π0.5 論文
通過異構數據協同訓練與分層推理,用中等規模的目標數據(400小時)實現了大規模泛化能力,為現實世界機器人學習提供了新范式。


高層推理(high-level) 根據當前觀測和任務指令預測子任務(如“打開抽屜”)。低層推理(low-level) 基于當前觀測和子任務生成具體動作序列。低級推理動作能夠受益于其他機器人收集的數據;高級推理能從網絡上的語義示例,高級注釋預測中受益。
- 輸入:多攝像頭圖像、語言指令、機器人本體狀態(關節位姿)。
- 輸出:高層語義子任務(文本 token)和底層動作序列(連續向量)。
- 模態交互:圖像通過視覺編碼器嵌入,文本和動作通過獨立編碼器處理,通過雙向注意力機制(不同于 LLM 的因果注意力)交互。
- 動作專家(Action Expert:專用于 flow matching 的小型 Transformer,生成高精度連續動作。
- 注意力掩碼:限制動作 token 與文本/圖像 token 的單向信息流,避免信息泄露。

模型的核心分布為 π θ ( a t : t + H , ? ^ ∣ o t , ? ) \pi_{\theta}(\mathbf{a}_{t:t+H},\hat{\ell}|\mathbf{o}_{t},\ell) πθ?(at:t+H?,?^∣ot?,?) 其中 ? \ell ? 是整體任務提示, ? ^ \hat{\ell} ?^ 是各個子任務的提示。
將聯合分布拆解為高層次和低層次兩個子任務:
π θ ( a t : t + H , ? ^ ∣ o t , ? ) = π θ ( a t : t + H ∣ o t , ? ^ ) π θ ( ? ^ ∣ o t , ? ) \pi_\theta(\mathbf{a}_{t:t+H},\hat{\ell}\left|\mathbf{o}_t,\ell\right)=\pi_\theta(\mathbf{a}_{t:t+H}\left|\mathbf{o}_t,\hat{\ell}\right.)\pi_\theta(\hat{\ell}\left|\mathbf{o}_t,\ell\right) πθ?(at:t+H?,?^∣ot?,?)=πθ?(at:t+H? ?ot?,?^)πθ?(?^∣ot?,?)
動作的 token 采用 π 0 ? f a s t \pi_0-fast π0??fast 的 token,但這種離散化表示不適合實時推理,因為需要昂貴的自回歸解碼推理,故而提出了一個結合 FAST 分詞器和迭代整合流場來預測動作:
min ? θ E D , τ , ω [ H ( x 1 : M , f θ l ( o t , l ) ) ? 文本token交叉熵損失 + α ∥ ω ? a t : t + H ? f θ a ( a t : t + H τ , ω , o t , l ) ∥ 2 ? 流匹配MSE損失 ] \min_{\theta}\mathbb{E}_{D,\tau,\omega}\left[\underbrace{\mathcal{H}(x_{1:M},f_{\theta}^{l}(o_{t},l))}_{\text{文本token交叉熵損失}}+\alpha\underbrace{\|\omega-a_{t:t+H}-f_{\theta}^{a}(a_{t:t+H}^{\tau,\omega},o_{t},l)\|^{2}}_{\text{流匹配MSE損失}}\right] θmin?ED,τ,ω? ?文本token交叉熵損失 H(x1:M?,fθl?(ot?,l))??+α流匹配MSE損失 ∥ω?at:t+H??fθa?(at:t+Hτ,ω?,ot?,l)∥2?? ?
階段一:預訓練(VLM模式)
- 僅使用文本token損失(α=0)
- 將動作視為特殊文本 token(FAST編碼),繼承語言模型強語義能力
- 采用
<control mode> joint/end effector區分末端執行器和關節 - 各數據集動作維度單獨歸一化至 [-1,1](采用1%與99%分位數)
| 數據類型 | 符號 | 數據量 | 關鍵特性 | 作用 |
|---|---|---|---|---|
| 移動機械臂家庭數據 | MM | 400小時 | 100+真實家庭環境,清潔/整理任務(圖7) | 目標場景直接適配 |
| 多環境靜態機械臂數據 | ME | 跨200+家庭 | 輕量化單/雙機械臂,安裝于固定平臺 | 增強物體操作多樣性 |
| 跨本體實驗室數據 | CE | 含OXE數據集 | 桌面任務(疊衣/餐具收納等)+移動/固定基座機器人 | 遷移無關場景技能(如咖啡研磨) |
| 高層子任務標注數據 | HL | 全數據集標注 | 人工標注原子子任務(如"拾取枕頭")+關聯定位框 | 實現分層推理能力 |
| 多模態網絡數據 | WD | 百萬級樣本 | 圖像描述(COCO)、問答(VQAv2)、室內場景物體檢測(擴展標注) | 注入語義先驗知識 |
階段二:微調(混合模式
- 引入動作專家分支,逐步提升α
- 流匹配分支從文本 token 條件生成動作,建立語言-動作關聯
推理流程
- 自回歸解碼:生成語義子任務 ? ^ \hat{\ell} ?^(如“拿起盤子”)
- 條件去噪:基于 ? ^ \hat{\ell} ?^ 執行10步流匹配去噪,輸出連續動作 a t : t + H a_{t:t+H} at:t+H?
實驗結果
Q1: π 0.5 \pi_{0.5} π0.5? 能否有效泛化到全新環境中的復雜多階段任務?
在三個未曾見過的真實環境中,使用兩種類型的機器人,每個機器人被指示執行臥室和廚房的清潔任務。比較了大致對應于每個任務成功完成的步驟百分比。

A!: 能夠在各種家庭任務中持續取得成功。泛化水平超過了以往的 VLA 模型。
Q2: π 0.5 \pi_{0.5} π0.5? 泛化能力隨訓練數據中不同環境的數量如何變化?
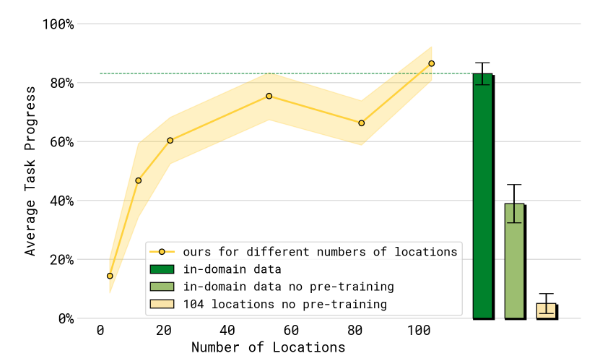
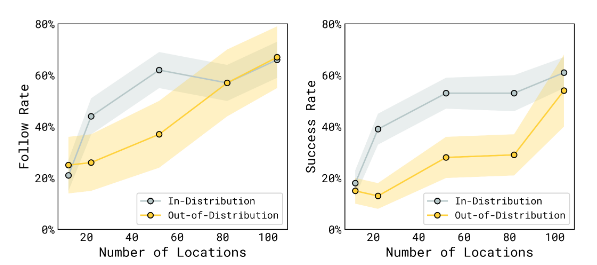
A2:隨著訓練位置的增加,任務之間的平均表現通常會有所提高。隨著訓練數據中地點數量的增加,語言跟隨表現和成功率都有所提高。
Q3: π 0.5 \pi_{0.5} π0.5? 各個共同訓練成分對最終性能的貢獻如何?
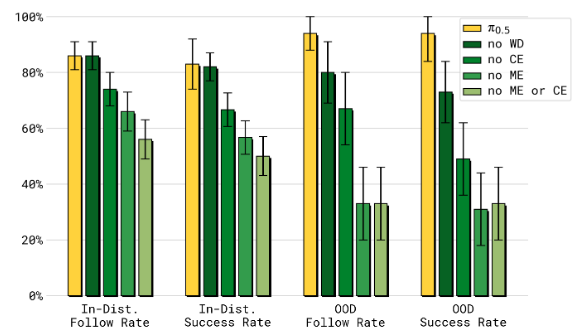
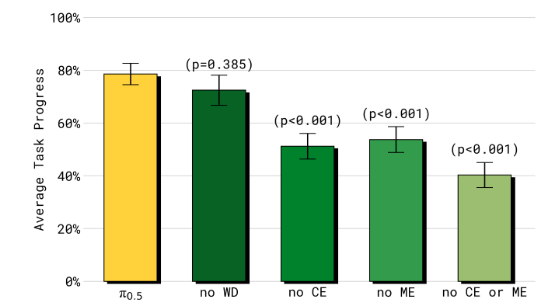
A3: π 0.5 \pi_{0.5} π0.5? 從跨剛體(ME和CE)轉移中獲得了相當大的好處。移除網絡數據(WD)會導致模型在處理異常分布(OOD)對象時表現顯著變差。
Q4: π 0.5 \pi_{0.5} π0.5? 與 π 0 V L A \pi_0 VLA π0?VLA 相比?
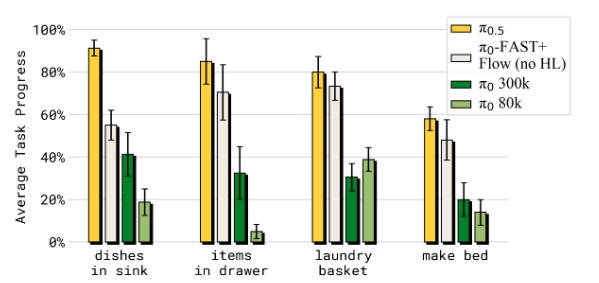
A4: π 0.5 \pi_{0.5} π0.5? 顯著優于 π 0 \pi_0 π0? 以及增強版本 p i 0 ? pi_0- pi0??-FAST+FLOW。 π 0 \pi_0 π0?-FAST+FLOW 是按照混合訓練設置的,但僅用包含機器人動作的數據進行訓練,因此無法執行高層次推理。
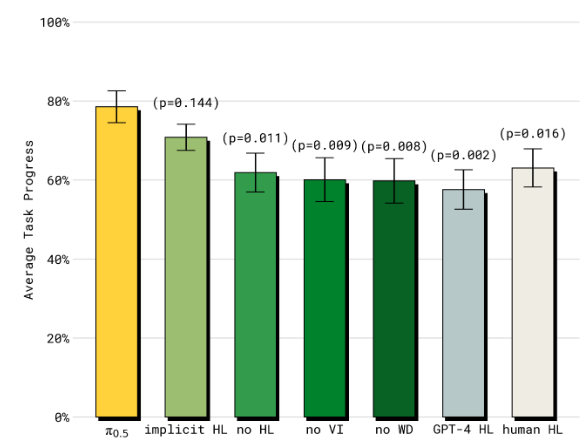
Q5: π 0.5 \pi_{0.5} π0.5? 的高層推理組件有多重要?與單一的低層次推理以及顯式的高層基線相比如何?
不足之處
- π 0.5 \pi_{0.5} π0.5? 雖然展示了廣泛的泛化能力,但在某些環境中仍存在挑戰,如不熟悉的抽屜把手或機器人難以打開的櫥柜。
- 一些行為在部分可觀測性方面存在挑戰,比如:機器人手臂遮擋了應該擦拭的溢出物。
- 在某些情況下,高層子任務推理容易分心,比如:在收拾物品時多次關閉和打開抽屜。
目前僅能處理的是相對簡單的提示。



















