大綱
1.Nacos集群模式的數據寫入存儲與讀取問題
2.基于Distro協議在啟動后的運行規則
3.基于Distro協議在處理服務實例注冊時的寫路由
4.由于寫路由造成的數據分片以及隨機讀問題
5.寫路由 + 數據分區 + 讀路由的CP方案分析
6.基于Distro協議的定時同步機制
7.基于Distro協議的心跳校驗下的數據同步補償機制
8.基于Raft協議實現的弱CP模式
9.Nacos集群模式下的lookup尋址機制
1.Nacos集群模式的數據寫入存儲與讀取問題
使用Nacos進行服務注冊時,需要解決如下問題:
一.應該找集群里的哪個節點來發起服務注冊?
二.服務實例數據應該存儲在集群的哪個節點?
三.應該找集群里的哪個節點來發起服務發現?
2.基于Distro協議在啟動后的運行規則
(1)Nacos集群啟動后會按如下規則運行
(2)Distro協議 + 定時數據同步與AP + 心跳檢驗與網絡分區
(1)Nacos集群啟動后會按如下規則運行
一.Nacos集群的每個節點都可以處理寫請求
Nacos集群節點收到寫請求后:首先根據要注冊的服務實例的IP:端口 + 路由算法,計算出所屬集群節點。然后把服務實例注冊請求轉發到負責該服務實例數據的集群節點中。接著負責該服務實例數據的集群節點就會解析請求,把數據存儲到內存里。同時會定期執行同步任務,把本節點負責的數據同步到其他節點。最終每個節點都會存儲全量的服務實例數據。
二.新加入Nacos集群的節點會拉取全量數據
新加入Nacos集群的節點會輪詢Nacos集群的所有節點,然后發送請求出去拉取各節點的數據,所以Nacos集群的每個節點上都會有所有已注冊的服務實例的數據。
三.每個節點都會定期發送心跳給其他節點
Nacos集群的節點通過心跳請求進行數據校驗,主要是交換數據的校驗值。如果發現其他節點上的數據與自己的不一致,就會全量拉取數據進行補齊。
四.Nacos集群的每個節點都可以處理讀請求
因為每個節點都有全量數據,所以每個節點都可以處理讀請求。
(2)Distro協議 + 定時數據同步與AP + 心跳檢驗與網絡分區
Distro協議兼顧了CAP中的AP。在這個協議下,所有節點通過定期數據同步 + 心跳校驗實現數據最終一致。這個協議能讓每個節點都有全量數據。
如果出現某節點宕機,不影響集群可用性。如果出現網絡分區,同樣不影響集群可用性。因為不同的網絡分區只會讀寫分區中的Nacos節點,此時只是沒辦法同步數據而已。雖然數據會不一致,但一旦分區恢復后,心跳校驗機制運作起來,數據會自動補齊。
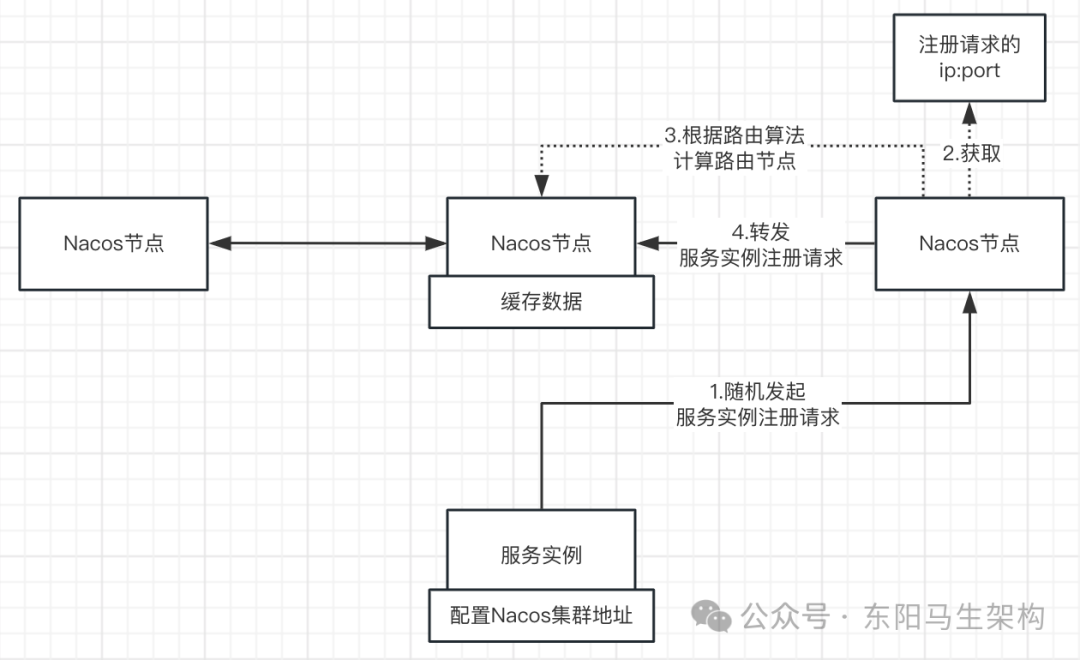
3.基于Distro協議在處理服務實例注冊時的寫路由
首先,服務實例會隨機選擇Nacos集群中的一個節點發起注冊請求。
然后,Nacos集群節點收到寫請求后:會根據要注冊的服務實例的IP:端口 + 路由算法,計算出所屬的集群節點。
接著,把服務實例注冊請求轉發到負責該服務實例數據的集群節點中。負責該服務實例數據的節點會解析請求,緩存服務實例數據到內存中。
4.由于寫路由造成的數據分片以及隨機讀問題
由于Nacos集群節點收到寫請求后:會根據要注冊的服務實例的IP:端口 + 路由算法,計算出所屬的集群節點。所以會導致數據分片,即每個節點僅負責管理一部分的服務實例數據。
服務實例進行服務發現時,只能隨機選擇一個Nacos節點來讀取數據。對Nacos集群節點進行隨機讀的時候,由于每個節點只負責處理部分數據,所以可能出現讀取不到剛向集群注冊的數據的隨機讀問題。
5.寫路由 + 數據分區 + 讀路由的CP方案分析
在數據分區 + 隨機讀的情況下,此時為了讀取到數據,有兩種解決方案。
方案一:讓隨機選擇的節點重新進行讀路由
方案二:讓隨機選擇的節點也擁有全部數據
如果采用方案一,也就是寫路由 + 數據分片 + 讀路由的架構設計。那么讀寫某個服務實例的數據,只能由Nacos集群中的其中一個節點處理。如果節點宕機,那么對應的該服務實例數據就不可用。雖然該節點的數據不可用,但也是對所有用戶都不可用,視圖是一致的。視圖是一致的,說明要么都能讀到數據,要么都讀不到數據。所以這種方案會存在可用性的問題,但優點是數據是強一致的。也就是犧牲了CAP中的A,沒有了可用性,但保證了CP。
Nacos的Distro協議則使用了方案二。某個節點宕機后,該節點的數據不會全部不可用,可能會丟失部分數據。也就是犧牲了CAP中的C,不能確保強一致性,但保證了AP。加上Distro協議的同步機制,可以讓各節點的數據實現最終一致性。
6.基于Distro協議的定時同步機制
Nacos集群中的每個節點,雖然通過寫路由只寫入由自己處理的數據,但同時也會定期執行同步任務,把本節點負責的數據同步到其他節點,最終每個節點都會存儲全量的集群數據。
同步機制的存在保證了各節點的數據最終是一致的。
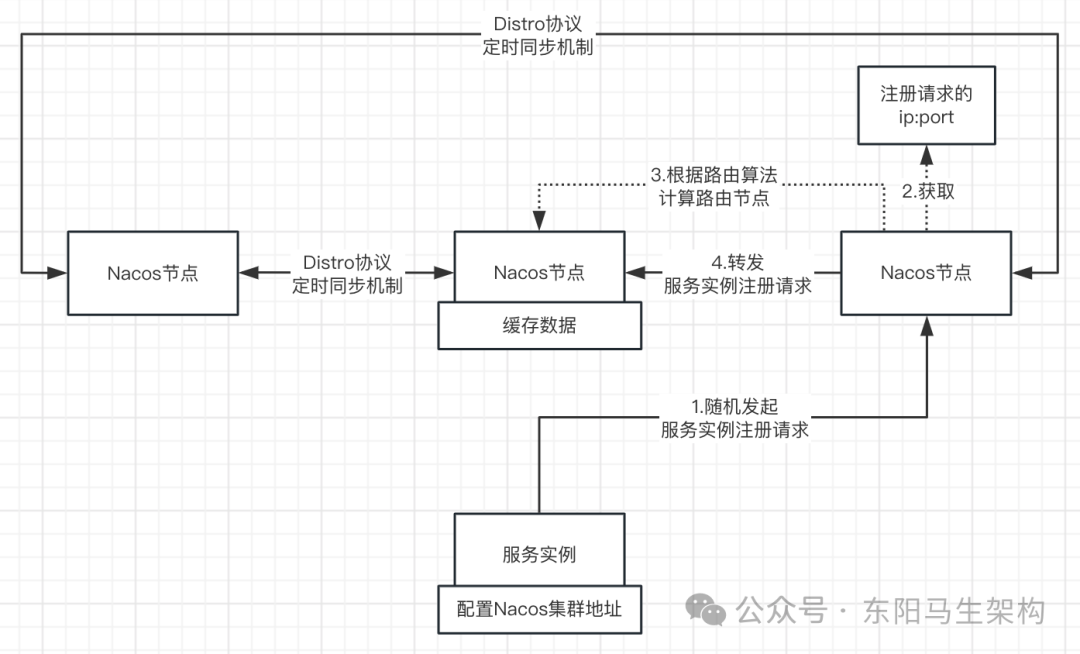
7.基于Distro協議的心跳校驗下的數據同步補償機制
Nacos集群的節點通過心跳請求進行數據校驗,主要是交換數據的校驗值。如果發現其他節點上的數據與自己的不一致,就會全量拉取數據進行補齊。
當出現網絡分區時,兩分區間的節點無法通信,此時自然就無法定時同步。但當分區恢復后,節點之間通過心跳校驗機制,數據可以快速自動補齊。
8.基于Raft協議實現的弱CP模式
Nacos集群節點在啟動時會選舉出一個Leader節點,由Leader節點負責數據的寫入,并將數據同步給其他節點。Leader節點成功寫入數據的判斷依據是,過半節點都成功同步數據了。
9.Nacos集群模式下的lookup尋址機制
(1)單機尋址
(2)文件尋址
(3)地址服務器尋址
尋址就是Nacos各節點啟動時如何找到其他節點。
(1)單機尋址
Nacos通過"-m standalone"模式來啟動時,會讀取自己本機的IP:端口,然后構造對象放入到ServerMemberManager,它是專門負責管理所有節點信息的組件。
(2)文件尋址
cluster.conf里會寫入各個節點地址,節點啟動時會讀取這個文件的內容。同時節點會針對這個文件施加監聽器,如果發現文件有變動,會進行重新讀取。但是需要手工維護每個節點的cluster.conf文件,比較適合常規的、三節點、小規模的生產集群部署。
(3)地址服務器尋址
如果Nacos需要進行大規模的集群部署,一般會采用這個方案。也就是使用一個Web服務器來維護一份cluster.conf,然后所有的Nacos都定時請求這個Web服務器獲取最新的地址列表。





)
)












設計)