效的頻率就太高了,所以需要做數據分離,真實的商品數據可能要有好幾張表,將來有好幾個不同的緩存。
3.導入Demo工程
下面導入課前資料提供的工程,項目結構如圖所示:

其中的業務包括:
- 分頁查詢商品
- 新增商品
- 修改商品
- 修改庫存
- 刪除商品
- 根據id查詢商品
- 根據id查詢庫存
業務全部使用mybatis-plus來實現
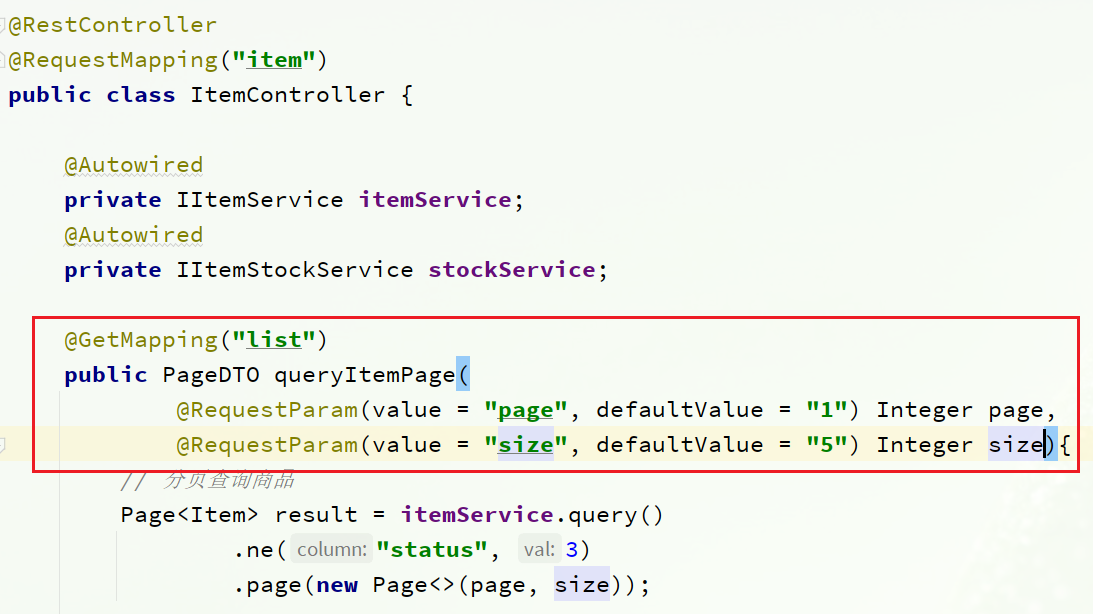
3.1.分頁查詢商品
在com.heima.item.web包的ItemController中可以看到接口定義:
3.2.新增商品
在com.heima.item.web包的ItemController中可以看到接口定義:

3.3.修改商品
在com.heima.item.web包的ItemController中可以看到接口定義:

3.4.修改庫存
在com.heima.item.web包的ItemController中可以看到接口定義:

3.5.刪除商品
在com.heima.item.web包的ItemController中可以看到接口定義,這里是采用了邏輯刪除,將商品狀態修改為3。

3.6.根據id查詢商品
在com.heima.item.web包的ItemController中可以看到接口定義,這里只返回了商品信息,不包含庫存

3.7.根據id查詢庫存
在com.heima.item.web包的ItemController中可以看到接口定義

3.8.啟動
注意修改application.yml文件中配置的mysql地址信息,需要修改為自己的虛擬機地址信息、還有賬號和密碼。
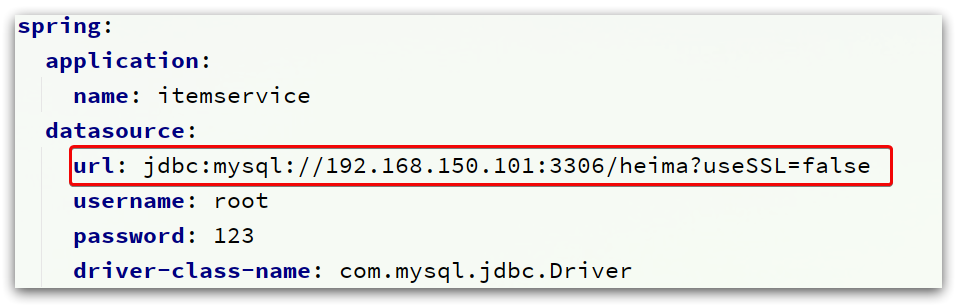
修改后,啟動服務,訪問:http://localhost:8081/item/10001即可查詢商品數據,訪問http://localhost:8081/item/stock/10001即可查詢商品對應庫存。
4.導入商品查詢頁面
商品查詢是購物頁面,與商品管理的頁面是分離的。部署方式如圖:
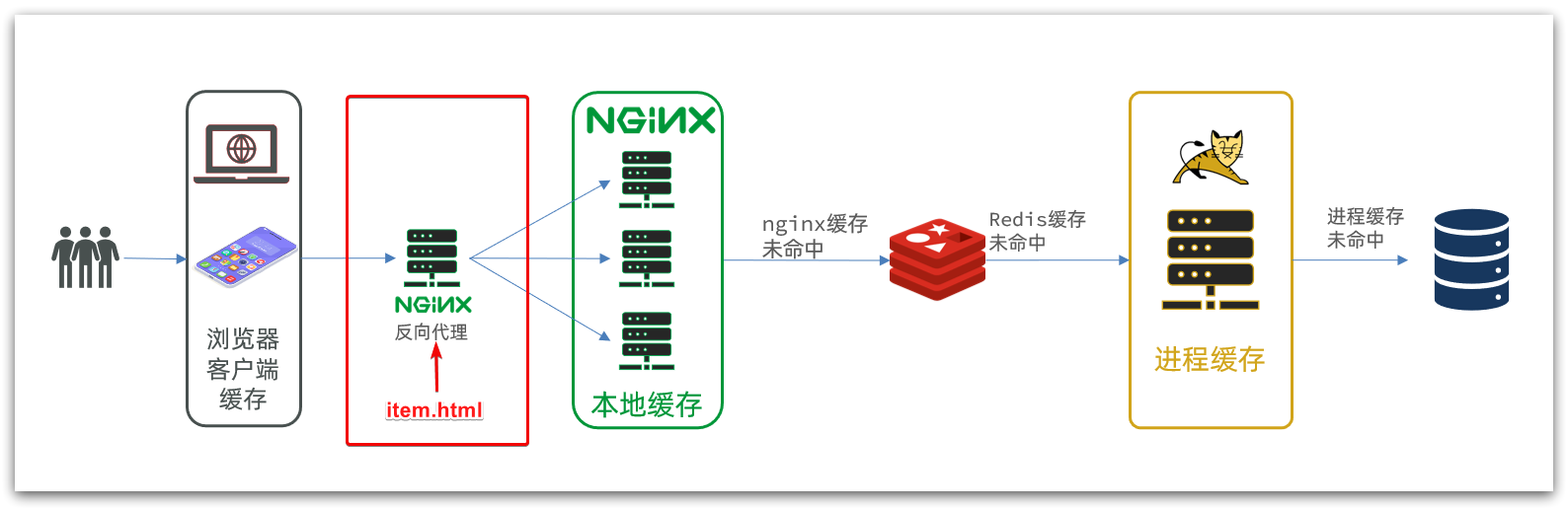
我們需要準備一個反向代理的nginx服務器,如上圖紅框所示,將靜態的商品頁面放到nginx目錄中。
頁面需要的數據通過ajax向服務端(nginx業務集群)查詢。
4.1.運行nginx服務
這里我已經給大家準備好了nginx反向代理服務器和靜態資源。
我們找到課前資料的nginx目錄:
將其拷貝到一個非中文目錄下,其中html目錄存放著頁面資源:
運行這個nginx服務。運行命令:
start nginx.exe
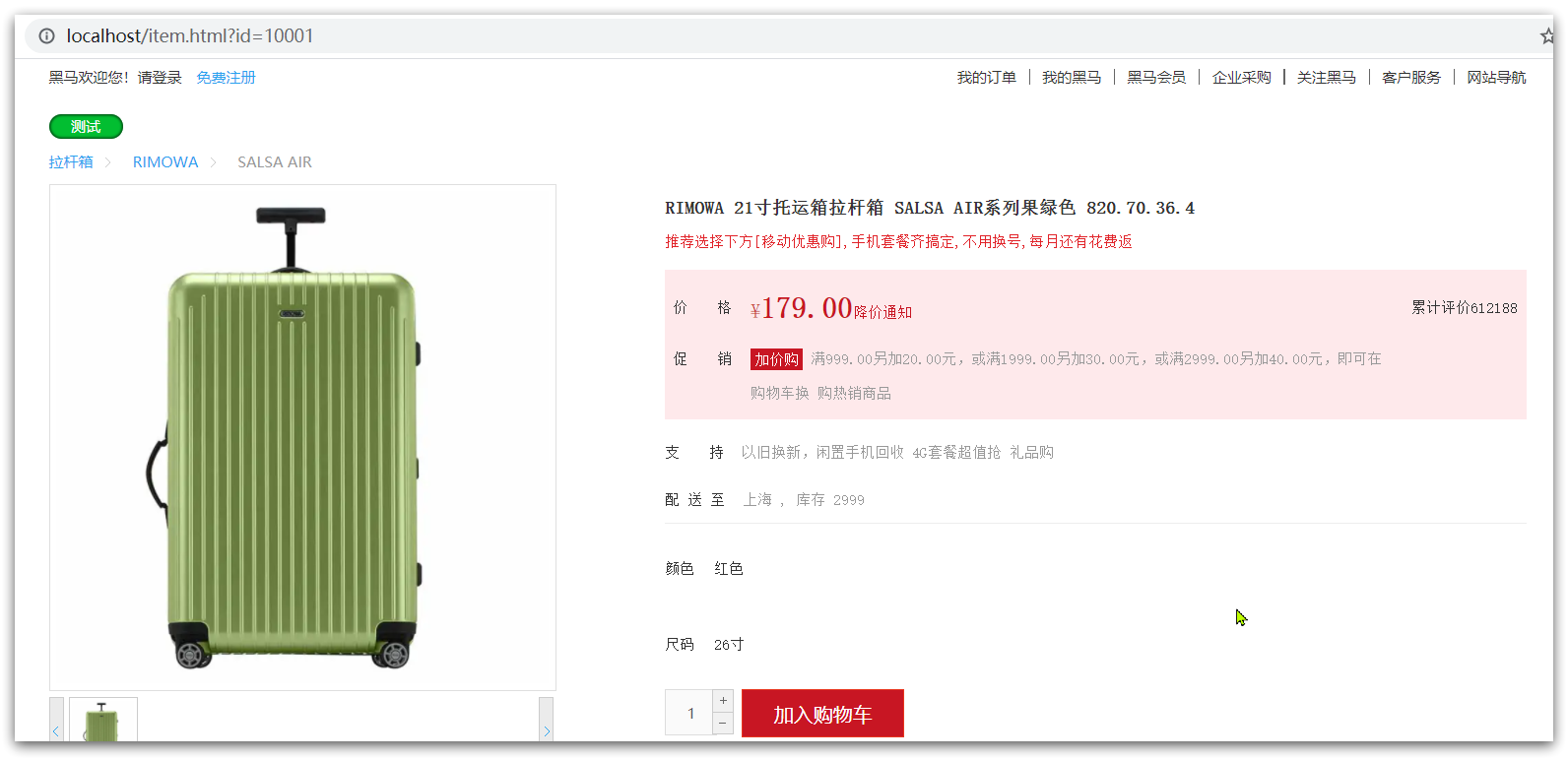
然后訪問 http://localhost/item.html?id=10001即可訪問商品:
4.2.反向代理
但是現在,頁面是假數據展示的(前端寫死)。我們需要向服務器發送ajax請求,查詢商品數據。
打開控制臺,可以看到頁面有發起ajax查詢數據:
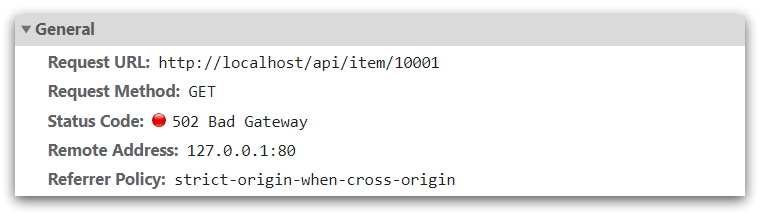
而這個請求地址同樣是80端口(沒加端口默認html是80,也是Nginx 默認監聽端口),所以被當前的nginx反向代理了,所以我們需要在當前的nginx做反向代理的配置。
查看nginx的conf目錄下的nginx.conf文件:
其中的關鍵配置如下:
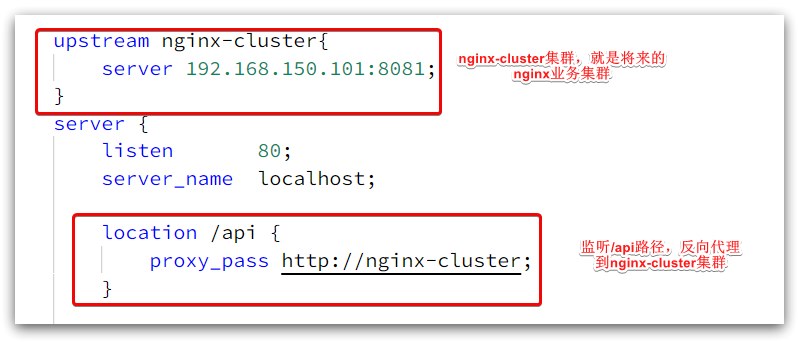
其中的192.168.150.101是我的虛擬機IP,也就是我的Nginx業務集群要部署的地方:
完整內容如下:
#user nobody;
worker_processes 1;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;#tcp_nopush on;keepalive_timeout 65;# nginx的業務集群(在這里做nginx本地緩存、redis緩存、tomcat查詢等)upstream nginx-cluster{# 還沒做集群 先配一個 這里ip是我的虛擬機ipserver 192.168.150.101:8081;}server {listen 80;server_name localhost;# /api接口反向代理到/nginx-cluster(nginx里的負載均衡的配置,在上面定義了)location /api {proxy_pass http://nginx-cluster;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
以上就是整個商品查詢案例的導入了,我們把架子搭好了。tomcat有了,數據有了,反向代理服務器也準備好了,瀏覽器也有了,現在差的是下面框內的部分,下面我們去實現。
1.JVM進程緩存
初識Caffeine
緩存在日常開發中啟動至關重要的作用,由于是存儲在內存中,數據的讀取速度是非常快的,能大量減少對數據庫的訪問,減少數據庫的壓力。我們把緩存分為兩類:
- 分布式緩存,例如Redis:
- 優點:存儲容量更大(Redis本身可以搭建集群)、可靠性更好(哨兵、主從)、可以在集群間共享(多臺tomcat都可以訪問同一個Redis緩存)
- 缺點:訪問緩存有網絡開銷(獨立于tomcat之外)
- 場景:緩存數據量較大、可靠性要求較高、需要在集群間共享
- 進程本地緩存,例如HashMap、GuavaCache:
- 優點:讀取本地內存,沒有網絡開銷,速度更快
- 缺點:存儲容量有限(上限就是這臺tomcat服務器的JVM堆內存上限,而且不能獨占,否則程序運行有問題)、可靠性較低(tomcat重啟、宕機則數據丟失)、無法共享(tomcat與tomcat之間)
- 場景:性能要求較高,緩存數據量較小
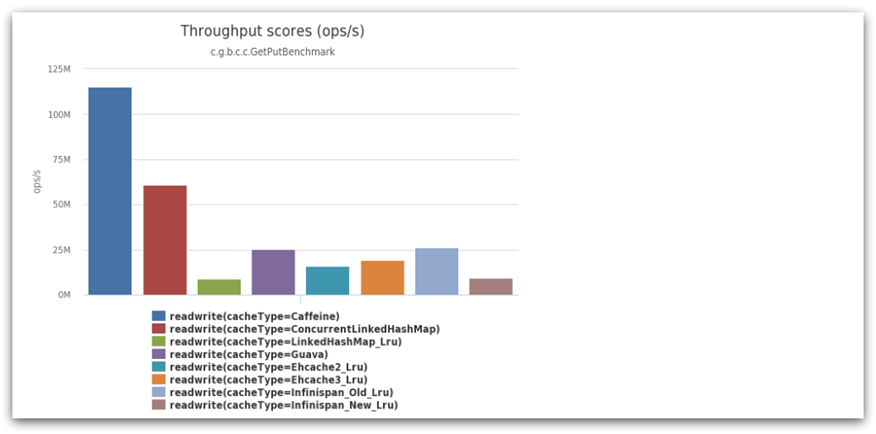
我們今天會利用Caffeine框架來實現JVM進程緩存。Caffeine是一個基于Java8開發的,提供了近乎最佳命中率的高性能的本地緩存庫。目前Spring內部的緩存使用的就是Caffeine。GitHub地址
Caffeine的性能非常好,下圖是官方給出的性能對比,可以看到Caffeine的性能遙遙領先
緩存使用的基本API:
@Test
void testBasicOps() {// 構建cache對象Cache<String, String> cache = Caffeine.newBuilder().build();// 存數據cache.put("gf", "迪麗熱巴");// 取數據,不存在則返回nullString gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 上面的取法不是用的最多的,因為一般緩存沒命中要去查數據庫,查完后再寫到緩存里,把結果返回給用戶// 去Caffeine也提供了這樣的一個api取數據,包含兩個參數:// 參數一:緩存的key// 參數二:Lambda表達式,表達式的參數就是緩存的key,方法體是自定義的后續邏輯(例如查詢數據庫),查詢到的結果會被存入緩存,并且返回給調用者。// 優先根據key查詢JVM緩存,如果未命中,則執行參數二的Lambda表達式,并將查詢到的結果存入緩存中String defaultGF = cache.get("defaultGF", key -> {// 根據key去數據庫查詢數據return "柳巖";});System.out.println("defaultGF = " + defaultGF);
}

與TTS的深度融合)

 打包詳解)



主要應用在什么方面?涉及到具體知識是什么?)




顏色空間轉換-----將圖像從 RGB 色彩空間轉換為 YUV 色彩空間函數RGB2YUV())
入門階段詳細指南)

![[GXYCTF2019]Ping Ping Ping](http://pic.xiahunao.cn/[GXYCTF2019]Ping Ping Ping)



