四、參數初始化
神經網絡的參數初始化是訓練深度學習模型的關鍵步驟之一。初始化參數(通常是權重和偏置)會對模型的訓練速度、收斂性以及最終的性能產生重要影響。下面是關于神經網絡參數初始化的一些常見方法及其相關知識點。
官方文檔參考:torch.nn.init — PyTorch 2.6 documentation
1. 固定值初始化
固定值初始化是指在神經網絡訓練開始時,將所有權重或偏置初始化為一個特定的常數值。這種初始化方法雖然簡單,但在實際深度學習應用中通常并不推薦。
1.1 全零初始化
將神經網絡中的所有權重參數初始化為0。
方法:將所有權重初始化為零。
缺點:導致對稱性破壞,每個神經元在每一層中都會執行相同的計算,模型無法學習。
應用場景:通常不用來初始化權重,但可以用來初始化偏置。
對稱性問題
-
現象:同一層的所有神經元具有完全相同的初始權重和偏置。
-
后果:
-
在反向傳播時,所有神經元會收到相同的梯度,導致權重更新完全一致。
-
無論訓練多久,同一層的神經元本質上會保持相同的功能(相當于“一個神經元”的多個副本),極大降低模型的表達能力。
-
代碼演示:
import torch import torch.nn as nn ? def test004():# 3. 全0參數初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化權重參數nn.init.zeros_(linear.weight)# 打印權重參數print(linear.weight) ? ? if __name__ == "__main__":test004() ?
打印結果:
Parameter containing: tensor([[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.]], requires_grad=True)
1.2 全1初始化
全1初始化會導致網絡中每個神經元接收到相同的輸入信號,進而輸出相同的值,這就無法進行學習和收斂。所以全1初始化只是一個理論上的初始化方法,但在實際神經網絡的訓練中并不適用。
代碼演示:
import torch import torch.nn as nn ? ? def test003():# 3. 全1參數初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化權重參數nn.init.ones_(linear.weight)# 打印權重參數print(linear.weight) ? ? if __name__ == "__main__":test003() ?
輸出結果:
Parameter containing: tensor([[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.]], requires_grad=True)
1.3 任意常數初始化
將所有參數初始化為某個非零的常數(如 0.1,-1 等)。雖然不同于全0和全1,但這種方法依然不能避免對稱性破壞的問題。
import torch import torch.nn as nn ? ? def test002():# 2. 固定值參數初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化權重參數nn.init.constant_(linear.weight, 0.63)# 打印權重參數print(linear.weight)pass ? ? if __name__ == "__main__":test002() ?
輸出結果:
Parameter containing: tensor([[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300]], requires_grad=True)
參考2:
import torch import torch.nn as nn ? ? def test002():net = nn.Linear(2, 2, bias=True)# 假設一個數值x = torch.tensor([[0.1, 0.95]]) ?# 初始化權重參數net.weight.data = torch.tensor([[0.1, 0.2], [0.3, 0.4]]) ?# 輸出什么:權重參數會轉置output = net(x)print(output, net.bias)pass ? ? if __name__ == "__main__":test002() ?
2. 隨機初始化
方法:將權重初始化為隨機的小值,通常從正態分布或均勻分布中采樣。
應用場景:這是最基本的初始化方法,通過隨機初始化避免對稱性破壞。
代碼演示:隨機分布之均勻初始化
import torch import torch.nn as nn ? ? def test001():# 1. 均勻分布隨機初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化權重參數nn.init.uniform_(linear.weight)# 打印權重參數print(linear.weight) ? ? if __name__ == "__main__":test001() ?
打印結果:
Parameter containing: tensor([[0.4080, 0.7444, 0.7616, 0.0565, 0.2589, 0.0562],[0.1485, 0.9544, 0.3323, 0.9802, 0.1847, 0.6254],[0.6256, 0.2047, 0.5049, 0.3547, 0.9279, 0.8045],[0.1994, 0.7670, 0.8306, 0.1364, 0.4395, 0.0412]], requires_grad=True)
代碼演示:正態分布初始化
import torch import torch.nn as nn ? ? def test005():# 5. 正太分布初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化權重參數nn.init.normal_(linear.weight, mean=0, std=1)# 打印權重參數print(linear.weight) ? ? if __name__ == "__main__":test005() ?
打印結果:
Parameter containing: tensor([[ 1.5321, ?0.2394, ?0.0622, ?0.4482, ?0.0757, -0.6056],[ 1.0632, ?1.8069, ?1.1189, ?0.2448, ?0.8095, -0.3486],[-0.8975, ?1.8253, -0.9931, ?0.7488, ?0.2736, -1.3892],[-0.3752, ?0.0500, -0.1723, -0.4370, -1.5334, -0.5393]],requires_grad=True)
3. Xavier 初始化
前置知識:
均勻分布:
均勻分布的概率密度函數(PDF):
如果其他情況
計算期望值(均值):
計算方差(二階矩減去均值的平方):
-
先計算 ?:
-
代入方差公式:
Xavier 初始化(由 Xavier Glorot 在 2010 年提出)是一種自適應權重初始化方法,專門為解決神經網絡訓練初期的梯度消失或爆炸問題而設計。Xavier 初始化也叫做Glorot初始化。Xavier 初始化的核心思想是根據輸入和輸出的維度來初始化權重,使得每一層的輸出的方差保持一致。具體來說,權重的初始化范圍取決于前一層的神經元數量(輸入維度)和當前層的神經元數量(輸出維度)。
方法:根據輸入和輸出神經元的數量來選擇權重的初始值。
數學原理:
(1) 前向傳播的方差一致性
假設輸入 x 的均值為 0,方差為 ?,權重 W的均值為 0,方差為 ?,則輸出 z=Wx的方差為:
為了使 Var(z)=Var(x),需要:
其中 ?是輸入維度(fan_in)。這里乘以 nin 的原因是,輸出 z 是由 nin 個輸入 x 的線性組合得到的,每個輸入 x 都與一個權重 W 相乘。因此,輸出 z 的方差是 nin 個獨立的 Wx 項的方差之和。
(2) 反向傳播的梯度方差一致性
在反向傳播過程中,梯度 ? 是通過鏈式法則計算得到的,其中 L 是損失函數,x 是輸入,z 是輸出。梯度?可以表示為:
假設 z=Wx,其中 W 是權重矩陣,那么 ?。因此,梯度 ?可以寫為: ?
反向傳播時梯度 ? 的方差應與 ? 相同,因此:
其中 ?是輸出維度(fan_out)。為了保持梯度的方差一致性,我們需要確保每個輸入維度 nin 的梯度方差與輸出維度 nout 的梯度方差相同。因此,我們需要將 W 的方差乘以 nout,以確保梯度的方差在反向傳播過程中保持一致。
(3) 綜合考慮
為了同時平衡前向傳播和反向傳播,Xavier 采用:
權重從以下分布中采樣:
均勻分布:
在Xavier初始化中,我們選擇 ? 和 ?,這樣方差為:
正態分布:
其中 ? 是當前層的輸入神經元數量,?是輸出神經元數量。
在前向傳播中,輸出的方差受 ? 影響。在反向傳播中,梯度的方差受 ? 影響。
優點:平衡了輸入和輸出的方差,適合? 和 ? 激活函數。
應用場景:常用于淺層網絡或使用? 、? 激活函數的網絡。
代碼演示:
import torch import torch.nn as nn ? ? def test007():# Xavier初始化:正態分布linear = nn.Linear(in_features=6, out_features=4)nn.init.xavier_normal_(linear.weight)print(linear.weight) ?# Xavier初始化:均勻分布linear = nn.Linear(in_features=6, out_features=4)nn.init.xavier_uniform_(linear.weight)print(linear.weight) ? ? if __name__ == "__main__":test007() ?
打印結果:
Parameter containing: tensor([[-0.4838, ?0.4121, -0.3171, -0.2214, -0.8666, -0.4340],[ 0.1059, ?0.6740, -0.1025, -0.1006, ?0.5757, -0.1117],[ 0.7467, -0.0554, -0.5593, -0.1513, -0.5867, -0.1564],[-0.1058, ?0.5266, ?0.0243, -0.5646, -0.4982, -0.1844]],requires_grad=True) Parameter containing: tensor([[-0.5263, ?0.3455, ?0.6449, ?0.2807, -0.3698, -0.6890],[ 0.1578, -0.3161, -0.1910, -0.4318, -0.5760, ?0.3746],[ 0.2017, -0.6320, -0.4060, ?0.3903, ?0.3103, -0.5881],[ 0.6212, ?0.3077, ?0.0783, -0.6187, ?0.3109, -0.6060]],requires_grad=True)
4. He初始化
也叫kaiming 初始化。He 初始化的核心思想是調整權重的初始化范圍,使得每一層的輸出的方差保持一致。與 Xavier 初始化不同,He 初始化專門針對 ReLU 激活函數的特性進行了優化。
數學推導
(1) 前向傳播的方差一致性
對于 ReLU 激活函數,輸出的方差為:
(因為 ReLU 使一半神經元輸出為 0,方差減半) 為使 Var(z)=Var(x),需:
(2) 反向傳播的梯度一致性
類似地,反向傳播時梯度方差需滿足:
因此:
(3) 兩種模式
-
fan_in模式(默認):優先保證前向傳播穩定,方差 ?。 -
fan_out模式:優先保證反向傳播穩定,方差?。
方法:專門為 ReLU 激活函數設計。權重從以下分布中采樣:
均勻分布:
正態分布:
其中 ? 是當前層的輸入神經元數量。
優點:適用于? 和 ? 激活函數。
應用場景:深度網絡,尤其是使用 ReLU 激活函數時。
代碼演示:
import torch import torch.nn as nn ? ? def test006():# He初始化:正態分布linear = nn.Linear(in_features=6, out_features=4)nn.init.kaiming_normal_(linear.weight, nonlinearity="relu", mode='fan_in')print(linear.weight) ?# He初始化:均勻分布linear = nn.Linear(in_features=6, out_features=4)nn.init.kaiming_uniform_(linear.weight, nonlinearity="relu", mode='fan_out')print(linear.weight) ? ? if __name__ == "__main__":test006() ?
輸出結果:
Parameter containing: tensor([[ 1.4020, ?0.2030, ?0.3585, -0.7419, ?0.6077, ?0.0178],[-0.2860, -1.2135, ?0.0773, -0.3750, -0.5725, ?0.9756],[ 0.2938, -0.6159, -1.1721, ?0.2093, ?0.4212, ?0.9079],[ 0.2050, ?0.3866, -0.3129, -0.3009, -0.6659, -0.2261]],requires_grad=True) ? Parameter containing: tensor([[-0.1924, -0.6155, -0.7438, -0.2796, -0.1671, -0.2979],[ 0.7609, ?0.9836, -0.0961, ?0.7139, -0.8044, -0.3827],[ 0.1416, ?0.6636, ?0.9539, ?0.4735, -0.2384, -0.1330],[ 0.7254, -0.4056, -0.7621, -0.6139, -0.6093, -0.2577]],requires_grad=True)
5. 總結
在使用Torch構建網絡模型時,每個網絡層的參數都有默認的初始化方法,同時還可以通過以上方法來對網絡參數進行初始化。
五、損失函數
1. 線性回歸損失函數
1.1 MAE損失
MAE(Mean Absolute Error,平均絕對誤差)通常也被稱為 L1-Loss,通過對預測值和真實值之間的絕對差取平均值來衡量他們之間的差異。。
MAE的公式如下:
其中:
-
? 是樣本的總數。
-
? 是第 ? 個樣本的真實值。
-
? 是第 ? 個樣本的預測值。
-
? 是真實值和預測值之間的絕對誤差。
特點:
-
魯棒性:與均方誤差(MSE)相比,MAE對異常值(outliers)更為魯棒,因為它不會像MSE那樣對較大誤差平方敏感。
-
物理意義直觀:MAE以與原始數據相同的單位度量誤差,使其易于解釋。
應用場景: MAE通常用于需要對誤差進行線性度量的情況,尤其是當數據中可能存在異常值時,MAE可以避免對異常值的過度懲罰。
使用torch.nn.L1Loss即可計算MAE:
import torch
import torch.nn as nn
?
# 初始化MAE損失函數
mae_loss = nn.L1Loss()
?
# 假設 y_true 是真實值, y_pred 是預測值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([2.5, 5.0, 3.0])
?
# 計算MAE
loss = mae_loss(y_pred, y_true)
print(f'MAE Loss: {loss.item()}')
1.2 MSE損失
均方差損失,也叫L2Loss。
MSE(Mean Squared Error,均方誤差)通過對預測值和真實值之間的誤差平方取平均值,來衡量預測值與真實值之間的差異。
MSE的公式如下:
其中:
-
? 是樣本的總數。
-
? 是第 ? 個樣本的真實值。
-
? 是第 ? 個樣本的預測值。
-
? 是真實值和預測值之間的誤差平方。
特點:
-
平方懲罰:因為誤差平方,MSE 對較大誤差施加更大懲罰,所以 MSE 對異常值更為敏感。
-
凸性:MSE 是一個凸函數(國際的叫法,國內叫凹函數),這意味著它具有一個唯一的全局最小值,有助于優化問題的求解。
應用場景:
MSE被廣泛應用在神經網絡中。
使用 torch.nn.MSELoss 可以實現:
import torch
import torch.nn as nn
?
# 初始化MSE損失函數
mse_loss = nn.MSELoss()
?
# 假設 y_true 是真實值, y_pred 是預測值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([2.5, 5.0, 3.0])
?
# 計算MSE
loss = mse_loss(y_pred, y_true)
print(f'MSE Loss: {loss.item()}')
2. CrossEntropyLoss
2.1 信息量
信息量用于衡量一個事件所包含的信息的多少。信息量的定義基于事件發生的概率:事件發生的概率越低,其信息量越大。其量化公式:
對于一個事件x,其發生的概率為 P(x),信息量I(x) 定義為:
性質
-
非負性:I(x)≥0。
-
單調性:P(x)越小,I(x)越大。
2.2 信息熵
信息熵是信息量的期望值。熵越高,表示隨機變量的不確定性越大;熵越低,表示隨機變量的不確定性越小。
公式由數學中的期望推導而來:
其中:
?是信息量,?是信息量對應的概率
2.3 KL散度
KL散度用于衡量兩個概率分布之間的差異。它描述的是用一個分布 Q來近似另一個分布 P時,所損失的信息量。KL散度越小,表示兩個分布越接近。
對于兩個離散概率分布 P和 Q,KL散度定義為:
其中:P 是真實分布,Q是近似分布。
2.4 交叉熵
對KL散度公式展開:
由上述公式可知,P是真實分布,H(P)是常數,所以KL散度可以用H(P,Q)來表示;H(P,Q)叫做交叉熵。
如果將P換成y,Q換成?,則交叉熵公式為:
其中:
-
? 是類別的總數。
-
? 是真實標簽的one-hot編碼向量,表示真實類別。
-
? 是模型的輸出(經過 softmax 后的概率分布)。
-
? 是真實類別的第 ? 個元素(0 或 1)。
-
? 是預測的類別概率分布中對應類別 ? 的概率。
函數曲線圖:
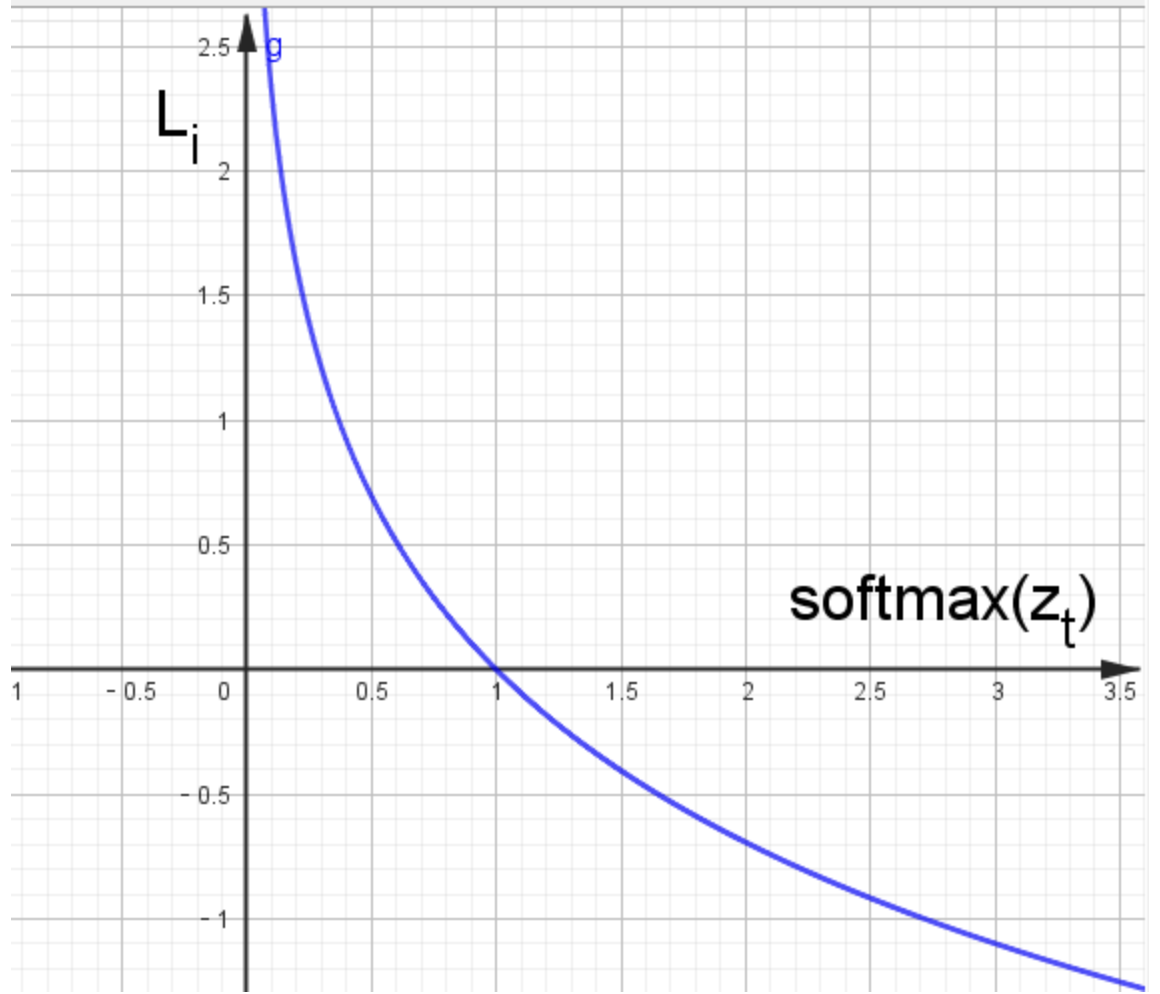 特點:
特點:
-
概率輸出:CrossEntropyLoss 通常與 softmax 函數一起使用,使得模型的輸出表示為一個概率分布(即所有類別的概率和為 1)。PyTorch 的 nn.CrossEntropyLoss 已經內置了 Softmax 操作。如果我們在輸出層顯式地添加 Softmax,會導致重復應用 Softmax,從而影響模型的訓練效果。
-
懲罰錯誤分類:該損失函數在真實類別的預測概率較低時,會施加較大的懲罰,這樣模型在訓練時更注重提升正確類別的預測概率。
-
多分類問題中的標準選擇:在大多數多分類問題中,CrossEntropyLoss 是首選的損失函數。
應用場景:
CrossEntropyLoss 廣泛應用于各種分類任務,包括圖像分類、文本分類等,尤其是在神經網絡模型中。
nn.CrossEntropyLoss基本原理:
由交叉熵公式可知:
因為?是one-hot編碼,其值不是1便是0,又是乘法,所以只要知道1對應的index就可以了,展開后:
其中,m表示真實類別。
因為神經網絡最后一層分類總是接softmax,所以可以把?直接看為是softmax后的結果。
所以,CrossEntropyLoss 實質上是兩步的組合:Cross Entropy = Log-Softmax + NLLLoss
-
Log-Softmax:對輸入 logits 先計算對數 softmax:
log(softmax(x))。 -
NLLLoss(Negative Log-Likelihood):對 log-softmax 的結果計算負對數似然損失。簡單理解就是求負數。原因是概率值通常在 0 到 1 之間,取對數后會變成負數。為了使損失值為正數,需要取負數。
對于?,在softmax介紹中了解到,需要減去最大值以確保數值穩定。
則:
所以:
總的交叉熵損失函數是所有樣本的平均值:
示例代碼如下:
import torch
import torch.nn as nn
?
# 假設有三個類別,模型輸出是未經softmax的logits
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])
?
# 真實的標簽
labels = torch.tensor([1, 2]) ?# 第一個樣本的真實類別為1,第二個樣本的真實類別為2
?
# 初始化CrossEntropyLoss
# 參數:reduction:mean-平均值,sum-總和
criterion = nn.CrossEntropyLoss()
?
# 計算損失
loss = criterion(logits, labels)
print(f'Cross Entropy Loss: {loss.item()}')
在這個例子中,CrossEntropyLoss 直接作用于未經 softmax 處理的 logits 輸出和真實標簽,PyTorch 內部會自動應用 softmax 激活函數,并計算交叉熵損失。
分析示例中的代碼:
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])
第一個樣本的得分是 [1.5, 2.0, 0.5],分別對應類別 0、1 和 2 的得分。
第二個樣本的得分是 [0.5, 1.0, 1.5],分別對應類別 0、1 和 2 的得分
labels = torch.tensor([1, 2])
第一個樣本的真實類別是 1。
第二個樣本的真實類別是 2。
CrossEntropyLoss 的計算過程可以分為以下幾個步驟:
(1) LogSoftmax 操作
首先,對每個樣本的 logits 應用 LogSoftmax 函數,將 logits 轉換為概率分布。LogSoftmax 函數的公式是: ?
對于第一個樣本 [1.5, 2.0, 0.5]:
減去最大值:
?
計算?:
求和并取對數:
計算 log_softmax:
對于第二個樣本 [0.5, 1.0, 1.5]:
減去最大值:
?
計算?:
求和并取對數:
計算 log_softmax:
(2) 計算每個樣本的損失
接下來,根據真實標簽 ? 計算每個樣本的交叉熵損失。交叉熵損失的公式是: ?
對于第一個樣本:
-
真實類別是 1,對應的 softmax 值是 -0.6041。
對于第二個樣本:
-
真實類別是 2,對應的 softmax 值是 -0.6803。
(3) 計算平均損失
最后,計算所有樣本的平均損失: 平均損失?
3. BCELoss
二分類交叉熵損失函數,使用在輸出層使用sigmoid激活函數進行二分類時。
由交叉熵公式:
對于二分類問題,真實標簽 y的值為(0 或 1),假設模型預測為正類的概率為 ?,則:
如果如果
所以:
示例:
import torch import torch.nn as nn ? # y 是模型的輸出,已經被sigmoid處理過,確保其值域在(0,1) y = torch.tensor([[0.7], [0.2], [0.9], [0.7]]) # targets 是真實的標簽,0或1 t = torch.tensor([[1], [0], [1], [0]], dtype=torch.float) ? # 計算損失方式一: bceLoss = nn.BCELoss() loss1 = bceLoss(y, t) ? #計算損失方式二: 兩種方式結果相同 loss2 = nn.functional.binary_cross_entropy(y, t) ? print(loss1, loss2)
逐樣本計算
| 樣本 | y_i | t_i | 計算項 ? |
|---|---|---|---|
| 1 | 0.7 | 1 | 1*log(0.7) + 0*log(0.3) ≈ -0.3567 |
| 2 | 0.2 | 0 | 0*log(0.2) + 1*log(0.8) ≈ -0.2231 |
| 3 | 0.9 | 1 | 1*log(0.9) + 0*log(0.1) ≈ -0.1054 |
| 4 | 0.7 | 0 | 0*log(0.7) + 1*log(0.3) ≈ -1.2040 |
計算最終損失
4. 總結
-
當輸出層使用softmax多分類時,使用交叉熵損失函數;
-
當輸出層使用sigmoid二分類時,使用二分類交叉熵損失函數, 比如在邏輯回歸中使用;
-
當功能為線性回歸時,使用均方差損失-L2 loss;
六、反向傳播算法
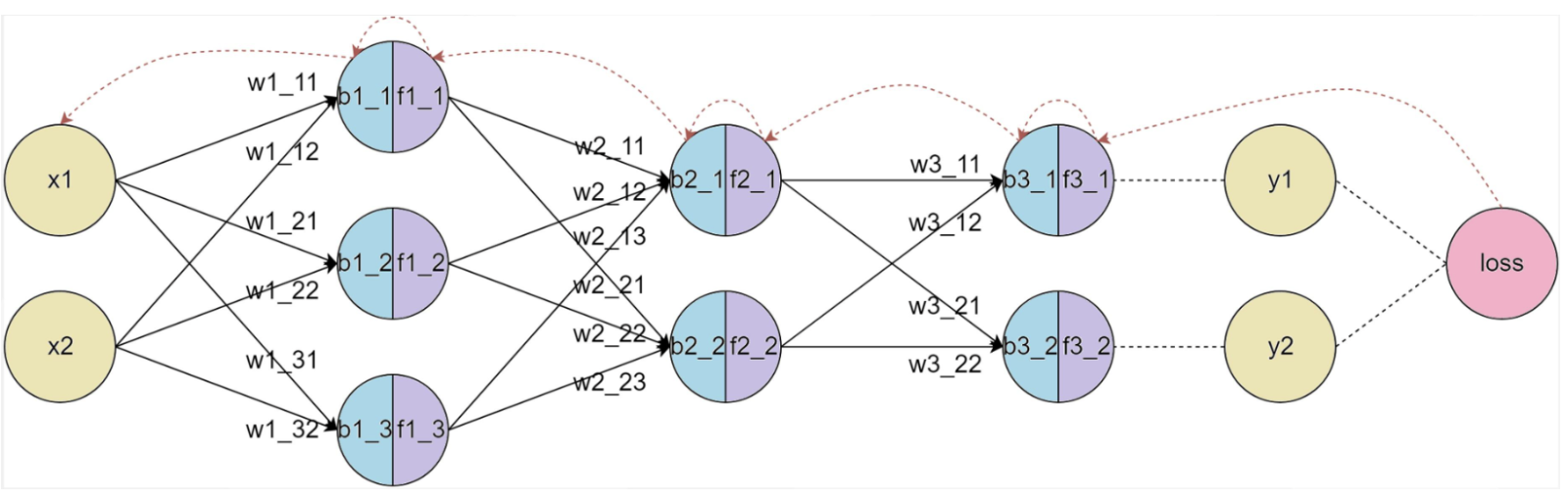 反向傳播(Back Propagation,簡稱BP)算法是用于訓練神經網絡的核心算法之一,它通過計算損失函數(如均方誤差或交叉熵)相對于每個權重參數的梯度,來優化神經網絡的權重。
反向傳播(Back Propagation,簡稱BP)算法是用于訓練神經網絡的核心算法之一,它通過計算損失函數(如均方誤差或交叉熵)相對于每個權重參數的梯度,來優化神經網絡的權重。
1. 前向傳播
前向傳播(Forward Propagation)把輸入數據經過各層神經元的運算并逐層向前傳輸,一直到輸出層為止。
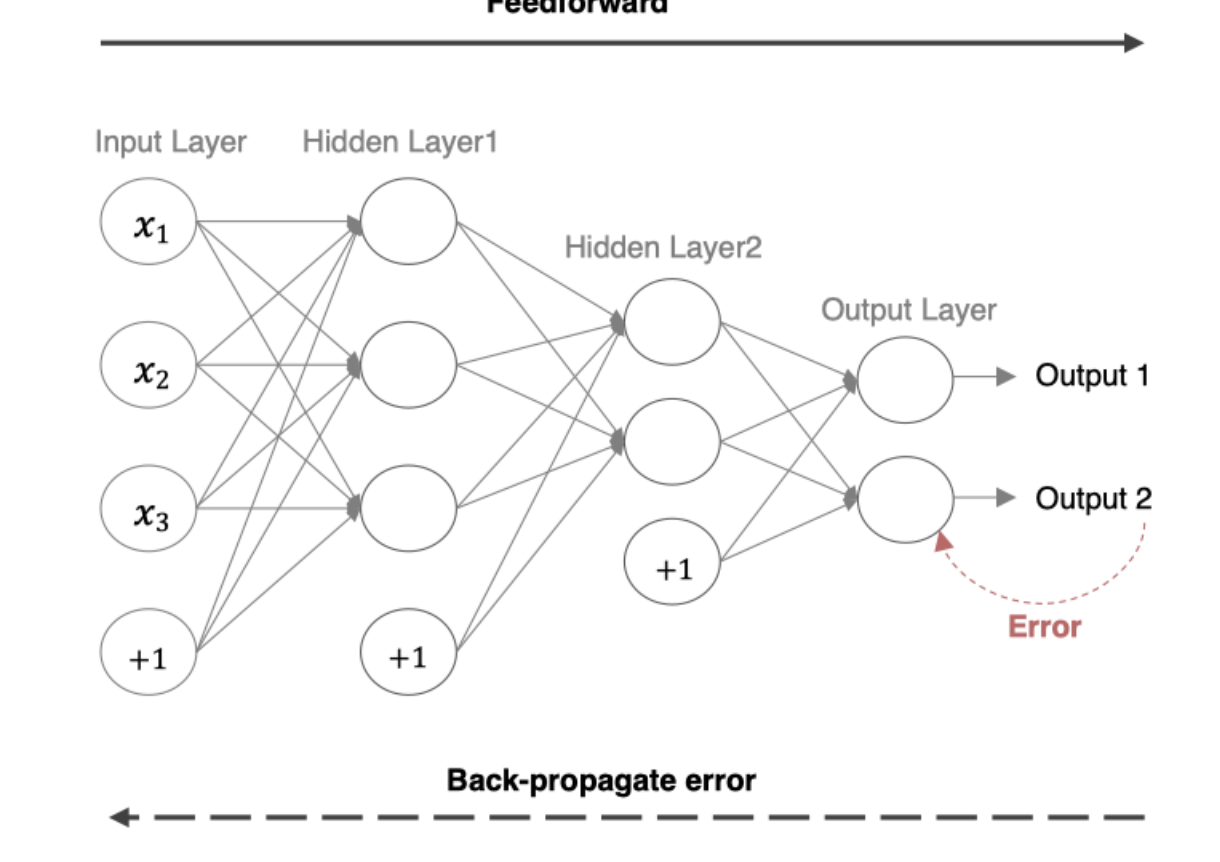 1.1 數學表達
1.1 數學表達
下面是一個簡單的三層神經網絡(輸入層、隱藏層、輸出層)前向傳播的基本步驟分析。
1.1.1 輸入層到隱藏層
給定輸入 ? 和權重矩陣 ? 及偏置向量 ?,隱藏層的輸出(激活值)計算如下:
將? 通過激活函數 ?進行激活:
1.1.2 隱藏層到輸出層
隱藏層的輸出 ? 通過輸出層的權重矩陣 ?和偏置 ? 生成最終的輸出:
輸出層的激活值 ? 是最終的預測結果:
1.2 作用
前向傳播的主要作用是:
-
計算神經網絡的輸出結果,用于預測或計算損失。
-
在反向傳播中使用,通過計算損失函數相對于每個參數的梯度來優化網絡。
2. BP基礎之梯度下降算法
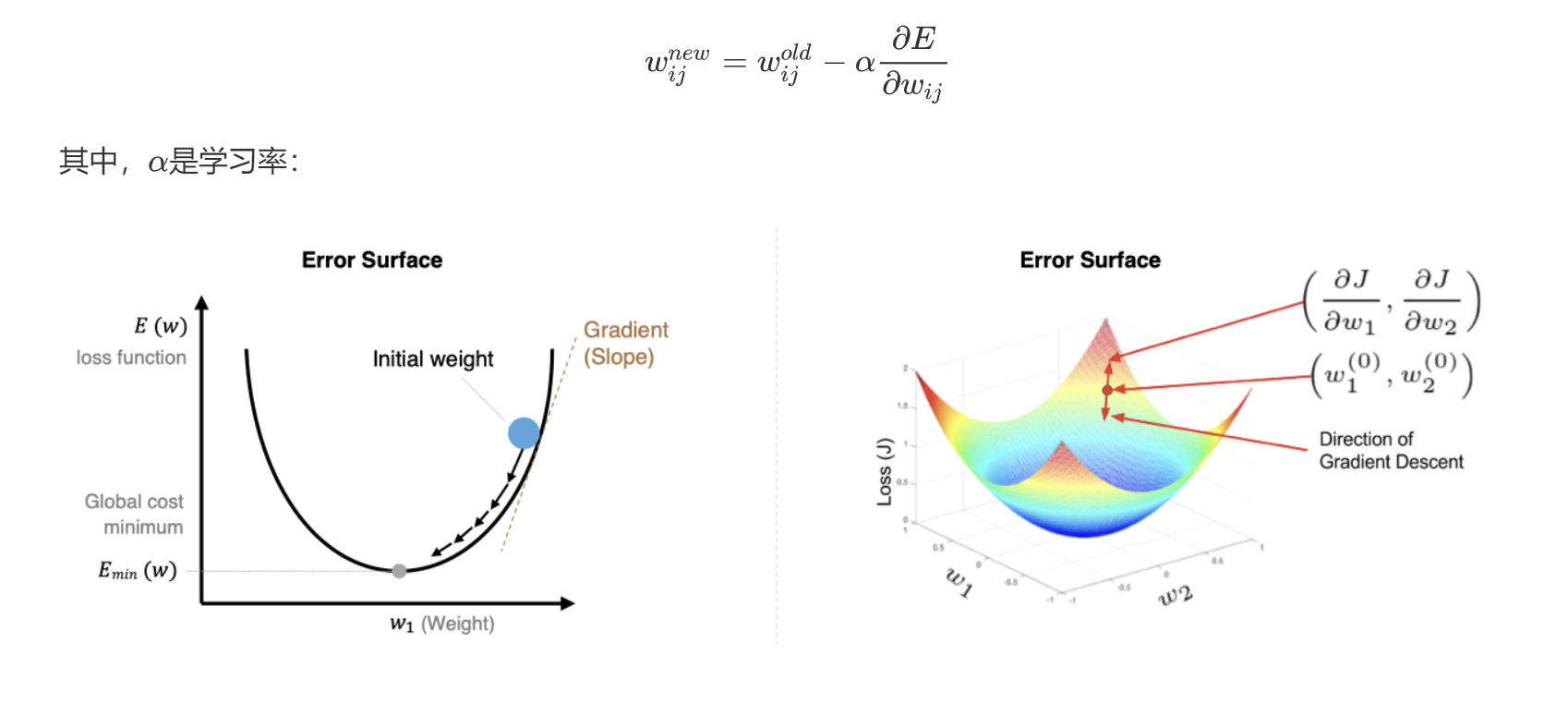
梯度下降算法的目標是找到使損失函數 ? 最小的參數 ?,其核心是沿著損失函數梯度的負方向更新參數,以逐步逼近局部或全局最優解,從而使模型更好地擬合訓練數據。
2.1 數學描述
簡單回顧下數學知識。
2.1.1 數學公式
其中,?是學習率:
-
學習率太小,每次訓練之后的效果太小,增加時間和算力成本。
-
學習率太大,大概率會跳過最優解,進入無限的訓練和震蕩中。
-
解決的方法就是,學習率也需要隨著訓練的進行而變化。
2.1.2 過程闡述
-
初始化參數:隨機初始化模型的參數 ?,如權重 ?和偏置 ?。
-
計算梯度:損失函數 ?對參數 ? 的梯度 ?,表示損失函數在參數空間的變化率。
-
更新參數:按照梯度下降公式更新參數:?,其中,? 是學習率,用于控制更新步長。
-
迭代更新:重復【計算梯度和更新參數】步驟,直到某個終止條件(如梯度接近0、不再收斂、完成迭代次數等)。
2.2 傳統下降方式
根據計算梯度時數據量不同,常見的方式有:
2. 2.1 批量梯度下降
Batch Gradient Descent BGD
-
特點:
-
每次更新參數時,使用整個訓練集來計算梯度。
-
-
優點:
-
收斂穩定,能準確地沿著損失函數的真實梯度方向下降。
-
適用于小型數據集。
-
-
缺點:
-
對于大型數據集,計算量巨大,更新速度慢。
-
需要大量內存來存儲整個數據集。
-
-
公式:
其中,? 是訓練集樣本總數,?是第 ? 個樣本及其標簽,?是第 ? 個樣本預測值。
例如,在訓練集中有100個樣本,迭代50輪。
那么在每一輪迭代中,都會一起使用這100個樣本,計算整個訓練集的梯度,并對模型更新。
所以總共會更新50次梯度。
因為每次迭代都會使用整個訓練集計算梯度,所以這種方法可以得到準確的梯度方向。
但如果數據集非常大,那么就導致每次迭代都很慢,計算成本就會很高。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)
?dataset = TensorDataset(x, y)dataloader = DataLoader(dataset, batch_size=len(dataset))
?model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)
?epochs = 100
?for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()
?print('Epoch %d, Loss: %f' % (epoch, loss.item()))
2.2.2 隨機梯度下降
Stochastic Gradient Descent, SGD
-
特點:
-
每次更新參數時,僅使用一個樣本來計算梯度。
-
-
優點:
-
更新頻率高,計算快,適合大規模數據集。
-
能夠跳出局部最小值,有助于找到全局最優解。
-
-
缺點:
-
收斂不穩定,容易震蕩,因為每個樣本的梯度可能都不完全代表整體方向。
-
需要較小的學習率來緩解震蕩。
-
-
公式:
其中,? 是當前隨機抽取的樣本及其標簽。
例如,如果訓練集有100個樣本,迭代50輪,那么每一輪迭代,會遍歷這100個樣本,每次會計算某一個樣本的梯度,然后更新模型參數。
換句話說,100個樣本,迭代50輪,那么就會更新100*50=5000次梯度。
因為每次只用一個樣本訓練,所以迭代速度會非常快。
但更新的方向會不穩定,這也導致隨機梯度下降,可能永遠都不會收斂。
不過也因為這種震蕩屬性,使得隨機梯度下降,可以跳出局部最優解。
這在某些情況下,是非常有用的。
示例:
? ?x = torch.randn(1000, 10)y = torch.randn(1000, 1)
?dataset = TensorDataset(x, y)dataloader = DataLoader(dataset, batch_size=1)
?model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)
?epochs = 100
?for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()
?print('Epoch %d, Loss: %f' % (epoch, loss.item()))
2.2.3 小批量梯度下降
Mini-batch Gradient Descent MGBD
-
特點:
-
每次更新參數時,使用一小部分訓練集(小批量)來計算梯度。
-
-
優點:
-
在計算效率和收斂穩定性之間取得平衡。
-
能夠利用向量化加速計算,適合現代硬件(如GPU)。
-
-
缺點:
-
選擇適當的批量大小比較困難;批量太小則接近SGD,批量太大則接近批量梯度下降。
-
通常會根據硬件算力設置為32\64\128\256等2的次方。
-
-
公式:
其中,? 是小批量的樣本數量,也就是 ?。
例如,如果訓練集中有100個樣本,迭代50輪。
如果設置小批量的數量是20,那么在每一輪迭代中,會有5次小批量迭代。
換句話說,就是將100個樣本分成5個小批量,每個小批量20個數據,每次迭代用一個小批量。
因此,按照這樣的方式,會對梯度,進行50輪*5個小批量=250次更新。
示例:
? ?x = torch.randn(1000, 10)y = torch.randn(1000, 1)
?dataset = TensorDataset(x, y)# 小批量梯度下降,每批次100個樣本dataloader = DataLoader(dataset, batch_size=100, shuffle=True)
?model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)
?epochs = 100
?for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()
?print('Epoch %d, Loss: %f' % (epoch, loss.item()))
2.3 存在的問題
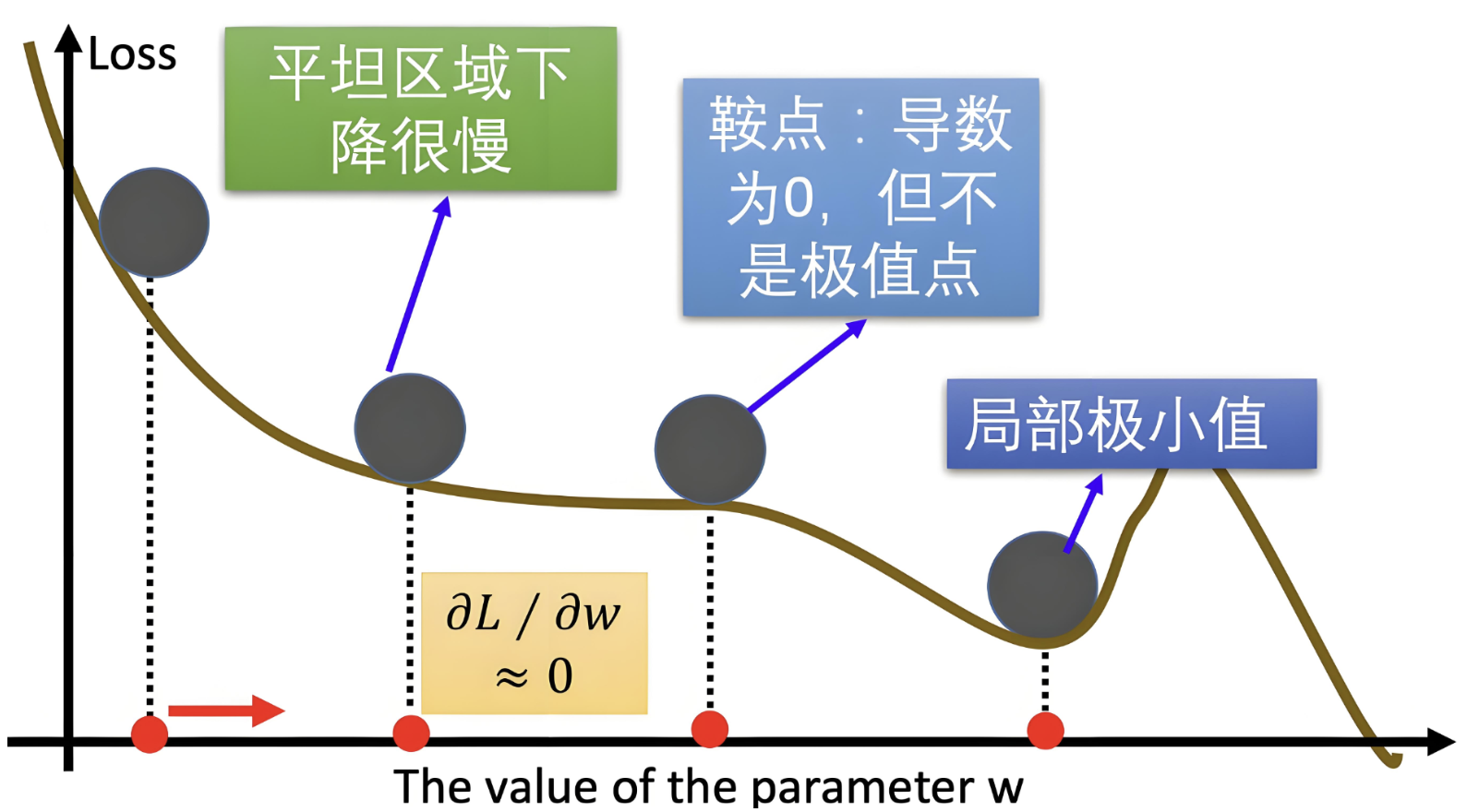
-
收斂速度慢:BGD和MBGD使用固定學習率,太大會導致震蕩,太小又收斂緩慢。
-
局部最小值和鞍點問題:SGD在遇到局部最小值或鞍點時容易停滯,導致模型難以達到全局最優。
-
訓練不穩定:SGD中的噪聲容易導致訓練過程中不穩定,使得訓練陷入震蕩或不收斂。
2.4 優化下降方式
通過對標準的梯度下降進行改進,來提高收斂速度或穩定性。
2.4.1 指數加權平均
我們平時說的平均指的是將所有數加起來除以數的個數,很單純的數學。再一個是移動平均數,指的是計算最近鄰的?個數來獲得平均數,感覺比純粹的直接全部求均值高級一點。
指數加權平均:Exponential Moving Average,簡稱EMA,是一種平滑時間序列數據的技術,它通過對過去的值賦予不同的權重來計算平均值。與簡單移動平均不同,EMA賦予最近的數據更高的權重,較遠的數據則權重較低,這樣可以更敏感地反映最新的變化趨勢。
比如今天股市的走勢,和昨天發生的國際事件關系很大,和6個月前發生的事件關系相對肯定小一些。
給定時間序列?,EMA在每個時刻 ? 的值可以通過以下遞推公式計算:
當?時:
當?時:
其中:
-
? 是第 ? 時刻的EMA值;
-
? 是第 ? 時刻的觀測值;
-
? 是平滑系數,取值范圍為 ?。? 越接近 ?,表示對歷史數據依賴性越高;越接近 ? 則越依賴當前數據。
公式推導:
那么:
從上述公式可知:
-
當 β接近 1 時,?衰減較慢,因此歷史數據的權重較高。
-
當 β接近 0 時,?衰減較快,因此歷史數據的權重較低。
示例
假設我們有一組數據 x=[1,2,3,4,5],我們選擇 β=0.1和β=0.9 來計算 EMA。
(1)β=0.1
-
初始化:
?
-
計算后續值:
最終,EMA 的值為 [1,1.9,2.89,3.889,4.8889]。
(2)β=0.9
-
初始化:
?
-
計算后續值:
最終,EMA 的值為 [1,1.1,1.29,1.561,1.9049]。
可以看到:
-
當 β=0.9 時,歷史數據的權重較高,平滑效果較強。EMA值變化緩慢(新數據僅占10%權重),滯后明顯。
-
當 β=0.1時,近期數據的權重較高,平滑效果較弱。EMA值快速逼近最新數據(每次新數據占90%權重)。
2.4.2 Momentum
動量(Momentum)是對梯度下降的優化方法,可以更好地應對梯度變化和梯度消失問題,從而提高訓練模型的效率和穩定性。它通過引入 指數加權平均 來積累歷史梯度信息,從而在更新參數時形成“動量”,幫助優化算法更快地越過局部最優或鞍點。
梯度更新算法包括兩個步驟:
a. 更新動量項
首先計算當前的動量項 ?: ? 其中:
-
? 是之前的動量項;
-
? 是動量系數(通常為 0.9);
-
? 是當前的梯度;
b. 更新參數
利用動量項更新參數:
特點:
-
慣性效應: 該方法加入前面梯度的累積,這種慣性使得算法沿著當前的方向繼續更新。如遇到鞍點,也不會因梯度逼近零而停滯。
-
減少震蕩: 該方法平滑了梯度更新,減少在鞍點附近的震蕩,幫助優化過程穩定向前推進。
-
加速收斂: 該方法在優化過程中持續沿著某個方向前進,能夠更快地穿越鞍點區域,避免在鞍點附近長時間停留。
在方向上的作用:
(1)梯度方向一致時
-
如果梯度在多個連續時刻方向一致(例如,一直指向某個方向),Momentum 會逐漸積累動量,使更新速度加快。
-
例如,假設梯度在多個時刻都是正向的,動量 ? 會逐漸增大,從而加速參數更新。
(2)梯度方向不一致時
-
如果梯度方向在不同時刻不一致(例如,來回震蕩),Momentum 會通過積累的歷史梯度信息部分抵消這些震蕩。
-
例如,假設梯度在一個時刻是正向的,下一個時刻是負向的,動量 ? 會平滑這些變化,使更新路徑更加穩定。
(3)局部最優或鞍點附近
-
在局部最優或鞍點附近,梯度可能會變得很小,導致標準梯度下降法停滯。
-
Momentum 通過積累歷史梯度信息,可以幫助參數更新越過這些平坦區域。
動量方向與梯度方向一致
(1)梯度方向一致時
-
如果梯度在多個連續時刻方向一致(例如,一直指向某個方向),動量會逐漸積累,動量方向與梯度方向一致。
-
例如,假設梯度在多個時刻都是正向的,動量 ? 會逐漸增大,從而加速參數更新。
(2)幾何意義
-
在優化問題中,如果損失函數的幾何形狀是 平滑且單調 的(例如,一個狹長的山谷),梯度方向會保持一致。
-
在這種情況下,動量方向與梯度方向一致,Momentum 會加速參數更新,幫助算法更快地收斂。
動量方向與梯度方向不一致
(1)梯度方向不一致時
-
如果梯度方向在不同時刻不一致(例如,來回震蕩),動量方向可能會與當前梯度方向不一致。
-
例如,假設梯度在一個時刻是正向的,下一個時刻是負向的,動量 ? 會平滑這些變化,使更新路徑更加穩定。
(2)幾何意義
-
在優化問題中,如果損失函數的幾何形狀是 復雜且非凸 的(例如,存在多個局部最優或鞍點),梯度方向可能會在不同時刻發生劇烈變化。
-
在這種情況下,動量方向與梯度方向可能不一致,Momentum 會通過積累的歷史梯度信息部分抵消這些震蕩,使更新路徑更加平滑。
總結:
-
動量項更新:利用當前梯度和歷史動量來計算新的動量項。
-
權重參數更新:利用更新后的動量項來調整權重參數。
-
梯度計算:在每個時間步計算當前的梯度,用于更新動量項和權重參數。
Momentum 算法是對梯度值的平滑調整,但是并沒有對梯度下降中的學習率進行優化。
示例:
# 定義模型和損失函數
model = nn.Linear(10, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) ?# PyTorch 中 momentum 直接作為參數
?
# 模擬數據
X = torch.randn(100, 10)
y = torch.randn(100, 1)
?
# 訓練循環
for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
2.4.3 AdaGrad
AdaGrad(Adaptive Gradient Algorithm)為每個參數引入獨立的學習率,它根據歷史梯度的平方和來調整這些學習率。具體來說,對于頻繁更新的參數,其學習率會逐漸減小;而對于更新頻率較低的參數,學習率會相對較大。AdaGrad避免了統一學習率的不足,更多用于處理稀疏數據和梯度變化較大的問題。
AdaGrad流程:
-
初始化:
-
初始化參數 ? 和學習率 ?。
-
將梯度累積平方的向量 ? 初始化為零向量。
-
-
梯度計算:
-
在每個時間步 ?,計算損失函數?對參數 ? 的梯度?。
-
-
累積梯度的平方:
-
對每個參數 ?累積梯度的平方:
其中? 是累積的梯度平方和,? 是第?個參數在時間步? 的梯度。
推導:
-
-
參數更新:
-
利用累積的梯度平方來更新參數:
-
其中:
-
? 是全局的初始學習率。
-
? 是一個非常小的常數,用于避免除零操作(通常取?)。
-
? 是自適應調整后的學習率。
-
-
AdaGrad 為每個參數分配不同的學習率:
-
對于梯度較大的參數,Gt較大,學習率較小,從而避免更新過快。
-
對于梯度較小的參數,Gt較小,學習率較大,從而加快更新速度。
可以將 AdaGrad 類比為:
-
梯度較大的參數:類似于陡峭的山坡,需要較小的步長(學習率)以避免跨度過大。
-
梯度較小的參數:類似于平緩的山坡,可以采取較大的步長(學習率)以加快收斂。
優點:
-
自適應學習率:由于每個參數的學習率是基于其梯度的累積平方和 ? 來動態調整的,這意味著學習率會隨著時間步的增加而減少,對梯度較大且變化頻繁的方向非常有用,防止了梯度過大導致的震蕩。
-
適合稀疏數據:AdaGrad 在處理稀疏數據時表現很好,因為它能夠自適應地為那些較少更新的參數保持較大的學習率。
缺點:
-
學習率過度衰減:隨著時間的推移,累積的時間步梯度平方值越來越大,導致學習率逐漸接近零,模型會停止學習。
-
不適合非稀疏數據:在非稀疏數據的情況下,學習率過快衰減可能導致優化過程早期停滯。
AdaGrad是一種有效的自適應學習率算法,然而由于學習率衰減問題,我們會使用改 RMSProp 或 Adam 來替代。
示例:
? ?# 定義模型和損失函數model = torch.nn.Linear(10, 1)criterion = torch.nn.MSELoss()optimizer = torch.optim.Adagrad(model.parameters(), lr=0.01)
?# 模擬數據X = torch.randn(100, 10)y = torch.randn(100, 1)
?# 訓練循環for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item()}')
2.4.4 RMSProp
雖然 AdaGrad 能夠自適應地調整學習率,但隨著訓練進行,累積梯度平方 ?會不斷增大,導致學習率逐漸減小,最終可能變得過小,導致訓練停滯。
RMSProp(Root Mean Square Propagation)是一種自適應學習率的優化算法,在時間步中,不是簡單地累積所有梯度平方和,而是使用指數加權平均來逐步衰減過時的梯度信息。旨在解決 AdaGrad 學習率單調遞減的問題。它通過引入 指數加權平均 來累積歷史梯度的平方,從而動態調整學習率。
公式為:
其中:
-
?是當前時刻的指數加權平均梯度平方。
-
β是衰減因子,通常取 0.9。
-
η是初始學習率。
-
?是一個小常數(通常取 ?),用于防止除零。
-
?是當前時刻的梯度。
優點
-
適應性強:RMSProp自適應調整每個參數的學習率,對于梯度變化較大的情況非常有效,使得優化過程更加平穩。
-
適合非稀疏數據:相比于AdaGrad,RMSProp更加適合處理非稀疏數據,因為它不會讓學習率減小到幾乎為零。
-
解決過度衰減問題:通過引入指數加權平均,RMSProp避免了AdaGrad中學習率過快衰減的問題,保持了學習率的穩定性
缺點
依賴于超參數的選擇:RMSProp的效果對衰減率 ? 和學習率 ? 的選擇比較敏感,需要一些調參工作。
示例:
? ?# 定義模型和損失函數model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01, alpha=0.9, eps=1e-8)
?# 模擬數據X = torch.randn(100, 10)y = torch.randn(100, 1)
?# 訓練循環for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
2.4.5 Adam
Adam(Adaptive Moment Estimation)算法將動量法和RMSProp的優點結合在一起:
-
動量法:通過一階動量(即梯度的指數加權平均)來加速收斂,尤其是在有噪聲或梯度稀疏的情況下。
-
RMSProp:通過二階動量(即梯度平方的指數加權平均)來調整學習率,使得每個參數的學習率適應其梯度的變化。
Adam過程
-
初始化:
-
初始化參數 ? 和學習率?。
-
初始化一階動量估計 ? 和二階動量估計?。
-
設定動量項的衰減率 ? 和二階動量項的衰減率?,通常 ?,?。
-
設定一個小常數?(通常取?),用于防止除零錯誤。
-
-
梯度計算:
-
在每個時間步 ?,計算損失函數? 對參數? 的梯度?。
-
-
一階動量估計(梯度的指數加權平均):
-
更新一階動量估計:
其中,? 是當前時間步 ? 的一階動量估計,表示梯度的指數加權平均。
-
-
二階動量估計(梯度平方的指數加權平均):
-
更新二階動量估計:
其中,? 是當前時間步 ? 的二階動量估計,表示梯度平方的指數加權平均。
-
-
偏差校正:
由于一階動量和二階動量在初始階段可能會有偏差,以二階動量為例:
在計算指數加權移動平均時,初始化 ?,那么?,得到?,顯然得到的 ? 會小很多,導致估計的不準確,以此類推:
根據:?,把 ? 帶入后, 得到:?,導致 ? 遠小于 ? 和 ?,所以 ? 并不能很好的估計出前兩次訓練的梯度。
所以這個估計是有偏差的。
使用以下公式進行偏差校正:
其中,? 和? 是校正后的一階和二階動量估計。
-
參數更新:
-
使用校正后的動量估計更新參數:
-
優點
-
高效穩健:Adam結合了動量法和RMSProp的優勢,在處理非靜態、稀疏梯度和噪聲數據時表現出色,能夠快速穩定地收斂。
-
自適應學習率:Adam通過一階和二階動量的估計,自適應調整每個參數的學習率,避免了全局學習率設定不合適的問題。
-
適用大多數問題:Adam幾乎可以在不調整超參數的情況下應用于各種深度學習模型,表現良好。
缺點
-
超參數敏感:盡管Adam通常能很好地工作,但它對初始超參數(如 ?、? 和 ?)仍然較為敏感,有時需要仔細調參。
-
過擬合風險:由于Adam會在初始階段快速收斂,可能導致模型陷入局部最優甚至過擬合。因此,有時會結合其他優化算法(如SGD)使用。
2.5 總結
梯度下降算法通過不斷更新參數來最小化損失函數,是反向傳播算法中計算權重調整的基礎。在實際應用中,根據數據的規模和計算資源的情況,選擇合適的梯度下降方式(批量、隨機、小批量)及其變種(如動量法、Adam等)可以顯著提高模型訓練的效率和效果。
Adam是目前最為流行的優化算法之一,因其穩定性和高效性,廣泛應用于各種深度學習模型的訓練中。Adam結合了動量法和RMSProp的優點,能夠在不同情況下自適應調整學習率,并提供快速且穩定的收斂表現。
示例:
? ?# 定義模型和損失函數model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.9, 0.999), eps=1e-8)
?# 模擬數據X = torch.randn(100, 10)y = torch.randn(100, 1)
?# 訓練循環for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
結合osg及osgEarth實現三維球經緯網格繪制及顯隱)









![[C]基礎11.深入理解指針(3)](http://pic.xiahunao.cn/[C]基礎11.深入理解指針(3))
)
)


(ArkTs))

報告》)

