1.?YOLO系列整體介紹
?
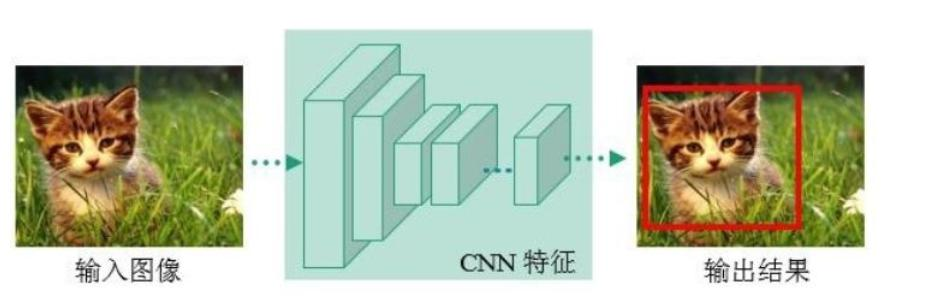
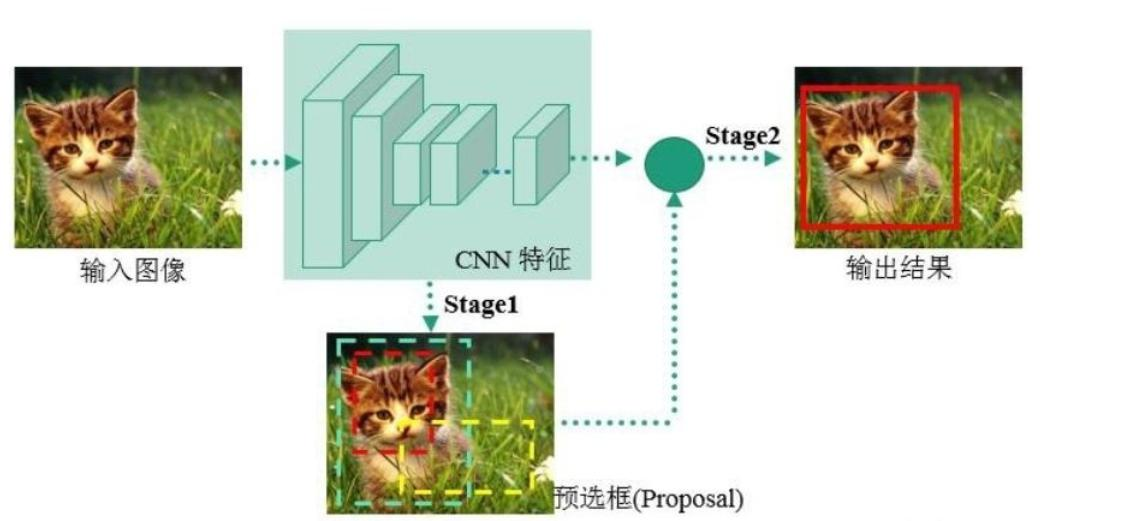
YOLO屬于深度學習經典檢測方法中的單階段(one - stage)類型,與兩階段(two - stage,如Faster - rcnn、Mask - Rcnn系列)方法相對。
不同模型性能
單階段方法的最核心優勢是速度非常快,適合做實時檢測任務,但通常檢測效果不如兩階段方法
?
2.?指標分析
?
map指標:綜合衡量檢測效果,不能僅依靠精度(Precision)和召回率(Recall)來評估檢測模型性能。


?
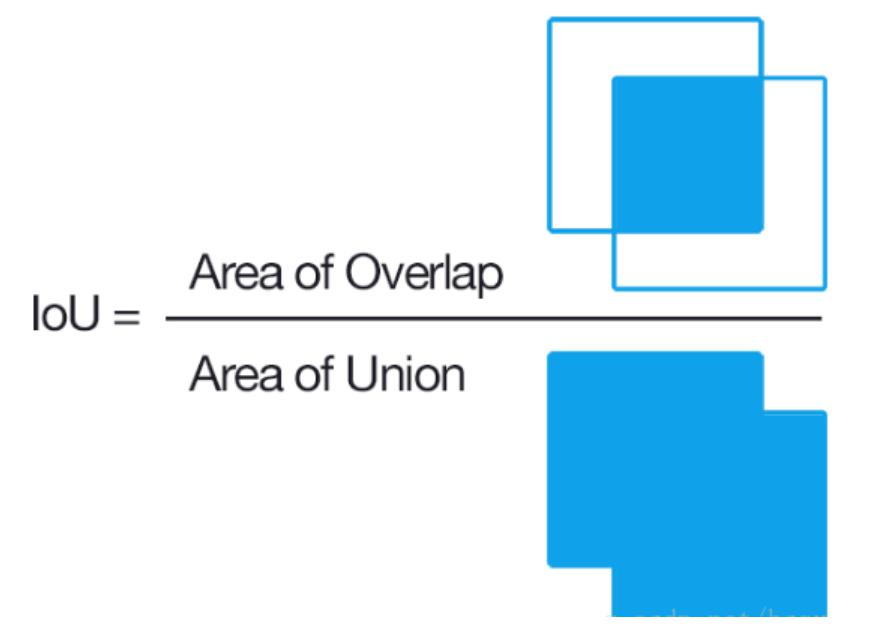
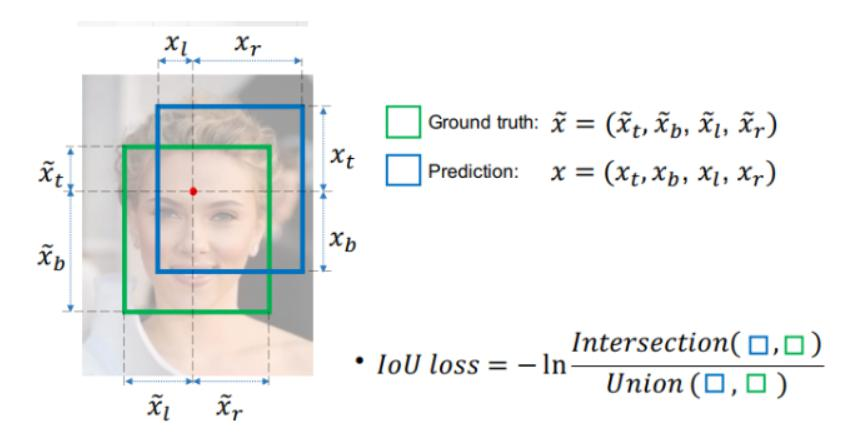
IOU(交并比):計算公式為,用于衡量預測框與真實框的重疊程度。
?
Precision和Recall:
Precision(精度)公式為,
Recall(召回率)公式為。
?基于置信度閾值來計算,例如分別計算0.9;0.8;0.7
0.9時:TP+FP = 1,TP = 1 ;FN = 2;Precision=1/1;Recall=1/3;
AP與MAP:
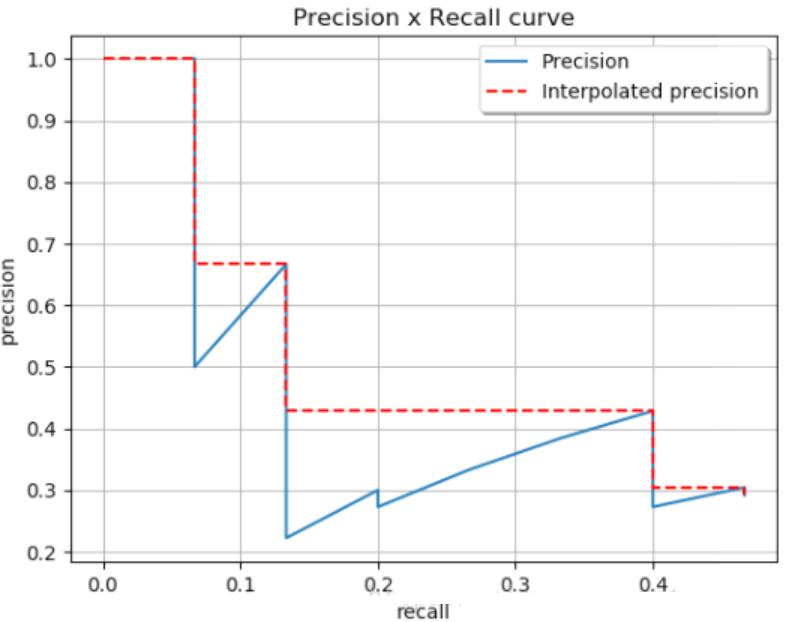
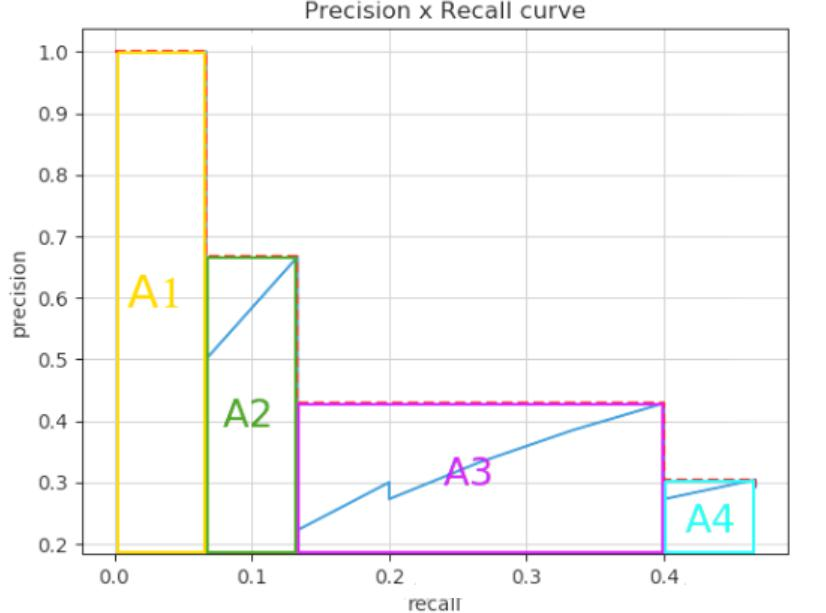
AP(Average Precision)計算需要考慮所有閾值,MAP(Mean Average Precision)是所有類別的平均AP,通過Precision - Recall曲線來理解。
?
3.?YOLO - V1
?
?
核心思想與方法:
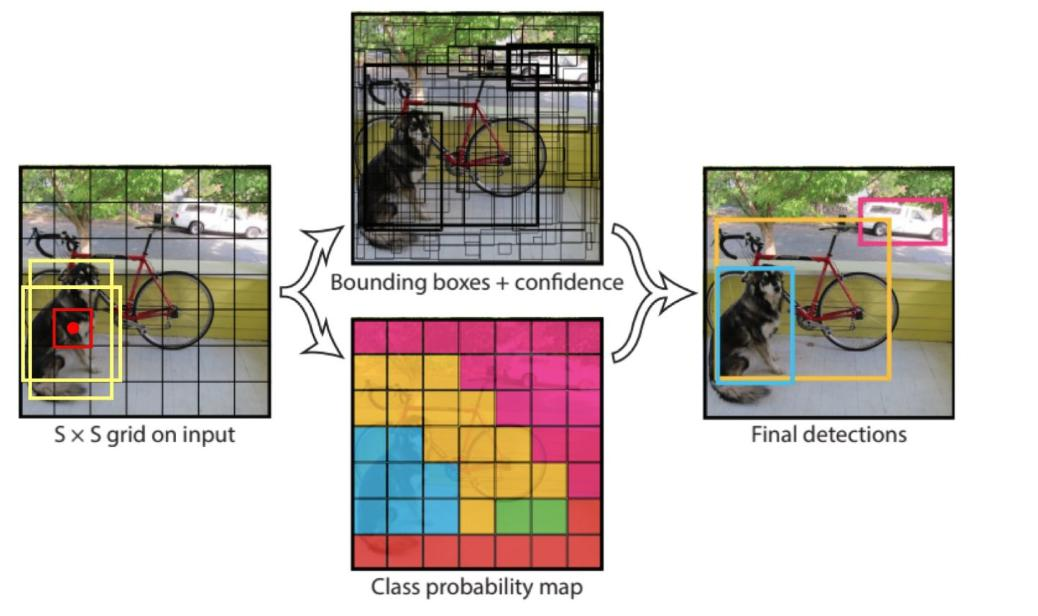
經典的one - stage方法,把檢測問題轉化成回歸問題,使用一個CNN即可完成檢測任務。
?
應用領域:可以對視頻進行實時檢測,應用領域廣泛。
?
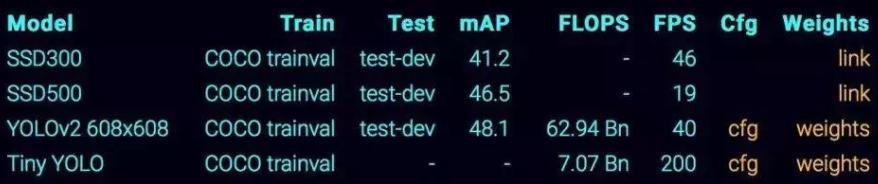
性能指標對比:
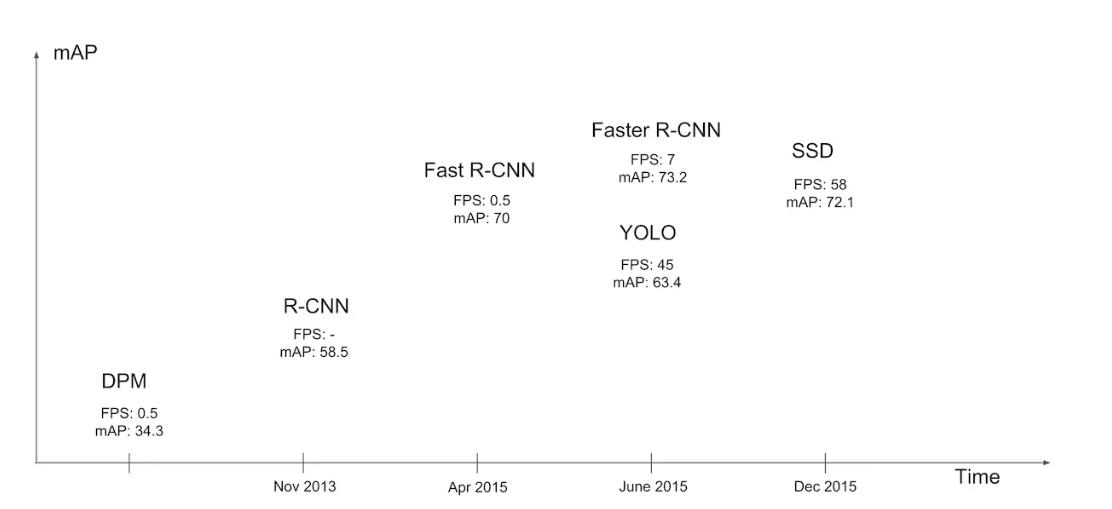
?
網絡架構:輸入圖像后經過一系列卷積層(CR)、全連接層(FC)處理,最終輸出預測結果。7×7表示最終網格的大小,每個網格預測B個邊界框,每個邊界框包含位置(X, Y, H, W)、置信度C等信息。
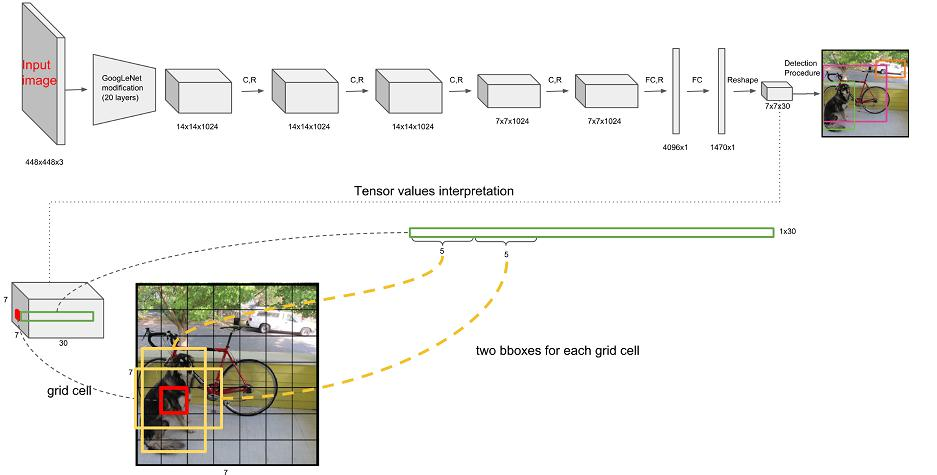
7×7表示最終網格的大小,每個網格預測B個邊界框,每個邊界框包含位置(X, Y, H, W)、置信度C等信息。
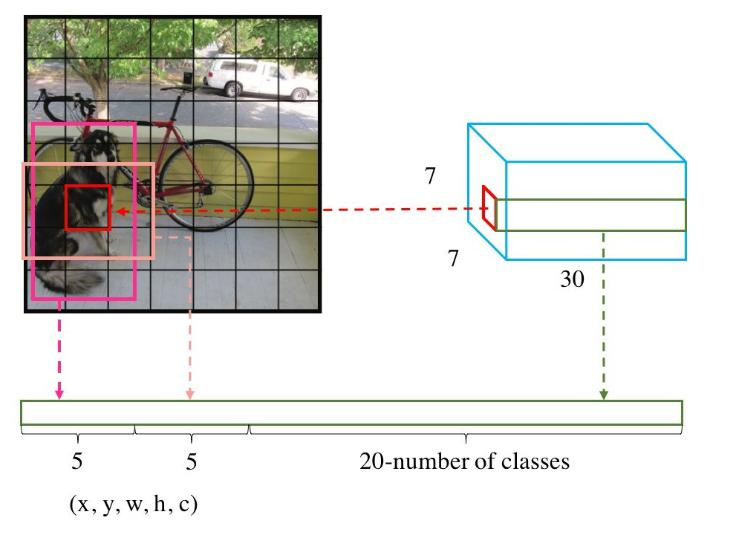
每個數字的含義:
10 =(X,Y,H,W,C)*B(2個)當前數據集中有20個類別,
7*7表示最終網格的大小(S*S)*(B*5+C)
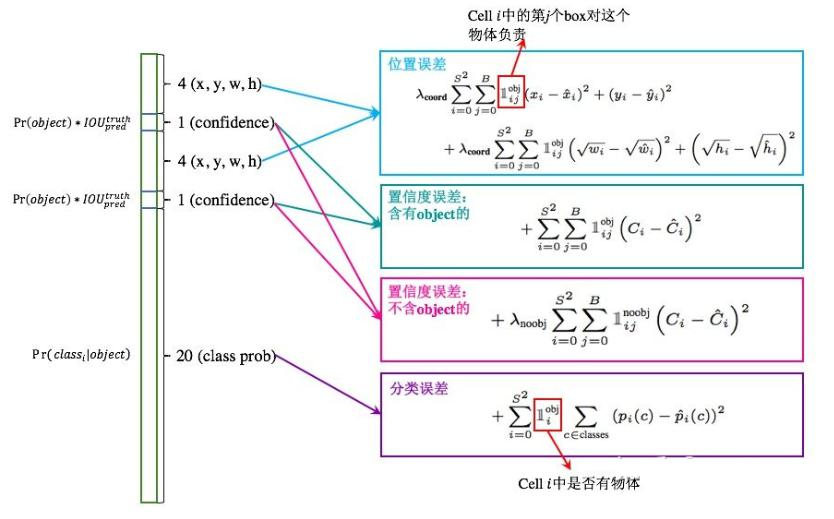
損失函數:包含位置誤差、置信度誤差(分含有物體和不含物體兩種情況)、分類誤差。
NMS(非極大值抑制)
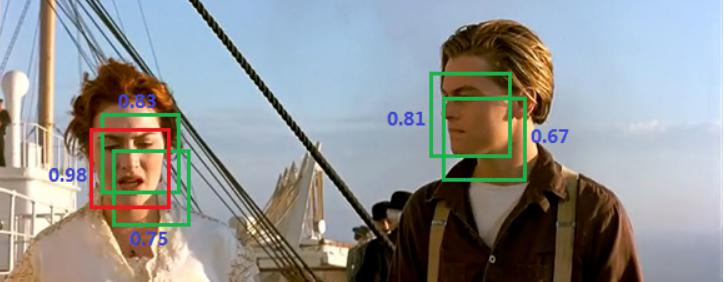
優點與問題:優點是快速、簡單;問題在于每個Cell只預測一個類別,重疊物體檢測存在困難,小物體檢測效果一般,長寬比可選但單一。
4.?YOLO - V2
?
整體提升:相比YOLO - V1更快、更強,在VOC2007數據集上mAP達到78.6。
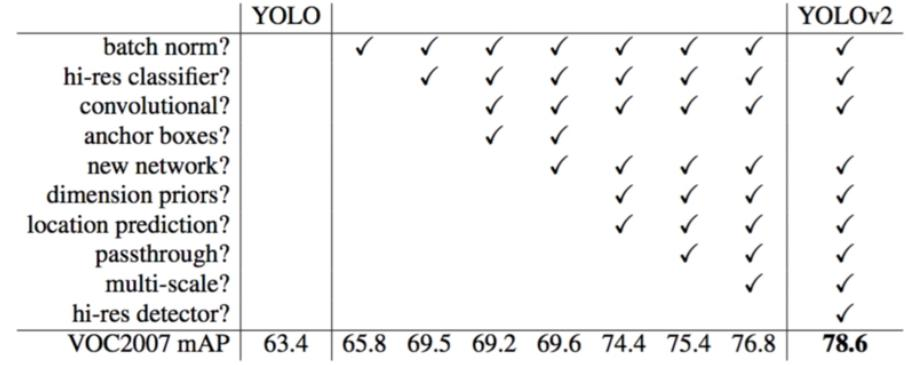
?
改進點
?
Batch Normalization:舍棄Dropout,卷積后全部加入Batch Normalization,使網絡每一層輸入歸一化,收斂更容易,mAP提升2%。
?
更大的分辨率:V1訓練和測試分辨率不同,訓練時用的是224*224,測試時使用448*448,可能導致模型水土不服。V2訓練時額外進行10次448×448的微調,使用高分辨率分類器后,mAP提升約4%。
?
網絡結構:采用DarkNet架構,實際輸入為416×416,沒有FC層,5次降采樣,通過1×1卷積節省參數。
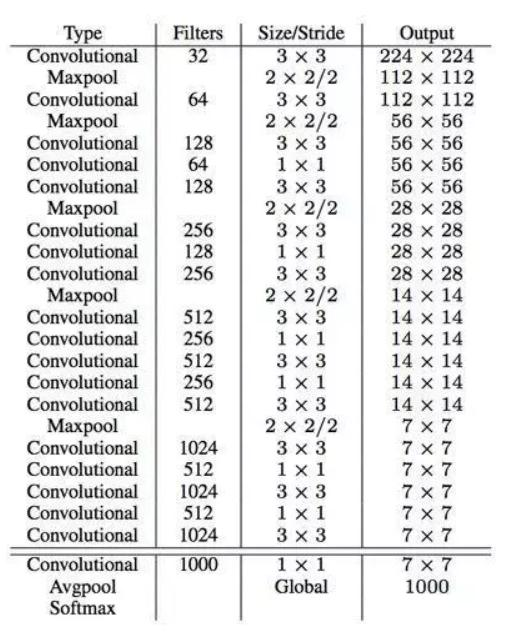
?
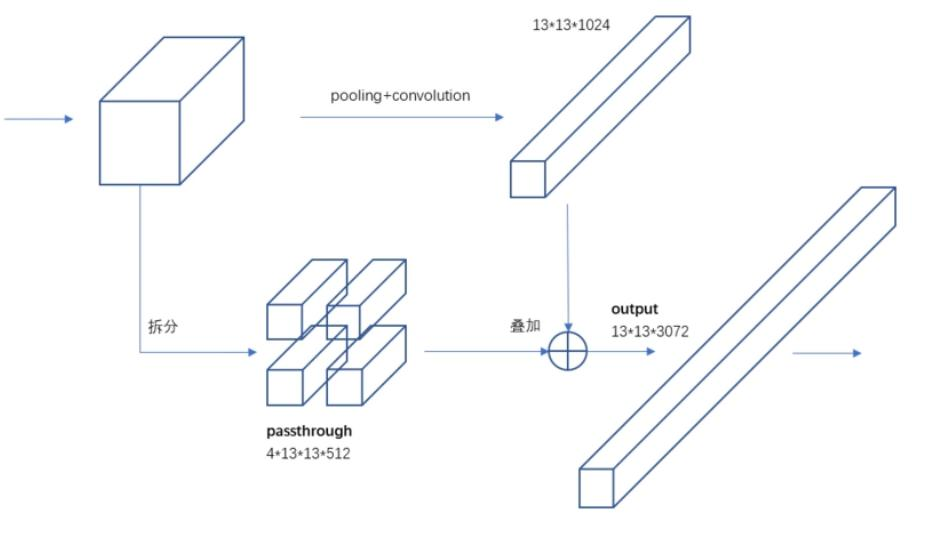
聚類提取先驗框:通過K - means聚類確定先驗框,使預測的box數量更多(13×13×n),先驗框不是直接按固定長寬比給定,引入anchor boxes后召回率提升。
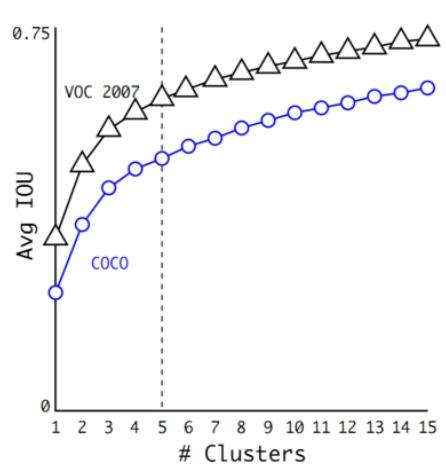
?
Anchor Box:
通過引入anchor boxes,使得預測的box數量更多(13*13*n)
跟faster-rcnn系列不同的是先驗框并不是直接按照長寬固定比給定
?

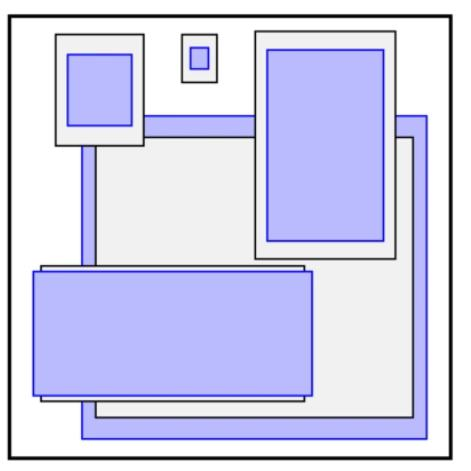
Directed Location Prediction:改進位置預測方式,使用相對grid cell的偏移量,避免模型不穩定問題,計算公式為
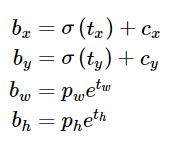
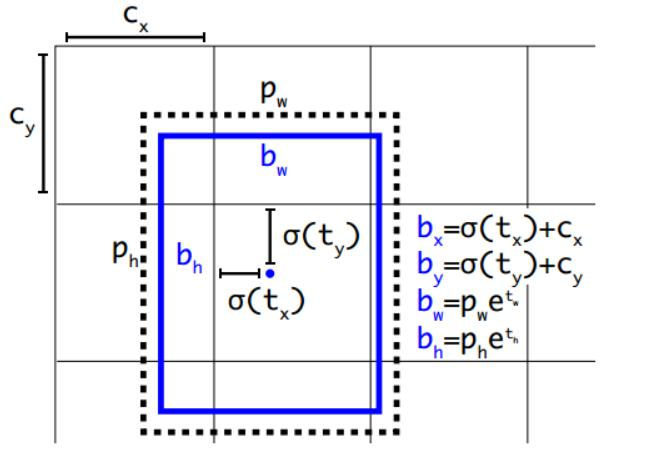
例如預測值(σtx,σty,tw,th)=(0.2,0.1,0.2,0.32),anchor框為:
![]()
在特征圖位置:
在原位置:
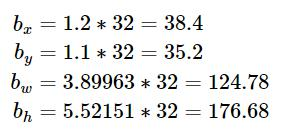
感受野與小卷積核優勢:
概述來說就是特征圖上的點能看到原始圖像多大區域
?
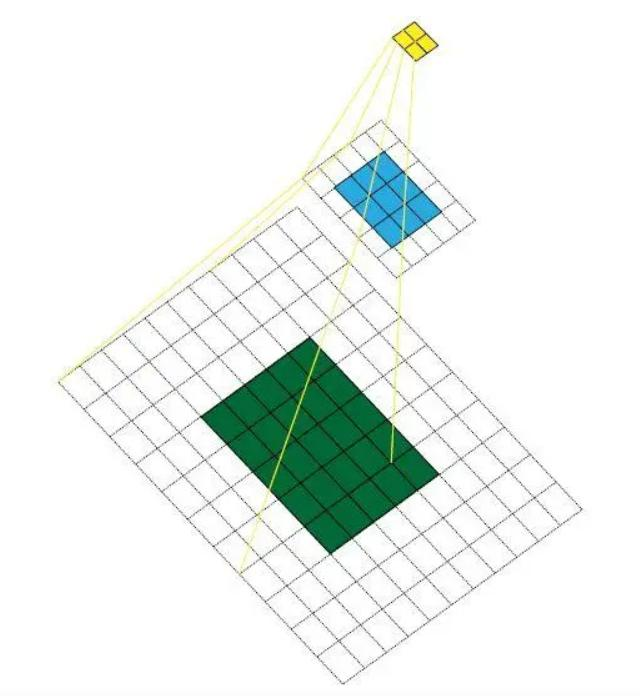
?如果堆疊3個3*3的卷積層,并且保持滑動窗口步長為1,其感受野就是7*7的了,這跟一個使用7*7卷積核的結果是一樣的,那為什么非要堆疊3個小卷積呢?
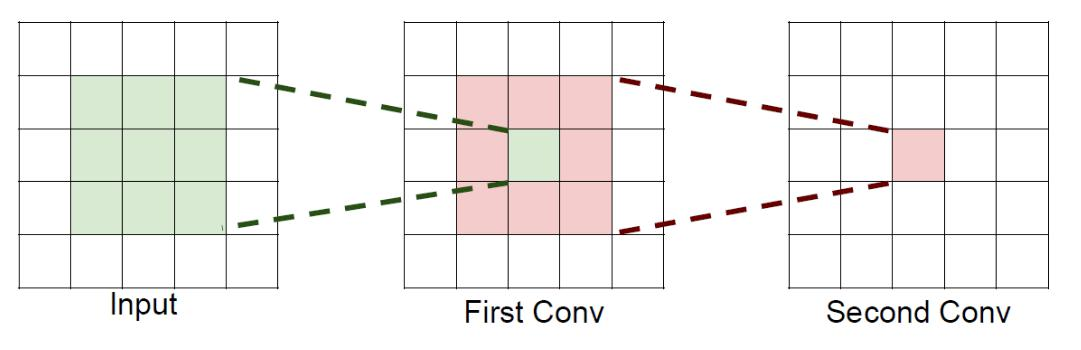
假設輸入大小都是h*w*c,并且都使用c個卷積核(得到c個特征圖),可以來計算一下其各自所需參數:
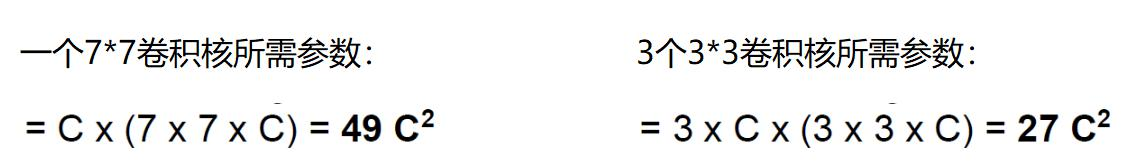
很明顯,堆疊小的卷積核所需的參數更少一些,并且卷積過程越多,特征提取也會越細致,加入的非線性變換也隨著增多,還不會增大權重參數個數,這就是VGG網絡的基本出發點,用小的卷積核來完成體特征提取操作。
Fine - Grained Features:融合之前的特征,解決最后一層感受野太大導致小目標可能丟失的問題。
?
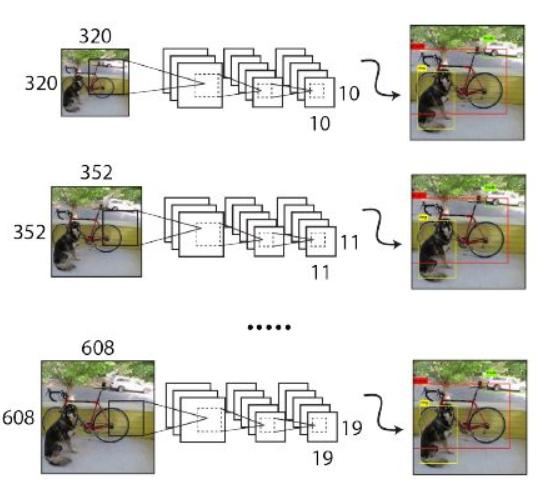
Multi - Scale:利用卷積操作特性,在一定iterations之后改變輸入圖片大小,最小320×320,最大608×608,以適應不同尺度目標檢測。
?
5.?YOLO - V3
?
主要改進:最大改進在于網絡結構,更適合小目標檢測。特征提取更細致,融入多尺度特征圖信息預測不同規格物體,先驗框更豐富(3種scale,每種3個規格,共9種),改進softmax用于預測多標簽任務。
?
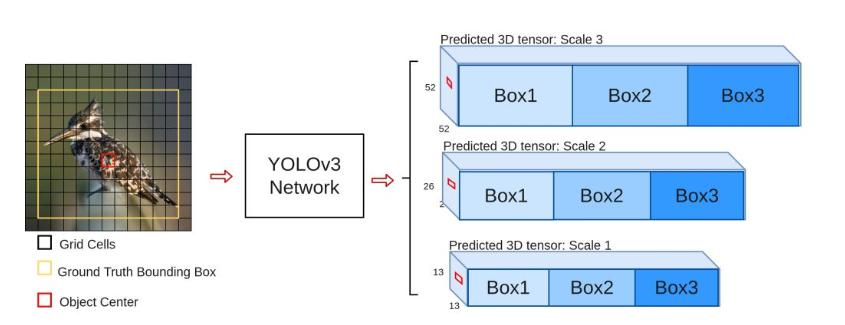
多scale檢測:設計3個scale用于檢測不同大小物體,介紹了不同scale的預測張量以及與特征圖的關系。
?
cale變換經典方法
左圖:對不同的特征圖分別利用;右圖:不同的特征圖融合后進行預測
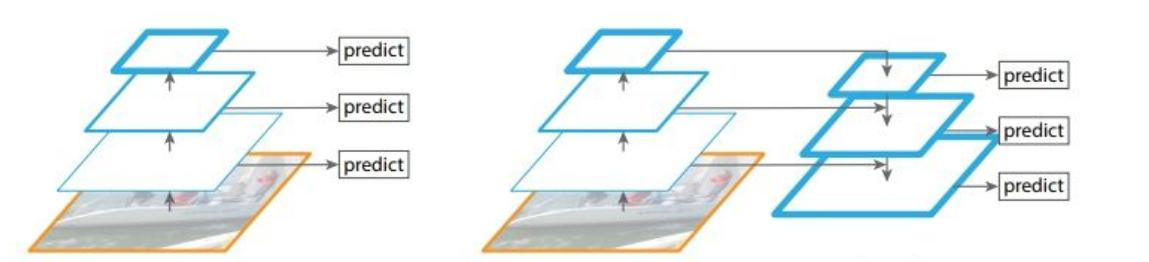
?
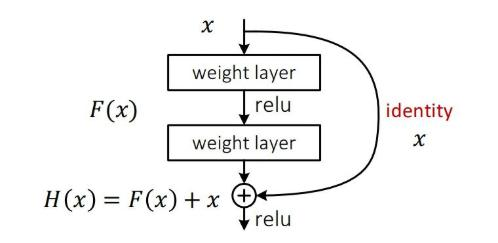
殘差連接:采用resnet的思想,堆疊更多層進行特征提取,利用殘差連接提升性能。從今天的角度來看,基本所有網絡架構都用上了殘差連接的方法
?
核心網絡架構:沒有池化和全連接層,全部采用卷積,下采樣通過stride為2實現,展示了網絡的輸入、卷積層操作以及輸出的相關信息。
?
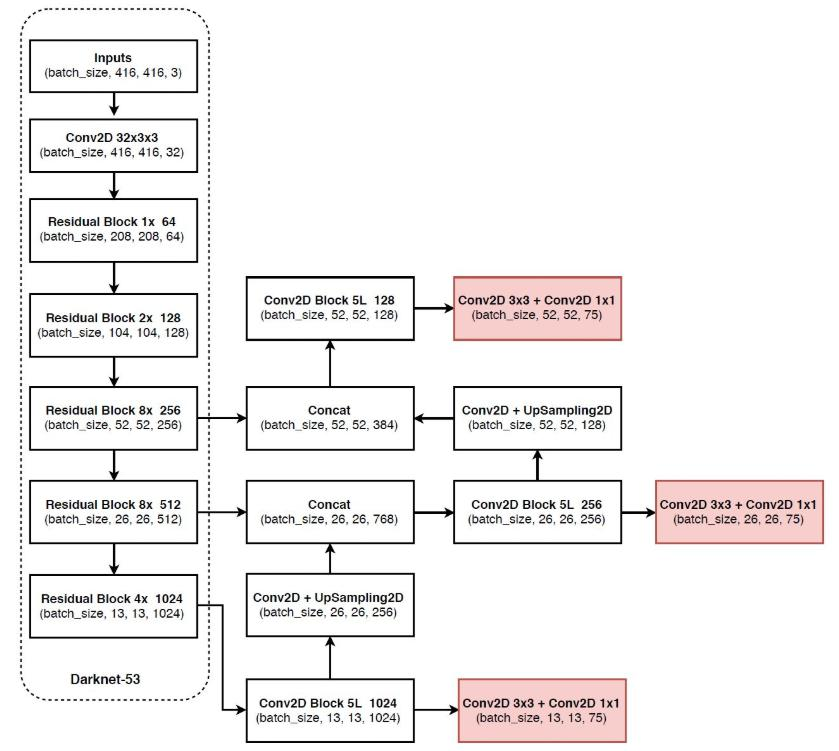
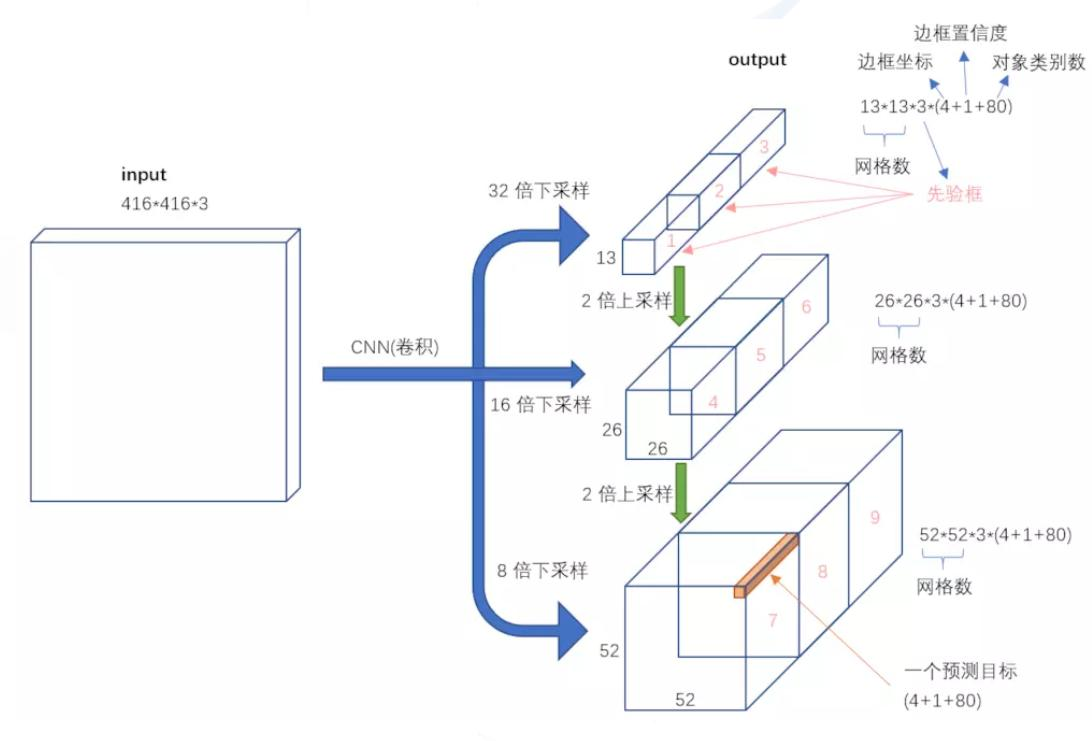
先驗框設計:
13*13特征圖上:(116x90),(156x198),(373x326)26*26特征圖上:(30x61),(62x45),(59x119)
52*52特征圖上:(10x13),(16x30),(33x23)

?
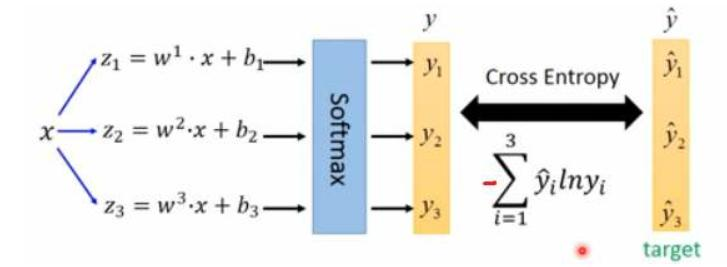
softmax層替代:使用logistic激活函數替代softmax,用于預測物體的多個標簽。
?
6.?YOLO - V4
?
整體介紹:雖作者更換,但核心精髓未變,在單GPU上訓練效果良好,從數據層面和網絡設計層面進行大量改進。
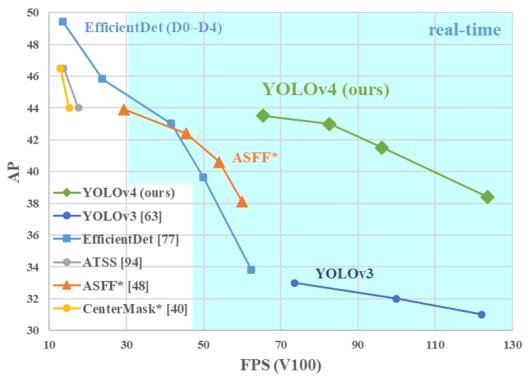
V4貢獻:
親民政策,單GPU就能訓練的非常好,接下來很多小模塊都是這個出發點兩大核心方法,從數據層面和網絡設計層面來進行改善
消融實驗,工作量不輕全部實驗都是單GPU完成
Bag of freebies(BOF)
?
數據增強:包括調整亮度、對比度、色調、隨機縮放、剪切、翻轉、旋轉,Mosaic數據增強(四張圖像拼接成一張訓練)、Random Erase(用隨機值或訓練集平均像素值替換圖像區域)、Hide and Seek(根據概率隨機隱藏一些補丁)等方法。
?
?Mosaic data augmentation
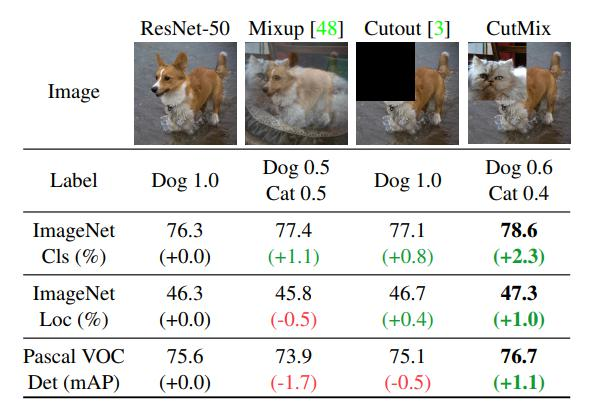

Random Erase:用隨機值或訓練集的平均像素值替換圖像的區域
Hide and Seek:根據概率設置隨機隱藏一些補丁

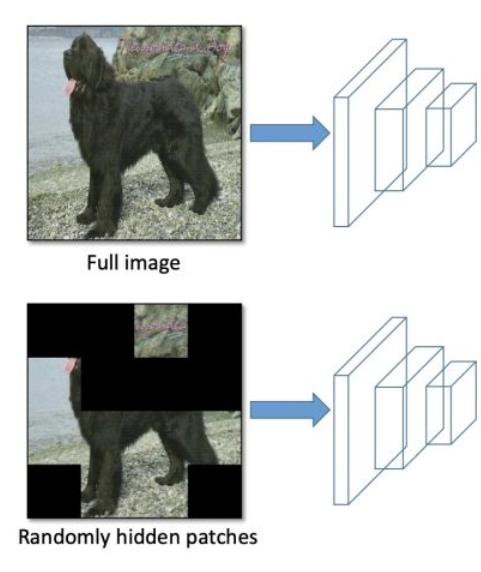
網絡正則化與損失函數:采用Dropout、Dropblock等網絡正則化方法,處理類別不平衡問題,設計合適的損失函數。
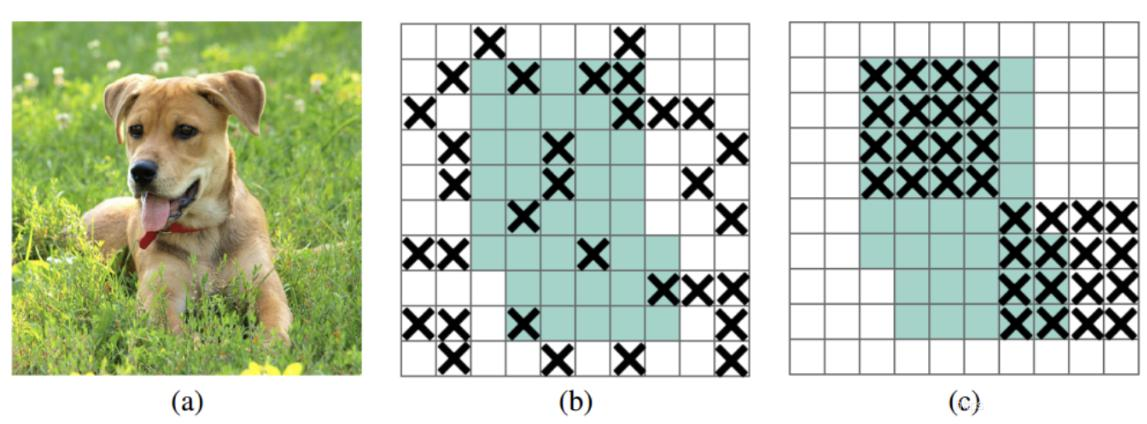
DropBlock
之前的dropout是隨機選擇點(b),現在吃掉一個區域
?
?
?
訓練優化相關方法
?
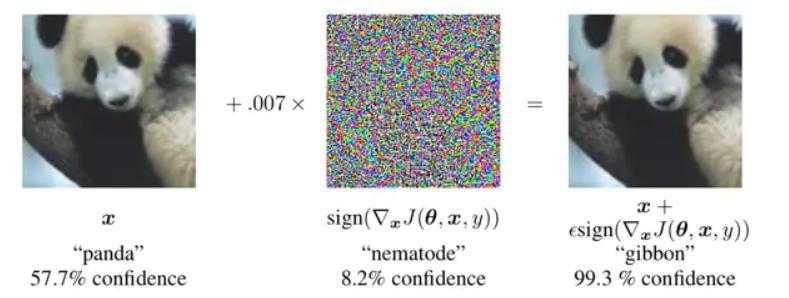
?Self-adversarial-training(SAT)
通過引入噪音點來增加游戲難度
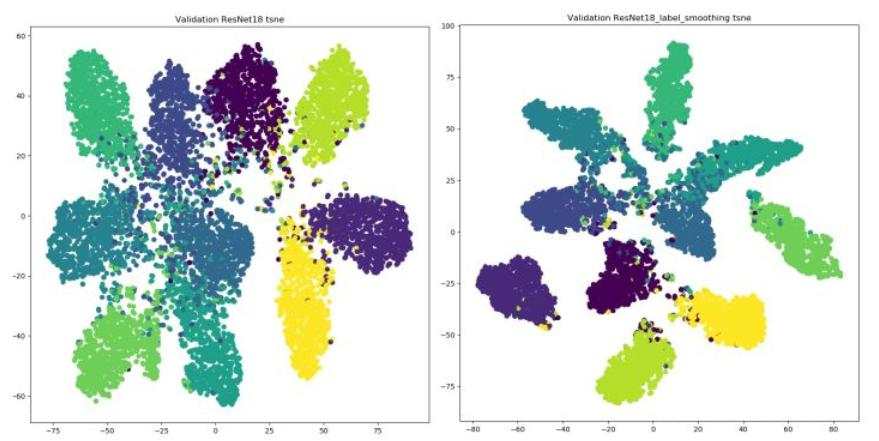
Label Smoothing:
神經網絡最大的缺點:自覺不錯(過擬合),讓它別太自信例如原來標簽為(0,1):![]()
緩解神經網絡過擬合問題,使標簽取值范圍從(0,1)調整為[0.05,0.95],使用后能使簇內更緊密,簇間更分離。
?
IOU相關損失函數:
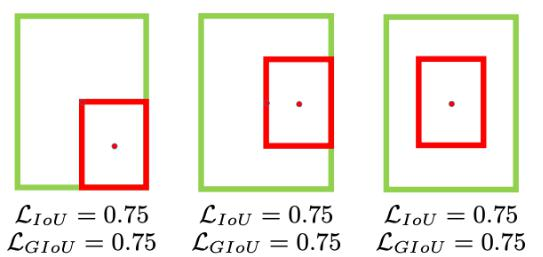
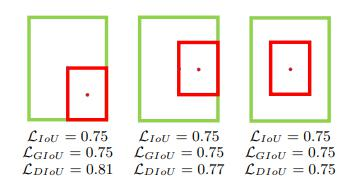
IOU損失(1 - IOU)存在的問題,如無相交時無法梯度計算、相同IOU無法反映實際情況;
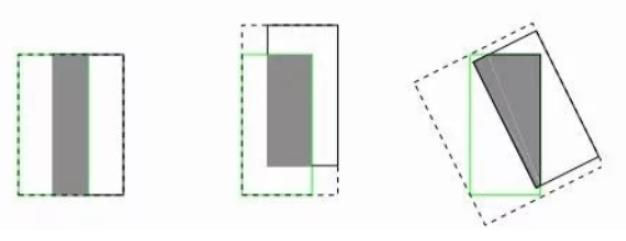
?
GIOU損失(引入最小封閉形狀C)、DIOU損失(直接優化距離)、CIOU損失(考慮重疊面積、中心點距離、長寬比三個幾何因素)。
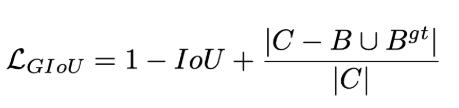
DIOU損失:
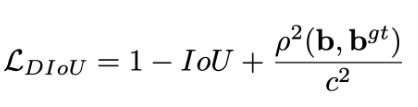
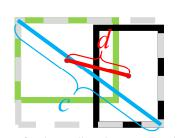
其中分子計算預測框與真實框的中心點歐式距離d 分母是能覆蓋預測框與真實框的最小BOX的對角線長度c 直接優化距離,速度更快,并解決GIOU問題?
CIOU損失:損失函數必須考慮三個幾何因素:重疊面積,中心點距離,長寬比 其中α可以當做權重參數
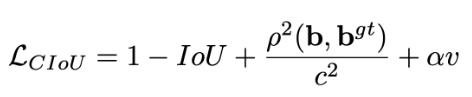
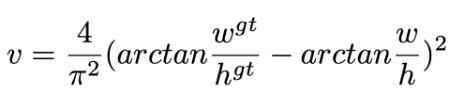
![]()
DIOU - NMS(不僅考慮IoU值,還考慮兩個Box中心點之間的距離)和SOFT - NMS(柔和處理,更改分數而非直接剔除)。
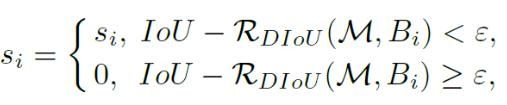
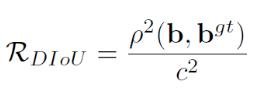
SOFT-NMS
Bag of specials(BOS)
?
網絡改進方法:增加稍許推斷代價但可提高模型精度,包括網絡細節部分的改進,引入注意力機制、特征金字塔等方法。
?
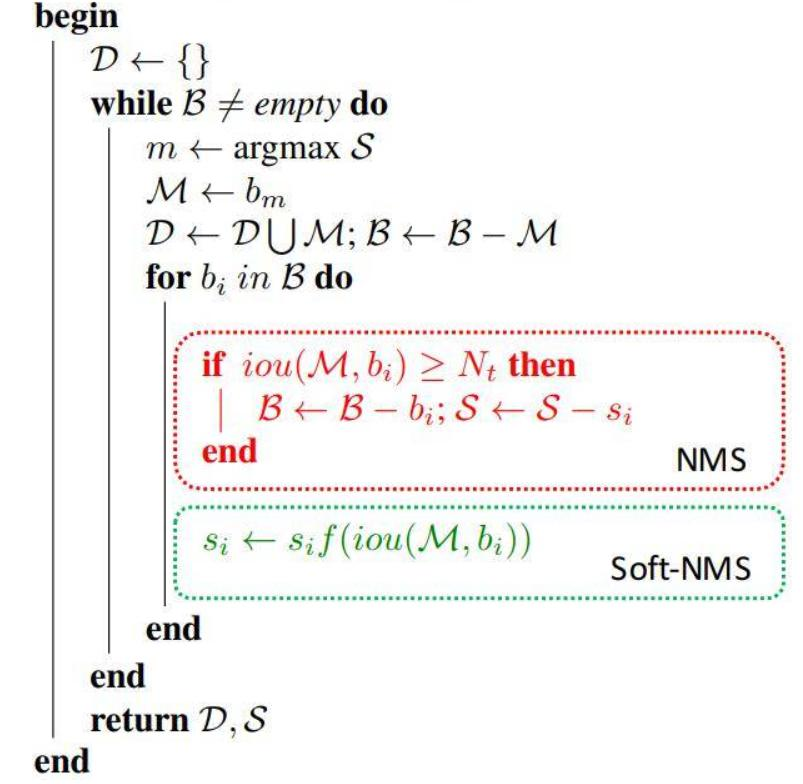
SPPNet(Spatial Pyramid Pooling)(用最大池化滿足最終輸入特征一致)
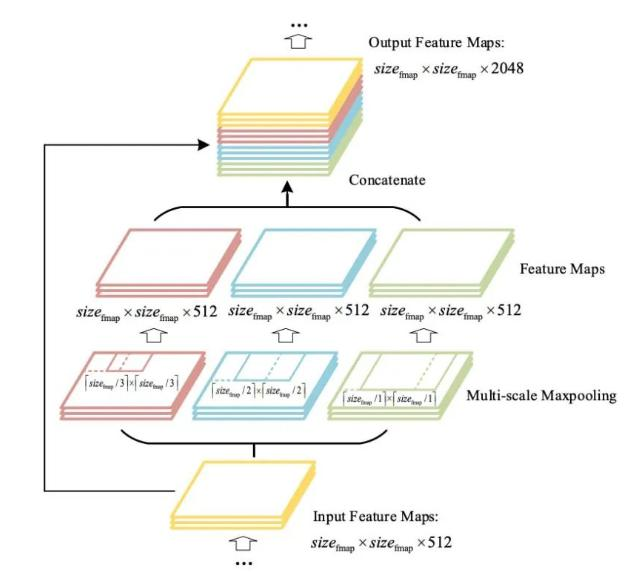
CSPNet(Cross Stage Partial Network)(按特征圖channel維度拆分,一部分正常走網絡,一部分直接concat到輸出)
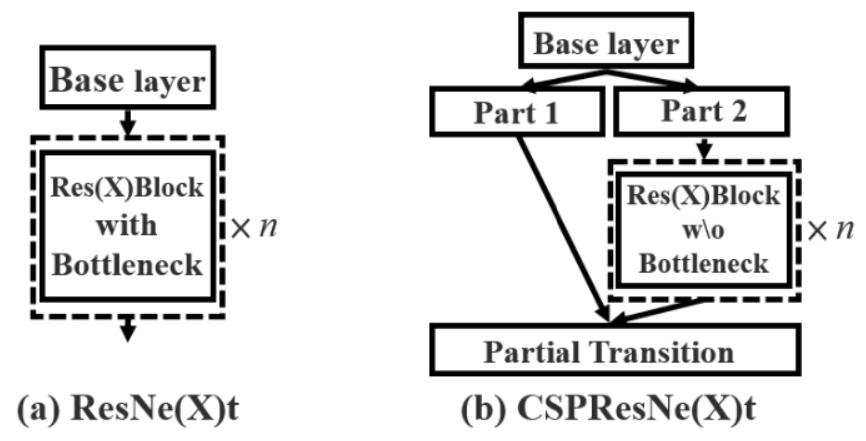
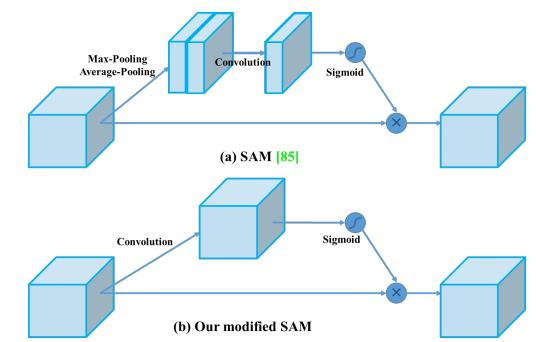
CBAM(引入注意力機制,V4中用的是空間注意力機制SAM)
V4中用的是SAM,也就是空間的注意力機制
不光NLP,語音識別領域在搞attention,CV中也一樣
?
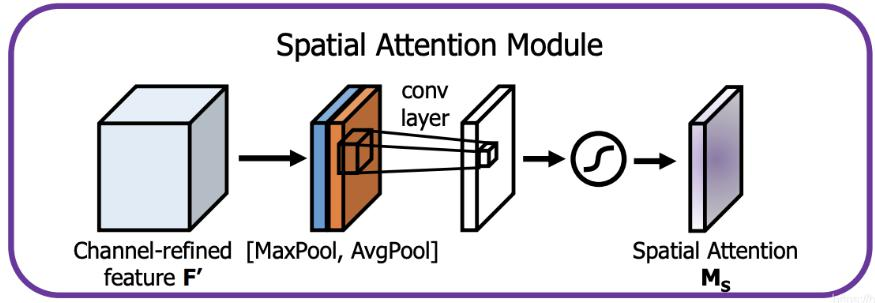
YOLOV4中的Spatial attention module
一句話概述就是更簡單了,速度相對能更快一點
?
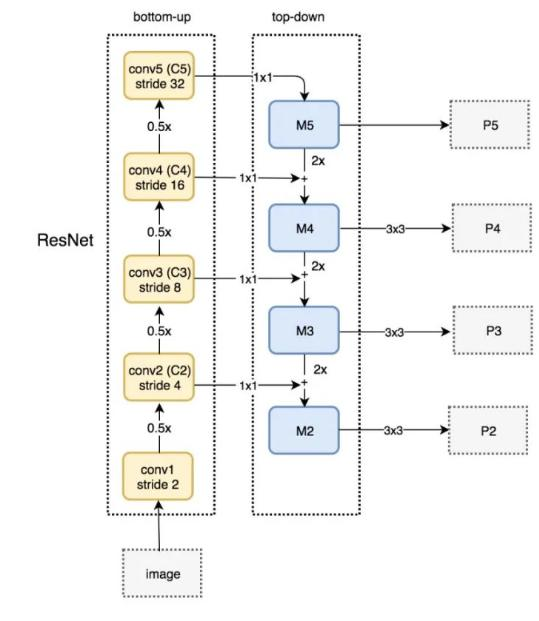
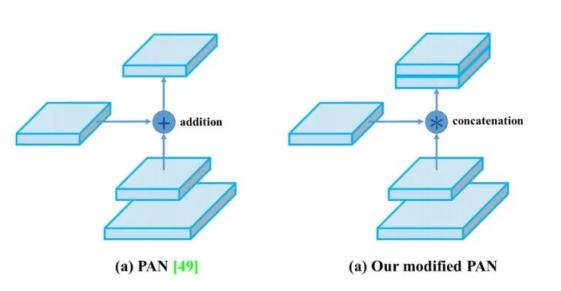
PAN(引入自底向上的路徑,使底層信息更易傳到頂部,且采用拼接而非加法)
先從FPN說起
自頂向下的模式,將高層特征傳下來
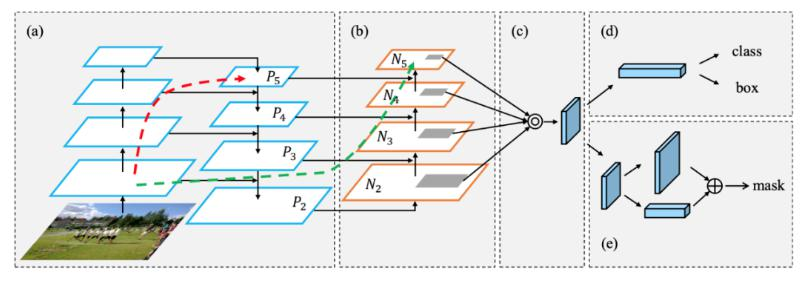
?
PAN(Path Aggregation Network)
引入了自底向上的路徑,使得底層信息更容易傳到頂部
并且還是一個捷徑,紅色的沒準走個100層(Resnet),綠色的幾層就到了
?
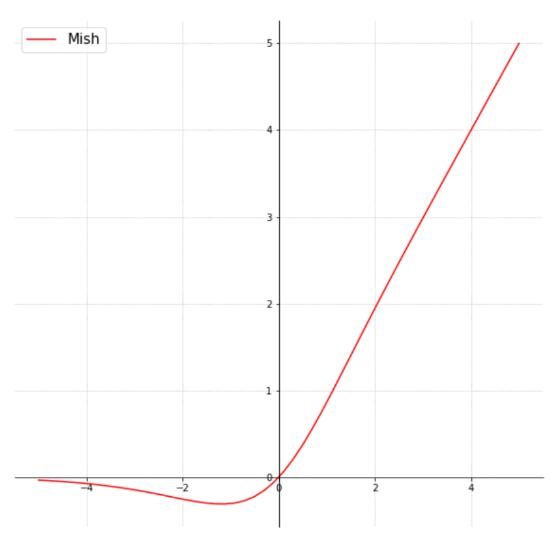
Mish激活函數公式為,計算量增加但效果有提升
?
消除網格敏感性:坐標回歸預測值在0 - 1之間,在grid邊界表示存在困難,通過在激活函數前加系數(大于1)緩解該問題。
?為了緩解這種情況可以在激活函數前加上一個系數(大于1的):
![]()
?
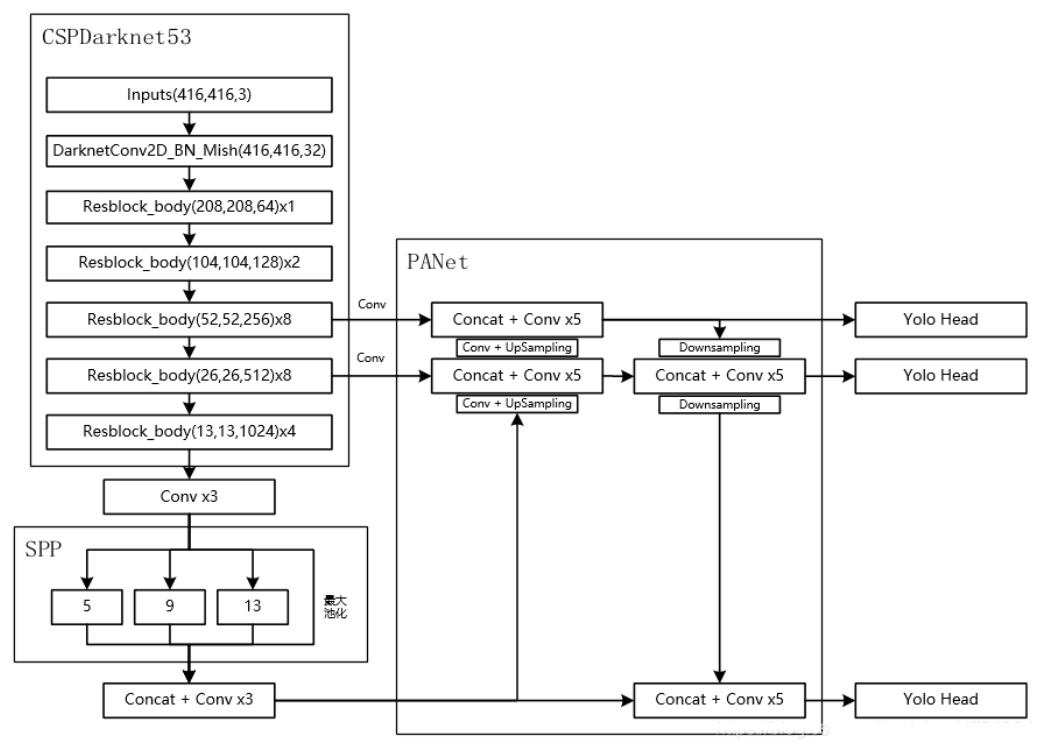
整體網絡架構:采用CSPDarknet53架構,展示了網絡的輸入、各層操作以及最終的輸出等信息。
?
7.?YOLOV5源碼相關
?
?
可視化工具:
1.配置好netron,詳情:https://github.com/lutzroeder/netron
? ?桌面版:https://lutzroeder.github.io/netron/
2.安裝好onnx,pip install onnx即可
3.轉換得到onnx文件,腳本原始代碼中已經給出
4.打開onnx文件進行可視化展示(.pt文件展示效果不如onnx)
Focus模塊:先分塊,后拼接,再卷積,間隔完成分塊任務,使卷積輸入的C變為12,目的是加速,不增加AP。
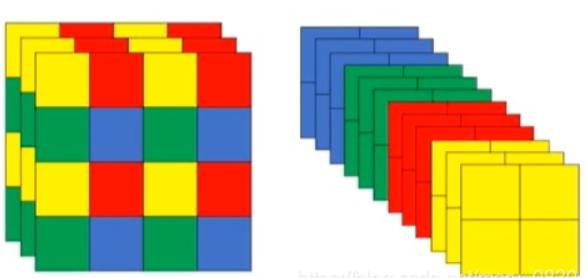
?
BottleneckCSP:注意疊加個數,里面包含resnet模塊,相比V3版本多了CSP,效果有一定提升。
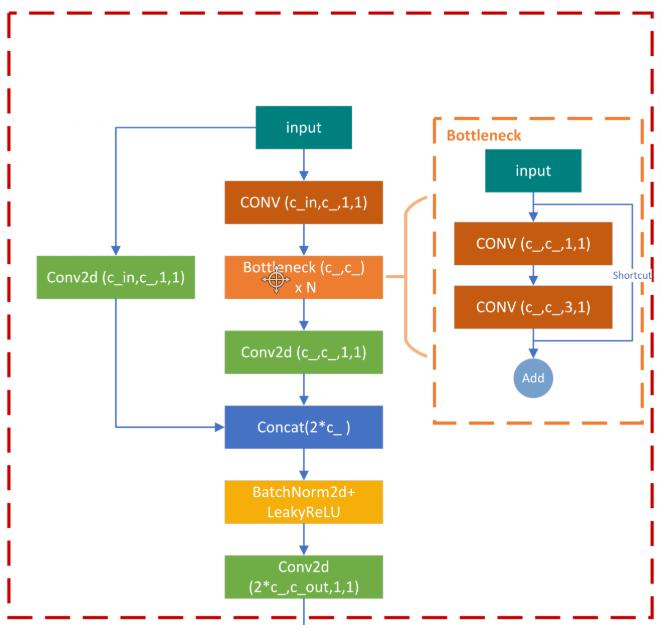
?
PAN流程:PAN流程中各模塊的操作,如Focus、CONV、BottleneckCSP、Concat、Upsample等層的參數和連接關系。
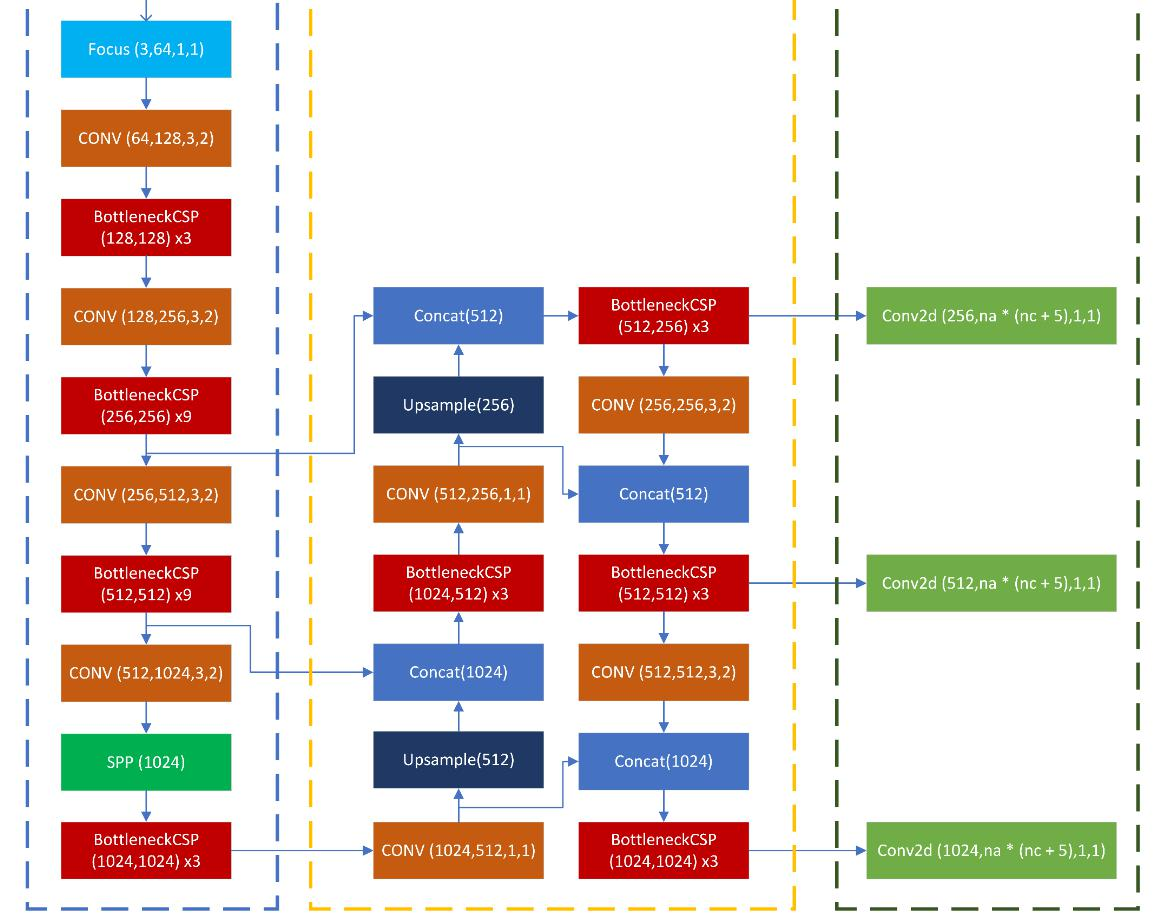
)
)

















