基于LLM的語音合成
- 1.技術架構
- 1.1 LlaSA
- 1.2 CosyVoice (和 CosyVoice2)
- 1.3 SparkTTS
- 2 特性對比
- 2.1 零樣本語音克隆
- 2.2 多語種支持
- 2.3 可控語音生成
- 2.4 計算效率和模型大小
- 總結
當前,在大型語言模型(Large Language Models,LLMs)的驅動下,TTS模型在語音自然度、表現力以及多功能性方面都實現了質的飛躍 。這些模型通過利用大規模語言理解和生成能力,在零樣本語音克隆和多語種支持等領域取得了顯著的進展 。
LLM作為這些TTS系統的核心組件或基礎架構被反復提及,標志著TTS領域從傳統的聲學建模方法向利用LLM的語義理解和生成能力的重大轉變。這種范式轉變直接促成了零樣本語音克隆和多語種支持等功能的進步 。
LlaSA、CosyVoice 和 SparkTTS 作為近期涌現的優秀TTS模型,均展現了基于LLM的強大能力。
1.技術架構
1.1 LlaSA
LlaSA 模型建立在強大的 Llama 架構之上,為了使 Llama 模型能夠處理音頻數據,LlaSA 采用了 XCodec2 作為語音標記器(Tokenizer)。XCodec2 的作用是將原始音頻波形轉換為離散的語音標記(Token) 。這種轉換使得 Llama 模型能夠像處理文本一樣直接生成語音。LlaSA 的核心是一個單一的 Transformer 架構,該架構以自回歸的方式進行訓練,即通過預測序列中的下一個標記來生成語音 。這種單一架構的設計簡化了傳統的 TTS 流程,傳統TTS通常包含獨立的聲學模型、韻律預測器和聲碼器等多個組件(如上一篇博客)。
LlaSA 模型提供不同參數規模的版本,包括 10 億參數、30 億參數以及即將推出的 80 億參數版本 。這表明 LlaSA 在模型容量和性能方面具有可擴展性,用戶可以根據計算資源和所需的合成質量進行選擇。LlaSA 支持 16kHz 的音頻輸出 。
LlaSA 基于 Llama LLM 構建,并利用特定的語音標記器,其設計重點在于利用語言模型的強大能力進行語音合成。不同的模型尺寸也體現了在性能和計算資源之間進行權衡的考慮。通過構建在 Llama 架構之上,LlaSA 繼承了其強大的語言理解和生成能力。
XCodec2 的集成彌合了連續音頻信號和離散標記 LLM 之間的差距,使得模型能夠直接生成語音標記。這種單階段自回歸方法與更復雜的TTS多階段系統不同,帶來更精簡和高效的過程。多種模型尺寸的可用性使得用戶能夠選擇適合其特定計算約束和性能要求的模型。
1.2 CosyVoice (和 CosyVoice2)
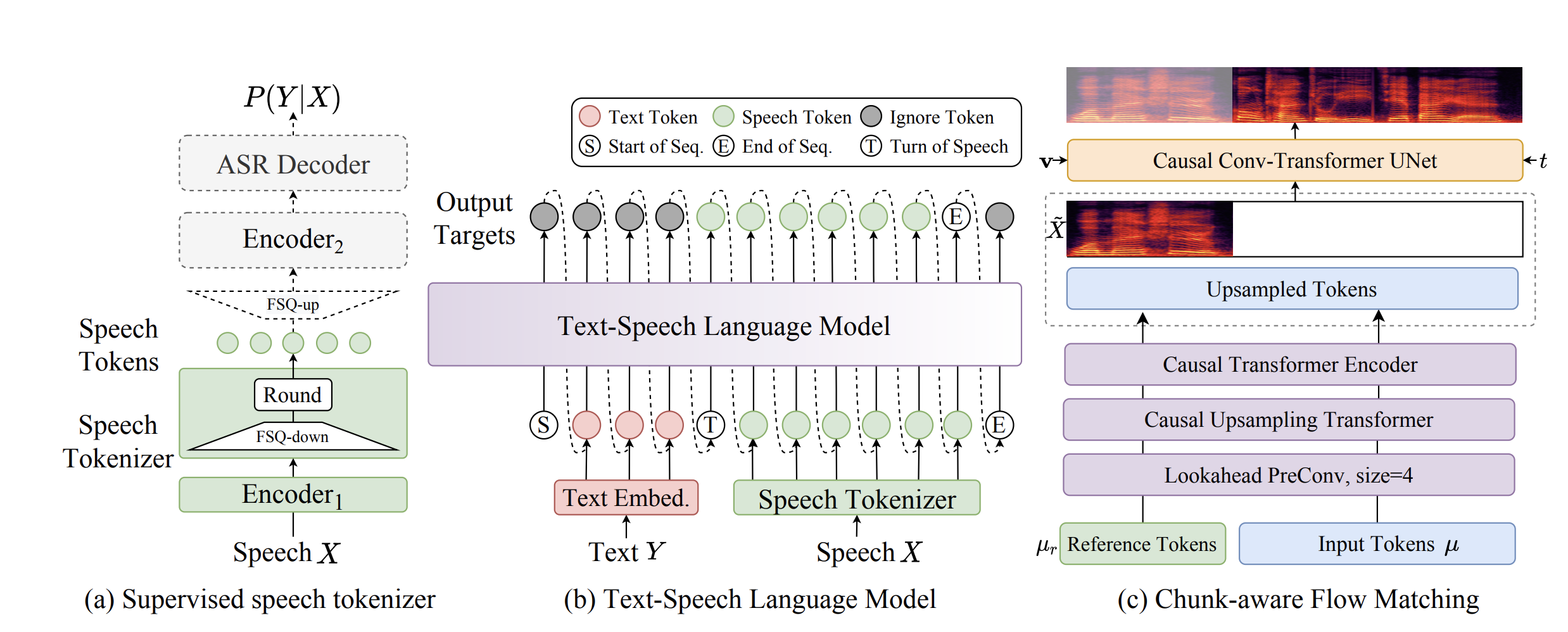
CosyVoice 采用從多語種語音識別模型中提取的監督語義標記 。與無監督標記方法相比,這種方法旨在捕獲顯式的語義信息,并改善與相應文本的對齊,從而可能提高內容一致性。
CosyVoice 的架構結合了一個用于文本到標記生成的 LLM 和一個用于標記到語音合成的條件流匹配模型 。這種兩階段方法將生成語義表示的任務與合成實際語音波形的任務分開,允許在每個階段進行專門的建模。CosyVoice2 引入了針對流式語音合成的優化,包括用于改進語音標記碼本利用的有限標量量化(Finite-Scalar Quantization,FSQ)和精簡的文本-語音 LM 架構 。這些優化對于降低延遲和實現實時應用至關重要。
CosyVoice2 允許直接使用預訓練的 LLM 作為骨干,無需單獨的文本編碼器和說話人嵌入,這可以通過直接利用強大的 LLM 的能力來增強上下文理解和跨語言性能 。CosyVoice2 采用分塊感知的因果流匹配模型,以支持單個模型中的流式和非流式合成,實現超低延遲(首包延遲低至 150 毫秒),這對于語音聊天等交互式應用至關重要 。該模型支持多種推理模式,包括零樣本、跨語言和指令式推理,為不同的語音合成任務提供了靈活性,并允許用戶使用自然語言指令來指導模型 。
CosyVoice 使用監督語義標記,其側重于改進文本和語音之間的對齊,從而可能帶來更好的內容一致性和說話人相似性。CosyVoice2 對流式傳輸和直接 LLM 集成的強調突顯了其對實時應用的適用性以及對 LLM 最新進展的利用。選擇監督語義標記意味著該模型受益于顯式的語言信息以及與文本的對齊,因為這些標記是從語音識別模型導出的。
兩階段架構允許LLM專門建模語義內容,而流匹配模型則專門建模聲學特征。CosyVoice2 的進步,特別是對流式傳輸的關注以及簡化架構以直接使用預訓練 LLM,表明其正朝著更高效、更快速的語音合成方向發展,這對于交互式應用至關重要。
1.3 SparkTTS
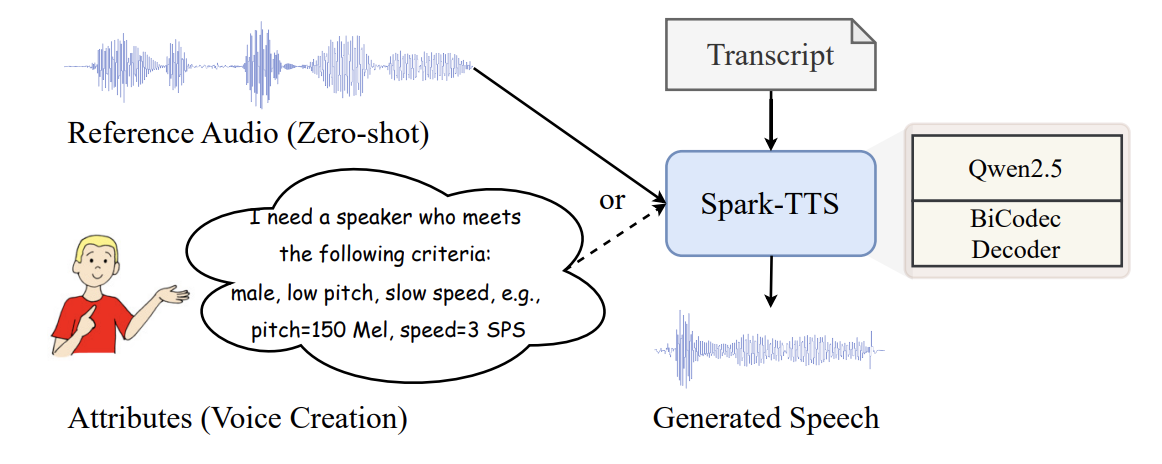
SparkTTS 由 BiCodec 提供支持,這是一種新穎的單流語音編解碼器,可將語音分解為用于語言內容的低比特率語義標記和用于說話人屬性的固定長度全局標記。這種解耦表示是其核心創新,允許獨立控制語言內容和說話人身份。
BiCodec作為SparkTTS的核心組件,是一種新穎的單流語音編解碼器 。它的主要作用是將語音分解為兩種互補的令牌類型:低比特率的語義令牌(semantic tokens)用于捕獲語言內容,以及固定長度的全局令牌(global tokens)用于表示說話人屬性 。這種解耦的表示方式使得對語言內容和說話人身份的控制可以相互獨立進行 。具體來說,全局令牌編碼器利用梅爾頻譜圖(Mel spectrograms)來生成全局令牌,這些令牌封裝了說話人的身份特征 。而語義令牌編碼器則借鑒了wav2vec 2.0模型的技術來提取語義令牌,確保在緊湊表示語言的同時不丟失上下文信息 。為了提高模型的魯棒性并最小化訓練崩潰的風險,BiCodec采用了量化技術,對語義令牌使用向量量化(VQ),對全局令牌使用有限標量量化(FSQ) 。
Qwen2.50.5B作為SparkTTS的基石 ,它不僅提供了強大的語言建模能力,還直接預測BiCodec的令牌序列(包括語義令牌和全局令牌),這些令牌隨后被BiCodec的解碼器用于重建音頻 。這消除了對諸如流匹配等額外生成模型的依賴,此外還結合了Qwen2.5和思維鏈(Chain-of-Thought,CoT)生成方法,可以實現粗粒度(例如,性別、說話風格)和細粒度(例如,精確的音高值、語速)的控制。這種架構的簡化是SparkTTS的關鍵創新之一,它通過直接利用LLM的輸出來進行音頻重建,無需單獨的聲學特征生成模型,潛在地提高了效率并降低了復雜性。
SparkTTS的訓練依賴于一個名為VoxBox的大規模數據集 。VoxBox是一個經過精心策劃的包含10萬小時語音的數據集,并且帶有全面的屬性標注 。該數據集的創建旨在促進可控TTS的研究 。開發者計劃在Hugging Face Datasets hub上公開發布該數據集 ,其總大小約為6TB 。如此龐大的數據集規模表明在數據收集和標注方面進行了大量的投入,這對于訓練高質量且可控的TTS模型至關重要。全面的屬性標注則表明其側重于實現對語音各個方面的細粒度控制。
在訓練方法方面,BiCodec采用了端到端的方式,并使用生成對抗網絡(GAN)方法 。訓練目標包括最小化重建損失和L1特征匹配損失(通過判別器),同時優化VQ碼本 。頻率域重建損失通過對多尺度梅爾頻譜圖使用L1損失來計算 。多周期和多頻帶多尺度短時傅里葉變換(STFT)判別器分別用于波形判別和頻率域判別 。VQ碼本學習結合了碼本損失和承諾損失,并使用直通估計器(straight-through estimator)進行反向傳播 。訓練代碼之前說計劃發布,目前看起來概率較低 。使用基于GAN的訓練方法,結合多個判別器和特定的損失函數,表明SparkTTS采用了復雜的訓練策略,旨在實現高質量的音頻合成。對重建損失和特征匹配的關注表明,其目標是捕捉語音的內容和風格細微之處。
表一:技術架構對比
| 特征 | LlaSA | CosyVoice (CosyVoice2) | SparkTTS |
|---|---|---|---|
| 基礎 LLM(如果適用) | Llama | LLM (Qwen2.5) | Qwen2.5 |
| 語音標記器 | XCodec2 | 監督語義標記 | BiCodec |
| 模型架構 | 單一 Transformer (自回歸) | LLM (文本到標記) + 條件流匹配 (標記到語音) | 單一 LLM (解碼器) |
| 關鍵架構特征 | 基于 Llama,單一階段,多種參數規模 | 兩階段,監督語義標記,CosyVoice2 優化流式 | 單流,解耦標記,思維鏈生成 |
2 特性對比
2.1 零樣本語音克隆
LlaSA 僅需幾秒鐘的音頻即可實現零樣本語音克隆 。github上的一些issue表明,其輸出可能存在噪聲或在音色上與原始聲音不太一致 ,這表明在捕獲個人聲音的細微差別方面仍有改進空間,其質量在不同用戶或場景中可能并不一致,拿來即用的概率不高,多半需要retrain或者fine-tune后使用。
CosyVoice 支持零樣本語音克隆,并展現出高韻律自然度、內容一致性和說話人相似性 。CosyVoice2 在零樣本合成過程中也能保持穩定的語音輸出 ,這表明其無需特定的訓練數據即可穩健地復制說話人特征,實現了與人類相當的合成質量 。
SparkTTS 在零樣本語音克隆方面是三者最好的(目前感覺是業界中文最先進的開源模型),僅需一段參考音頻即可。用戶反饋表明,即使使用很短的參考音頻,它也能生成非常逼真的中文語音 ,這表明其可能在處理聲調語言方面具有優勢或進行了專門優化。SparkTTS 在使用短音頻樣本進行高質量中文語音克隆方面的顯著成功可能歸因于其 BiCodec 架構有效捕獲說話人特定屬性的能力或其使用的訓練數據。這也可能意味著該模型特別適合像中文這樣的聲調語言。
所有三個模型在零樣本語音克隆方面都表現出色,這證明了 LLM 在學習說話人特征方面的強大能力。然而,感知質量和所需的參考音頻時長可能有所不同。SparkTTS 在語音克隆方面,尤其是在中文方面擁有很高的聲譽,零樣本語音克隆在所有三個模型中都是一項關鍵特性,這突顯了其在當前 TTS 技術領域的重要性。
2.2 多語種支持
LlaSA 在中文和英文中都展現出逼真且富有情感的語音 。還有一個多語種版本(Llasa-1B-Multilingual),包括對法語、德語、荷蘭語、西班牙語、意大利語、葡萄牙語、波蘭語、日語和韓語的支持,盡管由于訓練數據有限,某些語言的性能可能不太理想 ,合成的語音質量也不太穩定,這表明 LlaSA 正在努力擴展其語言覆蓋范圍,但對于數據較少的語言,質量可能會有所權衡。
CosyVoice 被描述為一個可擴展的多語種合成器,支持 100 多種語言 。CosyVoice2 特別提到了對中文、英文、日語、粵語和韓語的支持 ,在日語和韓語的基準測試中表現出色 。這表明其具有廣泛的多語種合成能力,并且在某些非英語語言中表現出強大的性能。
SparkTTS 支持中文和英文,并在這兩種語言之間具備零樣本語音克隆能力。這種重點雙語支持和跨語言克隆表明其優先考慮在這兩種語言中的高性能。
在三個模型中,CosyVoice 提供了最廣泛的多語種支持,而 LlaSA 和 SparkTTS 主要關注中文和英文,LlaSA 具有一定的擴展多語種能力。CosyVoice 和 SparkTTS 都具備跨語言語音克隆功能。支持的語言數量是衡量 TTS 模型多功能性的重要因素。CosyVoice 聲稱支持 100 多種語言,使其成為多語種應用的首選。雖然 LlaSA 和 SparkTTS 專注于廣泛使用的中文和英文,但 LlaSA 的多語種版本表明其正在努力擴展語言覆蓋范圍。跨語言語音克隆的能力進一步增強了這些模型在國際和混合語言場景中的實用性。
2.3 可控語音生成
LlaSA 能夠捕捉情感并提供對語音風格的一定程度的控制 。表達情感的能力增強了合成語音的自然度和表現力。CosyVoice 提供情感控制和粵語合成 。
CosyVoice2 提供了更精細的情感控制和方言口音調整 。這表明其側重于為用戶提供對生成語音特征的精細控制。
SparkTTS 支持通過調整性別、音高和語速等參數來創建虛擬說話人,并且可以進行粗粒度(例如,性別、說話風格)和細粒度(例如,精確的音高、語速)的調整。這種詳細的控制水平允許高度定制的語音生成。SparkTTS 似乎提供了對性別、音高和語速等語音參數最明確和最細粒度的控制。
雖然 LlaSA 和 CosyVoice 也提供了一定程度的控制,尤其是在情感和風格方面,但 SparkTTS 的方法似乎更側重于參數驅動。精確控制語音的各個方面對于許多應用至關重要。SparkTTS 提供的可調參數的全面集合,為用戶提供了高度的靈活性來創建所需的語音特征。雖然 LlaSA 側重于捕捉更廣泛的方面(如情感和風格),而 CosyVoice2 在精細的情感和方言控制方面取得了進展,但 SparkTTS 的顯式參數調整提供了一種更直接的方式來根據特定要求塑造輸出。這在需要精確控制聲學特征的場景中可能特別有用。
表二:特性對比
| 特征 | LlaSA | CosyVoice (CosyVoice2) | SparkTTS |
|---|---|---|---|
| 零樣本語音克隆 | 支持 (質量可能不一致) | 支持 (說話人相似性好) | 支持 (尤其擅長中文) |
| 多語種支持 | 中文、英文 + 部分其他語言 | 100+ 種語言 (CosyVoice),中文、英文、日語、粵語、韓語 (CosyVoice2) | 中文、英文 |
| 跨語言克隆 | 是 | 是 | 是 |
| 可控語音生成 | 情感、風格 | 情感、粵語、方言口音 (CosyVoice2) | 性別、音高、語速 (粗細粒度控制) |
| 優劣 | 基于廣泛被支持的Llama,輸出可能存在噪音,合成/克隆不夠穩定 | 提供指令遵循指導合成控制,克隆的相似度非業界領先,多語種效果待明確 | 擅長中文克隆,issue上提到了奇怪的聲音、停頓、吞字等 |
2.4 計算效率和模型大小
LlaSA 運行資源密集 。提供 1B和 3B 參數的變體,并且正在開發 8B億參數的版本 。較大的模型尺寸表明更高的計算需求。
CosyVoice 高效 。CosyVoice2 的參數大小為 0.5B 。強調低延遲和實時因子 。較小的模型尺寸和對低延遲的關注表明其設計優先考慮效率。
SparkTTS 設計高效且簡單,完全基于 Qwen2.5 構建。僅使用 1B 個參數即可實現優于其他需要高達 7B個參數的模型的性能 。生成語音的速度比競爭模型快 1.8 倍 。Spark-TTS-0.5B 的參數大小為 0.5B。較小的參數大小和明確的效率和速度聲明表明其側重于資源友好性。
SparkTTS (0.5B) 和 CosyVoice2 (0.5B) 的參數尺寸較小,并且明確提到了效率和低延遲,這表明這些模型旨在更加資源友好,并且適合具有計算約束或需要實時生成的應用程序。相比之下,LlaSA 的參數尺寸較大(1B、3B,以及正在開發的 8B),并且用戶反饋也表明其資源密集,這表明它可能需要更強大的硬件,并且更適合計算資源不太重要但需要高質量輸出的應用程序。
總結
基于LLM的方法擺脫了音素建模,采用了LLM+Decoder架構,在大大簡化了TTS的復雜度的同時,提高了合成的可控性,LLM作為這些TTS系統的核心組件或基礎架構被反復提及,標志著TTS領域從傳統的聲學建模方法向利用LLM的語義理解和生成能力的重大轉變。這種范式轉變直接促成了零樣本語音克隆和多語種支持等功能的進步 。
基于 LLM 的 TTS 技術正在迅速發展,LlaSA、CosyVoice 和 SparkTTS 等模型代表了該領域的重大進步。它們各自的技術選擇和性能特點使其在不同的應用領域具有獨特的優勢,共同推動著語音合成技術的發展。

 打包詳解)



主要應用在什么方面?涉及到具體知識是什么?)




顏色空間轉換-----將圖像從 RGB 色彩空間轉換為 YUV 色彩空間函數RGB2YUV())
入門階段詳細指南)

![[GXYCTF2019]Ping Ping Ping](http://pic.xiahunao.cn/[GXYCTF2019]Ping Ping Ping)




用戶管理)
