文章目錄
- 前言
- 一、學習率
- 1、什么學習率
- 2、什么是調整學習率
- 3、目的
- 二、調整方法
- 1、有序調整
- 1)有序調整StepLR(等間隔調整學習率)
- 2)有序調整MultiStepLR(多間隔調整學習率)
- 3)有序調整ExponentialLR (指數衰減調整學習率)
- 4)有序調整CosineAnnealing (余弦退火函數調整學習率)
- 2、自適應調整
- 1)自適應調整ReduceLROnPlateau (根據指標調整學習率)
- 3、自定義調整
- 1)自定義調整LambdaLR (自定義調整學習率)
- 三、代碼參考
- 總結
前言
在深度學習中,學習率(Learning Rate) 是優化算法中最重要的超參數之一。對于卷積神經網絡(CNN)而言,合理的學習率調整策略直接影響模型的收斂速度、訓練穩定性和最終性能。本文將系統性地介紹CNN訓練中常用的學習率調整方法,并結合PyTorch代碼示例和實踐經驗,幫助讀者掌握這一關鍵技巧。
一、學習率
1、什么學習率
??學習率是優化算法中一個重要的超參數,用于控制模型參數在每次更新時的調整幅度。學習率決定了模型在參數空間中搜索的步長大小。調整學習率是指在訓練過程中根據需要改變學習率的值。
2、什么是調整學習率
??常用的學習率有0.1、0.01以及0.001等,學習率越大則權重更新越快。一般來說,我們希望在訓練初期學習率大一些,使得網絡收斂迅速,在訓練后期學習率小一些,使得網絡更好的收斂到最優解。
- 使用庫函數進行調整
- 手動調整學習率

3、目的
?? 調整學習率的目的是為了能夠更好地優化模型,避免訓練過程中出現的一些問題,如梯度爆炸或梯度消失、陷入局部極小值等。
二、調整方法
Pytorch學習率調整策略通過 torch.optim.lr_sheduler 接口實現,本篇介紹3種庫函數調整方法:
(1)有序調整:等間隔調整(Step),多間隔調整(MultiStep),指數衰減(Exponential),余弦退火(CosineAnnealing);
(2)自適應調整:依訓練狀況伺機而變,通過監測某個指標的變化情況(loss、accuracy),當該指標不怎么變化 時,就是調整學習率的時機(ReduceLROnPlateau);
(3)自定義調整:通過自定義關于epoch的lambda函數調整學習率(LambdaLR)。
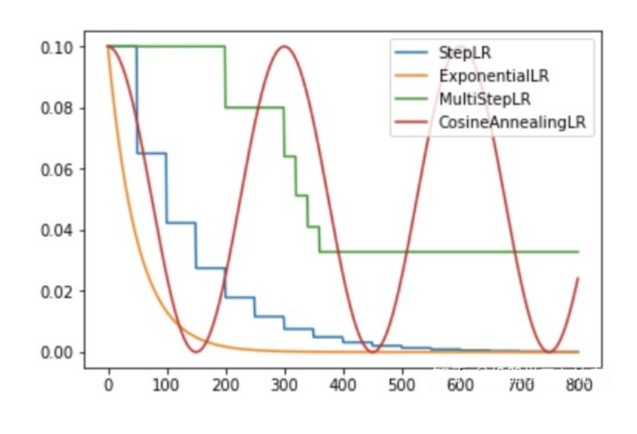
1、有序調整
1)有序調整StepLR(等間隔調整學習率)
"""等間隔調整"""
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
# optimizer: 神經網絡訓練中使用的優化器,
# 如optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
# step_size(int): 學習率下降間隔數,單位是epoch,而不是iteration.
# gamma(float):學習率調整倍數,默認為0.1
# 每訓練step_size個epoch,學習率調整為lr=lr*gamma.
2)有序調整MultiStepLR(多間隔調整學習率)
"""多間隔調整"""
torch.optim.lr_shceduler.MultiStepLR(optimizer, milestones, gamma=0.1)
milestone(list): 一個列表參數,表示多個學習率需要調整的epoch值,
如milestones=[10, 30, 80],即10輪時將gamma乘以學習率lr,30輪時、80輪時
3)有序調整ExponentialLR (指數衰減調整學習率)
'''指數衰減調整'''
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma)
參數:
gamma(float):學習率調整倍數的底數,指數為epoch,初始值我lr, 倍數為γepoch,每一輪都調整.
4)有序調整CosineAnnealing (余弦退火函數調整學習率)
'''余弦退火函數調整'''
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)
參數:
Tmax(int):學習率下降到最小值時的epoch數,即當epoch=T_max時,學習率下降到余弦函數最小值,當epoch>T_max時,學習率將增大;
etamin: 學習率調整的最小值,即epoch=Tmax時,lrmin=etamin, 默認為0.
2、自適應調整
當某指標(loss或accuracy)在最近幾個epoch中都沒有變化(下降或升高超過給定閾值)時,調整學習率。
1)自適應調整ReduceLROnPlateau (根據指標調整學習率)
"""根據指標調整學習率"""
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1,patience=10,verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
-
optimizer: 被包裝的優化器。
-
mode: 可以是 ‘min’ 或 ‘max’。如果是 ‘min’,當監測的指標停止下降時學習率會被降低;如果是
-
‘max’,當指標停止上升時學習率會被降低。
-
factor: 學習率降低的因子,新的學習率會是舊學習率乘以這個因子。
-
patience: 在指標停止改善之后等待多少個周期才降低學習率。
-
threshold: 用于衡量新的最優值的閾值,只關注顯著的變化。
-
threshold_mode: 可以是 ‘rel’ 或 ‘abs’。在 ‘rel’ 模式下,動態閾值會根據最佳值和閾值的相對關系來設定;在 ‘abs’ 模式下,動態閾值會根據最佳值加上或減去閾值來設定。
-
cooldown: 在學習率被降低之后,等待多少個周期再繼續正常操作。
-
min_lr: 所有參數組或每個組的學習率的下限。
-
eps: 應用于學習率的最小衰減。如果新舊學習率之間的差異小于 eps,則忽略這次更新。
3、自定義調整
可以為不同層設置不同的學習率。
1)自定義調整LambdaLR (自定義調整學習率)
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
參數:
lr_lambda(function or list): 自定義計算學習率調整倍數的函數,通常時epoch的函數,當有多個參數組時,設為list.
三、代碼參考
loss_fn = nn.CrossEntropyLoss() # 創建交叉熵損失函數對象
optimizer = torch.optim.Adam(model.parameters(),lr=0.001) #創建一個優化器,一開始lr可以大一些
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5) # 調整學習率
"""optimizer是一個PyTorch優化器對象
step_size表示學習率調整的步長
gamma表示學習率的衰減因子,即每次調整后將當前學習率乘以gamma
""""""訓練模型"""
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)epochs = 10
acc_s = []
loss_s = []for t in range(epochs):print(f"Epoch {t+1}\n---------------------------")train(train_dataloader,model,loss_fn,optimizer)test(test_dataloader, model, loss_fn)scheduler.step()
print(bast_acc)
總結
沒有"放之四海皆準"的最優策略,通過實驗找到適合具體任務的方法才是王道。






問題?)


)



)


與華為(Huawei)設備配置IPsec VPN的詳細說明,涵蓋配置流程、參數設置及常見問題處理)
:pyscript 目錄文件介紹)

