嘿,各位技術潮人!好久不見甚是想念。生活就像一場奇妙冒險,而編程就是那把超酷的萬能鑰匙。此刻,陽光灑在鍵盤上,靈感在指尖跳躍,讓我們拋開一切束縛,給平淡日子加點料,注入滿滿的passion。準備好和我一起沖進代碼的奇幻宇宙了嗎?Let's go!
我的博客:yuanManGan
我的專欄:C++入門小館?C言雅韻集?數據結構漫游記? 閑言碎語小記坊?題山采玉?領略算法真諦


目錄
string的成員變量
成員變量
c_str和size( ),capacity( )
默認成員函數:
string的默認構造
無參構造:
帶參構造:?
string的析構函數:
string 的拷貝構造:
賦值運算符重載:
尾插相關操作
string 的reserve(擴容)
string的push_back
string的append(追加字符串)
string重載運算符+=
string的遍歷:
重載[ ]:
迭代器:
范圍for:
string 在任意位置插入刪除?
insert
?編輯erase?
?編輯?string中的查找和裁剪
find:
?substr:
?補充拷貝構造和賦值運算符重載的現代寫法:
swap
拷貝構造
迭代區間構造
重載賦值運算符
流插入流提取操作符的重載
cout
?編輯
cin
clear
本章來模擬實現一下string類,不是按照模板實現,而是按照容易理解的實現。
string的成員變量
我們的string類本質還是字符數組,但我們可以動態開辟,用_str字符指針來指向數組,我們還需要知道數組的空間大小,以及有效字符個數,跟之前實現的順序表有點類似,但這里用類來實現。
我們將string放在一個命名空間里面,以防和庫里的沖突。
namespace refrain
{class string{public:private:char* _str;size_t _size;size_t _capacity;};
}成員變量
c_str和size( ),capacity( )
這里為了方便打印,我們先實現這個返回c類型的字符串,就是j將_str返回,隨便也實現另外倆個成員變量的返回
我們將聲明與定義分離,寫在不同的文件里。
const char* string::c_str() const
{return _str;
}
size_t string::capacity() const
{return _capacity;
}
size_t string::size() const
{return _size;
}默認成員函數:
string的默認構造
無參構造:
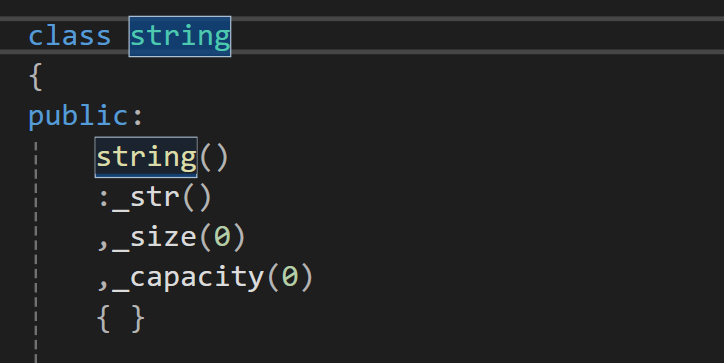
_size 和_capacity好處理,都是0但_str應該初始化為什么,是空指針還是什么,不如看看庫里面是怎么實現的?
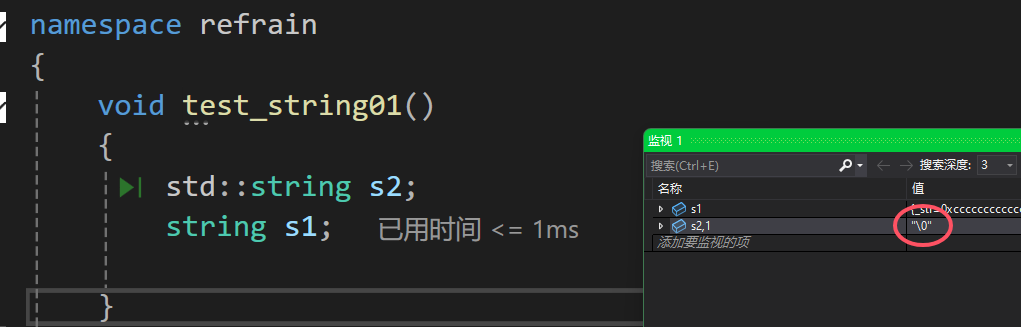
庫里面是'\0'那我們就按照它的來實現吧!那就意味著我們一開始就得開一個'\0'的空間。但我們的capacity和size不要記錄這個'\0'的空間。
string()
:_str(new char[1]{'\0'})
,_size(0)
,_capacity(0)
{ }帶參構造:?
我們帶參構造就將傳入的參數直接拷貝過去就好了。
string(const char* str):_str(new char[strlen(str) + 1]),_size(strlen(str)),_capacity(strlen(str))
{memcpy(_str, str, _size + 1);
}看看這種寫法,用了三次strlen時間成本大大提高了,我們可不可以在初始化列表先將_size初始化,然后復用_size呢??
我們試試:
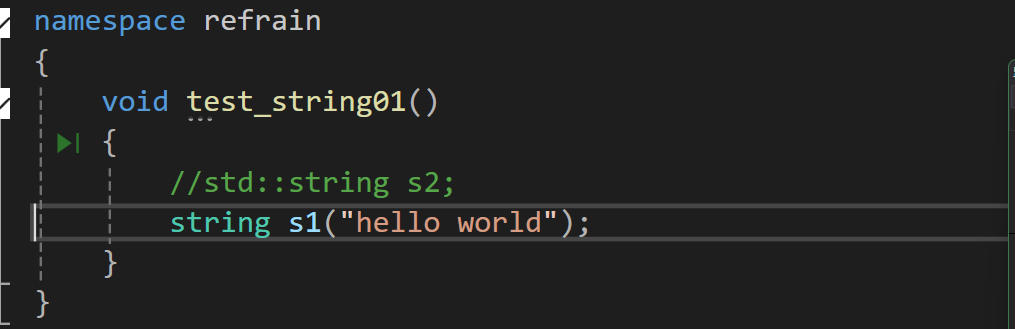

這里為什么_str沒有創建空間呢?我們回憶一下初始化列表是按照怎么順序,對是按照變量聲明的順序,我們先聲明的_str,但此時_size還未初始化,_size的值看編譯器實現,這里vs將_size初始化為了0,所以只有一個空間。
那有同學就要說了,那我們將聲明順序改一下能不能實現呢,我們試試。

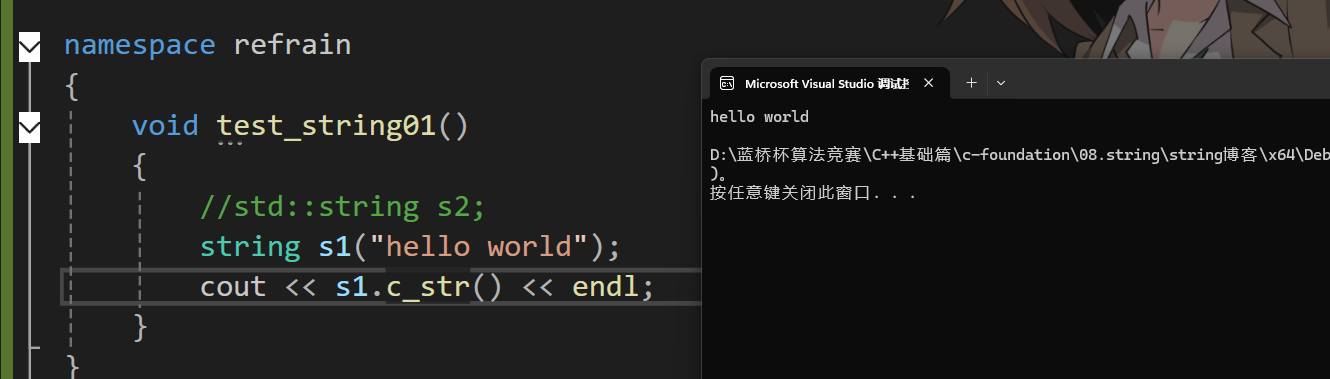
ok了,但這樣真的好嗎,你這不是自己給自己埋雷嗎,萬一別人不知道,在這里亂改一下,那怎么辦?
我們可以考慮只在初始化列表初始化_size讓_str和_capacity走初始化函數。
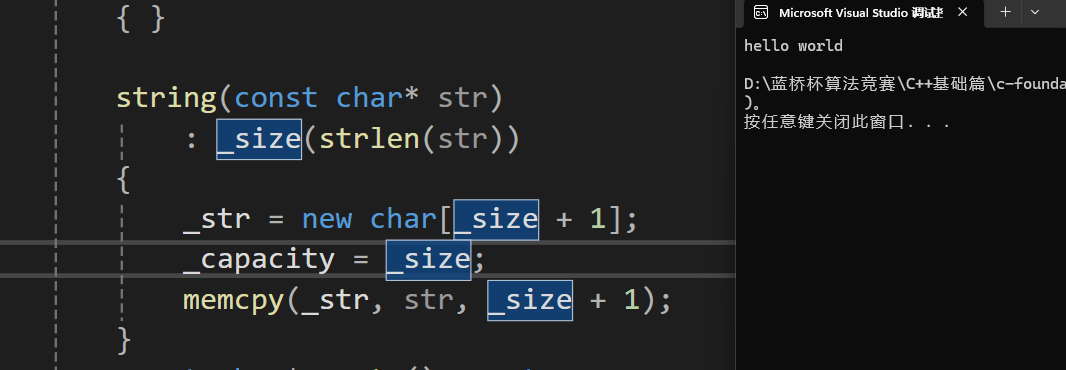
依舊ok。
還有個問題,我們可不可以給缺省值,就不用寫默認無參構造了?
最終版本:
string(const char* str = ""):_size(strlen(str))
{_str = new char[_size + 1];_capacity = _size;memcpy(_str, str, _size + 1);
}string的析構函數:
這個就簡單了,但要判斷一下,如果_str為空就不能析構
~string()
{if (_str){delete[] _str;_str = nullptr;_size = _capacity = 0;}
}string 的拷貝構造:
//傳統寫法
string::string(const string& s)
{_str = new char[s._capacity + 1];memcpy(_str, s._str, s._size + 1);_size = s._size;_capacity = s._capacity;
}賦值運算符重載:
// s1 = s2
string& string::operator=(const string& s)
{if (this != &s){char* tmp = new char[s._capacity + 1];memcpy(tmp, s._str, s._size + 1);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;}return *this;
}尾插相關操作
string 的reserve(擴容)
擴容是一個會頻繁調用的操作,所以我們先來實現一下這個操作。

這是庫里實現的。
void reserve(size_t n);
?先在string.h寫個聲明,在string.cpp里實現這個函數。我們要將容量擴容到n,如果n>capacity,就直接新創建一塊空間然后拷貝,有人說不能用relloc嗎,我的建議是不要使用,因為relloc擴容擴的空間大了,也是重新創建一塊空間進行擴容,然后拷貝。
那如果n <capacity呢,我們看編譯器,可能縮容,但一般不縮容,我們就不實現這個了,縮容是典型的以時間換空間的案例。
void string::reserve(size_t n)
{if (n > _capacity){//注意這里是n+1給'\0'留一點空間char* tmp = new char[n + 1];//要判斷_str是否為nullptr對空指針解引用要報錯if (_str){memcpy(tmp, _str, _size + 1);delete[] _str;}_str = tmp;_capacity = n;}
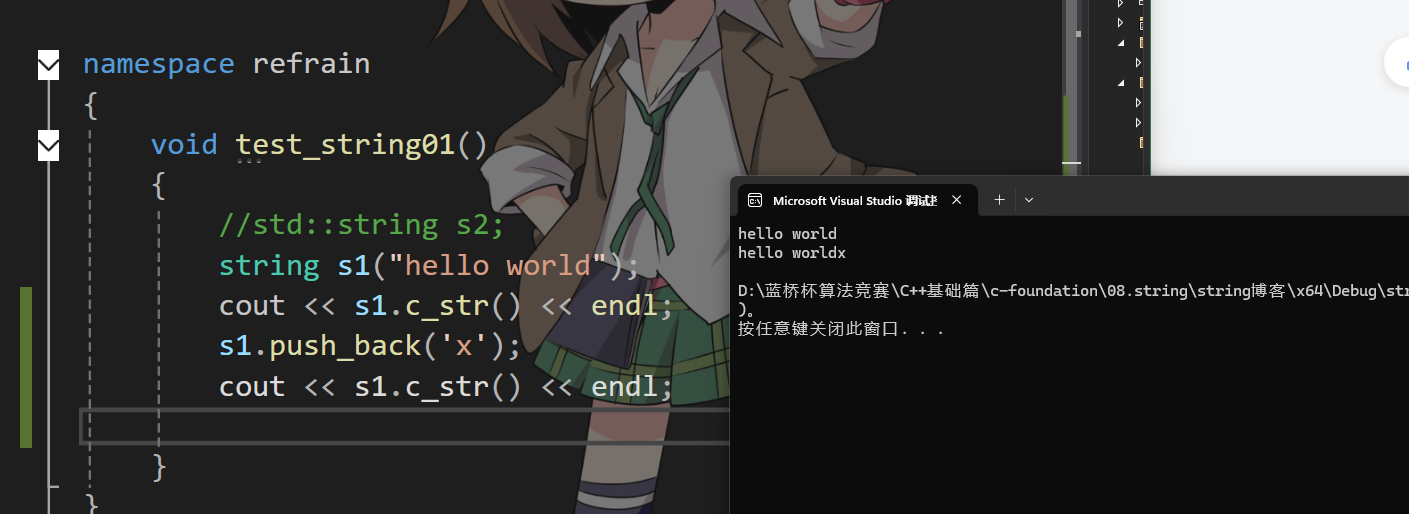
}string的push_back
加入函數得先判斷一下是否需要擴容,當_size == _capacity 時需要擴容。然后將最后一個字符改成要加入的值,再將_size++最后將最后一個位置弄成'\0'
void string::push_back(char ch)
{if (_size == _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;reserve(newcapacity);}_str[_size++] = ch;_str[_size] = '\0';
}
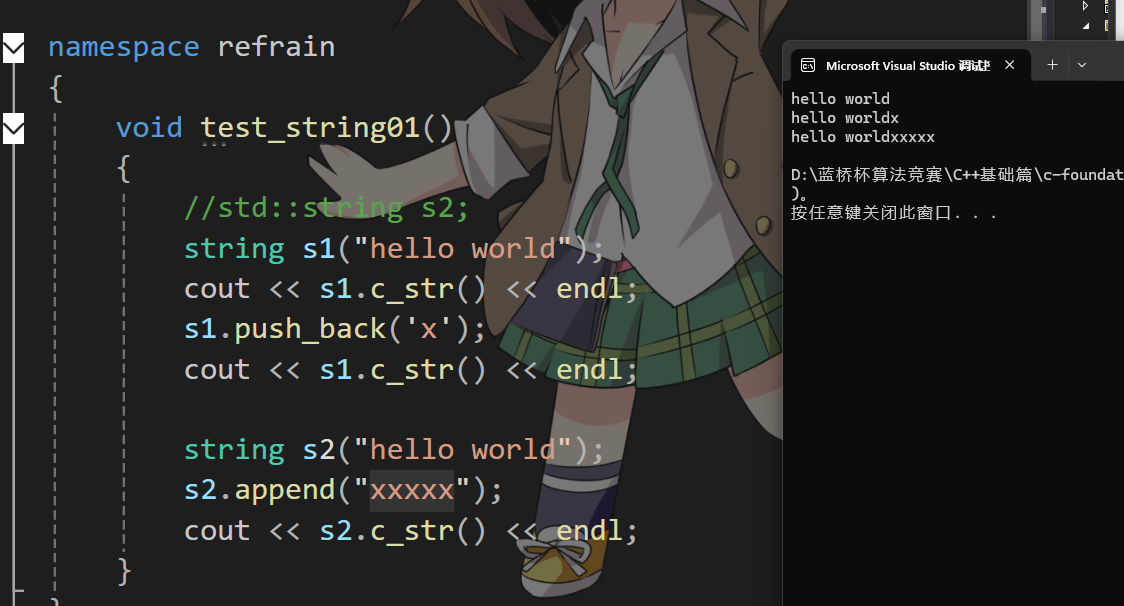
string的append(追加字符串)
這里的擴容邏輯就得考慮一下了,如果我們插入的字符串的長度是len,如果len + _size > _capaticy時才會擴容,我們是擴二倍,還是len + _size 呢,如果給多少擴多少時,我們會面臨一個問題:就是如果我們頻繁擴小字符串,就會頻繁擴容;如果我們擴二倍,如果我們擴容的字符串很大,len + _size > 2 * _capacity就出現了一個很嚴重的問題,我存的值不見了,就好比你去銀行存了幾百萬,結果一查就省幾十萬了,誰還敢存錢在你們銀行。
我們這里就得分類討論一下了,如果len+_size > 2*capacity,我們就擴容到len? +_size,沒有就擴到2倍。
void string::append(const char* str)
{size_t len = strlen(str);if (_size + len > _capacity){size_t newcapacity = _size + len > 2 * _capacity ? _size + len : 2 * _capacity;reserve(newcapacity);}memcpy(_str + _size, str, len + 1);_size += len;
}
string重載運算符+=
實現了push_back和append實現+=運算符就易如反掌了,只需要復用加重載就完成了。
string& string::operator+=(char ch)
{push_back(ch);return *this;
}
string& string::operator+=(const char* str)
{append(str);return *this;
}char& string::operator[](size_t i)
{return _str[i];
}
const char& string::operator[](size_t i) const
{return _str[i];
}我們再來實現一下string的遍歷吧
string的遍歷:
重載[ ]:
這個實現很簡單。直接返回*(_size + i);
char& string::operator[](size_t i)
{assert(i < _size);return _str[i];
}
const char& string::operator[](size_t i) const
{assert(i < _size);return _str[i];
}
迭代器:
這里實現迭代器就使用原生指針了,但底層實現不一定是原生指針,可能是其他的主要看編譯器想怎么實現。
string::iterator string::begin()
{return _str;
}
string::iterator string::end()
{return _str + _size;
}
string::const_iterator string::begin() const
{return _str;
}
string::const_iterator string::end() const
{return _str + _size;
}范圍for:
實現了迭代器就實現了范圍for,范圍for的實質就是替換為迭代器。
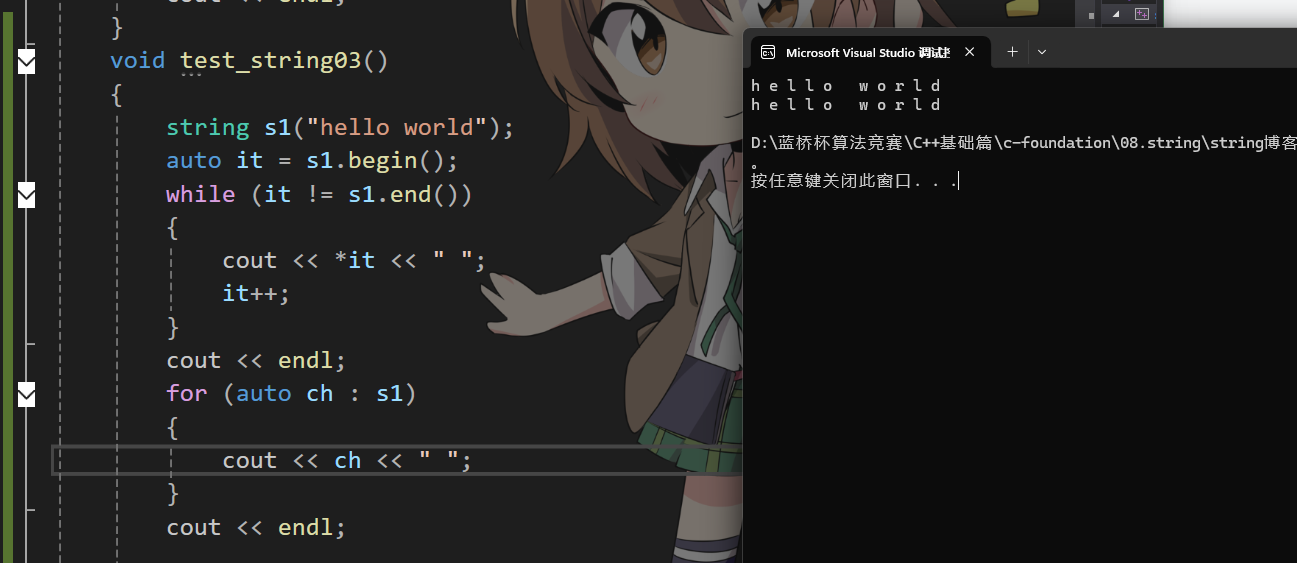
string 在任意位置插入刪除?
insert
insert有很多個版本,我們就實現其中比較實用的兩個吧,第二個就實現插入一個吧
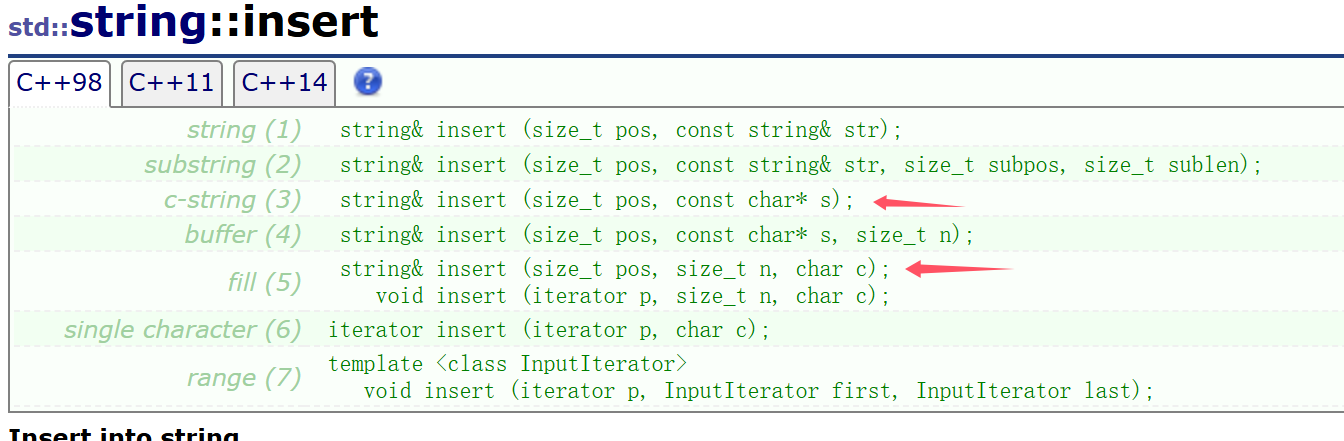
在pos位置插入一個字符:?
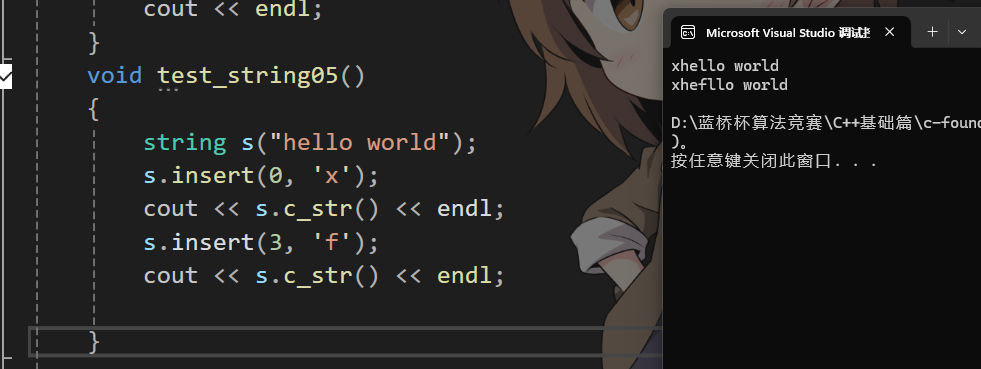
就將pos位置之后的字符全部向后挪一步,然后將pos位置改成插入的值。
void string::insert(size_t pos, char ch)
{assert(pos < _size);//判斷是否需要擴容if (_size == _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;reserve(newcapacity);}size_t end = _size + 1;while (pos < end){_str[end] = _str[end - 1];end--;}_str[pos] = ch;_size++;
}
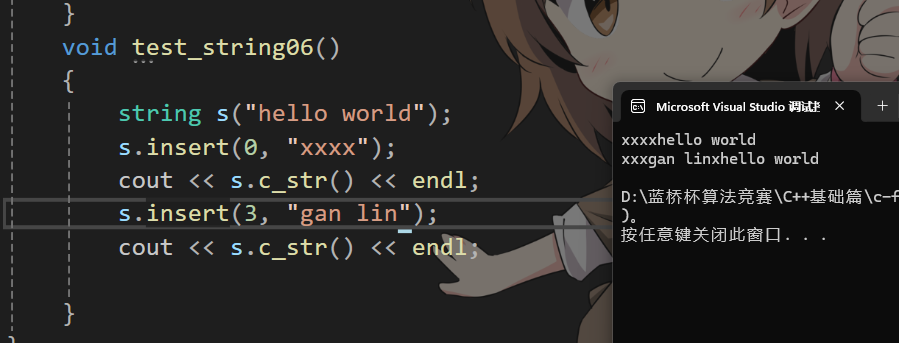
在任意位置插入字符串
void string::insert(size_t pos, const char* str)
{assert(pos < _size);size_t len = strlen(str);if (_size + len > _capacity){size_t newcapacity = _size + len > 2 * _capacity ? _size + len : 2 * _capacity;reserve(newcapacity);}size_t end = _size + len;while (end >= pos + len){_str[end] = _str[end - len];end--;}for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;
} erase?
erase?
任意位置刪除n個字符
這里得分類討論一下,如果刪的字符個數過多就等于把后面全刪了,這種情況比較好處理,當我們第二個參數不傳時,默認刪完,那我們該咋實現呢?對給缺省值給你npos我們得先定義一下npos,定義成const靜態成員變量
private:size_t _size;size_t _capacity;char* _str;static const size_t npos = -1;在c++這里可以這樣給缺省值哦。
?erase函數就成這樣了。
void erase(size_t pos, size_t len = npos);?注意聲明和定義不能同時給缺省值。
當刪不完的時候
我們可以使用c語言的庫函數memmove來移動數據(也是懶得實現了)
void string::erase(size_t pos, size_t len)
{assert(pos < _size);//刪完if (len == npos || pos + len >= _size){_str[pos] = '\0';_size = pos;}else {memmove(_str + pos, _str + pos + len, _size - (pos + len) + 1);_size -= len;}
} ?string中的查找和裁剪
?string中的查找和裁剪
find:

我們也是簡單實現這兩個哦
最后一個好實現直接遍歷一遍即可:
size_t string::find(char ch, size_t pos) const
{for (size_t i = 0; i < _size; i++){if (_str[i] == ch) return i;}return npos;
}
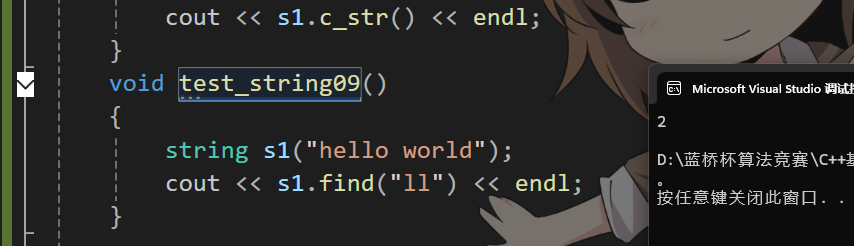
從第pos位置開始查找字符串sub返回最先的找到的下標
這里我們直接調用庫函數里面的strstr來查找。
size_t string::find(const char* sub, size_t pos) const
{assert(pos < _size);const char* p = strstr(_str + pos, sub);if (p == nullptr){return npos;}else{return p - _str;}
}
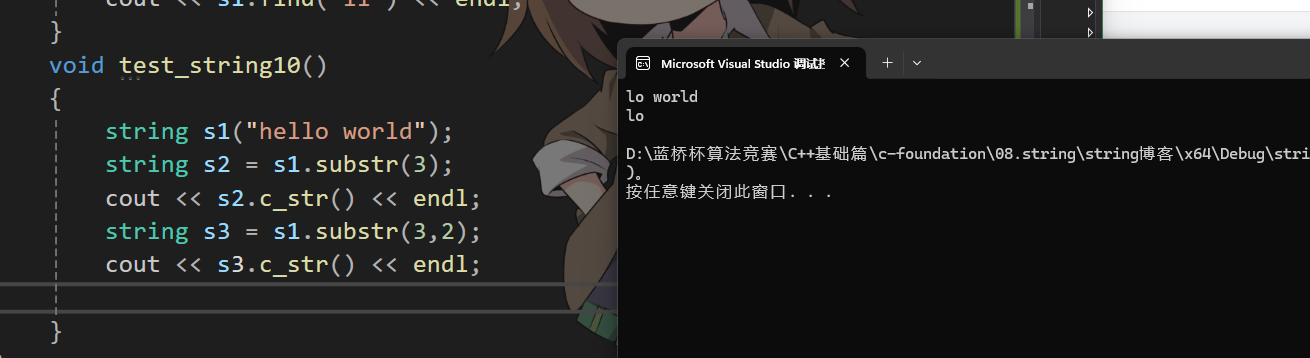
?substr:
創建一個string類型的ret,直接+=
string string::substr(size_t pos, size_t len)const
{assert(pos < _size);if (len > _size - pos){len = _size - pos;}string ret;ret.reserve(len);for (size_t i = 0; i < len; i++){ret += _str[pos + i];}return ret;
}
?補充拷貝構造和賦值運算符重載的現代寫法:
swap
我們先來實現一下swap函數,有人就要問了,庫里面不是有swap函數嗎
看看庫里面的swap
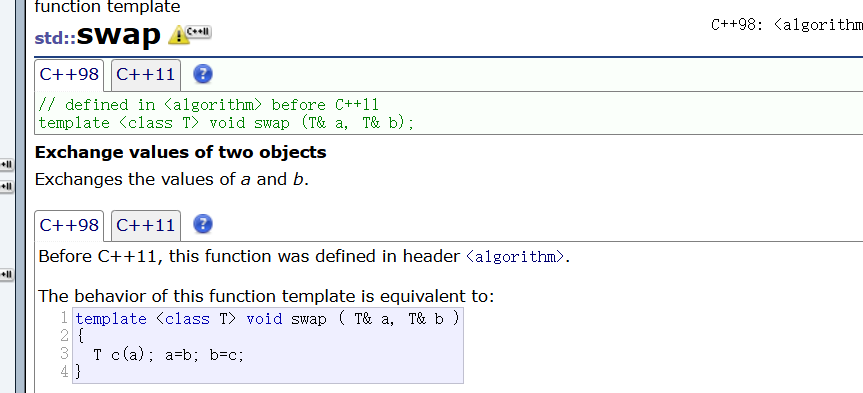
template <class T> void swap ( T& a, T& b )
{T c(a); a=b; b=c;
}看看這里是創建了一個c對象拷貝a對象,然后再賦值交換,要付出的代價有點太大了 。我們在string這個類中僅僅需要交換一下指針和_size 和_capacity就行了。
void string::swap(string& s)
{std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);
}注意這里的函數里面swap函數必須要制定std空間,不然會認為自己調用自己導致無限遞歸。
但我們學習C++的有兩種人,一種是只了解怎么使用string的,一種是像我們這樣深入學習string庫,了解底層原理,他們并不知道那種更高效,為了避免這種情況發生,我們編譯器會自動調用string庫里面的swap函數,無論你是下面那種代碼:
swap(s1, s2);
s1.swap(s2);?然后我們來實現一下構造函數:
我們可以將傳入的對象先默認構造一份然后交換給this
拷貝構造
string::string(const string& s)
{string tmp(s_str);swap(tmp);
}但當我們實現以下操作時得到的不是我們想要的答案?
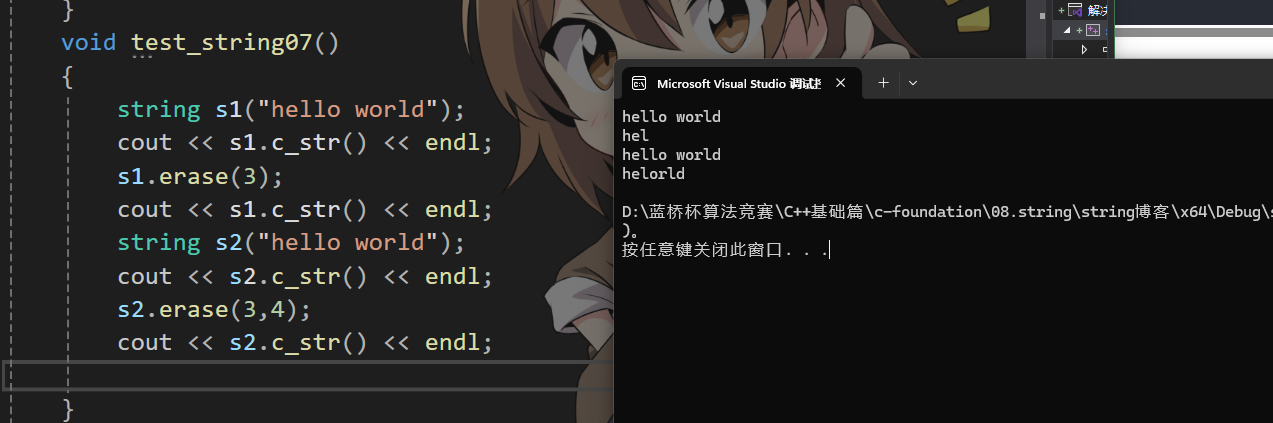
void test_string01(){string s1("hello world");s1 += '\0';s1 += "xxxxxx";string s2(s1);cout << s1 << endl;cout << s2 << endl;}為什么打印不了后面的呢?
問題出在了我們進入拷貝構造后,要將目標字符串默認構造一份,此時的默認構造除了問題,其中計算_size時只會計數到'\0',會導致出現問題。
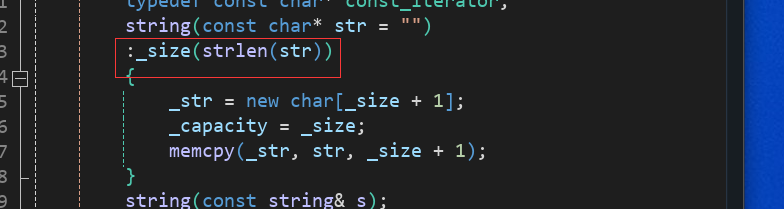
那我們咋解決呢?
在string中可以用迭代區間構造,需要使用模版,這里為什么要使用模版呢?有人說直接用string里面的迭代器不就好了。我們不只是可以使用string的迭代器,還可以用其他容器的迭代器。
迭代區間構造
template <class InputIterator>
string(InputIterator first, InputIterator last)
{while (first != last){push_back(*first);++first;}
}?我們將拷貝構造改成這樣就ok了。
string::string(const string& s)
{string tmp(s.begin(),s.end());swap(tmp);
}重載賦值運算符
賦值運算符也是同樣的思路
string& string::operator=(const string& s)
{string tmp(s.begin(), s.end());swap(s);return *this;
}還有一種更簡單的寫法?
string& string::operator=(string tmp)
{swap(tmp);return *this;
}我們這里自己傳值傳參,傳值傳參調用構造函數, 然后直接交換,返回*this,出作用于,tmp直接銷毀。
流插入流提取操作符的重載
cout
要將該重載定義在string類外。
這個實現就很簡單直接打印就行
ostream& operator<<(ostream& os,const string& s)
{for (auto& ch : s){os << ch;}return os;
}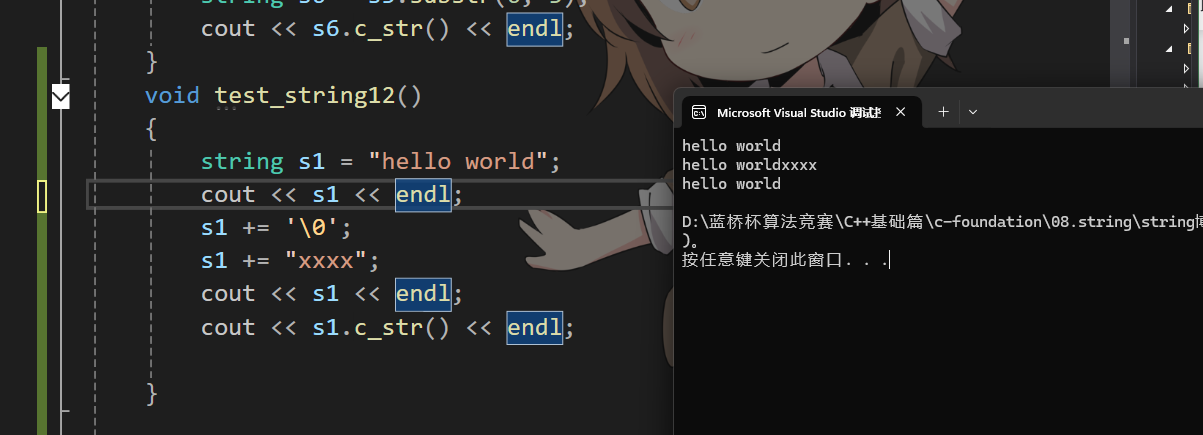
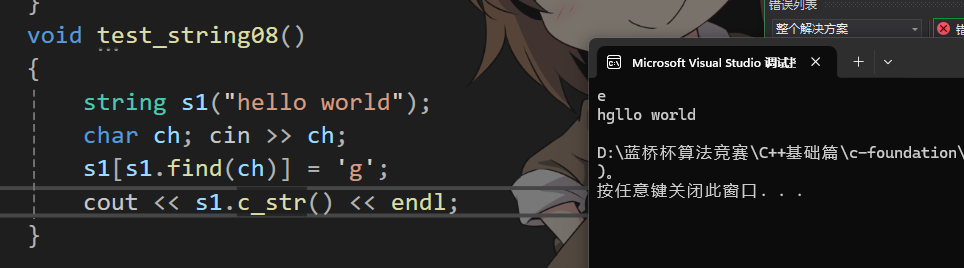
看這種情況,我們打印s1的c_str( )時出現了我們不想要的結果,這是為什么呢,c_str()返回的是c類型的字符串,而c類型的字符串它以'\0'為結尾,只要發現的'\0'就返回。
cin
我們先來簡單實現一個我們都愛犯的錯誤的代碼
istream& operator>>(istream& is, string& s)
{char ch; is >> ch;s += ch;while (ch != '\0' && ch != '\n'){is >> ch;s += ch;}return is;
}?
我們發現為什么一直得不到結果呢?因為我們的流輸入操作,以空格或者換行為間隔,讀取下一個,輸入流(如鍵盤、文件)不會直接讀取到?'\0'('\0'?是字符串的結束符,不是輸入字符)。
那我們該怎么解決呢?
c++io流中里面有一個get函數用來讀取單個字符
istream& operator>>(istream& is, string& s)
{char ch; is.get(ch);s += ch;while (ch != '\0' && ch != '\n'){is.get(ch);s += ch;}return is;
}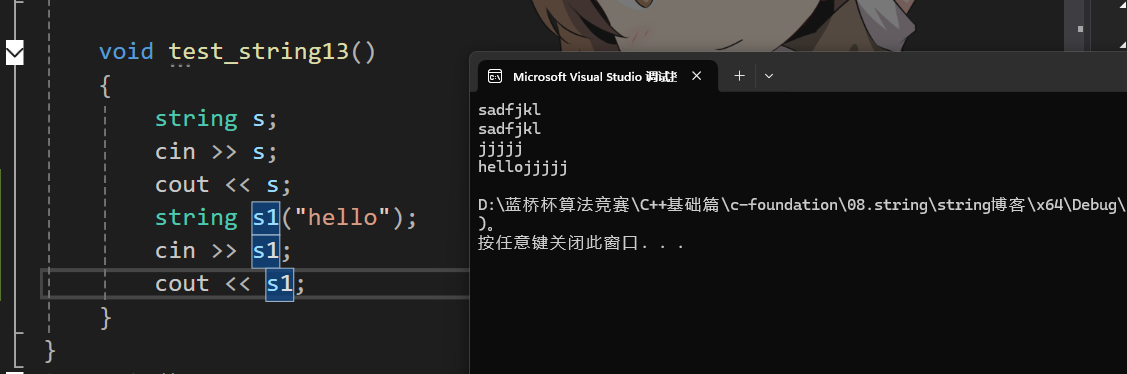 ?這里還存在一些問題就是,要把之前的數據清除掉。
?這里還存在一些問題就是,要把之前的數據清除掉。
這又得寫個clear函數了
簡單實現一下。
clear
void string::clear()
{_size = 0;_str[_size] = '\0';
}這里就不實現縮容了,沒必要。
?
istream& operator>>(istream& is, string& s)
{s.clear();char ch; is.get(ch);s += ch;while (ch != '\0' && ch != '\n'){is.get(ch);s += ch;}return is;
}最后一個小問題,我們如果頻繁輸入小的數據,就又會頻繁擴容的問題出現,那又該怎么解決了,我們都不知道我們要輸入多少的字符,也不能提前擴容。
我們可以實現一個內存池,比如開個255空間大小的內存池,當輸入的小于255時就放在內存池中。
實現如下:
istream& operator>>(istream& is, string& s)
{s.clear();char buff[256];size_t i = 0;char ch = is.get();while (ch != '\0' && ch != '\n'){buff[i++] = ch;ch = is.get();if (i == 255){buff[i] = '\0';s += buff;i = 0;}}if (i > 0){buff[i] = '\0';s += buff;}return is;
}over!感謝觀看!?


(ArkTs))

報告》)














 -> impl Fn(y)` 的同學點進來!)