25年4月來自CMU、TRI 和 豐田子公司 Woven 的論文“ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping”。
機器人抓取是具身系統的核心能力。許多方法直接基于部分信息輸出抓取結果,而沒有對場景的幾何形狀進行建模,導致運動效果不佳甚至發生碰撞。為了解決這些問題,本文引入 ZeroGrasp 框架,可以近乎實時地同時執行 3D 重建和抓取姿勢預測。該方法的一個關鍵洞察是,遮擋推理和目標之間空間關系建模,有助于實現精確的重建和抓取。其將該方法與一個大規模合成數據集相結合,該數據集包含來自 Objaverse-LVIS 數據集的 100 萬張逼真圖像、高分辨率 3D 重建以及 113 億個物理有效的抓取姿勢注釋,涵蓋 1.2 萬個目標。在 GraspNet-1B 基準測試以及真實世界的機器人實驗中對 ZeroGrasp 進行評估。ZeroGrasp 實現最佳性能,并利用合成數據將其泛化到真實世界的新目標。
ZeroGrasp 如圖所示:
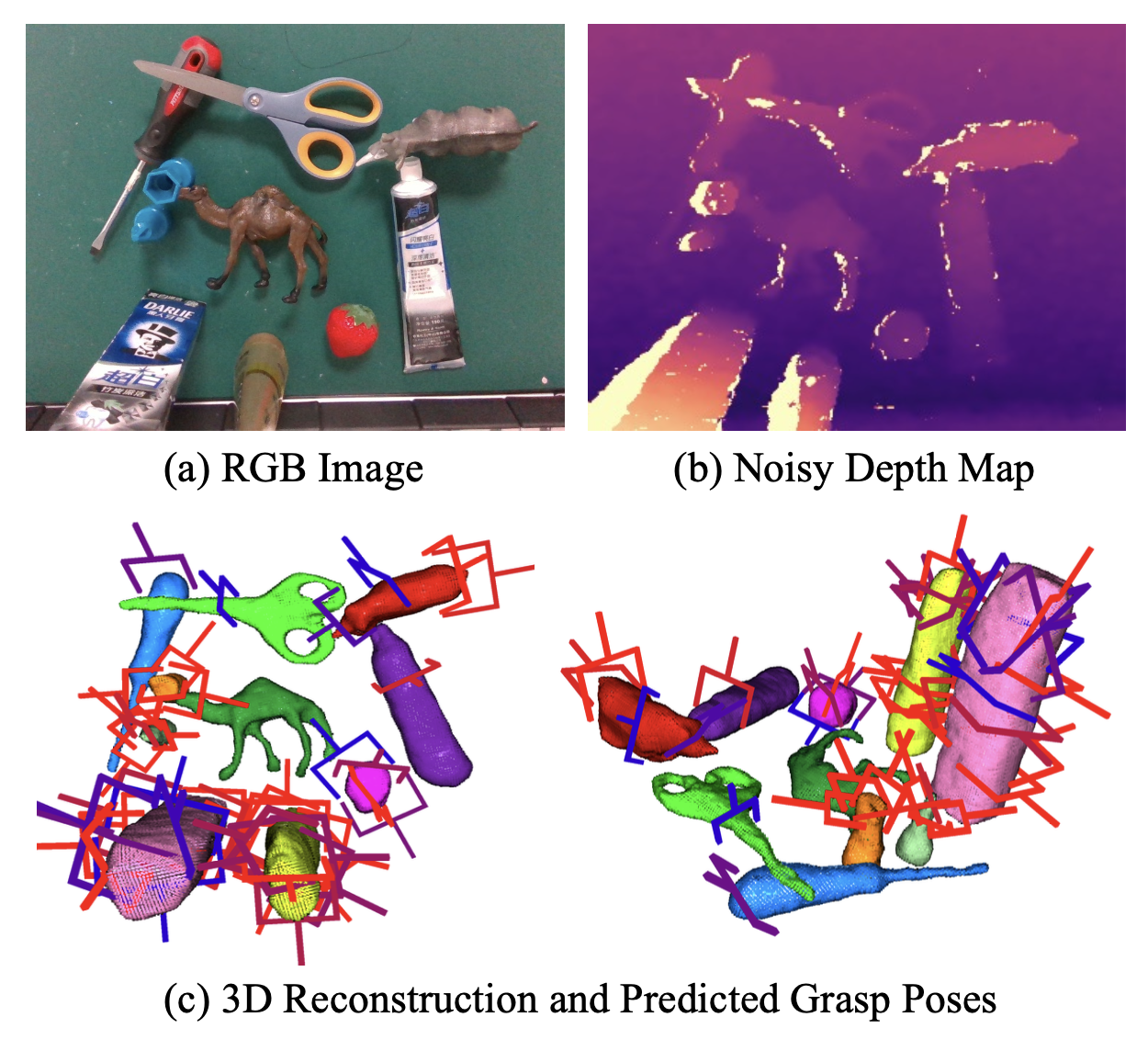
安全且魯棒的機器人抓取需要對目標物體及其周圍環境有準確的幾何理解。然而,大多數以前的抓取檢測方法 [1–6] 并沒有明確地對目標物體的幾何形狀進行建模,這可能導致意外碰撞以及與目標物體的不穩定接觸。雖然有幾種方法 [3, 7] 利用多視圖圖像提前重建目標物體,但此過程會帶來額外的計算開銷,并且需要更復雜的設置。對于放置在狹小空間內(如架子或盒子)的物體,多視圖重建通常也不切實際。此外,缺乏具有真實 3D 形狀和抓取姿勢注釋的大規模數據集,這使得從單個 RGB-D 圖像進行精確的 3D 重建變得更加復雜。最近,多項研究 [8–10] 表明,稀疏體素表征在運行時間、準確度和分辨率方面優于體表征和類似 NeRF 的隱形狀表征,尤其是在基于回歸的零樣本 3D 重建方面。
基于回歸的3D 重建。基于回歸的單視圖 RGB-D 圖像 3D 重建 [8, 20– 47] 一直是 3D 計算機視覺研究的重點。這些方法探索不同的 3D 表征,包括密集體素網格 [23, 31, 39, 48]、稀疏體素網格 [8, 9, 49](例如八叉樹 [9]、VDB [49]、哈希表 [8] 等)和隱式表征 [20, 33, 34, 38]。然而,由于昂貴的內存和計算成本,密集體素網格和隱式表示在輸出分辨率方面受到限制。另一方面,一些工作 [9, 20, 21, 49] 表明,稀疏體素表征(如八叉樹和 VDB [50])由于其高效的分層結構,能夠以更快的運行時間實現高分辨率 3D 重建。或者,通過新視圖合成進行單視圖重建也取得深刻的結果。近期的一些研究,例如 GeNVS [51]、Zero-1-to-3 [52]、3DiM [53] 和 InstantMesh [54],利用擴散模型在給定標準相機姿態的情況下渲染多視圖圖像。然而,這些方法速度較慢(通常超過 10 秒),并且物體間的遮擋會顯著降低性能。此外,集成抓握姿態預測并非易事。
基于回歸的抓握姿態預測。傳統的抓握姿態預測方法,通常假設人們已經具備 3D 物體的先驗知識,并且通常依賴于基于力閉合(force closure)原理的簡化分析模型 [55, 56]。近年來,基于學習的方法 [1, 6, 57, 58] 取得了巨大進展,這些方法使得模型能夠直接從 RGB(-D) 圖像和點云預測 6D 抓取姿勢。這使得在高度雜亂的場景中,無需明確建模物體幾何形狀即可回歸抓取姿勢。然而,這可能導致抓取不穩定和意外碰撞,因為準確學習防碰撞和精確接觸點仍然具有挑戰性。盡管一些方法 [42, 59, 60] 探索 3D 重建以改進抓取預測,但它們對形狀表征和網絡架構的選擇往往限制了其全部潛力。
零樣本機器人抓取。零樣本機器人抓取是指無需先驗知識即可抓取未見過目標物體的能力。為實現此目標,主要有兩個方向:(1)在測試時使用重建的或真實的 3D 形狀基于接觸點優化抓握姿勢 [3, 61];(2)增強或合成大規模抓握數據以提高泛化能力 [1, 15, 62]。例如,Ma [3] 提出一種基于接觸的優化算法,通過使用從多視角 RGB-D 圖像重建的 3D 場景來優化初始抓握姿勢。現有的大規模抓握姿勢數據集,如 ACRONYM [15]、GraspNet-1B [1] 和 EGAD [62] 探索第二種方法。然而,它們受限于物體多樣性或缺少注釋,例如 RGB-D 圖像。
為了將使用稀疏體素表征的重建方法應用于機器人抓取,開發能夠在統一框架內對兩者進行推理的新方法至關重要。為此,本文提出 ZeroGrasp,一個用于近實時 3D 重建和 6D 抓取姿態預測的框架。主要假設是,提高 3D 重建質量可以增強抓取姿態預測,特別是通過利用基于物理的接觸約束和碰撞檢測,這對于精確抓取至關重要。由于機器人環境通常涉及多個目標,且存在目標之間遮擋和緊密接觸,因此 ZeroGrasp 引入兩個關鍵組件:多目標編碼器和 3D 遮擋場。這些組件可以有效地模擬目標之間的關系和遮擋,從而提高重建質量。此外,設計一種簡單的細化算法,利用預測的重建結果來改進抓取姿態。由于重建結果高度精確,它能夠在夾持器和目標物體之間提供可靠的接觸點和碰撞掩碼,利用這些信息來細化抓取姿態。
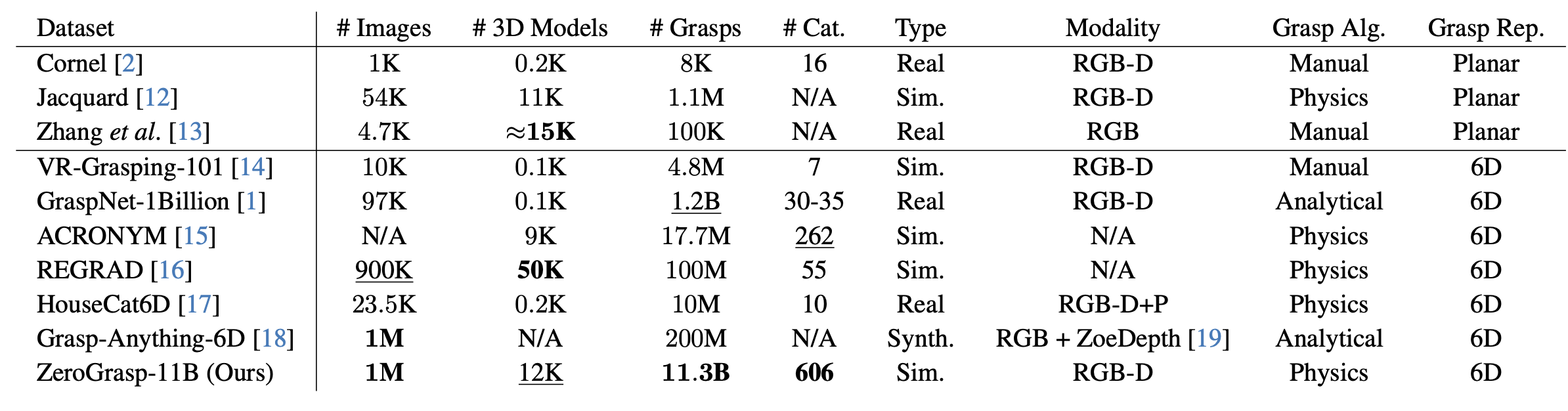
除了提出的模型之外,還創建一個用于評估的真實世界數據集 ReOcS 數據集和一個用于訓練的合成數據集 ZeroGrasp-11B 數據集。ReOcS 數據集是一個用于評估 3D 重建的真實世界數據集,其中三個分割代表不同程度的遮擋。使用此數據集來評估遮擋的魯棒性。ZeroGrasp-11B 數據集是一個大規模合成數據集,旨在訓練具有零樣本機器人抓取能力的模型,包含來自 Objaverse-LVIS 數據集 [11] 的高質量、多樣化的 3D 模型,如表所示。
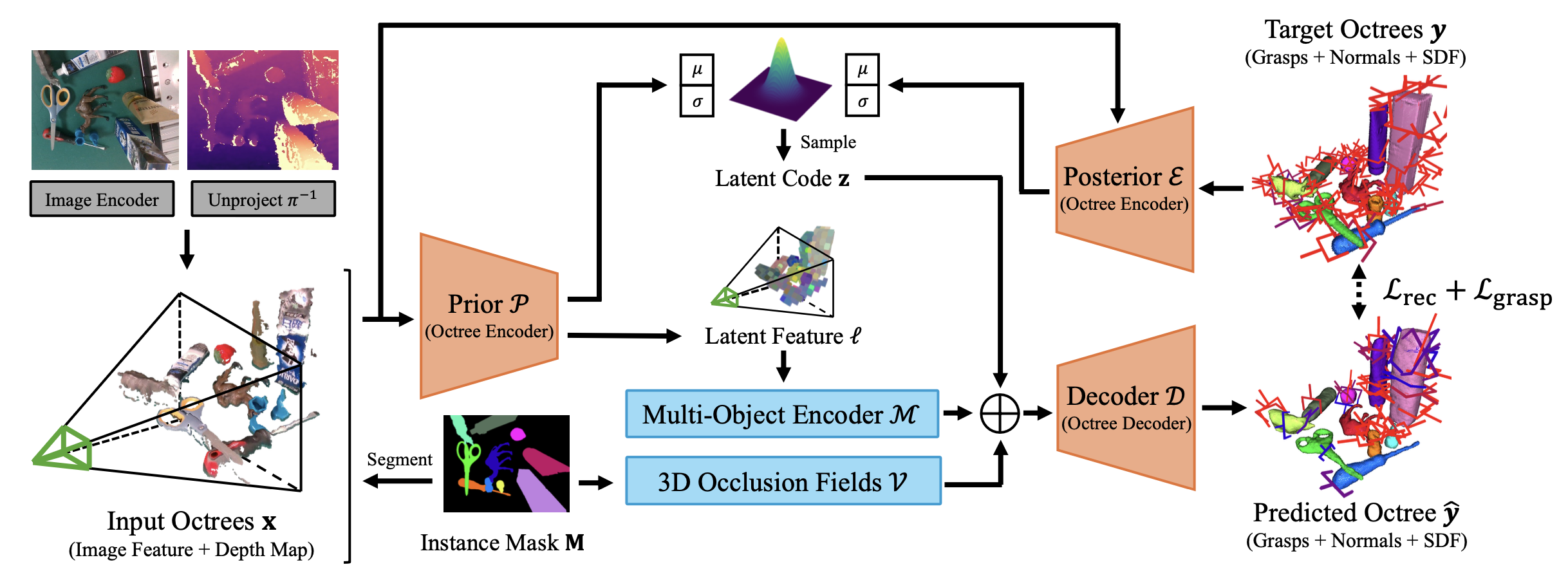
目標是構建一個高效且可泛化的模型,用于基于單個 RGB-D 觀測值同時進行 3D 形狀重建和抓取姿勢預測,并證明預測的重建結果可用于通過基于接觸的約束和碰撞檢測來優化抓取姿勢。
ZeroGrasp 概述如圖所示:輸入八叉樹 x 首先被輸入到基于八叉樹的 CVAE(橙色框中的組件)。多目標編碼器利用其潛特征 l 在潛空間學習多目標推理。此外,3D 遮擋場通過簡單的光線投射對目標間和自遮擋信息進行編碼。多目標編碼器和 3D 遮擋場的輸出特征與潛代碼 z 連接,解碼器預測 3D 形狀和抓握姿勢。
3D 形狀表征。采用八叉樹作為形狀表征,其中圖像特征、符號距離函數 (SDF)、法線和抓取姿勢等屬性定義在八叉樹的最深層。例如,將輸入八叉樹表示為最終深度的體素中心 p 多元組,并與圖像特征 f 相關聯。與點云不同,八叉樹結構支持高效的深度優先搜索和八分圓(octant)的遞歸細分,使其成為以內存和計算高效的方式進行高分辨率形狀重建和密集抓取姿勢預測的理想選擇。
抓取姿勢表征。用通用的兩指并聯夾持器模型來表示抓握姿勢,就像 GraspNet [1] 中所使用的一樣。具體來說,抓握姿勢由以下部分組成:視圖抓握度分 s,表示抓握位置的穩健性 [57];質量 q,使用力閉合算法 [55] 計算;視圖方向 v;角度 a;寬度 w;深度 d。每個點都會被分配在半徑 5 毫米以內的最近抓握姿勢。如果不存在,將其對應的抓握度設置為 0。在 GraspNet-1B 和 ZeroGrasp-11B 數據集中,每個點都標注有一組密集的抓握姿勢,涵蓋所有視圖、角度和深度的組合 (300 × 12 × 4)。
架構
給定輸入八叉樹 x(由深度圖和實例掩碼生成的每個實例部分點云組成)及其對應的圖像特征,目標是預測以八叉樹表示的 3D 重建和抓取姿勢 y?。ZeroGrasp 基于八叉樹的 U-Net [9] 和條件變分自編碼器 (CVAE) [63] 構建,用于建模形狀重建不確定性和抓取姿勢預測,同時保持近乎實時的推理能力。本文提出兩項??關鍵創新來提高其準確性和泛化能力。具體而言,引入 (1) 多目標編碼器,通過潛空間中的 3D transformer 來建模目標之間的空間關系,從而實現無碰撞的 3D 重建和抓取姿勢;以及 (2) 3D 遮擋場,這是一種3D 遮擋表征,可以捕捉目標間的遮擋,從而增強遮擋區域的形狀重建。
八叉樹特征提取。對 RGB 圖像 I 進行編碼以提取圖像特征 W。對 SAM 2 [64] 進行微調以生成二維實例掩碼 M,M_i 表示第 i 個目標掩碼。然后通過 (q_i, w_i) = π^?1 (W, D, K, M_i) 將圖像特征圖反投影到三維空間,其中 q_i 和 w_i 分別表示第 i 個目標的三維點云及其對應特征。其中,π 是反投影函數,D 是深度圖,K 表示相機本征矩陣。三維點云特征被轉換為八叉樹 x_i = (p_i, f_i) = G(q_i, w_i),其中 G 是從點云及其特征到八叉樹的轉換函數。
基于八叉樹的 CVAE。為了提高形狀重建質量,ZeroGrasp 利用基于八叉樹的條件變分自編碼器 (CVAE) 的概率建模來解決單視圖形狀重建中固有的不確定性,這對于提高重建和抓握姿勢預測質量都至關重要。受 [63] 的啟發,基于八叉樹的 CVAE 由編碼器 E、先驗 P 和解碼器 D 組成,用于學習 3D 形狀和抓握姿勢的潛表示作為對角高斯分布。具體來說,編碼器 E(z_i | x_i, y_i) 學習根據預測和真實八叉樹 x_i 和 y_i 來預測潛代碼 z_i。先驗 P(l_i, z_i | x_i) 將八叉樹 x_i 作為輸入并計算潛特征 l_i 和代碼 zi,Ni′ 和 D′ 分別是點的數量和潛特征的維度。在內部,潛編碼是通過重新參數化技巧從預測的均值和方差中采樣的 [65]。解碼器 D (y_i | l_i, z_i, x_i) 預測 3D 重建以及抓取姿勢。為了節省計算成本,解碼器預測每個深度的占用,丟棄那些概率低于 0.5 的網格單元。只有在最后一層,解碼器才會預測 SDF、法向量、抓取姿勢以及占用。在訓練期間,編碼器和先驗之間的 KL 散度被最小化,以使它們的分布達到匹配。
多目標編碼器。先驗 P 計算每個目標的特征,缺乏對無碰撞重建和抓取姿勢預測的全局空間排列進行建模的能力。為了解決這個問題,在潛空間中加入 Transformer,它由 K 個帶有自注意機制和 RoPE [66] 位置編碼的標準 Transformer 塊組成,效仿了 [10] 的做法。多目標編碼器 M 以體素中心 r_i 及其所有目標的特征 l_i 為中心,更新潛空間中所有目標的特征。
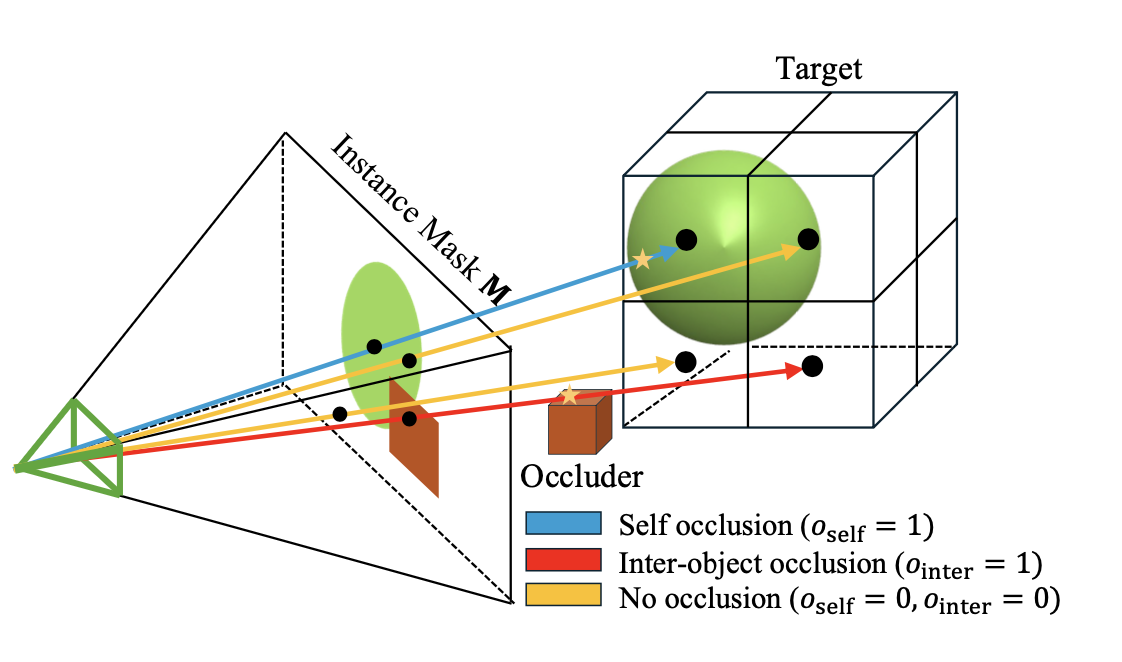
3D 遮擋場。關鍵見解是,多目標編碼器主要學習避免物體之間的碰撞以及在雜亂場景中掌握姿勢,因為碰撞建模只需要局部上下文,使其更易于處理。相比之下,遮擋建模需要全面理解全局上下文才能準確捕捉可見性關系,因為遮擋物和被遮擋物可能相距甚遠。為了緩解這個問題,設計 3D 遮擋場,通過簡化的基于八叉樹體渲染將可見性信息定位到體素上。具體而言,將潛空間中的體素細分為 B^3 個較小的塊(每個軸 B 個塊),然后將它們投影到圖像空間中。如圖所示,如果某個塊位于目標物體對應的實例掩碼內,則自遮擋標志 o_self 設置為 1。如果該塊位于鄰近目標的實例掩碼內,則目標間遮擋標志 o_inter 設置為 1。計算完所有塊的標志后,通過連接第 i 個目標的兩個標志來構建 3D 遮擋場 V_i。最后,使用三層 3D CNN 對其進行編碼,每層將分辨率下采樣 2 倍,以獲得潛空間的遮擋特征 o_i,并通過 l_i ← [l_i o_i] 更新潛特征,以考慮遮擋和碰撞。
訓練。與標準 VAE [63, 65] 類似,通過最大化證據下界 (ELBO) 來訓練模型。此外,選擇經濟監督 [67] 來有效地學習抓握姿勢預測。
抓取姿勢的細化
三維重建的一大優勢,在于它能夠利用重建結果來細化預測的抓取姿勢。雖然 Ma [3] 提出一種基于接觸的優化算法,但它需要從多視角圖像重建精確的截斷有符號距離場 (TSDF),而且運行時間相對較慢。相比之下,本文引入一種簡單的細化算法,該算法將基于接觸的約束和碰撞檢測應用于三維重建。具體而言,首先通過在重建中找到距離夾持器左右手指最近的點來檢測接觸點。然后,調整預測的寬度和深度,使兩個指尖都接觸。最后,對重建結果進行碰撞檢測,以丟棄存在碰撞的抓取姿勢。
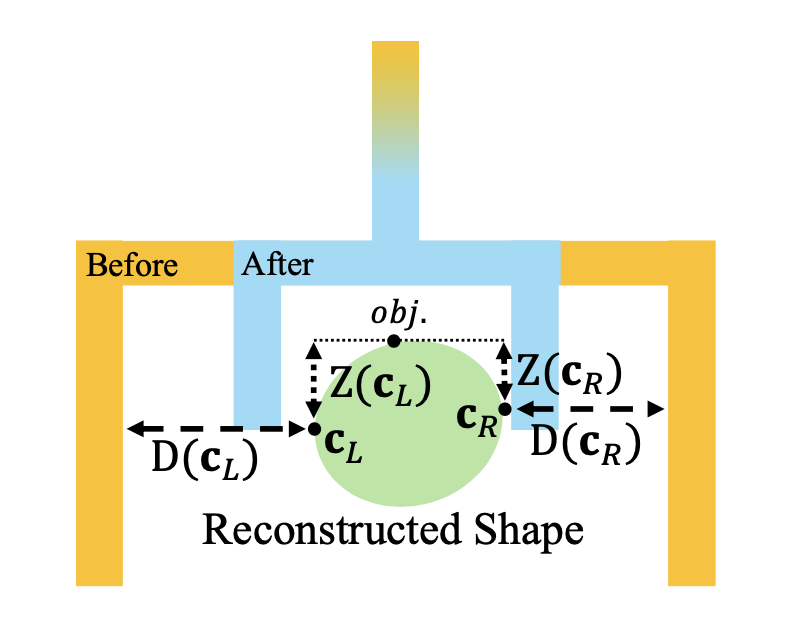
基于接觸的約束。準確的接觸對于成功抓取至關重要,因為它們確保操作過程中的穩定性和控制力。雖然網絡可以預測夾持器的寬度和深度,但即使是微小的誤差也可能導致抓取不穩定。為了解決這個問題,調整夾持器的指尖位置可優化抓取姿勢,使其與重建圖中左右手指 c_L 和 c_R 最近的接觸點對齊。基于這些接觸點優化寬度 w,使得接觸距離 ?w 保持在 γ_min 到 γ_max 范圍內。注:D? 表示與 c 點的接觸距離。之后進一步修正深度 d。這些簡單的細化步驟有助于確保穩定的抓取。
如圖所示:首先獲得接觸點 c_L 和 c_R。接下來,計算接觸距離 D(c_L | R),并通過 Z(c_L | R) 計算深度。最后更新寬度和深度。
碰撞檢測。基于 GS-Net [57],使用雙指夾持器實現一個簡單的無模型碰撞檢測器。雖然之前的方法使用從深度圖獲取的部分點云,但它無法丟棄導致與遮擋區域發生碰撞的預測抓取姿勢。為了克服這一限制,利用重建的形狀,從而實現更精確的碰撞檢測。為了證明這種方法的合理性,在實驗中進行廣泛的分析,并展示其優勢。
另外,創建兩個用于評估和訓練的數據集:1) ReOcS 數據集用于評估不同遮擋程度下的 3D 重建質量;2) ZeroGrasp-11B 數據集用于訓練基準和零樣本機器人抓取模型。如圖突出顯示數據集的幾個示例。

實現細節。Zero-Grasp 采用 ResNeXt [75] 架構作為圖像編碼器,在 ImageNet 數據集 [76] 上進行預訓練,除最后一層之外的所有參數在訓練期間都是固定的。與 EconomicGrasp [67] 使用預測的視圖抓取度 s 來確定視圖方向。對于訓練,使用 AdamW [77],學習率為 0.001,在 NVIDIA A100 上批量大小為 16。將輸入圖像特征 D、潛特征 D′ 和 3D 遮擋場 V 的尺寸分別設置為 32、192 和 16。對于 3D 遮擋場,用 8 作為塊分辨率 B。按照 Ma 的方法,接觸距離 γ_min 和 γ√max 的范圍分別定義為 0.005m 和 0.02m。為了生成抓取姿勢,我們使用 0.005m^2 作為采樣密度 ρ。













vit -- vision transformer 和其變體調研)


基本概念與核心原理)


