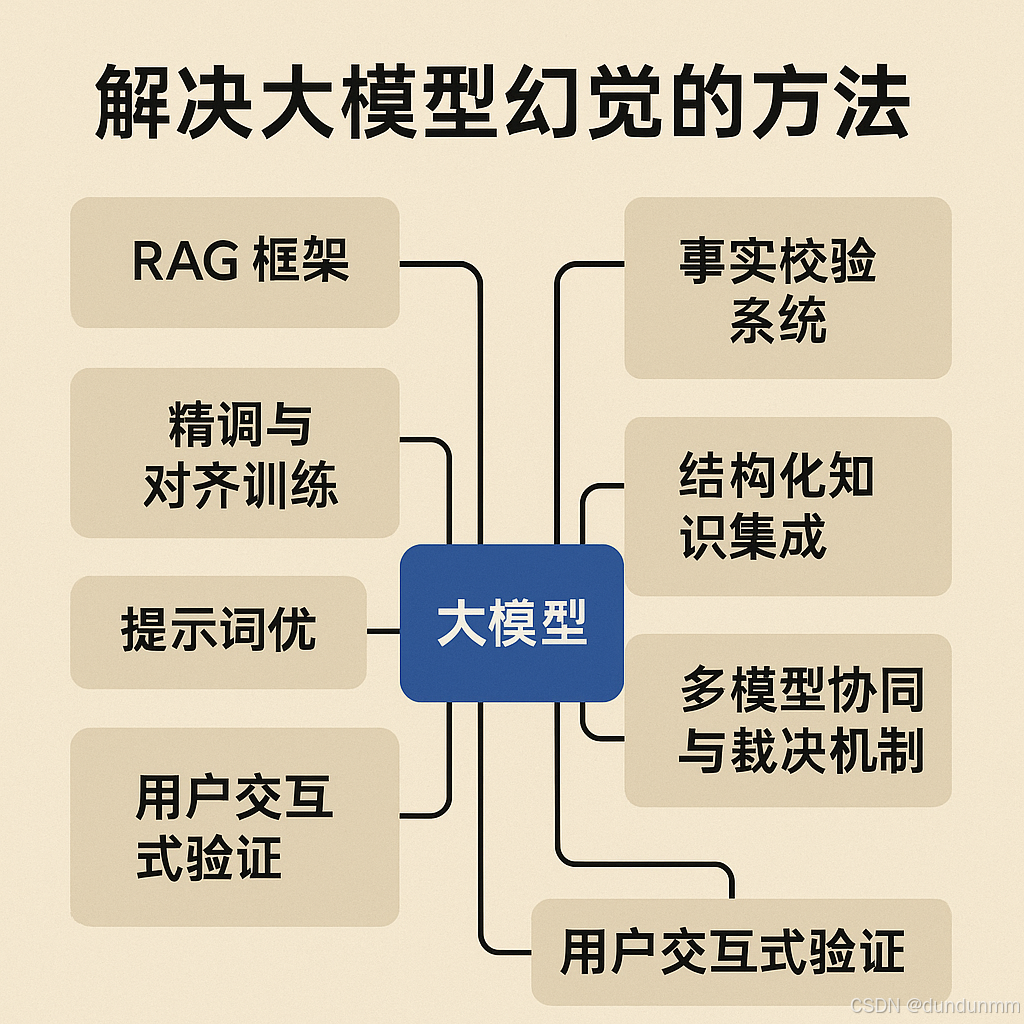
解決大模型幻覺(hallucination)問題,需要從模型架構、訓練方式、推理機制和后處理策略多方面協同優化。
🧠 1. 引入 RAG 框架(Retrieval-Augmented Generation)
思路: 模型生成前先檢索知識庫中的真實信息作為上下文輸入,讓生成“有據可依”。
-
? 結合外部數據庫、文檔系統或向量知識庫
-
? 常用于問答、總結、金融分析等領域
-
🔧 示例工具:FAISS、Elasticsearch、Milvus
🎯 2. 精調與對齊訓練(Alignment Fine-tuning)
用高質量的真實數據或人工標注數據對模型再訓練。
-
? 訓練時加入“拒絕回答不確定內容”的偏好
-
? 使用RLHF(人類反饋強化學習)提升真實性與安全性
-
? 結合指令微調(Instruction Tuning)防止過度自由發揮
🛠? 3. 提示詞優化(Prompt Engineering)
精細設計prompt,引導模型關注事實和來源。
-
? 加入如“請基于以下文檔回答”、“請注明出處”
-
? 提出明確限制:“如不知道請說明不知道”
-
? 通過 few-shot 提示加入“回答示例”來約束行為
🧾 4. 事實校驗系統(Fact-checking Module)
在生成后,使用另一個模塊來自動檢驗真假或一致性。
-
? 提取生成內容中的主張,去知識源中比對
-
? 使用NLI(自然語言推理)判斷事實一致性
-
? 構建“可信度評分”系統篩選或標記高風險回答
🧩 5. 結構化知識集成(Knowledge Injection)
將知識圖譜、結構化數據庫中的內容融入上下文。
-
? 在生成任務中插入規則知識或約束
-
? 使用Schema/Slot填空方式確保字段準確
-
? 常用于金融、法律、醫療等要求高度準確的場景
📶 6. 多模型協同與裁決機制
多個模型生成多個版本,通過比對、投票或裁判選擇最可信答案。
-
? 可顯著提升準確性
-
? 增加穩定性和魯棒性(尤其適用于自動報告生成)
-
?? 成本較高,適合關鍵任務使用
? 7. 用戶交互式驗證(Human-in-the-loop)
在關鍵任務場景中,設計交互機制讓用戶校對或確認模型輸出。
-
例如生成報告草稿→用戶確認→模型修訂
-
可視化高風險片段,提供編輯建議
📌 總結一句話:
“讓模型懂得‘不知道’比假裝知道更重要。”
——要想降低幻覺,不僅要提升知識準確度,還要讓模型“知道它不知道”的邊界。


)



)


與華為(Huawei)設備配置IPsec VPN的詳細說明,涵蓋配置流程、參數設置及常見問題處理)
:pyscript 目錄文件介紹)








 - 單通道ADC采集、多通道ADC采集、定時器觸發連續ADC采集 - STM32CubeMX)