引入
通過前面的文章,我們從S4到Storm,再到Storm結合Kafka成為當時的實時處理最佳實踐:
- S4論文詳解
- S4論文總結
- Storm論文詳解
- Storm論文總結
- Kafka論文詳解
- Kafka論文總結
然而Kafka+Storm的第一代流式數據處理組合,還面臨的三個核心挑戰:
-
數據的正確性,也就是需要能夠保障“正好一次”的數據處理。
-
系統的容錯能力,也就是我們不能因為某一臺服務器的硬件故障,就丟失掉一部分數據。
-
對于時間窗口的正確處理,也就是能夠準確地根據事件時間生成報表,而不是簡單地使用進行處理的服務器的本地時間。并且,還需要能夠考慮到分布式集群中,數據的傳輸可能會有延時的情況出現。
當然這些問題并不是解決不了,我們可以通過在應用層撰寫大量的代碼,來進行數據去重、狀態持久化。但是一個合理的解決方案, 應該是在流式計算框架層面就解決這些問題,而不是把這些問題留給應用開發人員。
圍繞著這三個核心挑戰,在2013年,Google的一篇論文《MillWheel: Fault-Tolerant Stream Processing at Internet Scale》給我們帶來了一套解決方案。這個解決方案,可以算得上是第二代流式數據處理系統。
那么今天,我們就來看看,在2013年這個時間點上,Google的工程師是怎么解決這個問題的。
MillWheel:互聯網規模下的容錯流處理
摘要
MillWheel是一個用于構建低延遲數據處理應用程序的框架,在谷歌被廣泛使用。用戶只需指定有向計算圖以及各個節點的應用代碼,系統便會在框架的容錯保障范圍內,管理持久狀態和連續的記錄流。
本文介紹了MillWheel的編程模型及其實現方式。通過谷歌正在使用的一個連續異常檢測器的案例研究,闡述了MillWheel的諸多特性是如何發揮作用的。MillWheel的編程模型引入了邏輯時間的概念,使得編寫基于時間的聚合操作變得簡單。
MillWheel從設計之初就考慮到了容錯性和可擴展性。在實際應用中,我們發現MillWheel將可擴展性、容錯性以及通用的編程模型獨特結合,能夠解決谷歌內部各種各樣的問題。
1. 引言
流處理系統對于向用戶提供內容以及幫助組織做出更快更好的決策至關重要,尤其是因為它們能夠提供低延遲的結果。用戶希望獲取關于周圍世界的實時新聞。企業同樣對諸如垃圾郵件過濾和入侵檢測等實時情報源所帶來的價值感興趣。類似地,科學家必須從海量的原始數據流中篩選出有價值的結果。
谷歌的流處理系統需要具備容錯性、持久狀態和可擴展性。分布式系統運行在數千臺共享機器上,其中任何一臺都可能隨時發生故障。基于模型的流處理系統,如異常檢測器,依賴于根據數周數據生成的預測,并且隨著新數據的到來,它們的模型必須實時更新。將這些系統的規模擴大幾個數量級,不應導致構建和維護系統的運營成本相應增加。
像MapReduce [11]這樣的分布式系統編程模型,將框架的實現細節隱藏在幕后,使用戶能夠創建表達簡潔的大規模分布式系統。通過讓用戶只專注于應用邏輯,這種編程模型使用戶無需成為分布式系統專家,就能對系統的語義進行推理。
具體而言,用戶能夠將框架層面的正確性和容錯性保障視為公理,極大地限制了錯誤可能出現的范圍。支持多種常見編程語言進一步推動了其應用,因為用戶可以以熟悉的方式利用現有庫的實用性和便利性,而不是局限于特定領域的語言。
MillWheel就是這樣一種專門為流處理、低延遲系統量身定制的編程模型。用戶將應用邏輯編寫為有向計算圖中的各個節點,并可以為其定義任意的、動態的拓撲結構。記錄沿著圖中的邊持續傳遞。MillWheel在框架層面提供容錯能力,拓撲結構中的任何節點或邊隨時可能發生故障,但不會影響結果的正確性。作為這種容錯能力的一部分,系統中的每一條記錄都保證會被傳遞給其消費者。此外,MillWheel為記錄處理提供的API以冪等方式處理每條記錄,從用戶的角度來看,記錄只會被傳遞一次。MillWheel以細粒度檢查點記錄其進展,無需在檢查點之間的長時間內,在外部發送方緩沖待處理的數據。
其他流處理系統并未同時具備這種容錯性、通用性和可擴展性。Spark Streaming [34]和Sonora [32]在高效檢查點方面表現出色,但限制了用戶代碼可用的操作符范圍。S4 [26]沒有提供完全容錯的持久狀態,而Storm [23]用于記錄傳遞的“恰好一次”機制Trident [22],需要嚴格的事務順序才能運行。試圖將MapReduce和Hadoop [4]的批處理模型擴展以提供低延遲系統,會導致靈活性受損,例如Spark Streaming中操作符對彈性分布式數據集(Replicated Distributed Datasets)[33]的特定依賴。流SQL系統[1] [2] [5] [6] [21] [24]為許多流處理問題提供了簡潔的解決方案,但直觀的狀態抽象和復雜的應用邏輯(例如矩陣乘法)使用命令式語言的操作流程來表達,比使用像SQL這樣的聲明式語言更為自然。
我們的貢獻在于為流處理系統設計了一種編程模型,并實現了MillWheel框架。
-
我們設計了一種編程模型,無需分布式系統專業知識,就能創建復雜的流處理系統。
-
我們構建了MillWheel框架的高效實現,證明了它作為一個可擴展且容錯的系統的可行性。
本文其余部分組織如下。第2節概述了MillWheel開發的一個動機示例,以及它所帶來的相應需求。第3節對系統進行了高層次的概述。第4節定義了MillWheel模型的基本抽象,第5節討論了MillWheel公開的API。第6節概述了MillWheel中容錯的實現,第7節涵蓋了一般實現。第8節提供實驗結果以說明MillWheel的性能,第9節討論相關工作。
2. 動機與需求
谷歌的Zeitgeist管道用于跟蹤網絡查詢趨勢。為了展示MillWheel功能集的實用性,我們將研究Zeitgeist系統的需求。這個管道持續接收搜索查詢的輸入,并進行異常檢測,盡快輸出搜索量激增或驟減的查詢。該系統為每個查詢構建一個歷史模型,以便預期的流量變化(例如傍晚時分的“電視節目預告”查詢)不會導致誤報。盡快識別出搜索量激增或驟減的查詢非常重要。例如,Zeitgeist為谷歌的熱門趨勢服務提供支持,該服務依賴最新信息。此管道的基本拓撲結構如圖1所示。
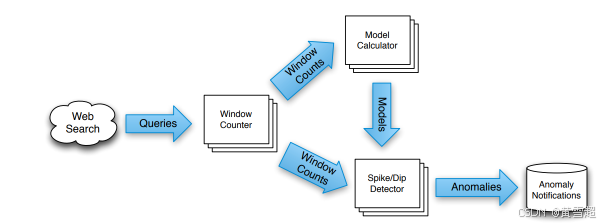
圖 1:輸入數據(搜索查詢)經過一系列 MillWheel 計算,這些計算以分布式進程的形式呈現。該系統的輸出由外部異常通知系統使用。
為了實現Zeitgeist系統,我們的方法是將記錄按一秒的時間間隔進行分桶,然后將每個時間桶的實際流量與模型預測的預期流量進行比較。如果在相當數量的桶中,這些數量持續不同,那么我們就有很大把握認為某個查詢的搜索量在激增或驟減。同時,我們用新接收到的數據更新模型,并存儲起來供將來使用。
-
持久存儲:需要注意的是,此實現既需要短期存儲,也需要長期存儲。搜索量激增可能只持續幾秒鐘,因此依賴于一小段時間窗口內的狀態,而模型數據可能對應數月的持續更新。
-
低水位標記:一些Zeitgeist用戶對檢測流量驟減感興趣,即某個查詢的流量異常低(例如埃及政府關閉互聯網的情況)。在一個接收來自世界各地輸入的分布式系統中,數據到達時間并不嚴格對應其生成時間(在這種情況下是搜索時間),因此能夠區分在t = 1296167641時預期的大量阿拉伯語查詢是在傳輸中延遲了,還是實際上根本沒有出現,這一點很重要。MillWheel通過為每個處理階段(例如窗口計數器、模型計算器)的傳入數據提供低水位標記來解決這個問題,該標記表明截至給定時間戳的所有數據都已收到。低水位標記跟蹤分布式系統中的所有待處理事件。利用低水位標記,我們能夠區分上述兩種情況——如果低水位標記超過時間t,而查詢仍未到達,那么我們就有很大把握認為這些查詢沒有被記錄,而不僅僅是延遲了。這種語義也消除了對輸入嚴格單調性的任何要求——亂序流是常態。
-
防止重復:對于Zeitgeist來說,重復的記錄傳遞可能會導致虛假的搜索量激增。此外,“恰好一次”處理是MillWheel眾多收益處理客戶的要求,他們都可以依賴框架實現的正確性,而無需重新發明自己的去重機制。用戶無需編寫代碼手動回滾狀態更新,或處理各種故障場景以保持正確性。
考慮到以上因素,我們提出谷歌對流處理框架的需求,這些需求在MillWheel中得到了體現:
-
數據一旦發布,就應該盡快提供給消費者(即攝取輸入和提供輸出數據不存在系統內在的障礙)。
-
用戶代碼應該能夠使用持久狀態抽象,并且這些抽象應該集成到系統的整體一致性模型中。
-
系統應該能夠優雅地處理亂序數據。
-
系統應該計算數據時間戳的單調遞增低水位標記。
-
隨著系統擴展到更多機器,延遲應該保持不變。
-
系統應該提供記錄的“恰好一次”傳遞。
3. 系統概述
從高層次來看,MillWheel是一個對輸入數據進行用戶定義轉換以生成輸出數據的圖。我們將這些轉換稱為計算,下面會更詳細地定義它們。這些轉換中的每一個都可以在任意數量的機器上并行化,這樣用戶就無需在細粒度層面擔心負載均衡問題。以圖1所示的Zeitgeist系統為例,我們的輸入是不斷到達的一組搜索查詢,輸出則是搜索量激增或驟減的查詢集合。
抽象地說,MillWheel中的輸入和輸出由(鍵、值、時間戳)三元組表示。鍵是系統中具有語義意義的元數據字段,而值可以是任意字節字符串,對應整個記錄。用戶代碼運行的上下文限定在特定的鍵范圍內,每個計算可以根據其邏輯需求為每個輸入源定義鍵。例如,Zeitgeist中的某些計算可能會選擇搜索詞(如“貓視頻”)作為鍵,以便按每個查詢計算統計信息,而其他計算可能會選擇地理來源作為鍵,以便按每個地區進行聚合。這些三元組中的時間戳可以由MillWheel用戶指定任意值(但通常接近事件發生時的實際時鐘時間),MillWheel將根據這些值計算低水位標記。
如果用戶要按秒統計搜索詞的計數(如圖2所示的Zeitgeist系統中的情況),那么他們會希望為搜索執行的時間分配一個對應的時間戳值。
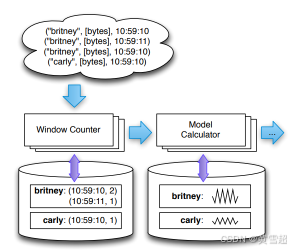
圖2:將網頁搜索聚合到以秒為單位的時間桶中,并使用每個鍵對應的持久狀態來更新模型。每個計算都可以訪問其自身每個鍵對應的狀態,并根據輸入記錄對其進行更新。
3. 系統概述
總體而言,MillWheel是一個對輸入數據進行用戶定義轉換以生成輸出數據的圖。我們將這些轉換稱為“計算”,后續會進一步詳細定義。每個轉換都能在任意數量的機器上并行處理,這樣用戶就無需操心細粒度的負載均衡問題。以圖1所示的Zeitgeist系統為例,輸入是源源不斷的搜索查詢,輸出則是搜索量激增或驟減的查詢集合。
抽象來講,MillWheel中的輸入和輸出由(鍵、值、時間戳)三元組表示。鍵是系統中具有語義意義的元數據字段,值可以是任意字節字符串,對應整條記錄。用戶代碼的運行上下文限定于特定的鍵,每個計算可依據自身邏輯需求,為每個輸入源定義鍵。例如,在Zeitgeist系統中,某些計算可能會選擇搜索詞(如“貓視頻”)作為鍵,以便按每個查詢統計數據;而其他計算可能會選擇地理來源作為鍵,以便按地區進行聚合。這些三元組中的時間戳可由MillWheel用戶指定任意值(通常接近事件發生時的實際時鐘時間),MillWheel會依據這些值計算低水位標記。
倘若用戶要按秒統計搜索詞的數量(如圖2所示的Zeitgeist系統場景),那么就會為搜索執行的時間分配對應的時間戳值。
4. 核心概念
MillWheel呈現了流處理系統的關鍵要素,并提供了清晰的抽象概念。數據通過用戶定義的有向計算圖在系統中傳輸(圖3),每個計算都能獨立地處理和輸出數據。

圖3:MillWheel拓撲結構中單個節點的定義。輸入流和輸出流分別對應圖中的有向邊。
4.1 計算
應用邏輯包含在“計算”中,“計算”封裝了任意的用戶代碼。當接收到輸入數據時,會調用計算代碼,此時會觸發用戶定義的操作,包括與外部系統交互、操作其他MillWheel基本元素或輸出數據。如果要與外部系統交互,用戶需確保其代碼對這些系統的操作具有冪等性。計算代碼在單個鍵的上下文中運行,并且無需知曉不同機器間鍵的分布情況。如圖4所示,處理過程按每個鍵進行序列化,但不同鍵之間可以并行處理。
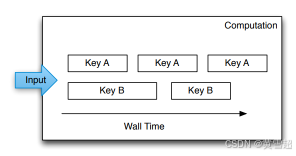
圖4:基于每個鍵的處理隨時間序列化,因此對于給定的鍵,一次只能處理一條記錄。多個鍵的處理可以并行運行。
4.2 鍵
在MillWheel中,鍵是用于不同記錄間聚合和比較的主要抽象概念。對于系統中的每條記錄,使用者會指定一個鍵提取函數,為該記錄分配一個鍵。計算代碼在特定鍵的上下文中運行,并且只能訪問該特定鍵對應的狀態。例如,在Zeitgeist系統中,對于查詢記錄,選擇查詢文本本身作為鍵是個不錯的選擇,因為我們需要按每個查詢來聚合計數并計算模型。又如,垃圾郵件檢測器可能會選擇cookie指紋作為鍵,以阻止惡意行為。圖5展示了不同的使用者從同一輸入流中提取不同的鍵。
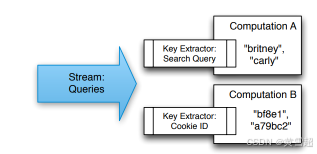
圖5:多個計算可以從同一流中提取不同的鍵。鍵提取器由流的消費者指定。
4.3 流
流是MillWheel中不同計算之間的數據傳輸機制。一個計算可以訂閱零個或多個輸入流,并發布一個或多個輸出流,系統保證數據會沿這些通道傳輸。每個使用者針對每個流指定鍵提取函數,這樣多個使用者就可以訂閱同一流,并以不同方式聚合其數據。流通過名稱唯一標識,沒有其他限定條件——任何計算都可以訂閱任何流,也可以向任何流生成記錄(輸出)。
4.4 持久狀態
在MillWheel中,最基本形式的持久狀態是一個不透明的字節字符串,按每個鍵進行管理。用戶提供序列化和反序列化例程(例如將復雜數據結構轉換為網絡傳輸格式或從網絡傳輸格式轉換回復雜數據結構),對此有多種便捷機制(如Protocol Buffers [13])可用。持久狀態由一個復制的、高可用的數據存儲(如Bigtable [7] 或Spanner [9])支持,以一種對終端用戶完全透明的方式確保數據完整性。狀態的常見用途包括在記錄窗口上聚合的計數器以及用于連接的緩沖數據。
4.5 低水位標記
一個計算的低水位標記為即將到達該計算的記錄的時間戳設定了界限。
定義:我們基于管道的數據流遞歸定義低水位標記。給定一個計算A,設A的最早工作時間是與A中最早未完成(在途、存儲或待交付)記錄對應的時間戳。基于此,我們將A的低水位標記定義為: min(A的最早工作時間,C的低水位標記:C向A輸出)
如果沒有輸入流,低水位標記和最早工作時間的值相等。
低水位標記值由注入器設定,注入器將外部系統的數據發送到MillWheel。對外部系統中待處理工作的測量通常是一種估計,因此在實際中,計算應該預期會從這類系統收到少量遲到的記錄——即落后于低水位標記的記錄。Zeitgeist系統通過丟棄此類數據來處理這個問題,同時記錄丟棄的數據量(根據經驗,大約為記錄總數的0.001%)。其他管道如果收到遲到的記錄,則會追溯修正其聚合結果。盡管上述定義中未體現,但系統保證即使面對遲到的數據,計算的低水位標記也是單調遞增的。
通過等待一個計算的低水位標記超過某個值,用戶可以確定截至該時間他們擁有完整的數據情況,正如Zeitgeist系統檢測流量驟減的示例所示。在為新記錄或聚合記錄分配時間戳時,用戶需選擇不小于任何源記錄時間戳的值。MillWheel框架報告的低水位標記衡量系統中已知的工作,如圖6所示。
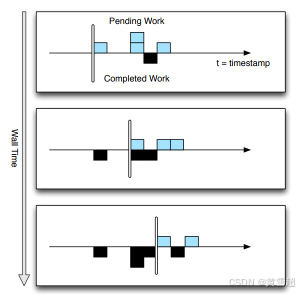
圖6:隨著記錄在系統中流轉,低水位標記不斷推進。在每個時間點的展示中,待處理記錄顯示在時間戳軸上方,已完成記錄顯示在下方。新記錄在后續時間點以待處理任務的形式出現,其時間戳值在水位標記之前。數據不一定按順序處理,低水位標記反映了系統中所有的待處理任務。
4.6 定時器
定時器是基于每個鍵的編程鉤子,在特定的實際時間或低水位標記值觸發。定時器在計算的上下文中創建并運行,因此可以運行任意代碼。使用實際時間還是低水位標記值取決于應用場景——一個希望按小時發送電子郵件(整點發送,無論數據是否延遲)的啟發式監控系統可能會使用實際時間定時器,而執行窗口聚合的分析系統可能會使用低水位標記定時器。一旦設定,定時器保證按時間戳遞增的順序觸發。它們被記錄在持久狀態中,并且可以在進程重啟和機器故障后繼續存在。當定時器觸發時,它會運行指定的用戶函數,并且與輸入記錄一樣具有“恰好一次”的保證。Zeitgeist系統中檢測流量驟減的一個簡單實現可以為給定時間桶的結束時間設置一個低水位標記定時器,如果觀察到的流量遠低于模型預測,則報告流量驟減。
定時器的使用是可選的——不需要基于時間的屏障語義的應用程序可以跳過它們。例如,Zeitgeist系統可以在不使用定時器的情況下檢測搜索量激增的查詢,因為即使沒有完整的數據,搜索量激增也可能很明顯。如果觀察到的流量已經超過模型預測,延遲的數據只會增加總數并增大激增的幅度。
5. API
在本節中,我們將概述與第4節中抽象概念相關的API。用戶實現Computation類的自定義子類,如圖7所示,該子類提供了訪問所有MillWheel抽象(狀態、定時器和輸出)的方法。一旦用戶提供了此代碼,框架便會自動運行它。按鍵序列化在框架級別處理,用戶無需構建任何按鍵鎖定語義。

圖7:MillWheel API包含一個父類Computation,通過它可以訪問基于每個鍵的定時器、狀態以及輸出操作。用戶通過重寫ProcessRecord和ProcessTimer方法來實現應用邏輯。
5.1 計算API
用戶代碼的兩個主要入口點由ProcessRecord和ProcessTimer鉤子提供,如圖8所示,它們分別在接收到記錄和定時器到期時觸發。這些共同構成了一個計算的應用邏輯。
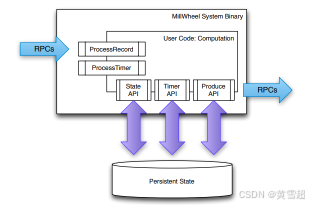
圖8:MillWheel系統會響應傳入的遠程過程調用(RPC)來調用用戶定義的處理鉤子。用戶代碼通過框架應用程序編程接口(API)訪問狀態、定時器和輸出。框架負責執行所有實際的RPC操作和狀態修改。
在這些鉤子的執行過程中,MillWheel提供系統函數來獲取和操作按鍵狀態、生成額外記錄以及設置定時器。圖9展示了這些機制之間的交互。它以我們的Zeitgeist系統為例,展示了在檢測查詢流中的流量驟減時持久狀態和定時器的使用。再次注意,這里沒有故障恢復邏輯,因為這一切都由框架自動處理。
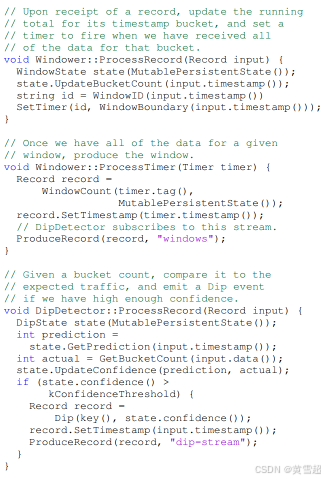
圖9:基于低水位標記定時器,利用現有模型計算窗口計數和流量驟減的計算所對應的ProcessRecord和ProcessTimer的定義。 ?
5.2 注入器和低水位標記API
在系統層,每個計算為其所有待處理工作(進行中的和排隊交付的)計算一個低水位標記值。持久狀態也可以分配一個時間戳值(例如聚合窗口的后沿)。系統會自動匯總這些值,以便以透明的方式為定時器提供API語義——用戶在計算代碼中很少直接與低水位標記交互,而是通過為記錄分配時間戳來間接操作它們。
注入器:注入器將外部數據引入MillWheel。由于注入器為管道的其余部分設定低水位標記值,它們能夠發布一個注入器低水位標記,該標記會傳播到其輸出流中的任何訂閱者,反映它們沿這些流的潛在交付情況。例如,如果一個注入器正在攝取日志文件,它可以發布一個與未完成文件中最小文件創建時間相對應的低水位標記值,如圖10所示。
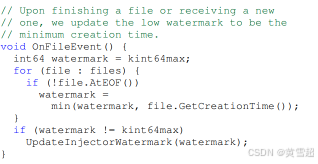
圖10:一個簡單的文件注入器報告的低水位標記值,與最舊的未完成文件相對應。
一個注入器可以分布在多個進程中,這些進程的聚合低水位標記將用作注入器低水位標記。用戶可以指定預期的注入器進程集,使此指標能夠抵御進程故障和網絡中斷。在實際中,谷歌針對常見輸入類型(日志文件、發布/訂閱服務源等)有相應的庫實現,普通用戶無需編寫自己的注入器。
如果一個注入器違反低水位標記語義并發送了落后于低水位標記的遲到記錄,用戶的應用代碼可以選擇丟棄該記錄或將其合并到現有聚合的更新中。
6. 容錯機制
6.1 交付保證
MillWheel編程模型在概念上的簡潔性,很大程度上依賴于它能夠將非冪等的用戶代碼當作冪等代碼來運行。通過從計算編寫者那里移除這一要求,我們減輕了他們顯著的實現負擔。
6.1.1 恰好一次交付
當一個計算接收到輸入記錄時,MillWheel框架會執行以下步驟:
-
將該記錄與之前交付的去重數據進行比對,重復記錄將被丟棄。
-
針對輸入記錄運行用戶代碼,這可能會導致對定時器、狀態和輸出的待處理更改。
-
將待處理更改提交到后端存儲。
-
向發送方發送確認(ACK)。
-
發送待處理的下游輸出。
作為一種優化,上述操作可能會合并為對多條記錄的單個檢查點。MillWheel中的交付會一直重試,直到收到確認,以滿足我們“至少一次”的要求,這是實現“恰好一次”交付的先決條件。我們進行重試是考慮到接收方可能出現網絡問題和機器故障。然而,這就帶來了一種情況,即接收方可能在有機會確認輸入記錄之前崩潰,即使它已經持久化了與該記錄成功處理相對應的狀態。在這種情況下,當發送方重試交付時,我們必須防止重復處理。
系統在生成記錄時為所有記錄分配唯一ID。我們通過在與狀態修改相同的原子寫入中包含該記錄的唯一ID來識別重復記錄。如果之后重試相同的記錄,我們可以將其與記錄日志中的ID進行比較,并丟棄重復記錄并發送確認(以免它無限期重試)。由于我們不一定能將所有重復數據存儲在內存中,我們維護一個已知記錄指紋的布隆過濾器,為我們肯定從未見過的記錄提供快速路徑。如果過濾器判斷失誤,我們必須讀取后端存儲以確定記錄是否重復。在MillWheel能夠保證所有內部發送方都完成重試之后,過去交付的記錄ID將被垃圾回收。對于經常發送遲到數據的注入器,我們將此垃圾回收延遲相應的松弛值(通常為幾個小時)。不過,“恰好一次”的數據通常可以在生成后的幾分鐘內清理完畢。
6.1.2 強輸出
由于MillWheel處理的輸入不一定是有序或確定的,我們在交付之前將生成的記錄與狀態修改在相同的原子寫入中進行檢查點操作。我們將這種在記錄生成之前進行檢查點操作的模式稱為“強輸出”。
以一個按實際時間聚合并向下游發送計數的計算為例。如果沒有檢查點,該計算有可能向下游生成一個窗口計數,但在保存其狀態之前崩潰。一旦該計算重新啟動,它可能在生成相同的聚合之前接收到另一條記錄(并將其添加到計數中),從而創建一個與前一個記錄在逐位上不同但對應相同邏輯窗口的記錄!為了正確處理這種情況,下游消費者需要復雜的沖突解決邏輯。然而,使用MillWheel,簡單的解決方案就能奏效,因為系統保證將用戶的應用邏輯變成了冪等操作。
我們使用諸如Bigtable [7] 這樣的存儲系統,它有效地實現了盲目寫入(與讀取 - 修改 - 寫入操作相反),使得檢查點模仿日志的行為。當一個進程重新啟動時,檢查點被掃描到內存中并重新播放。一旦這些輸出成功,檢查點數據將被刪除。
6.1.3 弱輸出和冪等性
強輸出和恰好一次交付相結合,使得許多計算在系統級重試方面具有冪等性。然而,一些計算本身可能已經具有冪等性,無論是否存在這些保證(這些保證伴隨著資源和延遲成本)。根據應用程序的語義需求,用戶可以自行決定禁用強輸出和/或恰好一次交付。在系統層面,禁用恰好一次交付可以簡單地通過跳過去重步驟來實現,但禁用強輸出需要更多地關注性能。
對于弱輸出,我們不是在交付之前對記錄輸出進行檢查點操作,而是在持久化狀態之前樂觀地向下游廣播交付。根據經驗,這引入了一個新問題,即管道連續階段的完成時間現在嚴格耦合,因為它們等待下游對記錄的確認。再加上機器故障的可能性,隨著管道深度的增加,這會極大地增加掉隊輸出的端到端延遲。例如,如果我們(相當悲觀地)假設任何一臺機器在給定分鐘內有1%的故障概率,那么我們等待至少一次故障的概率會隨著管道深度的增加而急劇增加——對于深度為5的管道,給定的輸出每分鐘可能有近5%的故障概率!我們通過對一小部分掉隊的待處理輸出進行檢查點操作來緩解這個問題,允許這些階段向它們的發送方發送確認。通過以這種方式選擇性地進行檢查點操作,我們既可以提高端到端延遲,又可以降低總體資源消耗。
在圖11中,我們展示了這種檢查點機制的實際運行情況。計算A向計算B生成輸出,計算B立即向計算C生成輸出。然而,計算C確認速度較慢,因此計算B在1秒延遲后對輸出進行檢查點操作。這樣,計算B可以向計算A確認交付,使A能夠釋放與該輸出相關的任何資源。即使計算B隨后重新啟動,它也能夠從檢查點恢復記錄并重新嘗試向計算C交付,而不會丟失數據。
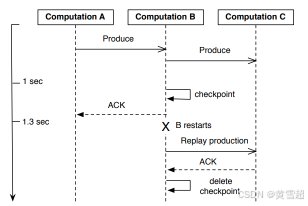
圖11:弱輸出檢查點機制通過為計算B保存檢查點,防止了掉隊的輸出在發送方(計算A)占用過多資源。
上述放寬條件適用于具有冪等計算的管道,因為重試不會影響正確性,并且下游輸出也對重試不敏感。無狀態過濾器就是一個冪等計算的實際例子,沿著輸入流的重復交付不會改變結果。
6.2 狀態操作
在實現MillWheel中用于操作用戶狀態的機制時,我們討論了持久化到后端存儲的“硬”狀態以及包括任何內存緩存或聚合的“軟”狀態。我們必須滿足以下用戶可見的保證:
-
系統不會丟失數據。
-
狀態更新必須遵循“恰好一次”語義。在任何給定時間,整個系統中的所有持久化數據都必須保持一致。
-
低水位標記必須反映系統中的所有待處理狀態。
-
對于給定的鍵,定時器必須按順序觸發。
為避免持久化狀態中的不一致(例如定時器、用戶狀態和輸出檢查點之間),我們將所有按鍵更新包裝在單個原子操作中。這使得系統能夠抵御進程故障和其他可能在任何給定時間中斷進程的不可預測事件。如前所述,“恰好一次”數據也在同一操作中更新,將其添加到按鍵一致性范圍內。
由于工作可能在機器之間轉移(由于負載均衡、故障或其他原因),我們數據一致性的一個主要威脅是可能存在僵尸寫入者和網絡殘留,它們會向后端存儲發出過時的寫入。為解決這一可能性,我們為每次寫入附加一個序列器令牌,后端存儲的中介在允許寫入提交之前會檢查其有效性。新的工作進程在開始工作之前會使任何現有的序列器無效,這樣此后殘留的寫入就無法成功。序列器的作用類似于Centrifuge [3] 系統中的租約執行機制。因此,我們可以保證,對于給定的鍵,在特定時間點只有一個工作進程可以寫入該鍵。
這種單寫入者保證對于維護軟狀態也至關重要,并且無法通過依賴事務來保證。以掛起定時器的緩存為例:如果另一個進程的殘留寫入在緩存構建后可以改變持久化的定時器狀態,那么緩存就會不一致。圖12展示了這種情況,僵尸進程(B)響應來自A的輸出發出一個在網絡中延遲的事務。在事務開始之前,B的后繼進程B - prime對掛起的定時器進行初始掃描。掃描完成后,應用事務并向A發送確認,導致B - prime的定時器狀態不完整。丟失的定時器可能會無限期地孤立,任意延遲其任何輸出操作。顯然,這對于對延遲敏感的系統是不可接受的。
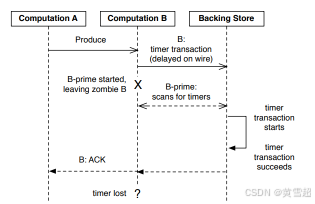
圖12:事務無法防止軟狀態中的不一致情況。孤立的事務可能在只讀掃描完成后提交,從而在MillWheel的定時器系統中導致狀態不一致。
此外,對于已檢查點的輸出也可能出現同樣的情況,系統可能會因未對后端存儲進行初始掃描而不知道該輸出。在發現該輸出之前,低水位標記中不會考慮它,在此期間,我們可能會向消費者報告錯誤的低水位標記值。此外,由于我們的低水位標記是單調遞增的,我們無法糾正錯誤增加的值。通過違反我們的低水位標記保證,可能會出現各種正確性違規情況,包括定時器過早觸發和窗口輸出不完整。
為了快速從意外的進程故障中恢復,MillWheel中的每個計算工作進程都可以以任意細粒度檢查點其狀態(在實際中,根據輸入量,通常為亞秒級或每條記錄的粒度)。我們使用始終一致的軟狀態,使得我們能夠將必須掃描這些檢查點的情況最小化到特定情況——機器故障或負載均衡事件。當我們確實執行掃描時,這些掃描通常可以是異步的,允許計算在掃描進行時繼續處理輸入記錄。
7. 系統實現
7.1 架構
MillWheel部署在一組動態的主機服務器上作為分布式系統運行。管道中的每個計算在一臺或多臺機器上運行,流通過RPC(遠程過程調用)進行交付。在每臺機器上,MillWheel系統整理傳入的工作并管理進程級元數據,必要時委托給適當的用戶計算。
7. 系統實現
7.1 架構
MillWheel以分布式系統的形式在一組動態的主機服務器上運行。管道中的每個計算在一臺或多臺機器上執行,流數據通過遠程過程調用(RPC)進行傳輸。在每臺機器上,MillWheel系統會整理傳入的任務,并管理進程級別的元數據,必要時將任務委托給相應的用戶計算程序。
負載分配與均衡由一個復制的主節點負責,它將每個計算劃分為一組按字典序排列的鍵區間(這些區間共同覆蓋所有可能的鍵),并將這些區間分配給一組機器。當檢測到CPU負載增加或內存壓力增大(由標準的進程監視器報告)時,主節點可以移動、拆分或合并這些區間。每個區間都會被分配一個唯一的序列器,每當該區間被移動、拆分或合并時,序列器就會失效。第6.2節討論了這個序列器的重要性。
對于持久狀態,MillWheel使用類似Bigtable [7] 或Spanner [9] 這樣的數據庫,它們支持原子性的單行更新。給定鍵的定時器、待處理的輸出以及持久狀態都存儲在數據存儲的同一行中。
每當一個鍵區間被分配給新的所有者時,MillWheel通過從這個后端存儲中掃描元數據,能夠有效地從機器故障中恢復。這個初始掃描會填充內存中的數據結構,比如待處理定時器的堆和已檢查點輸出的隊列,在區間分配的有效期內,這些內存結構會被認為與后端存儲保持一致。為了支持這一假設,我們實施了第6.2節中詳細描述的單寫入者語義(每個計算工作進程)。
7.2 低水位標記
為確保數據一致性,低水位標記必須作為一個全局可用且準確的子系統來實現。
我們將其實現為一個中央機構(類似于OOP [19]),該機構跟蹤系統中的所有低水位標記值,并將它們記錄到持久狀態中,以防止在進程故障時報告錯誤的值。
當向中央機構報告時,每個進程會聚合其所有已分配任務的時間戳信息。這包括任何已檢查點或待處理的輸出,以及任何待處理的定時器或持久化狀態。每個進程能夠高效地完成此操作,這得益于我們內存數據結構的一致性,從而無需對后端數據存儲執行任何昂貴的查詢。由于進程是根據鍵區間分配任務的,低水位標記更新也會按鍵區間進行分組,并發送到中央機構。
為了準確計算系統的低水位標記,這個中央機構必須能夠訪問系統中所有待處理和已持久化任務的低水位標記信息。在聚合每個進程的更新時,它通過為每個計算構建低水位標記值的區間映射,來跟蹤其關于每個計算的信息完整性。如果任何區間缺失,那么在該缺失區間報告新值之前,低水位標記將對應于該缺失區間的最后已知值。然后,中央機構會廣播系統中所有計算的低水位標記值。
感興趣的消費者計算會訂閱其每個發送者計算的低水位標記值,并將其輸入的低水位標記計算為這些值中的最小值。
之所以由工作進程計算這些最小值,而不是由中央機構計算,是出于一致性的考慮:中央機構的低水位標記值應始終至少與工作進程的一樣保守。因此,通過讓工作進程計算其各自輸入的最小值,中央機構的低水位標記永遠不會領先于工作進程的,從而保持了這一特性。
為了在中央機構維護一致性,我們為所有低水位標記更新附加序列器。與我們對鍵區間狀態進行本地更新的單寫入者方案類似,這些序列器確保只有給定鍵區間的最新所有者才能更新其低水位標記值。為了實現可擴展性,中央機構可以分布在多臺機器上,每個工作節點上運行一個或多個計算。根據經驗,這種方式可以擴展到500,000個鍵區間,且性能不會下降。
鑒于系統中工作的全局摘要,我們可以選擇去除異常值,并為那些更關注速度而非準確性的管道提供啟發式的低水位標記值。例如,我們可以計算一個99%低水位標記,它對應于系統中99%記錄時間戳的進度。只對近似結果感興趣的窗口消費者可以使用這些低水位標記值,以較低的延遲運行,因為無需等待掉隊的數據。
總之,我們對低水位標記的實現并不要求系統中的流具有任何嚴格的時間順序。低水位標記反映了在途和已持久化的狀態。通過為低水位標記值建立一個全局真實源,我們防止了諸如低水位標記后退之類的邏輯不一致情況。
8. 評估
為了說明MillWheel的性能,我們提供針對流處理系統關鍵指標的實驗結果。
8.1 輸出延遲
延遲是衡量流處理系統性能的關鍵指標。MillWheel框架支持低延遲的處理結果,并且隨著分布式系統擴展到更多機器,它能保持較低的延遲。為了展示MillWheel的性能,我們使用一個簡單的單階段MillWheel管道來測量記錄交付延遲,該管道對數字進行分桶和排序。這類似于在具有不同鍵的連續計算之間發生的多對多洗牌操作,因此是MillWheel中記錄交付的一種最壞情況。圖13顯示了在200個CPU上運行時記錄的延遲分布。記錄的中位延遲為3.6毫秒,95% 百分位數延遲為30毫秒,這輕松滿足了谷歌許多流處理系統的要求(即使是95% 百分位數也在人類反應時間之內)。
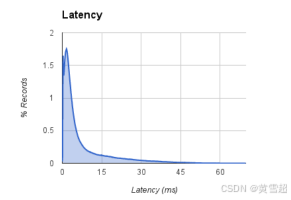
圖13:兩個不同鍵階段之間單階段記錄延遲的直方圖。
此測試是在禁用強輸出和恰好一次交付功能的情況下進行的。當啟用這兩個功能時,中位延遲躍升至33.7毫秒,95% 百分位數延遲升至93.8毫秒。這清楚地表明了冪等計算如何通過禁用這兩個功能來降低延遲。為了驗證MillWheel的延遲特性與系統資源占用的擴展性良好,我們使用從20個CPU到2000個CPU的不同規模設置運行單階段延遲實驗,并按比例縮放輸入。圖14顯示,無論系統規模如何,中位延遲大致保持不變。99% 百分位數延遲確實顯著變差(盡管仍在100毫秒量級)。然而,隨著規模的擴大,尾部延遲預計會下降——更多的機器意味著出現問題的機會更多。
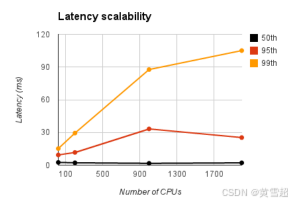
圖14:隨著系統資源規模的擴大,MillWheel的平均延遲并未顯著增加。
8.2 水位標記滯后
雖然有些計算(如Zeitgeist中的峰值檢測)不需要定時器,但許多計算(如驟降檢測)使用定時器等待低水位標記推進后再輸出聚合結果。對于這些計算,低水位標記落后于實時的程度限制了這些聚合結果的新鮮度。由于低水位標記從注入器通過計算圖傳播,我們預計一個計算的低水位標記滯后與它到注入器的最大管道距離成正比。我們在200個CPU上運行一個簡單的三階段MillWheel管道,并每秒輪詢一次每個計算的低水位標記值。在圖15中,我們可以看到第一階段的水位標記滯后實時1.8秒,然而,對于后續階段,每階段的滯后增加小于200毫秒。減少水位標記滯后是一個活躍的開發領域。
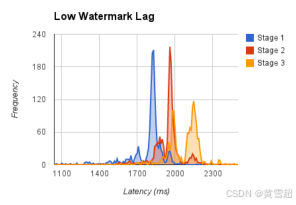
圖15:一個三階段管道中的低水位標記滯后情況。具體數據:{階段1:均值1795,標準差159。階段2:均值1954,標準差127。階段3:均值2081,標準差140} ?
8.3 框架級緩存
由于MillWheel的檢查點頻率較高,它會給存儲層帶來大量流量。當使用諸如Bigtable這樣的存儲系統時,讀取的成本高于寫入,MillWheel通過框架級緩存來緩解這一問題。MillWheel的一個常見用例是在存儲中緩沖數據,直到低水位標記超過窗口邊界,然后獲取數據進行聚合。這種使用模式對存儲系統中常見的LRU緩存不友好,因為最近修改的行是最不可能很快被讀取的。MillWheel知道這些數據可能的使用方式,并可以提供更好的緩存淘汰策略。在圖16中,我們測量了MillWheel工作進程和存儲層的綜合CPU使用率與最大緩存大小的關系(出于公司保密原因,CPU使用率已標準化)。增加可用緩存會線性改善CPU使用率(在550MB之后,大多數數據被緩存,因此進一步增加沒有幫助)。在這個實驗中,MillWheel的緩存能夠將CPU使用率降低一半。
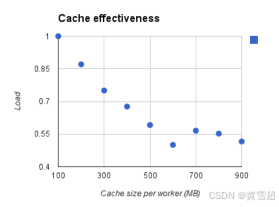
圖16:MillWheel與存儲層的總CPU負載 對比 框架緩存大小。
8.4 實際應用部署
MillWheel為谷歌內部各種各樣的系統提供支持。它為各種廣告客戶執行流連接操作,其中許多客戶要求對客戶可見的儀表板進行低延遲更新。計費管道依賴于MillWheel的恰好一次交付保證。除了Zeitgeist之外,MillWheel還為一個通用的異常檢測服務提供支持,許多不同的團隊將其作為一個交鑰匙解決方案使用。其他應用包括網絡交換機和集群健康監測。MillWheel還為面向用戶的工具提供支持,如谷歌街景的圖像全景生成和圖像處理。
也存在一些MillWheel不太適合的問題。本質上難以進行檢查點操作的單體操作不太適合包含在計算代碼中,因為系統的穩定性依賴于動態負載均衡。如果負載均衡器遇到與這種操作重合的熱點,它必須選擇要么中斷操作并強制其重新啟動,要么等待其完成。前者會浪費資源,而后者可能會使機器過載。作為一個分布式系統,MillWheel在那些不易在不同鍵之間并行化的問題上表現不佳。如果一個管道90% 的流量被分配到單個鍵,那么一臺機器必須處理該流90% 的整體系統負載,這顯然是不可取的。建議計算代碼的編寫者避免使用流量大到足以在單個機器上形成瓶頸的鍵(如客戶語言或用戶代理字符串),或者構建一個兩階段聚合器。
如果一個計算基于低水位標記定時器進行聚合,并且數據延遲長時間阻礙低水位標記推進,那么MillWheel的性能會下降。這可能導致系統中緩沖記錄出現數小時的偏差。通常內存使用與偏差成正比,因為應用程序依賴低水位標記來刷新這些緩沖數據。為了防止內存使用無限制增長,一個有效的補救方法是通過等待低水位標記推進后再注入新記錄,來限制系統中的總偏差。
9. 相關工作
我們構建流處理系統通用抽象的動機,在很大程度上受到了MapReduce [11] 在變革批處理領域所取得成功的影響,Apache Hadoop [4] 的廣泛應用便是例證。將MillWheel與現有的流處理系統模型(如Yahoo! S4 [26]、Storm [23] 和Sonora [32])進行比較,我們發現它們的模型對于我們期望解決的問題類別來說通用性不足。具體而言,S4和Sonora沒有涉及恰好一次處理和容錯持久狀態,而Storm直到最近才通過Trident [22] 添加了此類支持,Trident為了正常運行,對事務ID施加了嚴格的排序要求。Logothetis等人也提出了類似的觀點,強調了一流用戶狀態的必要性 [20]。Ciel [25] 針對一般的數據處理問題,同時動態生成數據流圖。與MapReduce Online [8] 一樣,我們認為為用戶提供 “早期返回” 具有極大的實用價值。谷歌的Percolator [27] 也針對大型數據集的增量更新,但期望的延遲在分鐘量級。
在評估我們的抽象時,我們注意到我們滿足了Stonebraker等人 [30] 列舉的流處理系統的要求。我們對亂序數據的靈活性與OOP方法 [19] 類似,OOP有力地論證了進行全局低水位標記計算(而非操作符級別的計算)的必要性,并令人信服地否定了使用靜態松弛值來補償亂序數據的可行性。
雖然我們贊賞Spark Streaming [34] 提出的針對特定操作符的流批系統統一方案,但我們認為MillWheel解決了更廣泛的問題集,并且微批處理模型如果不將用戶限制在預定義的操作符上是不可行的。具體來說,這個模型嚴重依賴RDDs [33],這將用戶限制在具有回滾能力的操作符上。
檢查點和恢復是任何流處理系統的關鍵方面,我們的方法與之前的許多方法相呼應。我們對發送方緩沖的使用類似于 [14] 中的 “上游備份”,它也定義了恢復語義(精確、回滾和間隙),與我們自己靈活的數據交付選項類似。正如Spark Streaming [34] 中提到的,簡單的上游備份解決方案可能會消耗過多資源,而我們對檢查點和持久狀態的使用消除了這些缺點。此外,我們的系統能夠實現比Spark Streaming [34] 更細粒度的檢查點,Spark Streaming建議每分鐘進行一次備份,并依賴應用程序的冪等性和系統松弛來進行恢復。類似地,SGuard [17] 比MillWheel更少地使用檢查點(同樣是每分鐘一次),盡管它的操作符分區方案類似于我們基于鍵的分片。
我們的低水位標記機制與其他流處理系統(如Gigascope [10])中使用的標點 [31] 或心跳 [16] 類似。然而,在我們的系統中,我們不會將心跳與標準元組交錯,而是選擇像OOP系統 [19] 那樣使用全局聚合器。我們的低水位標記概念也與OOP中定義的低水位標記類似。我們認同他們的分析,即在單個操作符上聚合心跳效率低下,最好留給全局機構處理。Srivastava等人在 [29] 中強調了這種低效率,其中討論了在每個操作符上維護每個流的心跳數組。此外,它還在用戶定義的時間戳(“應用時間”)和實際時鐘時間(“系統時間”)的概念之間建立了類似的區別,我們發現這非常有用。
我們注意到Lamport [18] 以及其他人 [12] [15] 在為分布式系統開發引人注目的時間語義方面所做的工作。
流處理系統的許多靈感可以追溯到流數據庫系統的開創性工作,如TelegraphCQ [6]、Aurora [2] 和STREAM [24]。我們觀察到我們實現的組件與流SQL中的對應組件之間存在相似之處,例如在Flux [28] 中使用分區操作符進行負載均衡。雖然我們認為我們的低水位標記語義比 [2] 中的松弛語義更強大,但我們發現我們的百分位低水位標記概念與 [1] 中的QoS系統有一些相似之處。
10. 參考文獻
[1] D. J. Abadi, Y. Ahmad, M. Balazinska, M. Cherniack,
J. hyon Hwang, W. Lindner, A. S. Maskey, E. Rasin,
E. Ryvkina, N. Tatbul, Y. Xing, and S. Zdonik. The design of
the borealis stream processing engine. In In CIDR, pages
277–289, 2005.
[2] D. J. Abadi, D. Carney, U. C? etintemel, M. Cherniack,
C. Convey, S. Lee, M. Stonebraker, N. Tatbul, and S. Zdonik.
Aurora: a new model and architecture for data stream
management. The VLDB Journal, 12(2):120–139, 2003.
[3] A. Adya, J. Dunagan, and A. Wolman. Centrifuge: Integrated
lease management and partitioning for cloud services. In
NSDI, pages 1–16. USENIX Association, 2010.
[4] Apache. Apache hadoop.
http://hadoop.apache.org, 2012.
[5] B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom.
Models and issues in data stream systems. In Proceedings of
the twenty-first ACM SIGMOD-SIGACT-SIGART symposium
on Principles of database systems, pages 1–16. ACM, 2002.
[6] S. Chandrasekaran, O. Cooper, A. Deshpande, M. J.
Franklin, J. M. Hellerstein, W. Hong, S. Krishnamurthy,
S. R. Madden, F. Reiss, and M. A. Shah. Telegraphcq:
continuous dataflow processing. In Proceedings of the 2003
ACM SIGMOD international conference on Management of
data, pages 668–668. ACM, 2003.
[7] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A.
Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E.
Gruber. Bigtable: A distributed storage system for structured
data. ACM Trans. Comput. Syst., 26:4:1–4:26, June 2008.
[8] T. Condie, N. Conway, P. Alvaro, J. M. Hellerstein,
K. Elmeleegy, and R. Sears. Mapreduce online. Technical
report, University of California, Berkeley, 2009.
[9] J. C. Corbett, J. Dean, M. Epstein, A. Fikes, C. Frost,
J. Furman, S. Ghemawat, A. Gubarev, C. Heiser,
P. Hochschild, et al. Spanner: Googles globally-distributed
database. To appear in Proceedings of OSDI, page 1, 2012.
[10] C. Cranor, Y. Gao, T. Johnson, V. Shkapenyuk, and
O. Spatscheck. Gigascope: High performance network
monitoring with an sql interface. In Proceedings of the 2002
ACM SIGMOD international conference on Management of
data, pages 623–623. ACM, 2002.
[11] J. Dean and S. Ghemawat. Mapreduce: simplified data
processing on large clusters. Commun. ACM, 51:107–113,
Jan. 2008.
[12] E. Deelman and B. K. Szymanski. Continuously monitored
global virtual time. Technical report, in Intern. Conf. Parallel
and Distributed Processing Techniques and Applications, Las
Vegas, NV, 1996.
[13] Google. Protocol buffers.
http://code.google.com/p/protobuf/, 2012.
[14] J.-H. Hwang, M. Balazinska, A. Rasin, U. Cetintemel,
M. Stonebraker, and S. Zdonik. High-availability algorithms
for distributed stream processing. In Data Engineering,
2005. ICDE 2005. Proceedings. 21st International
Conference on, pages 779–790. IEEE, 2005.
[15] D. R. Jefferson. Virtual time. ACM Transactions on
Programming Languages and Systems, 7:404–425, 1985.
[16] T. Johnson, S. Muthukrishnan, V. Shkapenyuk, and
O. Spatscheck. A heartbeat mechanism and its application in
gigascope. In Proceedings of the 31st international
conference on Very large data bases, pages 1079–1088.
VLDB Endowment, 2005.
[17] Y. Kwon, M. Balazinska, and A. Greenberg. Fault-tolerant
stream processing using a distributed, replicated file system.
Proceedings of the VLDB Endowment, 1(1):574–585, 2008.
[18] L. Lamport. Time, clocks, and the ordering of events in a
distributed system. Commun. ACM, 21(7):558–565, July
1978.
[19] J. Li, K. Tufte, V. Shkapenyuk, V. Papadimos, T. Johnson,
and D. Maier. Out-of-order processing: a new architecture
for high-performance stream systems. Proceedings of the
VLDB Endowment, 1(1):274–288, 2008.
[20] D. Logothetis, C. Olston, B. Reed, K. C. Webb, and
K. Yocum. Stateful bulk processing for incremental
analytics. In Proceedings of the 1st ACM symposium on
Cloud computing, pages 51–62. ACM, 2010.
[21] S. Madden and M. J. Franklin. Fjording the stream: An
architecture for queries over streaming sensor data. In Data
Engineering, 2002. Proceedings. 18th International
Conference on, pages 555–566. IEEE, 2002.
[22] N. Marz. Trident. https://github.com/
nathanmarz/storm/wiki/Trident-tutorial,
2012.
[23] N. Marz. Twitter storm.
https://github.com/nathanmarz/storm/wiki,
2012.
[24] R. Motwani, J. Widom, A. Arasu, B. Babcock, S. Babu,
M. Datar, G. Manku, C. Olston, J. Rosenstein, and R. Varma.
Query processing, resource management, and approximation
in a data stream management system. Technical Report
2002-41, Stanford InfoLab, 2002.
[25] D. G. Murray, M. Schwarzkopf, C. Smowton, S. Smith,
A. Madhavapeddy, and S. Hand. Ciel: a universal execution
engine for distributed data-flow computing. In Proceedings
of the 8th USENIX conference on Networked systems design
and implementation, page 9. USENIX Association, 2011.
[26] L. Neumeyer, B. Robbins, A. Nair, and A. Kesari. S4:
Distributed stream computing platform. In Data Mining
Workshops (ICDMW), 2010 IEEE International Conference
on, pages 170 –177, dec. 2010.
[27] D. Peng, F. Dabek, and G. Inc. Large-scale incremental
processing using distributed transactions and notifications. In
9th USENIX Symposium on Operating Systems Design and
Implementation, 2010.
[28] M. A. Shah, J. M. Hellerstein, S. Chandrasekaran, and M. J.
Franklin. Flux: An adaptive partitioning operator for
continuous query systems. In Data Engineering, 2003.
Proceedings. 19th International Conference on, pages
25–36. IEEE, 2003.
[29] U. Srivastava and J. Widom. Flexible time management in
data stream systems. In Proceedings of the twenty-third ACM
SIGMOD-SIGACT-SIGART symposium on Principles of
database systems, pages 263–274. ACM, 2004.
[30] M. Stonebraker, U. C? etintemel, and S. Zdonik. The 8
requirements of real-time stream processing. ACM SIGMOD
Record, 34(4):42–47, 2005.
[31] P. A. Tucker, D. Maier, T. Sheard, and L. Fegaras. Exploiting
punctuation semantics in continuous data streams.
Knowledge and Data Engineering, IEEE Transactions on,
15(3):555–568, 2003.
[32] F. Yang, Z. Qian, X. Chen, I. Beschastnikh, L. Zhuang,
L. Zhou, and J. Shen. Sonora: A platform for continuous
mobile-cloud computing. Technical report, Technical Report.
Microsoft Research Asia.






實驗文檔【新能源電力轉換與控制仿真】)
)


)



之中醫知識問答自動生成對話標題bug修改)



![[密碼學基礎]GMT 0029-2014簽名驗簽服務器技術規范深度解析](http://pic.xiahunao.cn/[密碼學基礎]GMT 0029-2014簽名驗簽服務器技術規范深度解析)
