01
引言
本文介紹的是在 LLM 討論中經常聽到的各種量化技術。本文的目的是提供一步一步的解釋和代碼,讓大家可以自己使用這些技術來壓縮模型。

閑話少說,我們來研究一下吧!
02
Quantization
量化是指將高精度數字轉換為低精度數字。低精度實體可以存儲在磁盤上很小的空間內,從而減少內存需求。讓我們從一個簡單的量化例子開始,以澄清概念。
假設有 25 個 FP16 格式的權重值,如下圖矩陣所示。

我們需要對這些值進行 int8 量化。具體步驟如下。
-
舊數值的取值范圍= fp16 格式的最大權重值 - fp16 格式的最小權重值 = 0.932-0.0609 = 0.871
-
新數值的取值范圍 = Int 8 包含 -128 至 127 的數字。因此,Range = 127-(-128) = 255
-
Scale: 新范圍內的最大值/舊范圍內的最大值=127/ 0.932 =136.2472498690413
-
量化后的值: 計算公式為:
Quantized Value = Round(Scale * Original Value)
經過上述轉換,得到量化后的結果為:
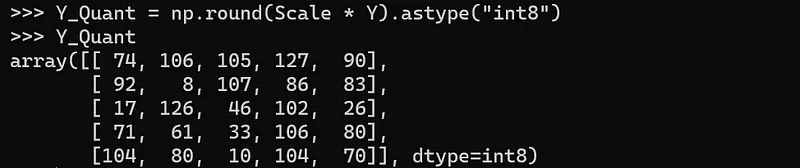
-
進而反量化操作的計算公式為:
New Value = Quantized Value / Scale

- 量化誤差:
這里需要注意的一點是,當我們去量化回到 fp16 格式時,我們會發現數字似乎并不完全相同。第一個元素 0.5415 變成了 0.543。在大多數元素中都可以發現同樣的問題。這就是量化-去量化過程中產生的誤差。
既然我們已經了解了量化的核心思想,下面我們就來談談 LLM 的量化類型。
?
03
GPTQ原理?
GPTQ是一種訓練后量化方法。這意味著在獲得預訓練的大型語言模型(LLM)后,您只需將模型參數轉換為較低精度即可。GPTQ更適用于GPU而非CPU。以下是GPTQ的幾種主要變體:
- 靜態范圍GPTQ:可將權重和激活值轉換為較低精度。
- 動態范圍GPTQ:將權重轉換為較低精度,并開發一個函數用于在推理過程中動態將激活值量化為較低精度。
- 權重量化: 通過降低模型權重和/或激活值的精度來節省存儲空間。在推理時,輸入仍保持float32格式,因此需要將權重還原至與輸入相同的精度進行計算。然而,由于舍入誤差,這一過程會導致一定的精度損失。
我們首先來看下靜態范圍量化的過程:
- 如果大家打算同時量化權重和激活,則需要一個樣本校準數據集來進行 GPTQ。
- 校準數據集 - 該數據集可以是從原始數據集中抽取的樣本。例如,從原始預訓練數據集中抽取 1000 個數據樣本,作為整個數據集的代表性樣本。
- 校準數據集推理 - 接著將使用該校準數據集進行推理,以找到采樣權重和相應激活的分布。該分布將作為量化的基礎。 例如,特定層中激活值的范圍是 0.2 至 0.9,權重的范圍是 0.1 至 0.3。有了最小-最大值范圍后,就可以使用本文之前解釋的數學方法對該層進行量化。
- 靜態范圍量化算法概述 :
在GPTQ算法中,我們逐層對神經網絡進行量化,具體步驟如下:
a. 權重矩陣分組
將每一層的權重矩陣按列劃分為若干組。
例如,若設置group_size=128,則權重矩陣會被劃分為多個128列的組。
b. 迭代式量化處理
在每組(128列)中,先量化其中一列的數據。
量化后,調整該組剩余的權重,以補償量化引入的誤差。
c. 全局誤差補償
處理完當前組的所有列后,更新整個矩陣的其他列組(其他128列組),以進一步修正誤差。這一完整過程也稱為"惰性批量更新”(Lazy Batch Update)。
接下來,我們通過代碼示例進一步說明。
04
GPTQ代碼實現?
這種量化方法需要使用GPU。起初,我嘗試對一個7B分片的Mistral模型進行量化,但失敗了。這是因為模型在下載后首先加載到CPU上,而T4顯卡的CPU內存不足以支持。最終,我選擇了一個較小的模型,可以在Google Colab的免費T4實例中容納。這個模型是來自HF倉庫的bigscience/bloom-3b。
!pip install auto_gptq
import torch
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import TextGenerationPipeline
from transformers import AutoTokenizer
pretrained_model_name = "bigscience/bloom-3b"
quantize_config = BaseQuantizeConfig(bits=4, group_size=128)
# Tensors of bloom are of float16. Hence, torch_dtype=torch.float16. Do not leave torch_dtype as "auto" as this leads to a warning of implicit dtype conversion
model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_name, quantize_config, trust_remote_code=False, device_map="auto", torch_dtype=torch.float16) # changing device map to "cuda" does not have any impact on T4 GPU mem usage.
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name)
# Calibration
examples = [tokenizer("Automated machine learning is the process of automating the tasks of applying machine learning to real-world problems. AutoML potentially includes every stage from beginning with a raw dataset to building a machine learning model ready for deployment.")
] # giving only 1 example here for testing. In an real world scenario, you might want to give 500-1000 samples.
model.quantize(examples)
quantized_model_dir = "bloom3b_q4b_gs128"
model.save_quantized(quantized_model_dir)
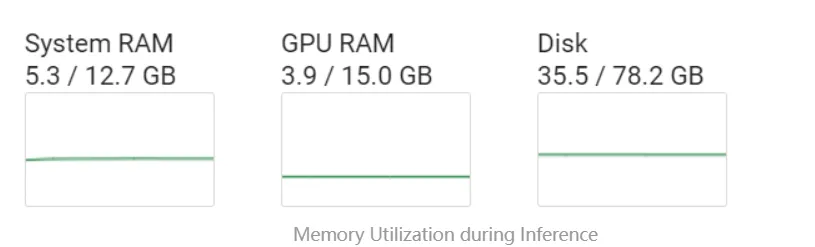
從下面的圖片可以注意到一個重要的點:在量化過程中,GPU內存其實并沒有被充分利用,雖然GPU是進行量化的前提條件。

我們使用以下代碼測試下量化模型的輸出:
# Inference with quantized model
device = "cuda:0" # make use of GPU for inference.
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device=device, torch_dtype=torch.float16)
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer, max_new_tokens=50)
print(pipeline("Automated machine learning is")[0]["generated_text"])
# Sequence length of a model (bloom has seq length of 2048) is total tokens in input & output;
# max_new_tokens is number of output tokens
# Do note that there is a warning while executing this code that model's sequence length was not in model config. However, what i could find any option to pass the seq length of bloom in configurations.
# The warnings related to fused modules & unsupported model is not valid. The links that i used to validate this are in references.
結果如下:

當執行推理代碼(上圖)時,GPU 的使用率會上升。這意味著量化模型正從 CPU 轉移到 GPU,從而增加了 GPU 內存消耗。
至此,GPTQ 結束。
?
05
GGUF | GGML?
GGUF是GGML的升級版本。GGML作為LLM庫的C++實現,支持LLaMA系列、Falcon等多種大語言模型。基于該庫的模型可運行于蘋果自研芯片(Mac OS系統)——這種由蘋果獨創的處理器創新性地集成了CPU與GPU功能。
GGUF格式同時兼容Windows和Linux操作系統,這意味著普通CPU環境也能運行這些模型。當CPU性能不足時,用戶還可將部分模型層卸載至GPU運算。該格式提供從2比特到8比特的多級量化選項,具體操作流程為:先獲取原始LLaMA模型,將其轉換為GGUF格式,最終對GGUF格式進行低精度量化處理。
# Install llama.cpp
!git clone https://github.com/ggerganov/llama.cpp
!cd llama.cpp && git pull && make clean && LLAMA_CUBLAS=1 make
!pip install -r llama.cpp/requirements.txt
# Download model
!git lfs install
!git clone https://huggingface.co/Siddharthvij10/MistralSharded2
# Convert weights to fp16
!python llama.cpp/convert.py MistralSharded2 --outtype f16 --outfile "MistralSharded2/mistralsharded2.fp16.bin"
# Quantization - Requires GPU RAM as a mandate. However, does not use much of it.
# As per info on https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML, q4_k_m uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q4_K!./llama.cpp/quantize "MistralSharded2/mistralsharded2.fp16.bin" "MistralSharded2/mistralsharded2.Q4_K_M.gguf" q4_k_m
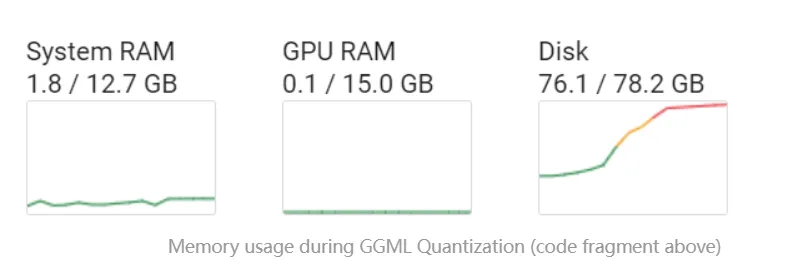
GGML 量化過程中的內存使用情況:
比較原始模型和 GGML 模型的大小:

推理代碼如下:
import os# There are 32 layers in mistral 7B. Hence offloading all 32 layers to GPU while loading for inference below.!./llama.cpp/main -m "MistralSharded2/mistralsharded2.Q4_K_M.gguf" -n 35 --color -ngl 32 -p "Automated machine learning"
結果如下:

推理過程中 GPU 的使用情況:

06
QAT?
我們開始進行量化感知訓練(QAT)時,會使用一個預訓練模型或后訓練量化(PTQ)模型作為基礎。若采用PTQ模型,QAT微調的主要目的是恢復因PTQ過程造成的精度損失。QAT會改變模型的前向傳播過程,但保持反向傳播不受影響。在QAT中,我們只對那些參數量化后不會導致精度顯著下降的網絡層實施量化操作,而對量化會負面影響精度的層則保留其原始精度。
QAT的核心思想是根據每層權重的精度要求,將輸入數據量化為較低精度。同時,若下一層需要更高精度,QAT還會負責將權重與輸入相乘后的輸出重新轉換回高精度。這種先將輸入降精度、再將計算輸出恢復高精度的過程被稱為"偽量化節點插入"——之所以稱為"偽量化",是因為它既執行量化又執行反量化,最終還原為基礎運算。
QAT在前向傳播中引入量化誤差,這些誤差會累積并通過反向傳播中的優化器進行調整。通過這種方式,模型能夠學習如何通過減小量化引入的誤差來優化自身性能。
請注意,TensorFlow 官網上提供了幾段代碼示例,其中一段使用標準 TensorFlow,另一段使用 tf-nightly。我在使用標準 TensorFlow 時遇到了“模型中的某些層不支持 QAT”的錯誤,因此切換到了 nightly 版本。此外,我還移除了 Keras 模型中的所有復雜層(如自定義層或高級結構)。由于這只是一個演示用的簡單模型,代碼是在 CPU 上運行的。
! pip uninstall -y tensorflow
! pip install -q tf-nightly # Use tf-nightly instead of tensorflow since it gets updated with fixes every day
! pip install -q tensorflow-model-optimization # this lib is used for QAT
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_model_optimization as tfmot
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
### Sample Keras model - Code generated by ChatGPT
# Generate sample data
np.random.seed(0)
data = pd.DataFrame(np.random.rand(1000, 5), columns=['Feature1', 'Feature2', 'Feature3', 'Feature4', 'Feature5'])
target = pd.Series(np.random.randint(0, 2, size=1000), name='Target')
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=42)
# Standardize features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define the Keras model
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu', input_shape=(5,)),tf.keras.layers.Dense(32, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X_train_scaled, y_train, epochs=10, batch_size=32, validation_split=0.2)
# Evaluate the model
test_loss, test_accuracy = model.evaluate(X_test_scaled, y_test)
print(f'Test Loss: {test_loss}, Test Accuracy: {test_accuracy}')
quant_aware_model = tfmot.quantization.keras.quantize_model(model)
quant_aware_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Fine tune to create a quant aware model
quant_aware_model.fit(X_train_scaled, y_train, epochs=10, batch_size=32, validation_split=0.2)
# Evaluate the quant aware model
test_loss, test_accuracy = quant_aware_model.evaluate(X_test_scaled, y_test)
print(f'Test Loss: {test_loss}, Test Accuracy: {test_accuracy}')
結果如下:

07
AWQ?
AWQ適用于 GPU 或 CPU。其核心思想是不量化所有權重,而是選擇性量化對模型性能影響較小的權重,從而保持模型的有效性。
算法流程:
a. 校準(Calibration)
向預訓練的大語言模型(LLM)輸入樣本數據,分析權重和激活值的分布。
識別關鍵激活值及其對應的權重(即對模型輸出影響較大的部分)。
b. 縮放(Scaling)
放大關鍵權重(提高其數值范圍),同時對非關鍵權重進行低精度量化。
由于重要權重被保留(甚至增強),而次要權重被壓縮,量化帶來的精度損失被最小化。
c. 權重格式要求(SafeTensor)
AWQ 要求模型權重從 PyTorch 的 .bin 格式轉換為 SafeTensor(.safetensors)格式。轉換方法可參考官方指南:
鏈接:https://huggingface.co/spaces/safetensors/convert



)
)












設計)


