目錄
1.deque(簡單介紹)
1.1?deque介紹:
1.2?deque迭代器底層
1.2.1 那么比如說用迭代器實現元素的遍歷,是如何實現的呢?
1.2.2?頭插
1.2.3?尾插
1.2.4?實現+=
??編輯
1.2.5?總結
2.stack
2.1?函數介紹
2.2?模擬實現:
3.queue
3.1?函數介紹
3.2?模擬實現:
3.3?為什么選擇deque來作為他們的底層容器?
4.priority_queue
4.1 priority_queue的使用
4.2?仿函數
4.2.1?基本原理
4.3?priority_queue模擬實現
5.cpu緩存知識
1.deque(簡單介紹)
咱們今天講適配器以及deque,主要講適配器,那么講deque是因為,stack,queue的底層都是封裝的容器deque。
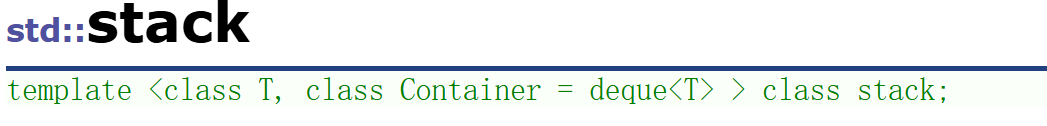
 ?
?
Container就是適配器,可以看出,官方庫中都是以deque為底層容器,那么為什么呢?今天咱們就來討論一下。
deque與queue看著是不是很像,但千萬別把他們給搞混了,deque是容器,而queue是容器適配器。?
1.1?deque介紹:
deque(雙端隊列):是一種雙開口的"連續"空間的數據結構,雙開口的含義是:可以在頭尾兩端 進行插入和刪除操作,且時間復雜度為O(1),與vector比較,頭插效率高,不需要搬移元素;與 list比較,空間利用率比較高。它支持兩端的高效插入與刪除。
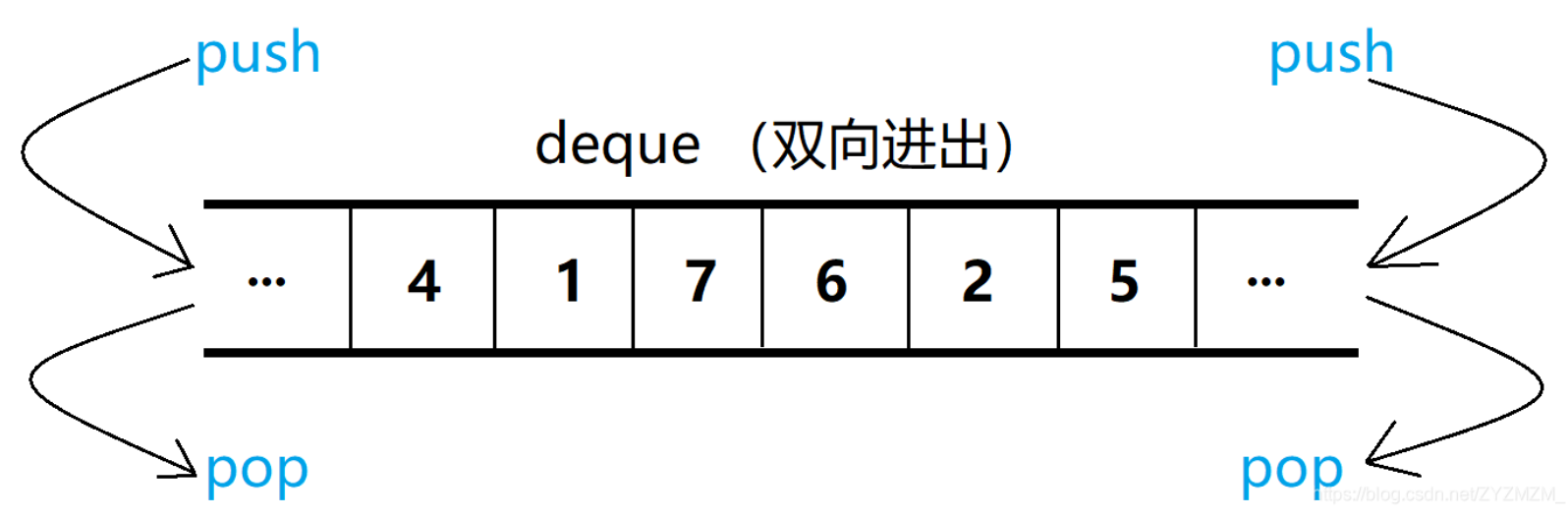
?deque的功能也挺齊全的其實,基本上前面幾個容器有的,它都具備。
-
核心操作:
-
push_back()?和?push_front():在兩端插入元素。 -
pop_back()?和?pop_front():在兩端刪除元素。 -
operator[]?或?at():隨機訪問元素。 -
front()?和?back():訪問兩端元素。
-
那么接下來咱們呢進入重點部分,也就是deque的迭代器部分的講解,聽完這個,您就知道為什么stack與queue要選擇deque作為他們的底層容器了。
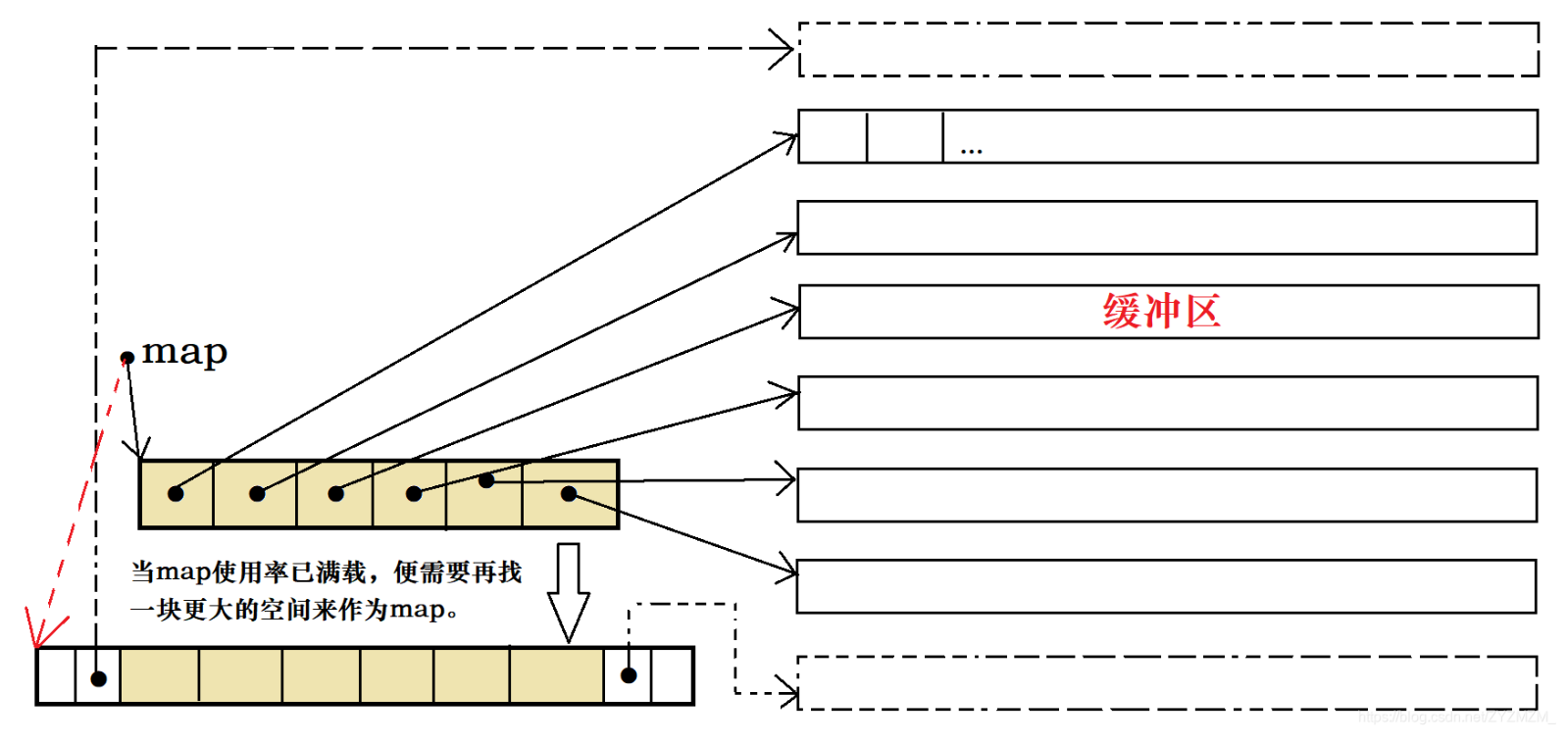
1.2?deque迭代器底層
 ?
?
deque的迭代器更像是一塊一塊的動態內存塊。例如上圖,右方的就是他的一個一個的內存塊,也可以叫緩沖區,那么這些內存塊是由中間的那個中控指針數組map控制的。map中存的是指向每個內存塊的指針,那么它們要是想移動內存塊的時候,就只需要移動指向他們的指針即可。
當然,這個也需要擴容,但是只需要當中控數組滿了的時候才去擴容,即擴容的對象就單一了。
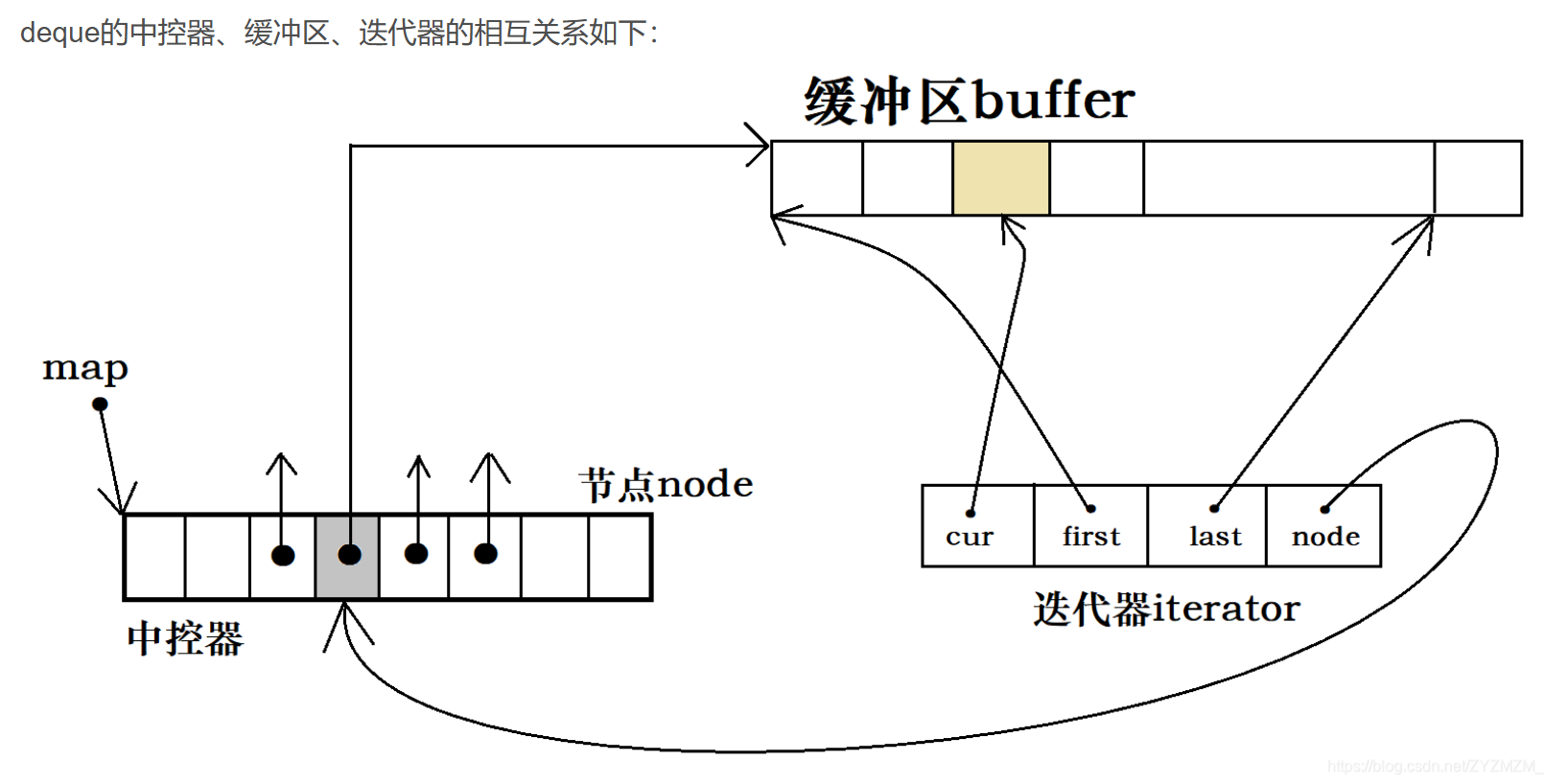 ?
?
這個圖更形象,因為這個圖中有控制每一個內存塊的迭代器。注意看,這個迭代器中有node,這個node是個二級指針,指向中控器中的元素(一級指針)。所以,內存塊的移動就是對node進行的加加或者減減。那么cur指向的是當前元素的位置,而first指向的是開始,last指向的是結尾。
1.2.1 那么比如說用迭代器實現元素的遍歷,是如何實現的呢?
 ?
?
咱們來看這一段代碼,比較兩個內存塊是否相等,比較cur即可,因為每個內存塊的first與last的位置都是相同的,所以無法比較這兩個,只有比較你當前元素的位置才可以看出你兩個內存塊到底相不相等。這里面也是實現的operator++,
1.先讓每一個塊中的cur往后走,直至走完?。
2.如果說當前塊中的元素遍歷完了(cur==last),那么通過node來改變下一個要訪問的內存塊,之后更新first,last,cur的位置即可。
3.以此類推即可。
4.那么是不是可以看出遍歷的時候,deque的迭代器要頻繁的去檢測其 是否移動到某段小空間的邊界(cur==last),導致效率低下。所以說deque并不適合遍歷。
1.2.2?頭插
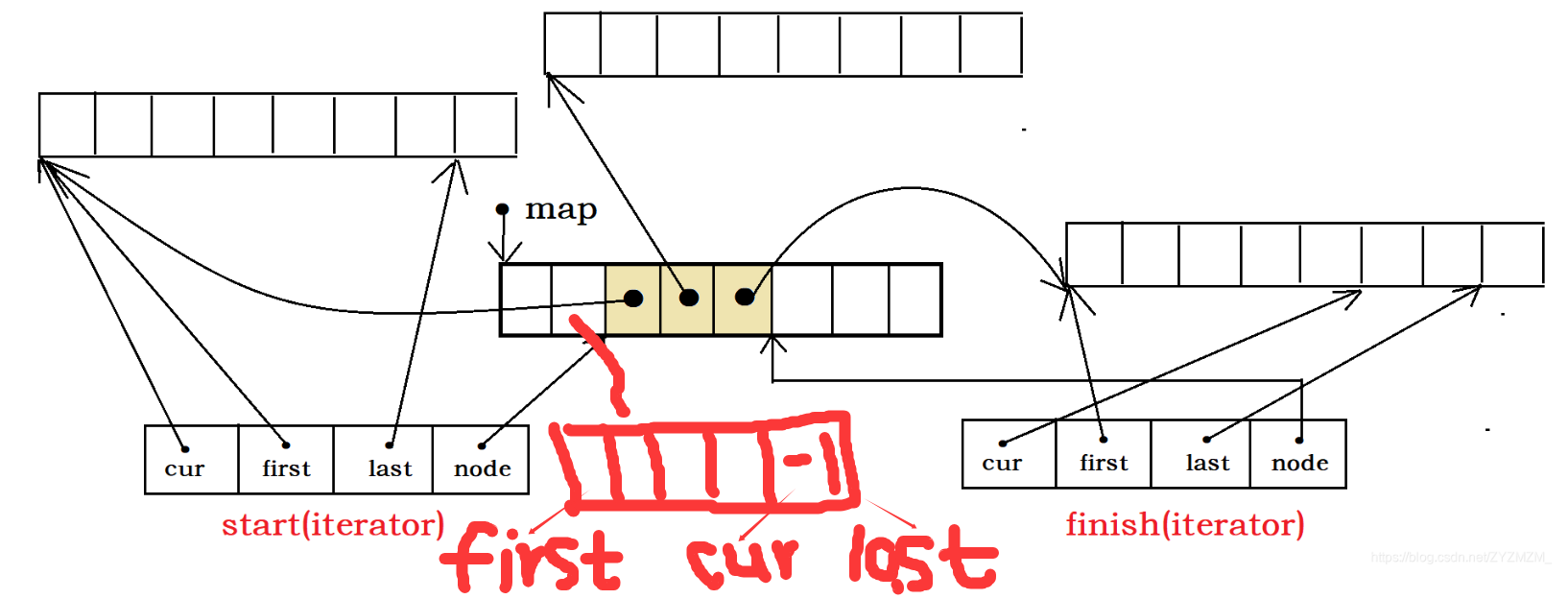
頭插直接在map前面拿一個內存塊,在后面插入數據即可,但之后別忘了更新位置。則,頭插既不需要申請空間(因為map已有空間),也不需要反復挪動數據,很高效吧。
1.2.3?尾插
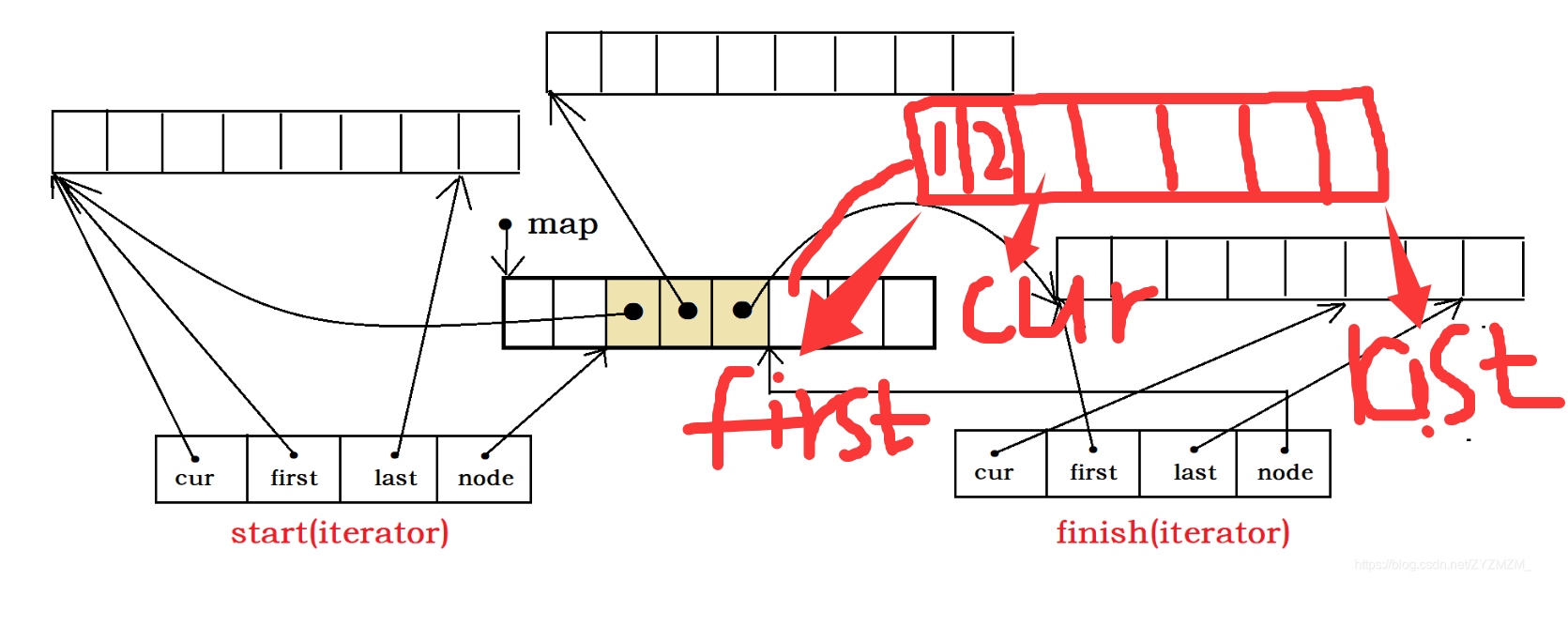 注意頭插是從尾部開始插入,尾插是從頭部開始插入,那么這里需要注意的是,cur在這里指向的當前元素的下一個位置,是因為,咱們的迭代器都是左閉右開的,所以說,左邊的可以cur可以指向當前元素(頭插),因為可以取到那個數據。但是右邊的cur指向的當前元素的下一個位置(尾插),這樣才可以確保可以取到已經插入的那個元素。
注意頭插是從尾部開始插入,尾插是從頭部開始插入,那么這里需要注意的是,cur在這里指向的當前元素的下一個位置,是因為,咱們的迭代器都是左閉右開的,所以說,左邊的可以cur可以指向當前元素(頭插),因為可以取到那個數據。但是右邊的cur指向的當前元素的下一個位置(尾插),這樣才可以確保可以取到已經插入的那個元素。
但尾插也是很高效的。因為他也是不需要申請空間,直接從map中拿就可以了。
1.2.4?實現+=
?
現在比如說咱們要加等一個數,那么面臨的問題是跳過幾個內存塊?最后的位置要落在最后一個內存塊的哪個位置?那么接下來,用除(/)去確定跳過幾個內存塊,用取模(%)去確定最后停在內存塊的第幾個位置處,您想想是不是這樣的一個道理。當然這個只是簡單的原理,具體的實現,比較復雜,?因為考慮了負數。
1.2.5?總結
OK,經過以上的講解,大家應該知道deque的迭代器不適合用于遍歷元素,因為需要頻繁的判斷邊界是否相等。
所以,deque的缺陷:
1.與vector比較,deque的優勢是:頭部插入和刪除時,不需要搬移元素,效率特別高,而且在擴 容時,也不需要搬移大量的元素,因此其效率是必vector高的。
2.與list比較,其底層是連續空間,空間利用率比較高,不需要存儲額外字段。
3.但是,deque有一個致命缺陷:不適合遍歷,因為在遍歷時,deque的迭代器要頻繁的去檢測其 是否移動到某段小空間的邊界,導致效率低下,而序列式場景中,可能需要經常遍歷,因此在實 際中,需要線性結構時,大多數情況下優先考慮vector和list,deque的應用并不多,而目前能看 到的一個應用就是,STL用其作為stack和queue的底層數據結構。
?咱們先來看stack與queue,最后再來說為什么選擇deque作為底層容器,因為還得理解stack與queue的模擬實現。
2.stack
stack是個容器適配器,這是個新的概念,那么什么是容器適配器呢?容器適配器是建立在現有容器之上的抽象,提供不同的接口,但底層使用已有的容器實現。以我的個人見解就是這些stack,queue,priority_queue,這些的接口可以用其他的容器進行覆蓋,就是說,這些容器適配器有的接口,那些對應的底層容器也是有的,這樣就直接將那些底層容器封裝起來,然后再實現一些這些容器適配器特有的接口,其實也是一種封裝的體現。
即將底層的那些大的不同的封裝起來,不讓你看,讓你看的就是那些自己的接口,這樣雖然底層可能用不同的容器實現的,但是你表面看上去還是沒什么不同,但是底層早已天差地別。這就是封裝,不關心底層的實現,只關心自己的目前的接口。
2.1?函數介紹
stack():構造空的棧.
empty():檢測stack是否為空.
size():返回stack中元素的個數.
top():返回棧頂元素的引用.
push():將元素val壓入stack中.
pop():將stack中尾部的元素彈出.
這些看著是不是很眼熟,沒錯,就是咱們數據結構——棧和隊列那一章實現的。
2.2?模擬實現:
template<class T, class Container = deque<T>>
class stack
{
????????public:
????????void push(const T& x)
????????{
????????????????_con.push_back(x);
????????}
????????void pop()
????????{
????????????????_con.pop_back();
????????}
????????T& top()
?????????{
????????????????return _con.back();
????????}
????????const T& top() const
????????{
????????????????return _con.back();
????????}
????????bool empty() const
????????{
????????????????return _con.empty();
????????}
????????size_t size() const
????????{
????????????????return _con.size();
????????}
????????private:
????????Container _con;//用模板去實例化對象,這樣_con可以是任何類的對象。
};
基本也就這些東西,唯一增加的就是一個容器適配器。
3.queue
1. 隊列是一種容器適配器,專門用于在FIFO上下文(先進先出)中操作,其中從容器一端插入元 素,另一端提取元素。
2. 隊列作為容器適配器實現,容器適配器即將特定容器類封裝作為其底層容器類,queue提供 一組特定的成員函數來訪問其元素。元素從隊尾入隊列,從隊頭出隊列。
3. 底層容器可以是標準容器類模板之一,也可以是其他專門設計的容器類。該底層容器應至少 支持以下操作:
empty:檢測隊列是否為空
size:返回隊列中有效元素的個數
front:返回隊頭元素的引用
back:返回隊尾元素的引用
push_back:在隊列尾部入隊列
pop_front:在隊列頭部出隊列
4. 標準容器類deque和list滿足了這些要求。默認情況下,如果沒有為queue實例化指定容器類,則使用標準容器deque。
3.1?函數介紹
queue():構造空的隊列
empty():檢測隊列是否為空,是返回true,否則返回false
size():返回隊列中有效元素的個數
front():返回隊頭元素的引用
back():返回隊尾元素的引用
push():在隊尾將元素val入隊列
pop():將隊頭元素出隊列
3.2?模擬實現:
template<class T, class Container = deque<T>>
class queue
{
????????public:
????????void push(const T& x)
????????{
????????????????_con.push_back(x);
????????}
????????void pop()
????????{
????????????????_con.pop_front();
????????}
????????T& front()
????????{
????????????????return _con.front();
????????}
????????const T& front() const
????????{
????????????????return _con.front();
????????}
????????T& back()
????????{
????????????????return _con.back();
????????}
????????const T& back() const
????????{
????????????????return _con.back();
????????}
????????bool empty() const
????????{
????????????????return _con.empty();
????????}
????????size_t size() const
????????{
????????????????return _con.size();
????????}
????????private:
????????Container _con;
};
3.3?為什么選擇deque來作為他們的底層容器?
stack是一種后進先出的特殊線性數據結構,因此只要具有push_back()和pop_back()操作的線性 結構,都可以作為stack的底層容器,比如vector和list都可以;queue是先進先出的特殊線性數據 結構,只要具有push_back和pop_front操作的線性結構,都可以作為queue的底層容器,比如 list。但是STL中對stack和queue默認選擇deque作為其底層容器,主要是因為:
1. stack和queue不需要遍歷(因此stack和queue沒有迭代器),只需要在固定的一端或者兩端進 行操作。而經過咱們上邊對deque迭代器原理的講解,可知頭插與尾插的效率很高。
2. 在stack中元素增長時,deque比vector的效率高(擴容時不需要搬移大量數據);queue中的 元素增長時,deque不僅效率高,而且內存使用率高。 結合了deque的優點,而完美的避開了其缺陷。?
4.priority_queue

1. 優先隊列是一種容器適配器,根據嚴格的弱排序標準,它的第一個元素總是它所包含的元素 中最大的。
2. 此上下文類似于堆,在堆中可以隨時插入元素,并且只能檢索最大堆元素(優先隊列中位于頂 部的元素)。
3. 優先隊列被實現為容器適配器,容器適配器即將特定容器類封裝作為其底層容器類,queue 提供一組特定的成員函數來訪問其元素。元素從特定容器的“尾部”彈出,其稱為優先隊列的 頂部。
4. 底層容器可以是任何標準容器類模板,也可以是其他特定設計的容器類。容器應該可以通過 隨機訪問迭代器訪問,并支持以下操作:
empty():檢測容器是否為空
size():返回容器中有效元素個數
front():返回容器中第一個元素的引用
push_back():在容器尾部插入元素
pop_back():刪除容器尾部元素?
?5. 標準容器類vector和deque滿足這些需求。默認情況下,如果沒有為特定的priority_queue 類實例化指定容器類,則使用vector。
6. 需要支持隨機訪問迭代器,以便始終在內部保持堆結構。容器適配器通過在需要時自動調用 算法函數make_heap、push_heap和pop_heap來自動完成此操作。
這里的底層容器又變了,是vector,那么問什么是vector呢?因為priority_queue的底層是堆,而堆又是以順序表為載體實現的(后面會講)。所以說具體的原因是:
1. vector的連續內存布局,訪問元素高效,緩存友好。
2. 尾部操作(push_back和pop_back)的高效性,這對堆的調整非常重要。
3. 動態擴容的均攤時間復雜度低。
4. 相比其他容器如deque或list,vector在堆操作中的綜合性能更好。
4.1 priority_queue的使用
優先級隊列默認使用vector作為其底層存儲數據的容器,在vector上又使用了堆算法將vector中 元素構造成堆的結構,因此priority_queue就是堆,所有需要用到堆的位置,都可以考慮使用 priority_queue。注意:默認情況下priority_queue是大堆。如果想用小頂堆,就需要傳入greater<T>這個仿函數。
priority_queue()/[riority_queue(first,last):構造一個空的優先級隊列
empty():檢測優先級隊列是否為空,是返回true,否則返回false
top():返回優先級隊列中最大(最小元素),即堆頂元素
push(x):在優先級隊列中插入元素x
pop():刪除優先級隊列中最大(最小)元素,即堆頂元素
在看他的模擬實現之前,先學一個知識點:仿函數
4.2?仿函數
在 C++ 中,仿函數(Functor)?是一種通過重載?operator()?運算符,使得類的對象可以像函數一樣被調用的機制。它是 STL(標準模板庫)中實現自定義行為的核心工具之一,常用于算法(如?sort、transform)和容器(如?priority_queue、set)的自定義邏輯中。
4.2.1?基本原理
仿函數本質是一個類對象,但通過重載?operator(),可以像函數一樣調用:
例如:
class Adder { public:int operator()(int a, int b) {return a + b;} };int main() {Adder add;cout << add(3, 5); // 輸出 8:對象像函數一樣被調用 }
仿函數與普通函數的比較:?
| 特性 | 仿函數 | 普通函數 |
|---|---|---|
| 狀態管理 | 可以保存狀態(通過成員變量) | 無狀態(全局變量除外) |
| 靈活性 | 可作為模板參數傳遞 | 需用函數指針或?std::function |
| 性能 | 通常可被編譯器內聯優化 | 函數指針可能無法內聯 |
| 適配性 | 與 STL 算法/容器無縫集成 | 需額外適配(如?std::ptr_fun) |
現在仿函數用到的還比較少,因為博主現在看的關于仿函數的代碼比較少。那么如何創建一個仿函數呢?
定義類:創建一個類,重載?
operator()。實現邏輯:在?
operator()?中定義具體行為。傳遞對象:將類的實例傳遞給算法或容器。
?OK,仿函數目前就講這么多,接下來來看代碼就可以看的懂了。
4.3?priority_queue模擬實現
template<class T>
class less
{
public:
?? ?bool operator()(const T & s1, const T & s2)//仿函數重載的是(),不是其他的符號
?? ?{
?? ??? ?return s1 < s2;
?? ?}
};
/*template<class T>
class less<T*>
{
public:
?? ?bool operator()( T &*const s1, ?T & *const s2)
?? ?{
?? ??? ?return *s1 < *s2;
?? ?}
};*/這個注釋掉了
template<class T>
class greater
{
public:
?? ?bool operator()(const T & s1, const T & s2)
?? ?{
?? ??? ?return s1 > s2;
?? ?}
};
template<class T, class Container = vector<T>, class Compare = less<T>>
//為什么在test.cpp中放開#include"priority_queue.h",vector就可以用了呢?
class priority_queue
{
public:
?? ?priority_queue()//一個類創建好了,別忘了構造
?? ?{}
?? ?void push(const T& x)
?? ?{
?? ??? ?_con.push_back(x);
?? ??? ?//底層是堆,所以不管插入還是刪除數據,最后都別忘了再調整
?? ??? ?adjustup(_con.size() - 1);
?? ?}
?? ?void pop()
?? ?{
?? ??? ?swap(_con[0], _con[_con.size() - 1]);?? ??? ?_con.pop_back();
?? ??? ?adjustdown(0);
?? ?}
?? ?const T& top() const//這倆const是必須要加的,因為堆頂的元素是不允許
?? ??? ?//被更改的,一旦更改,就全都亂了,堆中元素的順序全都亂了
?? ?{
?? ??? ?return _con[0];
?? ?}
?? ?size_t size() const//這個返回的是個數,是size類型,不是T類型
?? ?{
?? ??? ?return _con.size();
?? ?}
?? ?bool empty()
?? ?{
?? ??? ?return _con.empty();
?? ?}
private:
?? ?void adjustup(int child)//parent=(child-1)/2
?? ??? ?//從誰開始調整,就傳誰,這里先從孩子開上調整,所以先傳孩子
?? ?{
?? ??? ?Compare com;
?? ??? ?int parent = (child - 1) / 2;
?? ??? ?while (child > 0)
?? ??? ?{
?? ??? ??? ?if (com( _con[parent], _con[child] ))
?? ??? ??? ?{
?? ??? ??? ??? ?swap(_con[child], _con[parent]);
?? ??? ??? ??? ?child = parent;
?? ??? ??? ??? ?parent = (child - 1) / 2;
?? ??? ??? ?}
?? ??? ??? ?else
?? ??? ??? ?{
?? ??? ??? ??? ?break;
?? ??? ??? ?}
?? ??? ?}
?? ?}
?? ?void adjustdown(int parent)
?? ?{
?? ??? ?Compare com;
?? ??? ?size_t child = parent * 2 + 1;
?? ??? ?while (child < _con.size())
?? ??? ?{
?? ??? ??? ?if (child + 1 < _con.size() && com(_con[child] , _con[child + 1]))
?? ??? ??? ?{
?? ??? ??? ??? ?child += 1;
?? ??? ??? ?}
?? ??? ??? ?if (com( _con[parent], _con[child] ))//這個地方是<,return x<y,所以注意com中的順序
?? ??? ??? ?{
?? ??? ??? ??? ?swap(_con[child], _con[parent]);
?? ??? ??? ??? ?parent = child;
?? ??? ??? ??? ?child = parent * 2 + 1;
?? ??? ??? ?}
?? ??? ??? ?else
?? ??? ??? ?{
?? ??? ??? ??? ?break;
?? ??? ??? ?}
?? ??? ?}
?? ?}
private:
?? ?Container _con;
};
這里就不放代碼圖片了,因為截圖的話,一整張字太小,看不清代碼。?
?
這里還要注意的是包的頭文件,一般像這樣的#include""的頭文件放在using?namespace?std;后
,這樣可以避免出現錯誤。
OK,以上關于三個容器適配器的內容講完了,其實您看,也就多了一個容器適配器,以及模板,其余的用法啥的與前面的?容器基本類似。主要這部分還是在多寫代碼多應用,我在這嘴皮子磨冒煙了,您不寫代碼,還是沒用。
5.cpu緩存知識
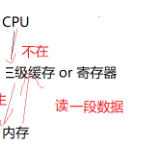
上面咱們老是提到緩存命中率高,啥的,這個到底是啥,那么今天我就來簡單的介紹一下:
假如說有一段數據,那么這個數據是不是存放在內存中,當然也有的存放在緩存中。如果說cpu要訪問一個數據,要看這個數據是否在緩存中,在就叫緩存命中,不在就叫緩存不命中。不命中,就要先將數據從內存加載到緩存中(一般都是加載一段數據)。然后再訪問緩存。

 ?
?
OK,咱們先來看vector,為什么說vector的緩存命中率高呢?
 假如說第一個數據不在緩存中,那么cpu就要讀取一段數據到緩存中,又因為vector地址是連續的,所以說讀一段數據到緩存中就很自然地將后面的數據全都讀到緩存中并且全部讀取出來。
假如說第一個數據不在緩存中,那么cpu就要讀取一段數據到緩存中,又因為vector地址是連續的,所以說讀一段數據到緩存中就很自然地將后面的數據全都讀到緩存中并且全部讀取出來。
但是list:緩存命中率低
它的地址不是連續的,所以說你讀取一段數據的時候,可能讀過來了,數據不是咱們想要的?。還可能讀過來了,但不是咱們想要的數據,這就是緩存污染!
OK,本博主的粗略解釋就這些,大家要是想看詳細的。
與程序員相關的CPU緩存知識 | 酷 殼 - CoolShell
這是陳大佬寫的一篇文章,大家可以去閱讀一下。
本篇完...................






![[langchain教程]langchain03——用langchain構建RAG應用](http://pic.xiahunao.cn/[langchain教程]langchain03——用langchain構建RAG應用)
)


結合osg及osgEarth實現三維球經緯網格繪制及顯隱)








