本文是LLM應用開發101系列的先導篇,旨在幫助讀者快速了解LLM應用開發中需要用到的一些基礎知識和工具/組件。
本文將包括以下內容:首先會介紹LLM應用最常見的搜索增強生成RAG,然后引出實現RAG的一個關鍵組件 – 向量數據庫,隨后我們是我們這篇博客的重點,一個非常有效的輕量級向量數據庫實現ChromaDB.
概述
大語言模型(LLMs)的應用開發可以被視為一種實現人工智能(AI)和自然語言處理(NLP)技術的方式。這種類型的模型,比如GPT-3或GPT-4(但其實一些不那么大的模型例如BERT及其變種, 在很多應用中也非常有用),能夠生成與人類語言類似的文本,使其在各種應用上具有廣泛的可能性。
以下是一些大語言模型應用開發的主要應用領域:
-
內容生成與編輯:語言模型可以生成文章、報告、電子郵件等,也可以提供寫作建議和修改。
-
問答系統:大語言模型可以被用來創建自動問答系統,能夠理解并回答用戶的問題(
BERT應用中有一種Question Answer和我們直覺的問答系統有點不一樣,是從給出的文本中找答案)。 -
對話系統與聊天機器人:大語言模型可以生成連貫且自然的對話,使其在創建聊天機器人或虛擬助手方面具有潛力。
-
機器翻譯:雖然這些模型通常不專為翻譯設計,但它們可以理解并生成多種語言,從而能夠進行一定程度的翻譯。
-
編程助手:語言模型可以理解編程語言,并提供編程幫助,比如代碼生成、代碼審查、錯誤檢測等。
-
教育:語言模型可以被用于創建個性化的學習工具,如自動化的作業幫助或在線教育平臺。
在開發這些應用時,開發者需要注意模型可能存在的限制,比如誤解用戶的輸入、生成不準確或不可靠的信息、可能出現的偏見等等。這就需要開發者在應用設計和實現時進行適當的控制和優化。
那么在什么情況下需要RAG呢?
RAG模型在以下幾種情況下可能特別有用:
-
需要大量背景知識的任務:比如在問答系統中,如果問題需要引用大量的背景知識或者事實來回答,那么RAG模型可能是一個很好的選擇。RAG模型可以從大規模的知識庫中檢索相關信息,然后生成回答。
-
需要復雜推理的任務:在一些需要理解和推理復雜關系的任務中,比如多跳問答或者復雜的對話生成,RAG模型也可能表現得比純生成模型更好。因為RAG模型可以利用檢索到的文本來幫助生成模型進行推理。
-
需要從長文本中提取信息的任務:在一些需要從長文本中提取信息的任務中,比如文檔摘要或者長文本閱讀理解,RAG模型也有很大的潛力。因為RAG模型可以先檢索到相關的文本片段,然后再生成答案,避免了生成模型處理長文本的困難。
總的來說,RAG模型在需要大量背景知識、復雜推理或者長文本信息提取的任務中可能有很大的優勢。下面我們介紹一下RAG。
RAG
RAG,全稱為Retrieval-Augmented Generation,是一種結合了檢索和生成的深度學習模型。它首先使用一個檢索模型從一個大規模的知識庫中找出和輸入相關的文檔或者文本片段,然后將這些檢索到的文本和原始輸入一起輸入到一個生成模型中。生成模型使用這些信息來生成響應。這種結合檢索和生成的方式使得RAG模型可以更好地處理需要大量背景知識或者具有復雜推理需求的問題。
RAG模型的一個關鍵優點是它可以從非結構化的大規模文本數據中提取知識,而不需要預先構建一個結構化的知識圖譜。這使得RAG模型在許多NLP任務,如問答、對話生成等,都有出色的表現。
下圖展現了LLMs和RAG是如何協作的:
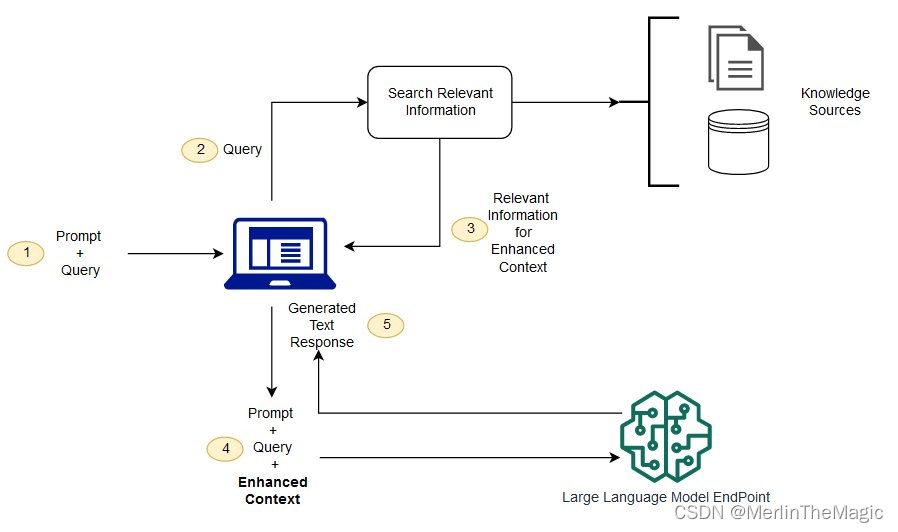
從圖中我們可以看到,RAG的關鍵步驟,就是要能夠Search Relevant Information, 而向量數據庫,就是一個非常好的實現途徑. 下面介紹一個非常優秀的實現, ChromaDB.
向量數據庫ChromaDB
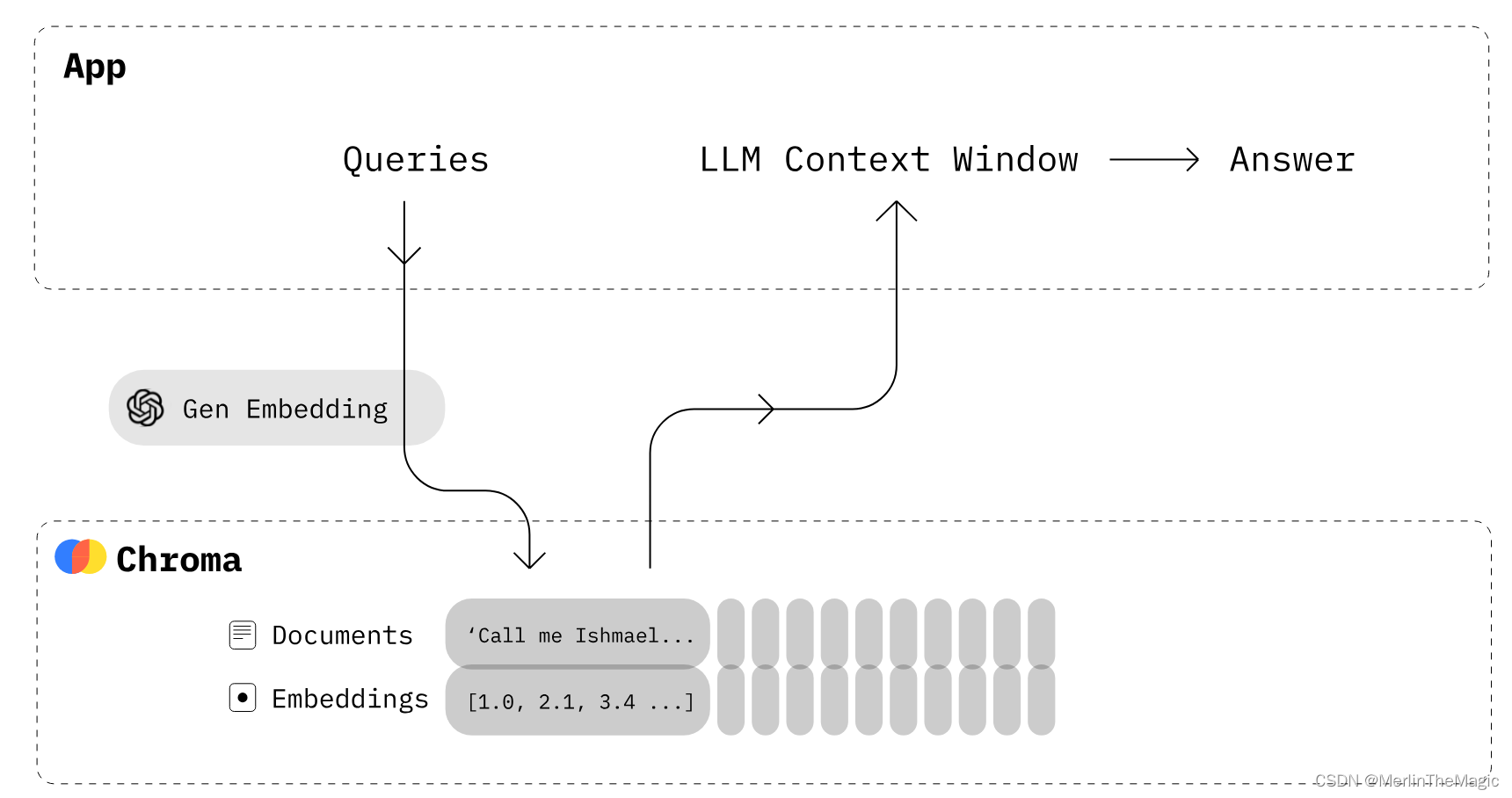
ChromaDB 是一個輕量級、易用的向量數據庫,主要用于 AI 和機器學習場景。
它的主要功能是存儲和查詢通過嵌入(embedding)算法從文本、圖像等數據轉換而來的向量數據。ChromaDB 的設計目標是簡化大模型應用的構建過程,允許開發者輕松地將知識、事實和技能等文檔整合進大型語言模型中。
ChromaDB 的開源地址是: https://github.com/chroma-core/chroma
ChromaDB 支持大多數的主流編程語言,如Python, Javascript,Java, Go等,當前具體支持情況可以看下表,本文主要介紹Python環境下的使用.
| 編程語言 | 客戶端 |
|---|---|
| Python | ? chromadb (by Chroma) |
| Javascript | ? chromadb (by Chroma) |
| Ruby | ? from @mariochavez |
| Java | ? from @t_azarov |
| Go | ? from @t_azarov |
| C# | ? from @microsoft |
| Rust | ? from @Anush008 |
| Elixir | ? from @3zcurdia |
| Dart | ? from @davidmigloz |
| PHP | ? from @CodeWithKyrian |
| PHP (Laravel) | ? from @HelgeSverre |
安裝
在python環境下,安裝非常簡單,只需要用pip 就可以完成,如果遇到網絡速度問題,可以選擇替換pip mirror, 如果擔心環境中各種包的干擾,可以用Annaconda創建一個全新的env.
pip install chromadb順便介紹一下nodejs 環境下的安裝,也非常容易
## yarnyarn install chromadb chromadb-default-embed## npmnpm install --save chromadb chromadb-default-embed編程交互
在開始用代碼和chromadb交互前,我們還有一個問題需要理清:向量數據庫存儲的是向量,而RAG需要的是文本來做增強生成,那么顯然,我們需要有一個機制來實現文本和向量之間的轉換。這個轉換過程就是我們常說的文本嵌入(Text Embedding)。在ChromaDB中,這個過程是自動完成的,它內置了多種嵌入模型供我們選擇。
為了演示過程,我們先創建一個collection
collection = chroma_client.create_collection(name="my_collection")
添加一些數據
collection.add(documents=["This is a document about pineapple","This is a document about oranges"],ids=["id1", "id2"]
)
這里是為了簡單起見用的非常短的測試文本,在實際應用中,就是從文檔中切分出的某一段文字了。文檔顯示,Chroma使用all-MiniLM-L6-v2作為默認的embedding模型(第一次進行embedding時,可以看到下載模型的輸出\.cache\chroma\onnx_models\all-MiniLM-L6-v2\onnx.tar.gz). 這個模型參數量適中且經過充分訓練,在模型上加上分類頭進行classification任務也能取得很好的效果。
接下來進行一次query
results = collection.query(query_texts=["This is a query document about hawaii"], n_results=2 # 設置返回文檔數量,默認是10
)
print(results)
可以看到輸出的結果
{'ids': [['id1', 'id2']],'embeddings': None,'documents': [['This is a document about pineapple','This is a document about oranges']],'uris': None,'included': ['metadatas', 'documents', 'distances'],'data': None,'metadatas': [[None, None]],'distances': [[1.0404009819030762, 1.2430799007415771]]}
完整例子
import re
import ollama
import chromadb
from chromadb.config import Settings
from concurrent.futures import ThreadPoolExecutor# 1. 文檔加載與文本切分(這里以純文本為例,實際可用PyMuPDF等庫加載PDF)
def split_text(text, chunk_size=500, chunk_overlap=100):chunks = []start = 0length = len(text)while start < length:end = min(start + chunk_size, length)chunk = text[start:end]chunks.append(chunk)start += chunk_size - chunk_overlapreturn chunks# 2. 初始化Ollama Embeddings(DeepSeek-R1)
class OllamaDeepSeekEmbeddings:def __init__(self, model="deepseek-r1:14b"):self.model = modelself.client = ollama.Ollama()def embed_query(self, text):# 通過 Ollama API 調用 DeepSeek-R1 生成文本向量# Ollama Python SDK具體接口可能不同,以下為示例response = self.client.embeddings(model=self.model, input=text)return response['embedding']# 3. 初始化Chroma客戶端和向量庫
def init_chroma_collection(collection_name="rag_collection"):client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",persist_directory="./chroma_db"))collection = client.get_or_create_collection(name=collection_name)return client, collection# 4. 構建向量數據庫:將文本切分后生成embedding并存入Chroma
def build_vector_store(text, embedding_model, collection):chunks = split_text(text)# 并行生成向量def embed_chunk(chunk):return embedding_model.embed_query(chunk)with ThreadPoolExecutor() as executor:embeddings = list(executor.map(embed_chunk, chunks))# 插入Chromaids = [f"chunk_{i}" for i in range(len(chunks))]metadatas = [{"text": chunk} for chunk in chunks]collection.add(documents=chunks,embeddings=embeddings,metadatas=metadatas,ids=ids)collection.persist()# 5. 檢索相關文本
def retrieve_relevant_docs(query, embedding_model, collection, top_k=3):query_embedding = embedding_model.embed_query(query)results = collection.query(query_embeddings=[query_embedding],n_results=top_k,include=["documents", "metadatas"])# 返回文本塊列表return results['documents'][0]# 6. 結合上下文調用DeepSeek-R1生成回答
def generate_answer(question, context, model="deepseek-r1:14b"):client = ollama.Ollama()prompt = f"Question: {question}\n\nContext: {context}\n\nAnswer:"response = client.chat(model=model,messages=[{"role": "user", "content": prompt}])answer = response['message']['content']# 清理DeepSeek可能的特殊標記answer = re.sub(r'<think>.*?</think>', '', answer, flags=re.DOTALL).strip()return answer# 7. RAG整體調用示例
if __name__ == "__main__":# 假設有一個大文本知識庫knowledge_text = """這里放入你的知識庫文本,比如從PDF提取的內容。"""# 初始化embedding模型和Chromaembedding_model = OllamaDeepSeekEmbeddings(model="deepseek-r1:14b")client, collection = init_chroma_collection()# 構建向量數據庫(首次運行)build_vector_store(knowledge_text, embedding_model, collection)# 用戶提問user_question = "什么是深度學習?"# 檢索相關上下文relevant_chunks = retrieve_relevant_docs(user_question, embedding_model, collection, top_k=3)combined_context = "\n\n".join(relevant_chunks)# 生成回答answer = generate_answer(user_question, combined_context)print("回答:", answer)總結
本文介紹了RAG的原理并給出代碼示例,相信能夠幫助讀者快速熟悉RAG并上手開發應用.





vit -- vision transformer 和其變體調研)


基本概念與核心原理)






)



