一、Chroma 核心概念與優勢
1. 什么是 Chroma?
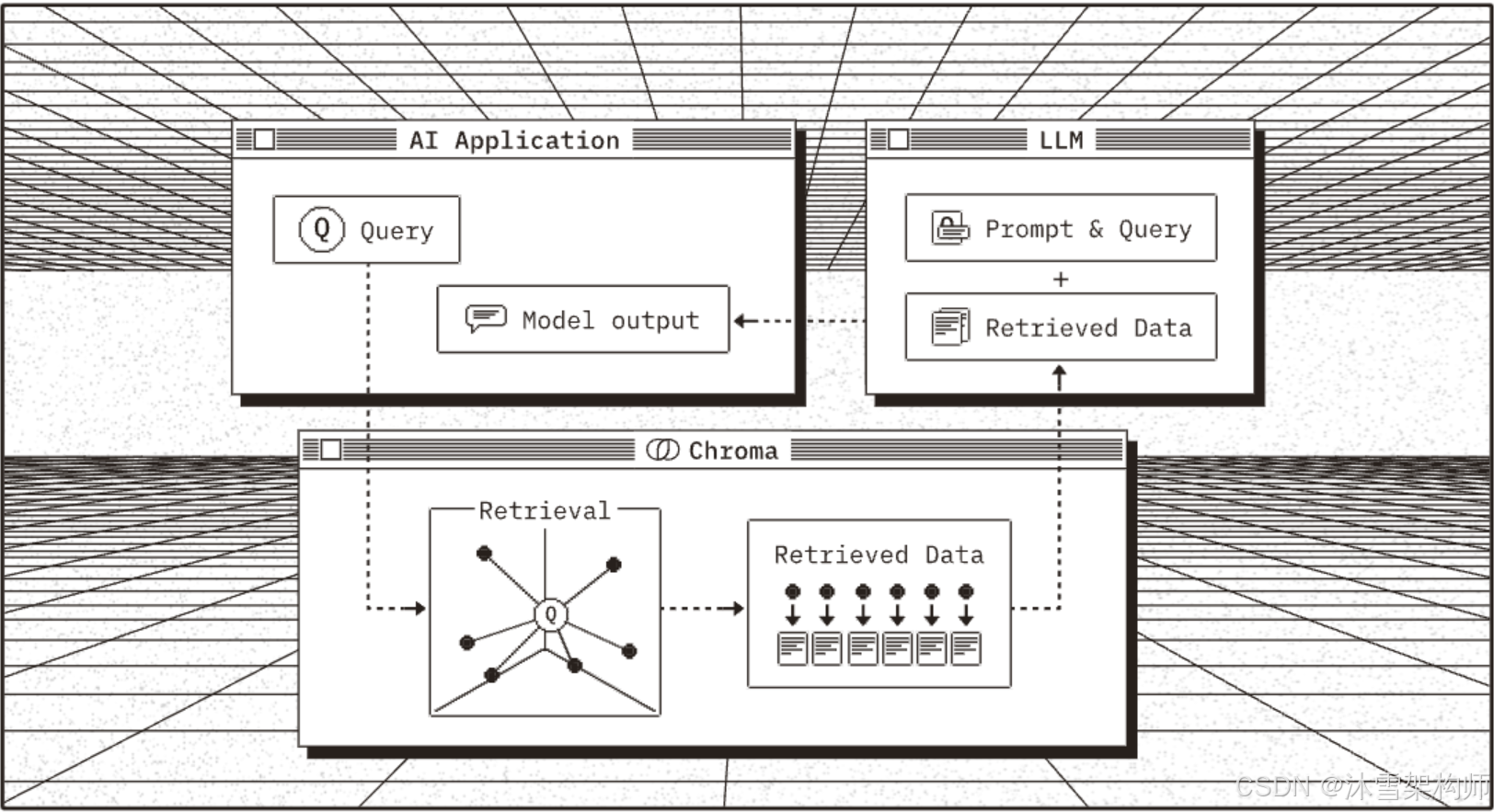
Chroma 是一款開源的向量數據庫,專為高效存儲和檢索高維向量數據設計。其核心能力在于語義相似性搜索,支持文本、圖像等嵌入向量的快速匹配,廣泛應用于大模型上下文增強(RAG)、推薦系統、多模態檢索等場景。與傳統數據庫不同,Chroma 基于向量距離(如余弦相似度、歐氏距離)衡量數據關聯性,而非關鍵詞匹配。

GitHub地址:
https://github.com/chroma-core/chroma
官方文檔:
https://docs.trychroma.com/
2. 核心優勢
- 輕量易用:以 Python/JS 包形式嵌入代碼,無需獨立部署,適合快速原型開發。
- 靈活集成:支持自定義嵌入模型(如 OpenAI、HuggingFace),兼容 LangChain 等框架。
- 高性能檢索:采用 HNSW 算法優化索引,支持百萬級向量毫秒級響應。
- 多模式存儲:內存模式用于開發調試,持久化模式支持生產環境數據落地。
?
二、安裝和基礎配置
?1、安裝Chroma
支持windows、ubuntu等操作系統,Python>=3.9? 。
創建虛擬環境以及安裝
#創建虛擬環境
conda create -n chromadb python==3.10#激活
conda activate chromadb#安裝chromadb
pip install chromadb注意:Chroma 默認是本地嵌入式數據庫,并不原生支持遠程訪問像傳統數據庫那樣(比如 PostgreSQL 那種 client-server 模式)。
當然官方也提供了客戶端-服務器端模式(Client-Server Mode),服務器端的啟動方式如下:
#服務器端啟動,默認端口號8000
chroma run --path /db_path2、初始化客戶端
?內存模式(調試,實驗的場景):
import chromadb
client = chromadb.Client()持久化模式(生產環境):
在創建的時候,可以配置本地的存儲路徑
client = chromadb.PersistentClient(path="/path/to/save") # 數據保存至本地目錄Client-Server模式的客戶端:
前兩種,都是本地模式,chroma的服務端和客戶端需要位于同一臺機器。CS模式可以獨立部署,通過httpclient進行訪問。
import chromadbchroma_client = chromadb.HttpClient(host='localhost', port=8000)
三、增刪改查操作
1. 創建集合(Collection)
- 名稱的長度必須介于 3 到 63 個字符之間。
- 名稱必須以小寫字母或數字開頭和結尾,中間可以包含點、破折號和下劃線。
- 名稱不得包含兩個連續的點。
- 該名稱不能是有效的 IP 地址。
Chroma 集合是用一個名稱和一個可選的嵌入函數創建的。
如果您提供嵌入函數,則每次獲取集合時都必須提供它。
# 創建
collection = client.create_collection(name="my_collection", embedding_function=emb_fn)# 獲取
collection = client.get_collection(name="my_collection", embedding_function=emb_fn)# 若沒有則創建,若有則獲取
collection = chroma_client.get_or_create_collection(name="my_collection2")
如果不提供嵌入函數,則使用默認的嵌入函數 sentence transformer? 使用的的是一個小型的模型all-MiniLM-L6-v2,該模型主要是針對英語場景。一般我們都需要自定義一個嵌入函數:
import chromadb
from sentence_transformers import SentenceTransformerclass SentenceTransformerEmbeddingFunction:def __init__(self, model_path: str, device: str = "cuda"):self.model = SentenceTransformer(model_path, device=device)def __call__(self, input: list[str]) -> list[list[float]]:if isinstance(input, str):input = [input]return self.model.encode(input, convert_to_numpy=True).tolist()# 創建/加載集合(含自定義嵌入函數)
embed_model = SentenceTransformerEmbeddingFunction(model_path=r"D:\Test\LLMTrain\testllm\llm\BAAI\bge-m3",device="cuda" # 無 GPU 改為 "cpu"
)# 創建客戶端和集合
client = chromadb.Client()
collection = client.create_collection("my_knowledge_base", metadata={"hnsw:space": "cosine"},embedding_function=embed_model)創建collect時,可以配置如下參數。
- name標識collect的名稱,是必填項;
- embedding_function,指定嵌入函數,不填為默認的嵌入模型。
- metadata,元數據,比如索引方式等,非必填。
from datetime import datetimecollection = client.create_collection(name="my_collection", embedding_function=emb_fn,metadata={"description": "my first Chroma collection","created": str(datetime.now())}
)
集合有一些常用方法:
- peek()?- 返回集合中前 10 個項目的列表。
- count()?-返回集合中的項目數。
- modify()?-重命名集合
collection.peek()
collection.count()
collection.modify(name="new_name")
2、寫入數據
寫入數據時,配置以下參數:
- document,原始的文本塊。
- metadatas,描述文本塊的元數據,kv鍵值對。
- ids,文本塊的唯一標識,每個文檔必須具有唯一關聯的ID。 若添加兩次相同的 ID 將導致僅存儲初始值。
- embeddings,對于已經向量化的文本塊,可以直接寫入結果。如果不填,則在寫入時,使用指定或者默認的嵌入函數對documents進行向量化。
collection.add(documents=["lorem ipsum...", "doc2", "doc3", ...],metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],ids=["id1", "id2", "id3", ...]
)
或者
collection.add(embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],ids=["id1", "id2", "id3", ...]
)
3、修改數據
提供ids(文本唯一標識)。
collection.update(ids=["doc1"], # 使用已存在的IDdocuments=["RAG是一種檢索增強生成技術222"]
)4、更新插入方法
Chroma 還支持更新插入操作,更新現有項目,如果項目尚不存在則添加它們。
collection.upsert(ids=["id1", "id2", "id3", ...],embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],documents=["doc1", "doc2", "doc3", ...],
)
5、刪除數據
Chroma 支持通過以下方式從集合中刪除項目ID使用delete。與每個項目相關的嵌入、文檔和元數據將被刪除。
還支持where過濾器。如果沒有ID提供,它將刪除集合中與where篩選。
# 提供ids
collection.delete(ids=["doc1"])
collection.delete(ids=["id1", "id2", "id3",...],where={"chapter": "20"}
)
6、查詢數據
(1)查詢所有數據
all_docs = collection.get()
print("集合中所有文檔:", all_docs)(2)根據ids查詢
可以通過以下方式從集合中檢索項目ID使用get。
collection.get(ids=["id1", "id2", "id3", ...],where={"style": "style1"}
)
(3)查詢嵌入
可以通過多種方式查詢 Chroma 集合,使用query方法。比如 使用query_embedding。
collection.query(query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],n_results=10,where={"metadata_field": "is_equal_to_this"},where_document={"$contains":"search_string"}
)
查詢將返回n_result每個最接近的匹配查詢嵌入,按順序排列。?可選where過濾字典可以通過metadata與每個文檔關聯。?此外,where document可以提供過濾字典來根據文檔內容進行過濾。
(4)查詢相似文檔
還可以通過一組查詢文本query_texts. Chroma 將首先嵌入每個查詢文本與集合的嵌入函數,然后使用生成的嵌入執行查詢。
# 查詢相似文檔
results = collection.query(query_texts=["什么是RAG技術?"],n_results=3
)print("查詢的結果",results)查詢結果
- 當使用 get 或 query 時,您可以使用include參數來指定您想要返回的數據包括:embeddings, documents,metadatas;include為數組,可以傳多個值。
- 對于查詢query,默認返回距離distances結果。
- embeddings出于性能考慮,默認不返回,直接顯示None ,若想返回,則include中包含embeddings即可。
- ID始終會返回。
- 返回值里有included參數,表明本次返回的數據有哪些類型。
- embeddings將以二維 NumPy 數組的形式返回。
# Only get documents and ids
collection.get(include=["documents"]
)collection.query(query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],include=["documents"]
)
#查詢的結果{'ids': [['doc1', 'doc3', 'doc2']],
'embeddings': None,
'documents': [['RAG是一種檢索增強生成技術', '三英戰呂布', '向量數據庫存儲文檔的嵌入表示']],
'uris': None,
'included': ['metadatas', 'documents', 'distances'],
'data': None,
'metadatas': [[{'source': 'tech_doc'}, {'source': 'tutorial1'}, {'source': 'tutorial'}]],
'distances': [[0.2373753786087036, 0.7460092902183533, 0.7651787400245667]]
}
四、實戰操作
將一批數據插入向量數據庫,再根據一個問題從向量數據庫中找出相似數據。
?1、安裝包
pip install sentence_transformerspip install modelscope2、下載Embedding模型到本地
#模型下載
from modelscope import snapshot_download
model_dir = snapshot_download('BAAI/bge-m3',cache_dir=r"D:\Test\LLMTrain\testllm\llm")3、寫入數據和查詢相似文本
import chromadb
from sentence_transformers import SentenceTransformerclass SentenceTransformerEmbeddingFunction:def __init__(self, model_path: str, device: str = "cuda"):self.model = SentenceTransformer(model_path, device=device)def __call__(self, input: list[str]) -> list[list[float]]:if isinstance(input, str):input = [input]return self.model.encode(input, convert_to_numpy=True).tolist()# 創建/加載集合(含自定義嵌入函數)
embed_model = SentenceTransformerEmbeddingFunction(model_path=r"D:\Test\LLMTrain\testllm\llm\BAAI\bge-m3",device="cuda" # 無 GPU 改為 "cpu"
)# 創建客戶端和集合
client = chromadb.PersistentClient(path=r"D:\Test\LLMTrain\chromadb_test\chroma_data")
collection = client.get_or_create_collection("my_knowledge_base",metadata={"hnsw:space": "cosine"},embedding_function=embed_model)# 添加文檔
collection.add(documents=[ "向量數據庫存儲文檔的嵌入表示", "三英戰呂布","RAG是一種檢索增強生成技術"],metadatas=[{"source": "tech_doc"}, {"source": "tutorial"}, {"source": "tutorial1"}],ids=["doc1", "doc2", "doc3"]
)# 查詢相似文檔
results = collection.query(query_texts=["什么是RAG技術?"],n_results=3
)print("查詢的結果",results)
執行返回結果:
查詢的結果
{
'ids': [['doc3', 'doc2', 'doc1']],
'embeddings': None,
'documents': [['RAG是一種檢索增強生成技術', '三英戰呂布', '向量數據庫存儲文檔的嵌入表示']],
'uris': None,
'included': ['metadatas', 'documents', 'distances'],
'data': None,
'metadatas': [[{'source': 'tutorial1'}, {'source': 'tutorial'}, {'source': 'tech_doc'}]],
'distances': [[0.2373753786087036, 0.7460092902183533, 0.7651787400245667]]
}查看結果,我們重點看 distances,值是從小到大排序的,所以3條數據與問題“什么是RAG技術?”的相似度情況:distances值越小越相似。因此,第1條數據與問題越相似。


)

的SWOT分析)








問題?)


)


