在當今社會,隨著科技生產力的飛速發展,汽車早已成為人們日常出行不可或缺的交通工具。它不僅極大地提高了人們的出行效率,也為生活帶來了諸多便利。然而,隨著汽車保有量的不斷增加,交通安全問題也日益凸顯。疲勞駕駛和分心駕駛是導致交通事故的兩大隱形殺手,它們嚴重威脅著司機和他人的生命安全。幸運的是,隨著人工智能技術的蓬勃發展,我們有了應對這些安全隱患的新利器。疲勞駕駛和分心駕駛的危害不言而喻。長時間駕駛會使司機身體和精神處于高度緊張狀態,反應速度和判斷能力會逐漸下降,極易引發交通事故。而分心駕駛,如接打電話、玩手機、整理妝容等行為,會讓司機的注意力從道路上轉移,大大增加了事故發生的概率。據統計,每年因疲勞駕駛或分心駕駛導致的交通事故數量驚人,這不僅給無數家庭帶來了痛苦,也給社會造成了巨大的損失。
然而,科技的進步總是在為人類的安全保駕護航。如今,人工智能技術已經滲透到我們生活的方方面面,汽車駕駛領域也不例外。借助車載內置安裝的多攝像頭,我們可以實時捕捉司機駕駛過程中的畫面。這些攝像頭就像是汽車的“眼睛”,能夠全方位地觀察司機的一舉一動。而基于人工智能的檢測識別預警模型,則是汽車的“大腦”,能夠對這些畫面進行智能分析識別。當司機出現疲勞駕駛或分心駕駛的跡象時,如頻繁眨眼、打哈欠、目光偏離前方、操作儀表等行為,預警模型能夠迅速捕捉到這些異常信號,并進行精準判定。一旦判定當前狀態為疲勞駕駛或分心駕駛,系統會立即發出預警信息,提醒司機集中精神或盡快行駛到安全區域休息。這種預警機制不僅能夠及時發現潛在的安全隱患,還能在關鍵時刻挽救生命。人工智能技術在車輛駕駛場景中的應用,不僅僅局限于疲勞駕駛和分心駕駛的檢測。它還可以通過分析道路狀況、交通流量等信息,為司機提供更安全、更高效的駕駛建議。例如,當遇到復雜路況時,系統可以提前預警并建議司機減速慢行;當發現前方有危險時,系統可以及時提醒司機采取避讓措施。這些智能化的功能,讓駕駛變得更加安全、便捷。
本文正是在這樣的思考背景下,想要探索嘗試從實驗性質的角度出來構建分心駕駛智能化檢測識別系統,首先看下實例效果:

接下來看下實例數據:
YOLOv5(You Only Look Once version 5)是YOLO系列目標檢測算法的經典版本,由Ultralytics團隊于2020年發布。其構建原理主要基于深度學習技術,通過構建神經網絡模型來實現對圖像中目標的快速、準確檢測。
YOLOv5的模型結構主要由以下幾個核心部分組成:
輸入端:
Mosaic圖像增強:通過組合多個不同的圖像來生成新的訓練圖像,增加數據集的多樣性,提高模型的魯棒性。
自適應錨框計算:自動計算出最適合輸入圖像的錨框參數,提高目標檢測的精度。
自適應圖片縮放:根據目標尺度自適應地縮放輸入圖像的尺寸,以適應不同尺度目標的檢測。
Backbone層:
通常采用CSPDarknet53作為主干網絡,具有較強的特征提取能力和計算效率。
Focus結構:用于特征提取的卷積神經網絡層,對輸入特征圖進行下采樣,減少計算量和參數量。
Neck網絡:
主要負責跨層特征融合和處理,提升模型對小目標的檢測效果。常見的結構包括FPN(特征金字塔網絡)和PANet等。
Head網絡:
包含預測層,用于生成目標檢測框和類別置信度等信息。
損失函數:
采用常見的目標檢測損失函數,如IOU損失、二值交叉熵損失等,以及Focal Loss等用于緩解類別不平衡問題的損失函數。
二、技術亮點
單階段檢測:YOLOv5在單階段內完成了目標的定位和分類,大大簡化了檢測流程,提高了檢測速度。
高精度與高速度:通過優化模型結構和參數,YOLOv5在保持高精度(mAP可達83.8%)的同時,實現了較快的檢測速度(可達140FPS),適用于實時檢測場景。
易用性與可擴展性:YOLOv5提供了簡單易用的接口和多種預訓練模型,便于用戶進行模型訓練和部署。同時,支持自定義數據集進行訓練,具有良好的可擴展性。
數據增強技術:如Mosaic圖像增強等技術的應用,有效增加了數據集的多樣性,提高了模型的魯棒性和泛化能力。
三、優劣分析
優點:
速度快:YOLOv5的檢測速度非常快,適用于實時性要求較高的應用場景。
精度高:在多種目標檢測任務中表現出色,具有較高的準確率。
易于訓練與部署:提供了簡單易用的接口和多種預訓練模型,降低了模型訓練和部署的門檻。
可擴展性強:支持自定義數據集進行訓練,適用于不同場景下的目標檢測任務。
缺點:
對小目標檢測效果不佳:相比于一些專門針對小目標檢測的算法,YOLOv5在小目標檢測上的表現可能有所不足。
對密集目標檢測效果不佳:在密集目標檢測場景中,YOLOv5可能會出現重疊框的問題,影響檢測效果。
需要更多的訓練數據:為了達到更好的檢測效果,YOLOv5需要更多的訓練數據來支撐模型的訓練過程。
YOLOv5算法模型以其單階段檢測、高精度與高速度、易用性與可擴展性等優勢在目標檢測領域取得了顯著成效。然而,在應對小目標和密集目標檢測等挑戰時仍需進一步優化和改進。
實驗截止目前,本文將YOLOv5系列五款不同參數量級的模型均進行了開發評測,接下來看下模型詳情:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5# Parameters
nc: 10 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 1024]l: [1.00, 1.00, 1024]x: [1.33, 1.25, 1024]# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)]實驗階段我們保持完全相同的參數設置,等待五款參數量級的模型全部開發訓練完成后來對其進行全方位各指標的對比分析。
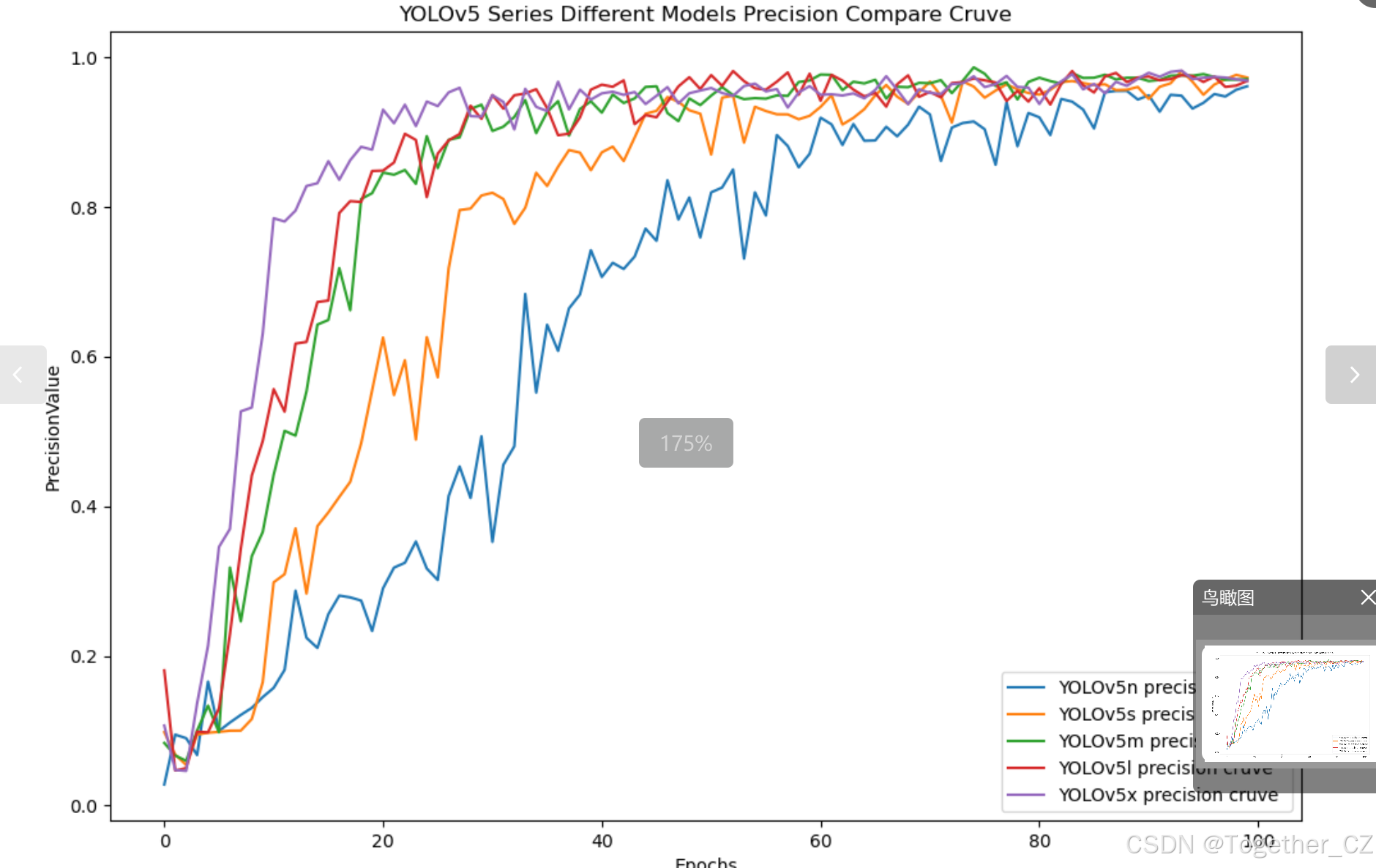
【Precision曲線】
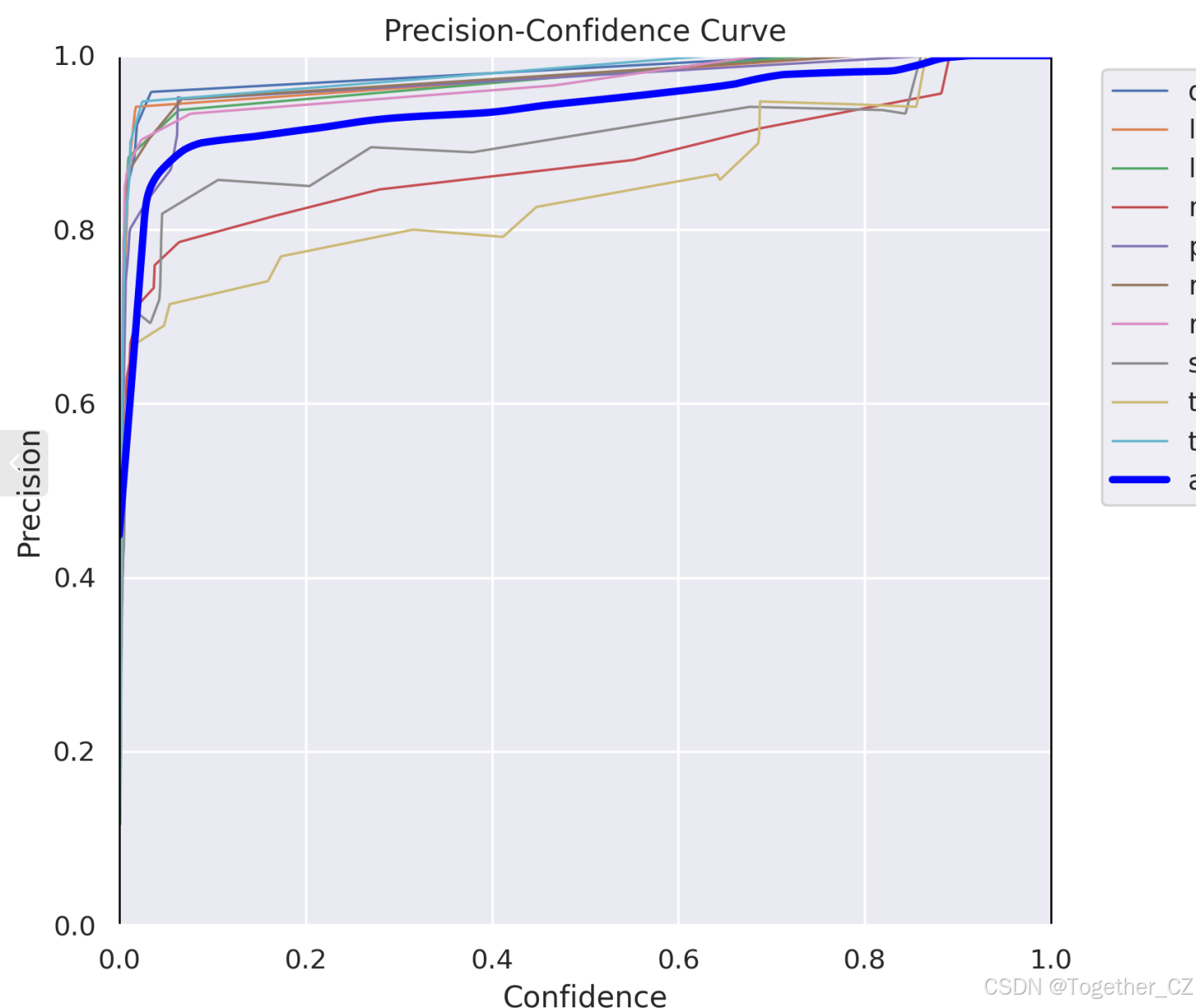
精確率曲線(Precision Curve)是一種用于評估二分類模型在不同閾值下的精確率性能的可視化工具。它通過繪制不同閾值下的精確率和召回率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率(Precision)是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率曲線。
根據精確率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察精確率曲線,我們可以根據需求確定最佳的閾值,以平衡精確率和召回率。較高的精確率意味著較少的誤報,而較高的召回率則表示較少的漏報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
精確率曲線通常與召回率曲線(Recall Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。
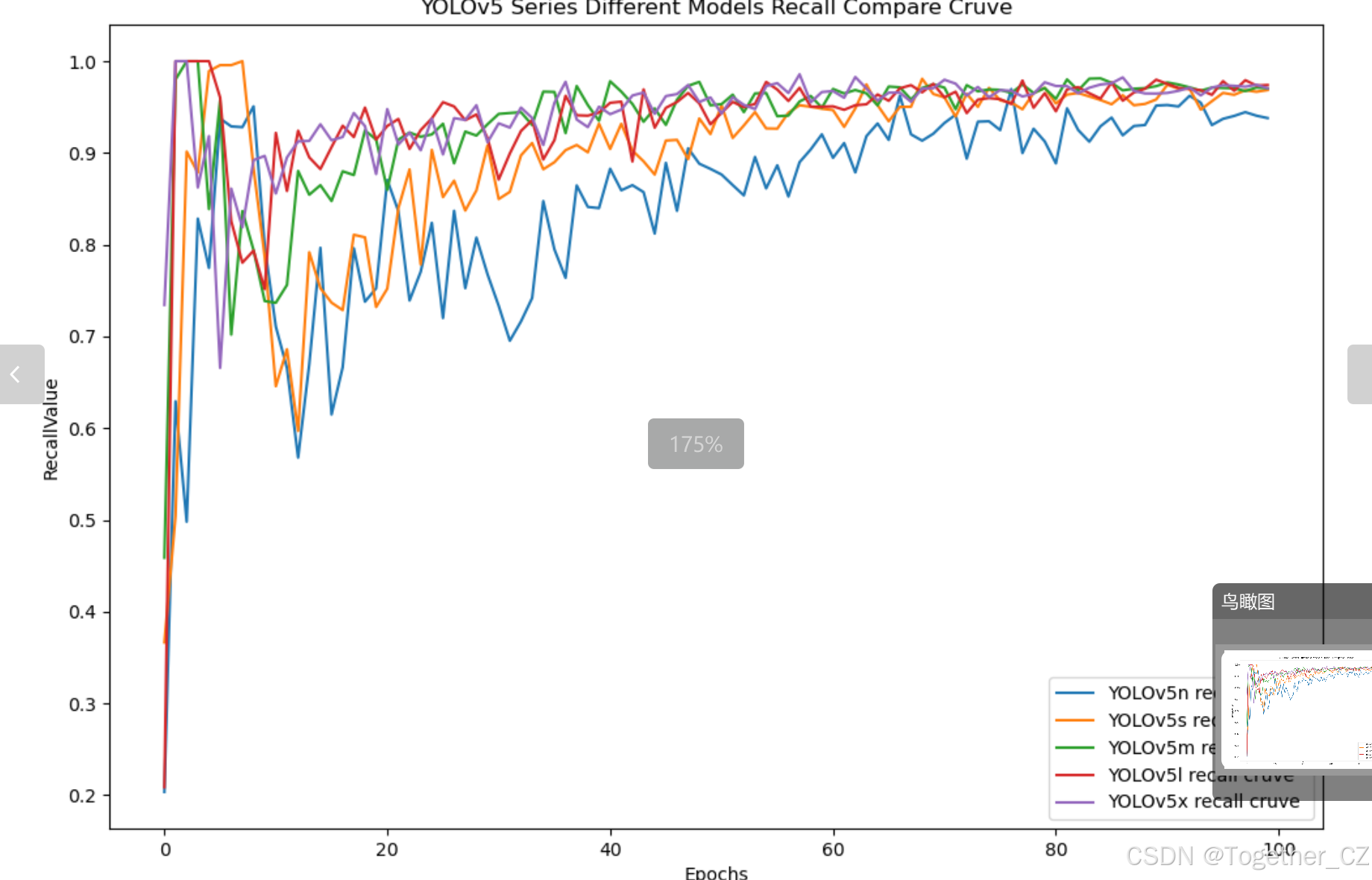
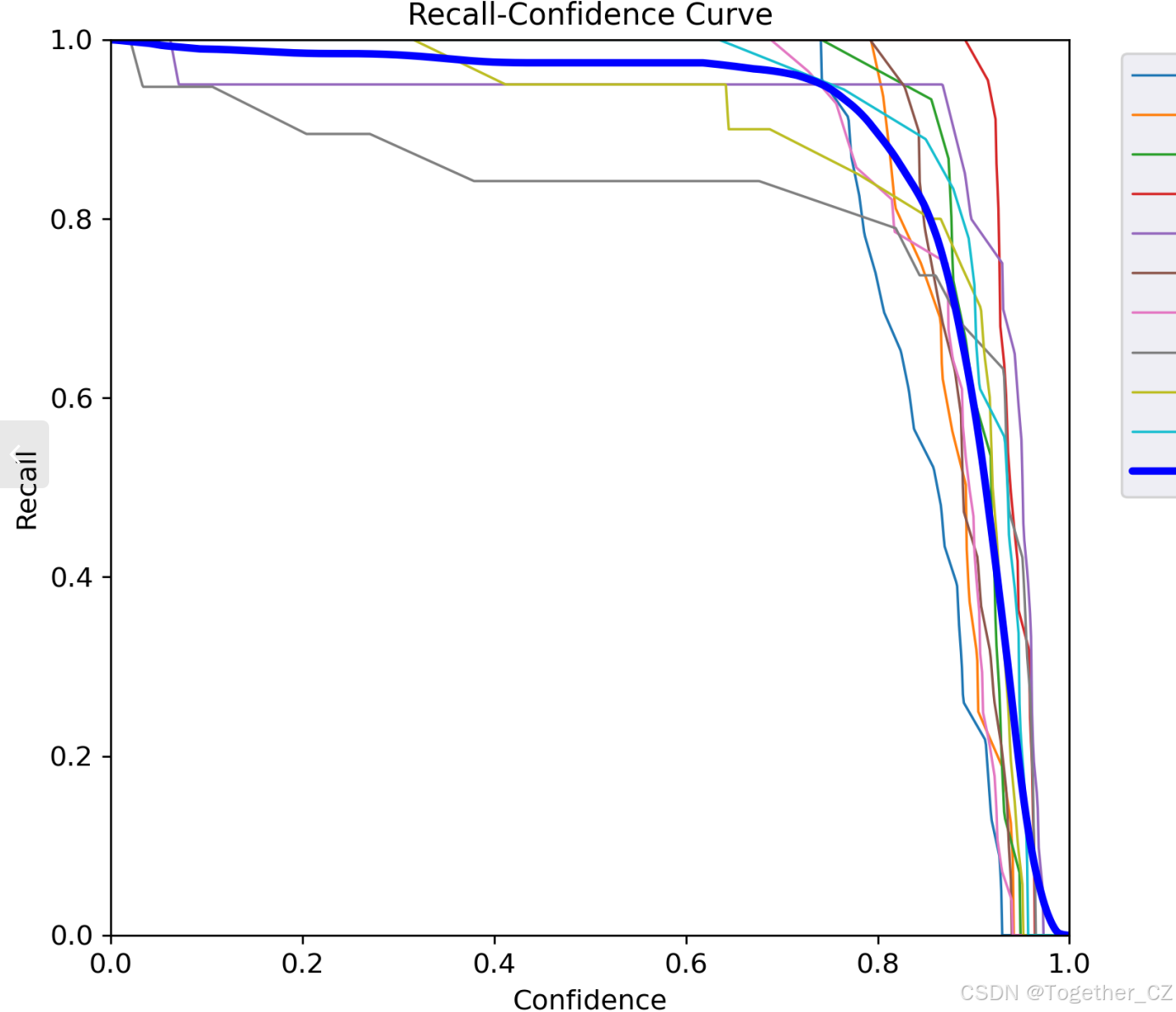
【Recall曲線】
召回率曲線(Recall Curve)是一種用于評估二分類模型在不同閾值下的召回率性能的可視化工具。它通過繪制不同閾值下的召回率和對應的精確率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。召回率也被稱為靈敏度(Sensitivity)或真正例率(True Positive Rate)。
繪制召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的召回率和對應的精確率。
將每個閾值下的召回率和精確率繪制在同一個圖表上,形成召回率曲線。
根據召回率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察召回率曲線,我們可以根據需求確定最佳的閾值,以平衡召回率和精確率。較高的召回率表示較少的漏報,而較高的精確率意味著較少的誤報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
召回率曲線通常與精確率曲線(Precision Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。
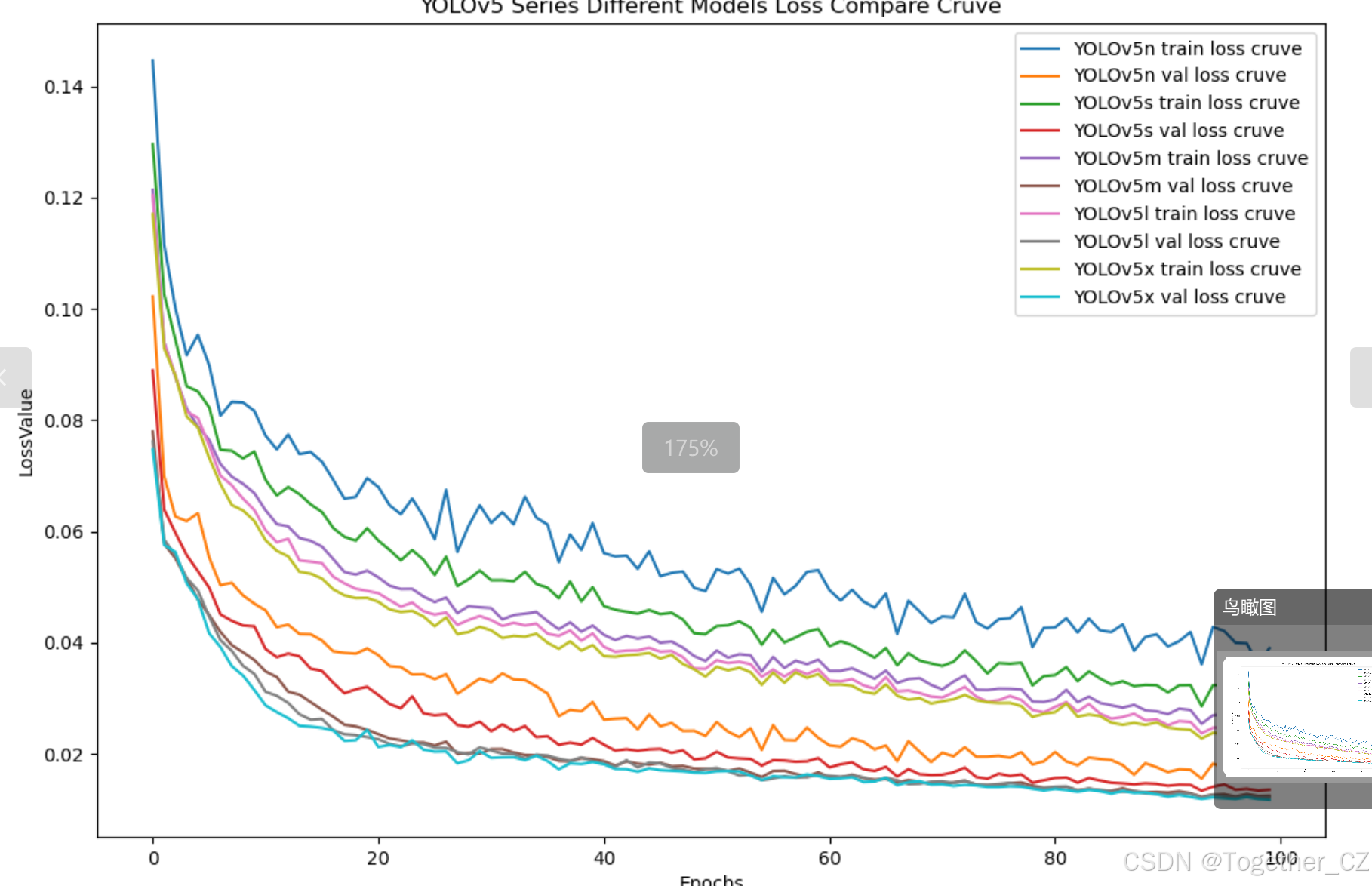
【loss曲線】
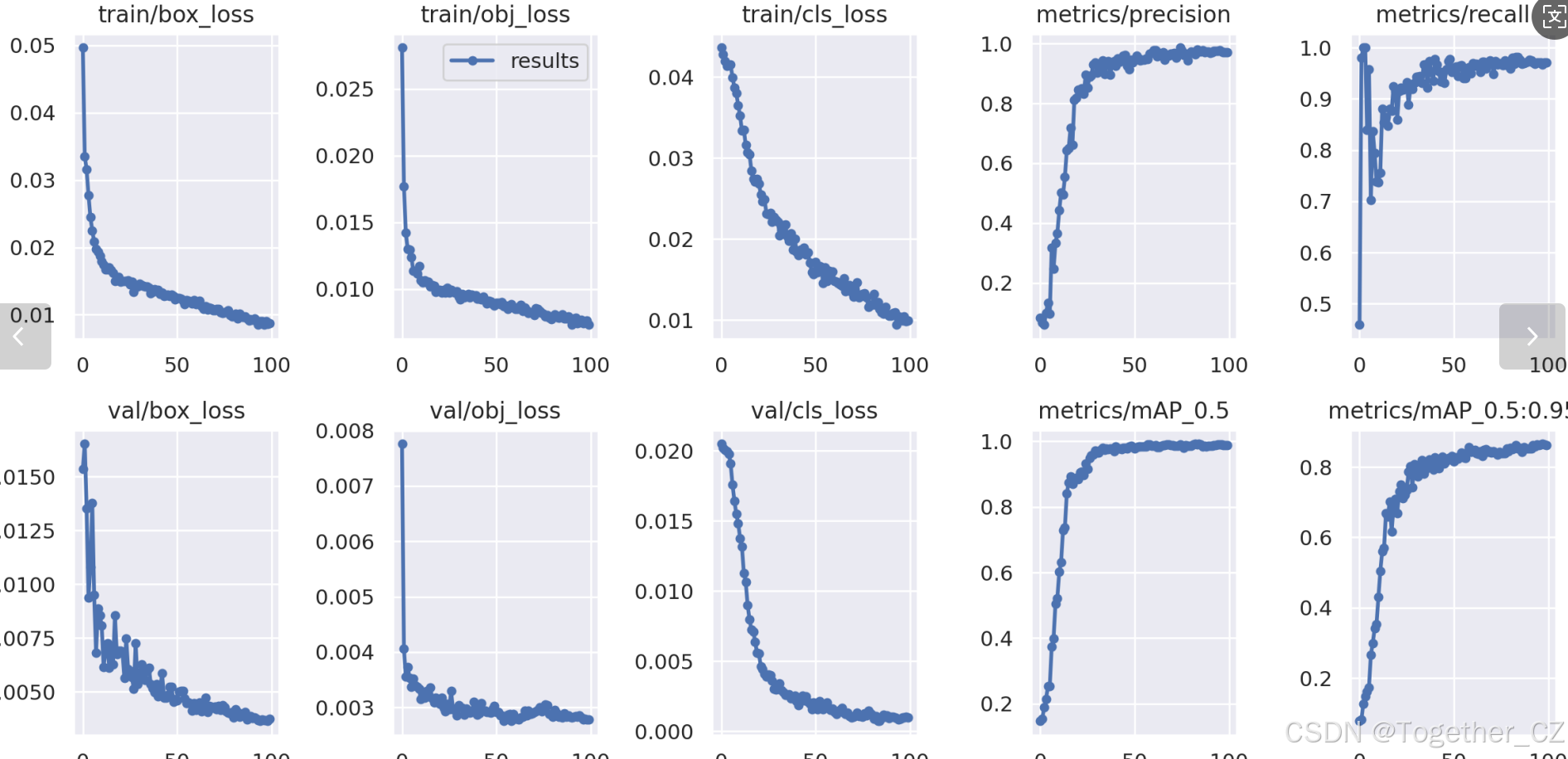
在深度學習的訓練過程中,loss函數用于衡量模型預測結果與實際標簽之間的差異。loss曲線則是通過記錄每個epoch(或者迭代步數)的loss值,并將其以圖形化的方式展現出來,以便我們更好地理解和分析模型的訓練過程。
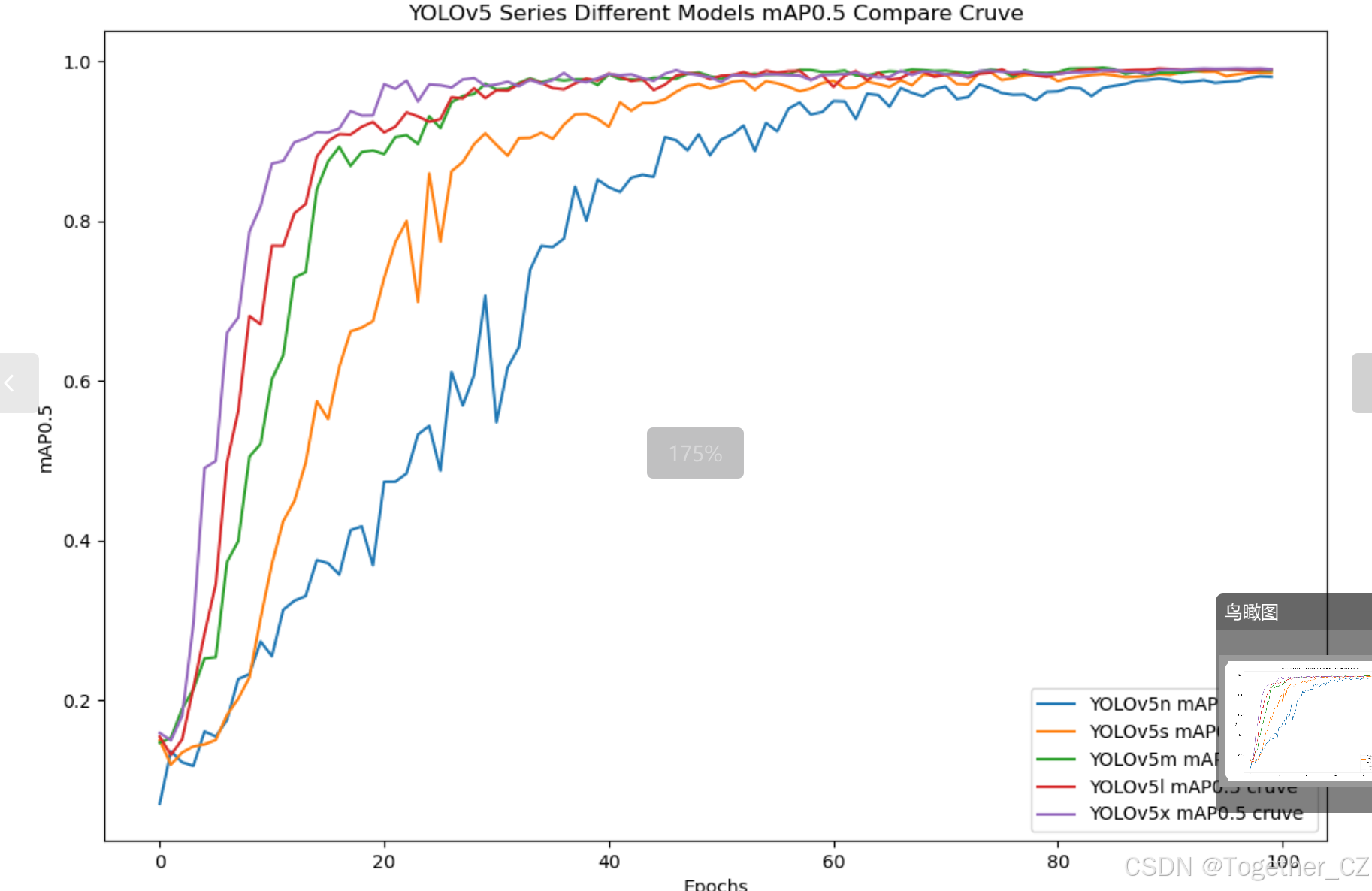
【mAP0.5】
mAP0.5,也被稱為mAP@0.5或AP50,指的是當Intersection over Union(IoU)閾值為0.5時的平均精度(mean Average Precision)。IoU是一個用于衡量預測邊界框與真實邊界框之間重疊程度的指標,其值范圍在0到1之間。當IoU值為0.5時,意味著預測框與真實框至少有50%的重疊部分。
在計算mAP0.5時,首先會為每個類別計算所有圖片的AP(Average Precision),然后將所有類別的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲線下面的面積,這個面積越大,說明AP的值越大,類別的檢測精度就越高。
mAP0.5主要關注模型在IoU閾值為0.5時的性能,當mAP0.5的值很高時,說明算法能夠準確檢測到物體的位置,并且將其與真實標注框的IoU值超過了閾值0.5。
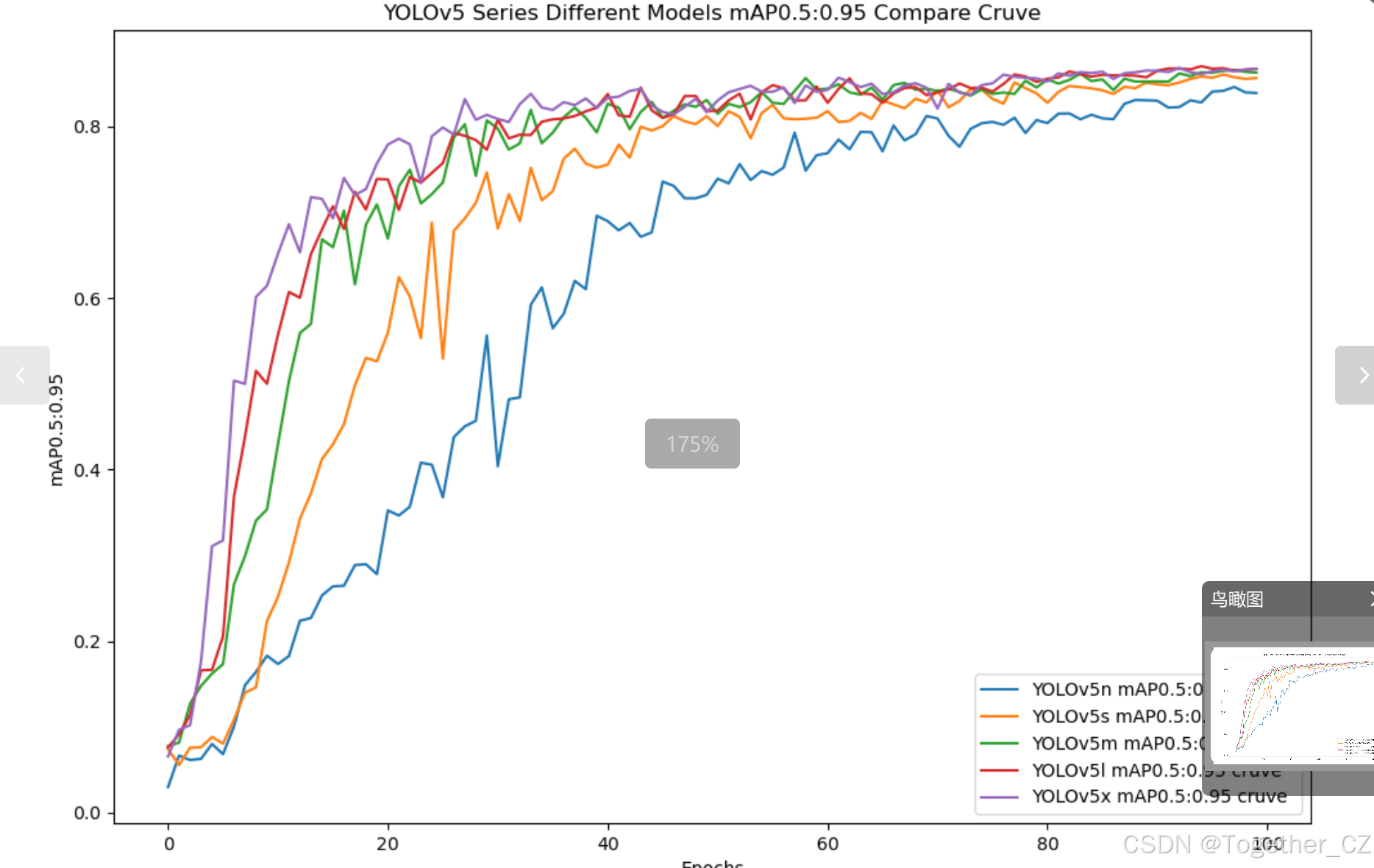
【mAP0.5:0.95】
mAP0.5:0.95,也被稱為mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU閾值從0.5到0.95變化時,取各個閾值對應的mAP的平均值。具體來說,它會在IoU閾值從0.5開始,以0.05為步長,逐步增加到0.95,并在每個閾值下計算mAP,然后將這些mAP值求平均。
這個指標考慮了多個IoU閾值下的平均精度,從而更全面、更準確地評估模型性能。當mAP0.5:0.95的值很高時,說明算法在不同閾值下的檢測結果均非常準確,覆蓋面廣,可以適應不同的場景和應用需求。
對于一些需求比較高的場合,比如安全監控等領域,需要保證高的準確率和召回率,這時mAP0.5:0.95可能更適合作為模型的評價標準。
綜上所述,mAP0.5和mAP0.5:0.95都是用于評估目標檢測模型性能的重要指標,但它們的關注點有所不同。mAP0.5主要關注模型在IoU閾值為0.5時的性能,而mAP0.5:0.95則考慮了多個IoU閾值下的平均精度,從而更全面、更準確地評估模型性能。
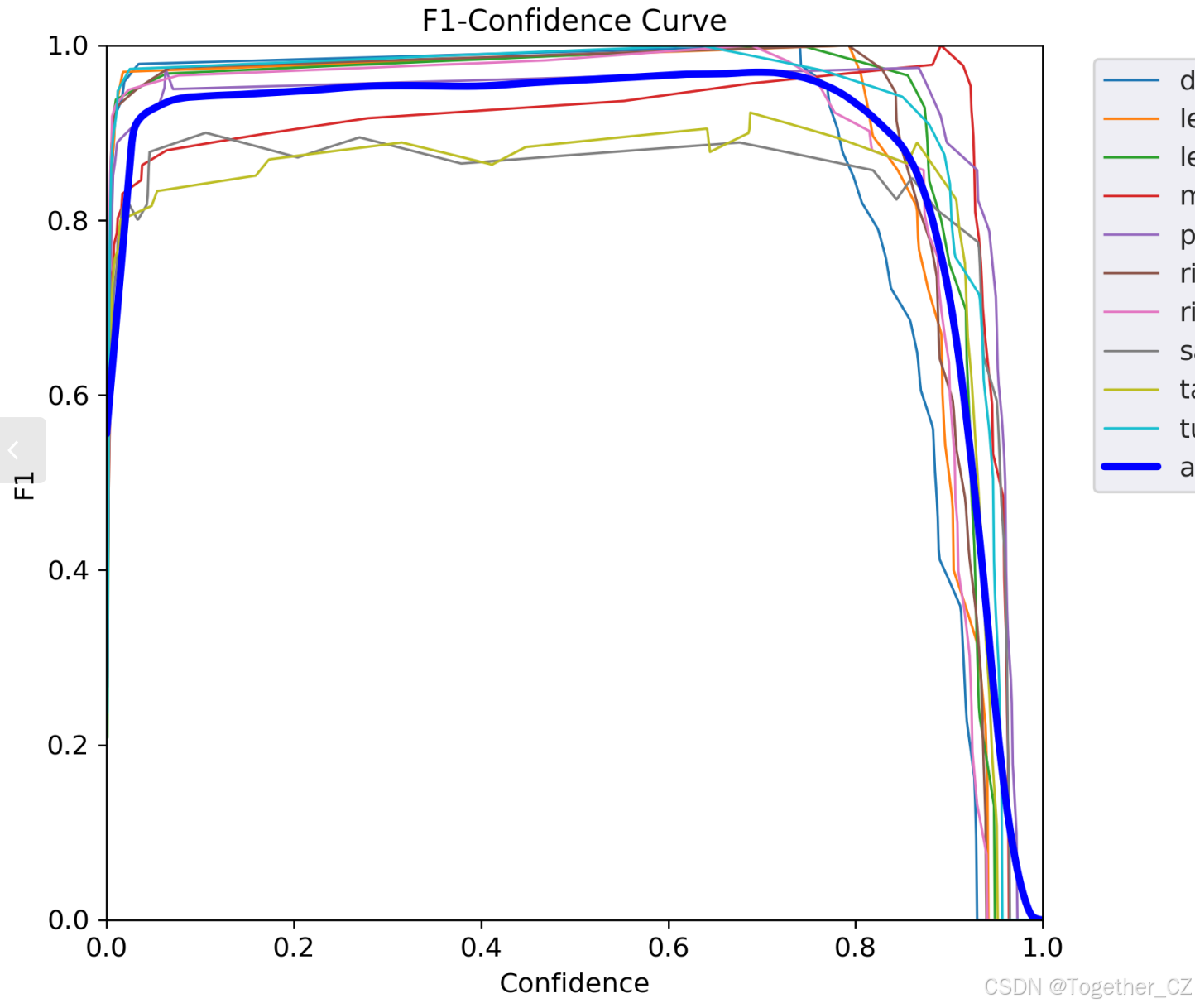
【F1值曲線】
F1值曲線是一種用于評估二分類模型在不同閾值下的性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)、召回率(Recall)和F1分數的關系圖來幫助我們理解模型的整體性能。
F1分數是精確率和召回率的調和平均值,它綜合考慮了兩者的性能指標。F1值曲線可以幫助我們確定在不同精確率和召回率之間找到一個平衡點,以選擇最佳的閾值。
繪制F1值曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率、召回率和F1分數。
將每個閾值下的精確率、召回率和F1分數繪制在同一個圖表上,形成F1值曲線。
根據F1值曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
F1值曲線通常與接收者操作特征曲線(ROC曲線)一起使用,以幫助評估和比較不同模型的性能。它們提供了更全面的分類器性能分析,可以根據具體應用場景來選擇合適的模型和閾值設置。
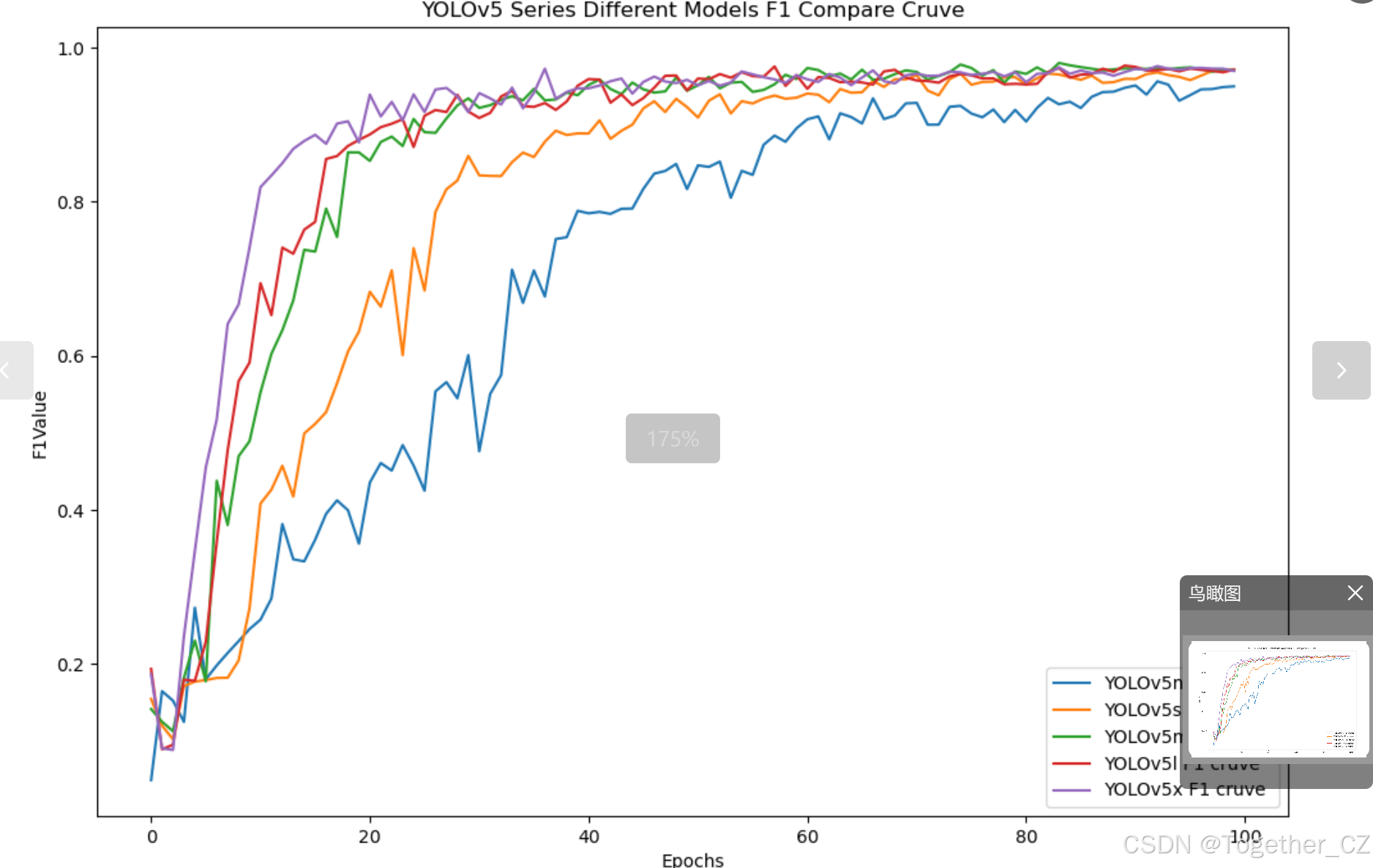
整體5款模型對比結果來看,五款模型最終沒有拉開較為明顯的差距,其中,n系列的模型效果略低一點,其余4款模型則達到了較為相近的水準,這里我們綜合考慮使用s系列的模型作為最終的推理模型。
接下來看下s系列模型的詳情。
【離線推理實例】

【Batch實例】

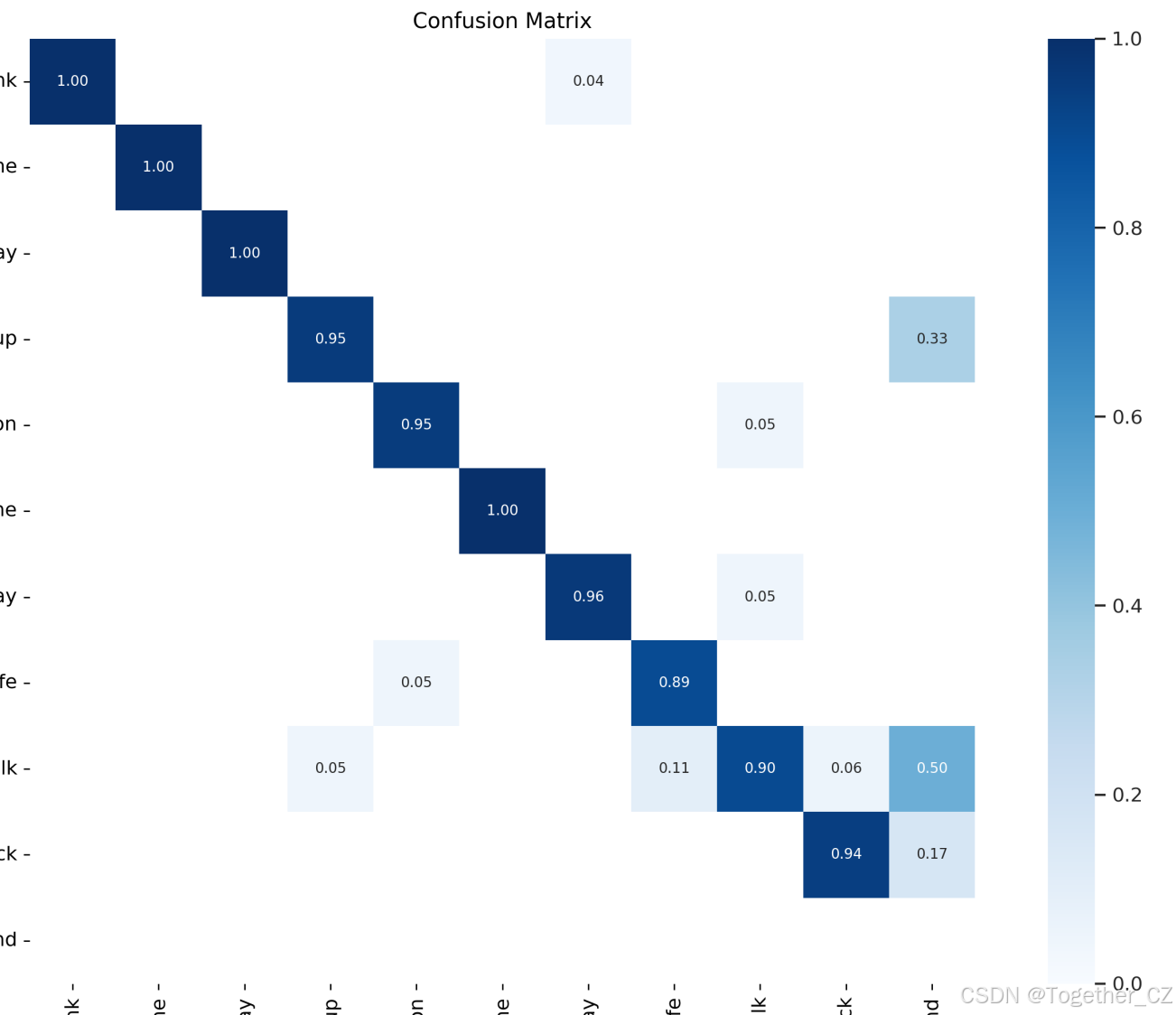
【混淆矩陣】
【F1值曲線】
【Precision曲線】
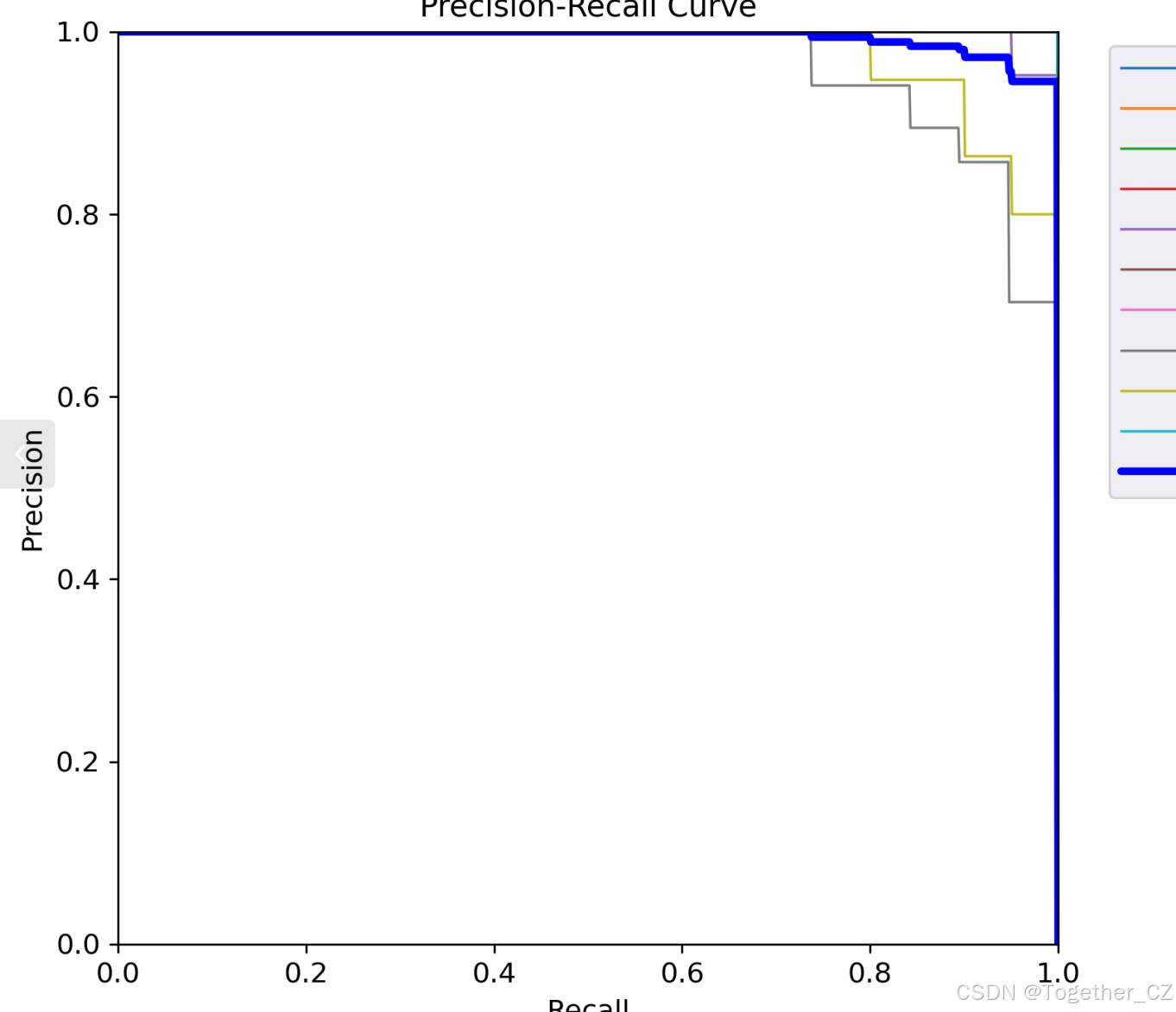
【PR曲線】
【Recall曲線】
【訓練可視化】
人工智能技術在車輛駕駛領域的應用也面臨著一些挑戰。例如,如何確保預警模型的準確性和可靠性,避免誤報或漏報;如何保護司機的隱私,確保攝像頭捕捉的畫面不被濫用;以及如何讓司機更好地接受和信任這些新技術等。但這些問題并不能阻擋人工智能技術在交通安全領域的發展,隨著技術的不斷進步和完善,這些問題都將逐步得到解決。總之,人工智能技術為交通安全帶來了新的希望和機遇。它通過智能化的檢測識別預警模型,為司機提供了一道堅實的安全防線。我們有理由相信,在人工智能的助力下,未來的汽車駕駛將更加安全、智能。讓我們共同期待這一天的到來,也希望每一位司機都能時刻牢記交通安全,珍愛生命,文明駕駛。

主要應用在什么方面?涉及到具體知識是什么?)




顏色空間轉換-----將圖像從 RGB 色彩空間轉換為 YUV 色彩空間函數RGB2YUV())
入門階段詳細指南)

![[GXYCTF2019]Ping Ping Ping](http://pic.xiahunao.cn/[GXYCTF2019]Ping Ping Ping)




用戶管理)


)

