完整內容請看文末最后的推廣群

基于自然語言處理的競賽論文初步篩選系統
基于多模態分析的競賽論文自動篩選與重復檢測模型
摘要
隨著大學生競賽規模的不斷擴大,參賽論文的數量激增,傳統的人工篩選方法面臨著工作量大、效率低且容易出錯的問題。因此,利用計算機和人工智能技術對競賽論文進行自動篩選成為一種有效的解決方案。該賽題的目標是通過設計數學模型和算法,實現競賽論文的自動篩選,計算論文的重復率,檢測文本、圖片和公式的相似性,從而提高篩選效率、減少人工誤差,并降低人工成本。
問題一主要關注從競賽論文中提取基本信息(如標題、摘要、關鍵詞等),以便為后續的篩選和評審提供基礎數據。通過PDF提取工具( pdfplumber),自動化提取論文中的文本內容,并通過論文結構和正則化表達進行信息提取,如標題通常位于論文前幾頁,摘要、關鍵詞等信息緊隨其后, 并設計了針對圖片、公式和代碼的識別函數。該模型能夠快速處理大量競賽論文,自動提取關鍵信息。
問題二旨在根據論文的內容和格式進行篩選,檢查是否包含有效的參賽隊信息,判斷論文是否與賽題相關,且是否具有實質性內容。通過文件名映射提取參賽隊號,通過關鍵詞匹配判斷論文是否與賽題相關,并識別無實質內容的論文。
問題三的目標是檢測論文之間的重復內容,包括文本的重復率、雷同圖片和雷同公式。通過提取文本內容,使用TF-IDF和余弦相似度計算論文之間的文本相似度;對于圖片和公式,使用感知哈希和哈希值比較的方法來判斷圖片和公式是否雷同。該模型通過結合文本、圖片和公式的相似度,能夠全面檢測論文中的重復內容。在文本檢測方面,余弦相似度和TF-IDF方法能夠有效衡量文本的相似性。圖片和公式的檢測通過感知哈希和哈希值比較,表現良好。
問題四的目的是檢測高圖片占比的PDF文件,并分析其與其他文檔的重復情況。通過計算圖片在頁面中的占比來判斷是否為高圖片占比的論文,并結合OCR技術提取圖片中的文字內容來提高圖文結合的相似度計算。該模型能夠有效識別高圖片占比的PDF,并對其進行重復率分析。通過計算每一頁的圖片占比并進行平均,可以準確識別圖片占比較高的文檔。使用OCR技術提取圖片中的文字,有助于提高圖文結合相似度的計算精度。
模型有效地實現了自動化的競賽論文篩選與分析,極大地提升了論文評審的效率。未來可以考慮通過進一步優化算法、增強模型的魯棒性,來解決這些問題。此外,模型的計算消耗較大,尤其是在處理大規模數據時,需要高效的計算資源和優化策略。
關鍵詞:余弦相似度; 感知哈希; OCR技術; 多模態分析; 競賽評審; pdfplumber; 正則化表達
目錄
摘要 1
一、 問題重述 4
1.1 問題背景 4
1.2 要解決的問題 4
二、 問題分析 6
2.1 任務一的分析 6
2.2 任務二的分析 6
2.3 任務三的分析 7
2.4 任務四的分析 7
三、 問題假設 9
四、 模型原理 10
4.1 關鍵詞識別 10
4.2 中文文本分析 11
4.3 相關性分析 11
五、 模型建立與求解 13
5.1 問題一建模與求解 13
5.2問題二建模與求解 18
5.3問題三建模與求解 21
5.4問題四建模與求解 25
六、 模型評價與推廣 29
6.1模型的評價 29
6.1.1模型缺點 29
6.1.2模型缺點 29
6.2 模型推廣 30
七、 參考文獻 31
附錄【自行黏貼】 32
二、 問題分析
2.1任務一的分析
針對問題一,論文的初步篩選與評審工作通常需要涉及對論文的基本信息進行提取和統計,包括論文的標題、作者、摘要、關鍵詞等內容。對于大量的競賽論文而言,手動提取這些信息顯然是不切實際的,因此需要自動化的手段來完成這些任務。問題一的核心目標是設計一個自動化的系統,通過程序從PDF格式的論文中提取相關信息,為后續的篩選和評審提供基礎數據。
具體來說,論文的標題和摘要通常位于論文的前幾頁,是論文的關鍵部分。作者和關鍵詞可能出現在標題之后或其他部分。為了準確提取這些內容,需要假設每篇論文都有類似的結構,并且可以通過正則表達式或關鍵詞匹配來識別這些部分。文本的提取也依賴于PDF的結構,如果文件的排版或內容較復雜,提取的準確性可能受到影響。
此外,提取公式和圖片的工作同樣需要自動化完成。公式通常以數學符號和特定的格式(如 . . . ... ... 或 […])出現,圖片則嵌入在文本中。需要對每一頁進行遍歷和分析,提取有效的公式和圖片內容。
2.2任務二的分析
問題二的目的是對論文進行篩選,確保論文與賽題相關并且具有實質內容。具體任務包括三個方面:首先,需要確認論文是否包含有效的參賽隊信息;其次,需要判斷論文內容是否與賽題相關;最后,評估論文是否具有實質性內容,避免出現大量無意義的內容,如致謝、附錄和參考文獻等。
第一步是檢查參賽隊信息,這一任務通過查看文件名中的加密號并將其與參賽隊號映射表進行匹配來完成。若匹配成功,則認為該論文包含有效的參賽隊信息。
第二步是判斷論文內容與賽題的相關性。為此,需要提取論文正文部分并通過關鍵詞匹配方法來判斷論文是否與賽題相關。賽題的相關關鍵詞已給出,因此可以通過在文本中查找這些關鍵詞來識別與賽題相關或無關的論文。
最后,第三步是檢查論文的實質性內容。很多論文可能在正文中包含大量無實際內容的段落,例如致謝、附錄、代碼實現等部分。通過檢測正文內容的有效性以及是否含有這些無關段落,能夠篩選出不符合要求的論文。
2.3任務三的分析
問題三的核心目標是通過自動化手段檢測競賽論文中的重復內容,具體包括計算文本的重復率、檢測雷同的圖片以及雷同的公式。隨著論文數量的增多,檢測論文中是否存在抄襲或雷同內容變得尤為重要。
首先,文本重復率的計算基于文本相似度的分析。通過提取每篇論文的正文文本,并將其轉化為TF-IDF向量,利用余弦相似度來衡量不同論文之間的文本相似度。通過計算每篇論文與其他論文的相似度,可以得出每篇論文的重復率。
其次,雷同圖片的檢測依賴于圖片的感知哈希技術。通過提取論文中的圖片并計算其哈希值,利用哈希值之間的差異來判斷圖片是否雷同。感知哈希是一種能夠有效識別圖片相似度的方法,尤其是在圖片做了細微修改時,依然能夠識別出相似內容。
最后,雷同公式的檢測同樣使用哈希技術。通過提取公式并計算其哈希值,比較不同論文中的公式,判斷是否存在雷同公式。公式的格式一般具有較強的規律性,因此通過哈希值可以準確地檢測出相似或相同的公式。
2.4任務四的分析
問題四的目標是通過分析PDF文件中的圖片占比來識別是否為高圖片占比的文檔,并進一步分析其與其他文檔的重復情況。高圖片占比PDF常常包含大量無關或無實際內容的圖片,這些圖片可能是裝飾性的或者與論文主題無關。因此,識別這種類型的PDF文件對于競賽論文的篩選具有重要意義。
首先,圖片占比的計算基于頁面的總面積和圖片的面積,通過計算圖片在頁面中所占的比例來判斷是否為高圖片占比PDF。若該比例超過設定的閾值(如30%),則該PDF被認為是高圖片占比。
接下來,使用OCR技術提取圖片中的文字內容。OCR(光學字符識別)可以從圖片中提取出有用的文字信息,幫助進一步分析圖片的內容。對于有文字內容的圖片,OCR可以提升其在相似度計算中的作用。
最后,進行多模態相似度分析,即結合文本和圖片的相似度來評估論文之間的相似度。通過對論文的文本部分和圖片部分分別計算相似度,并結合兩者的信息來綜合評定論文的重復率。綜合相似度將文本和圖片的相似度進行加權合并,得到更為準確的重復率結果。
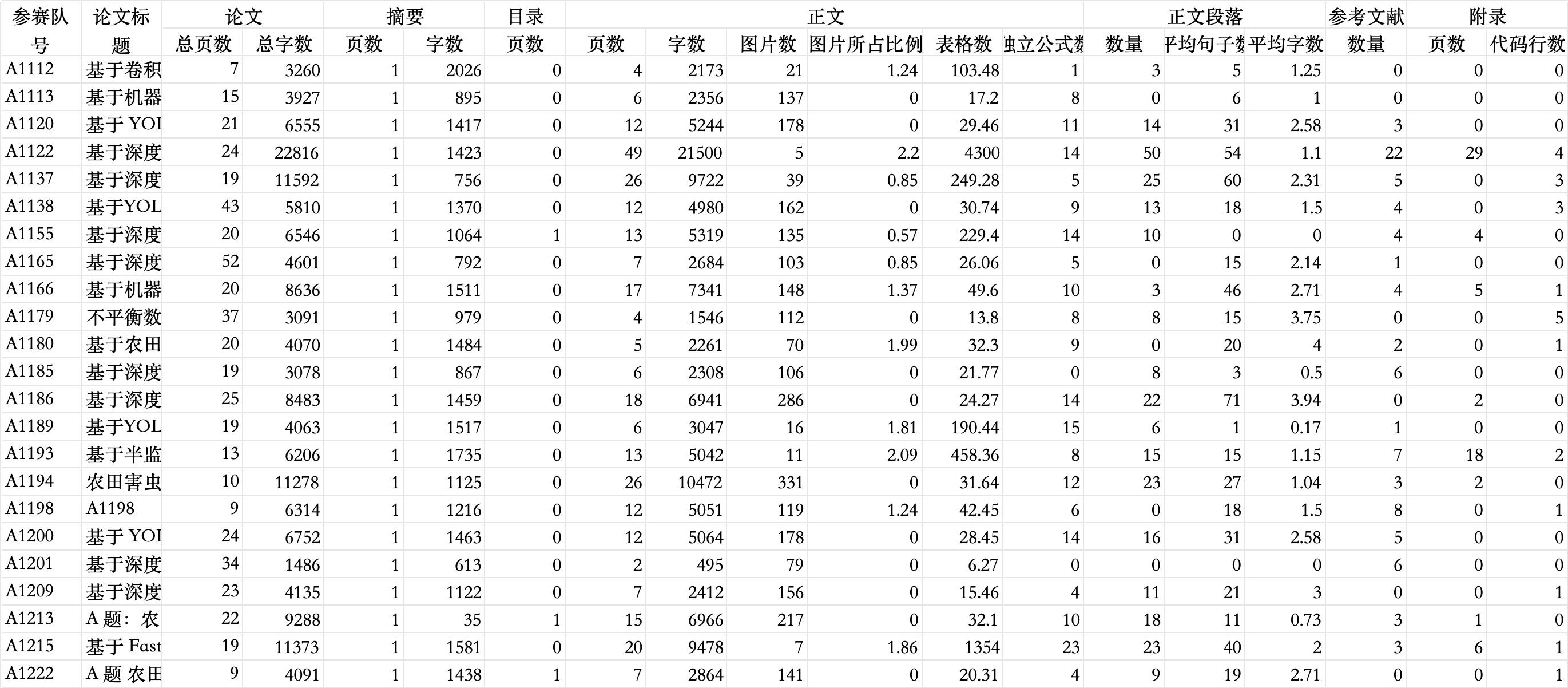
問題一結果
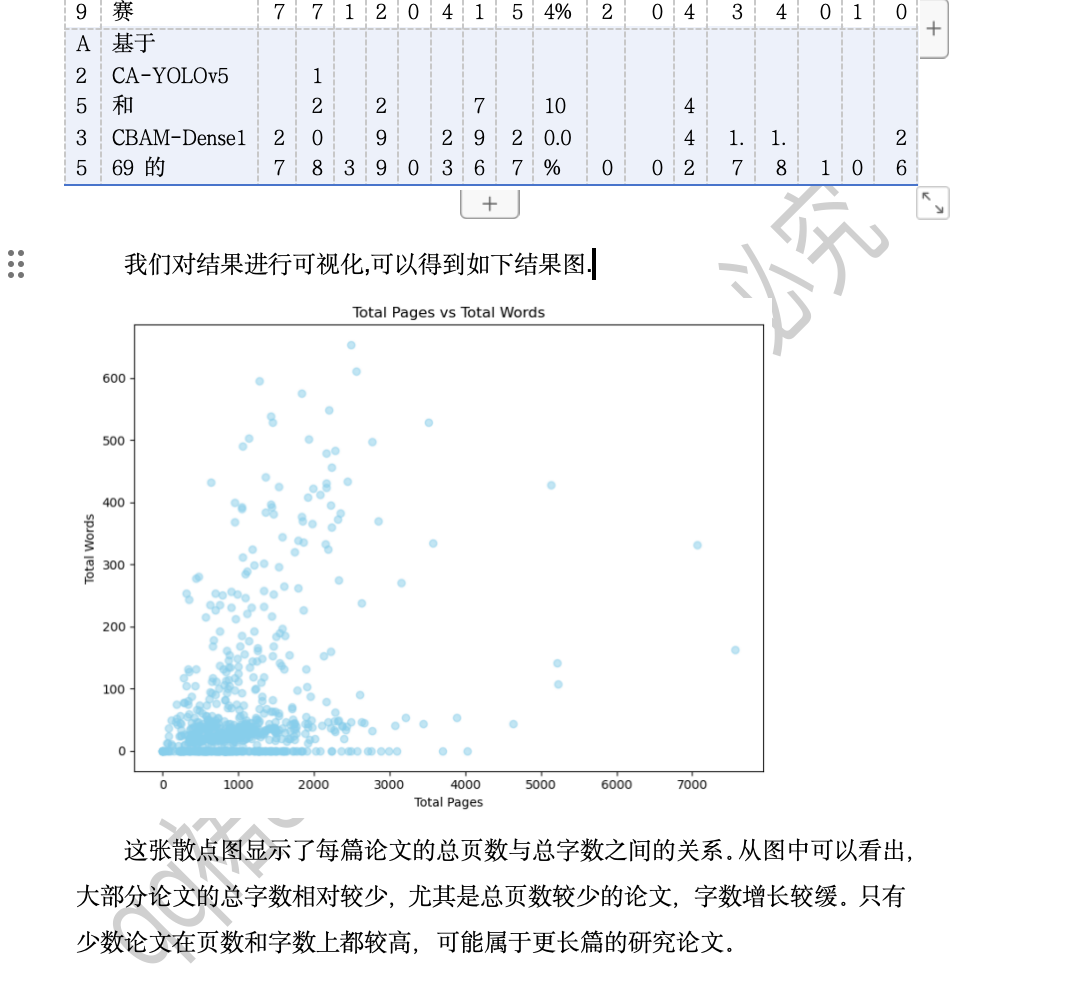
問題二結果
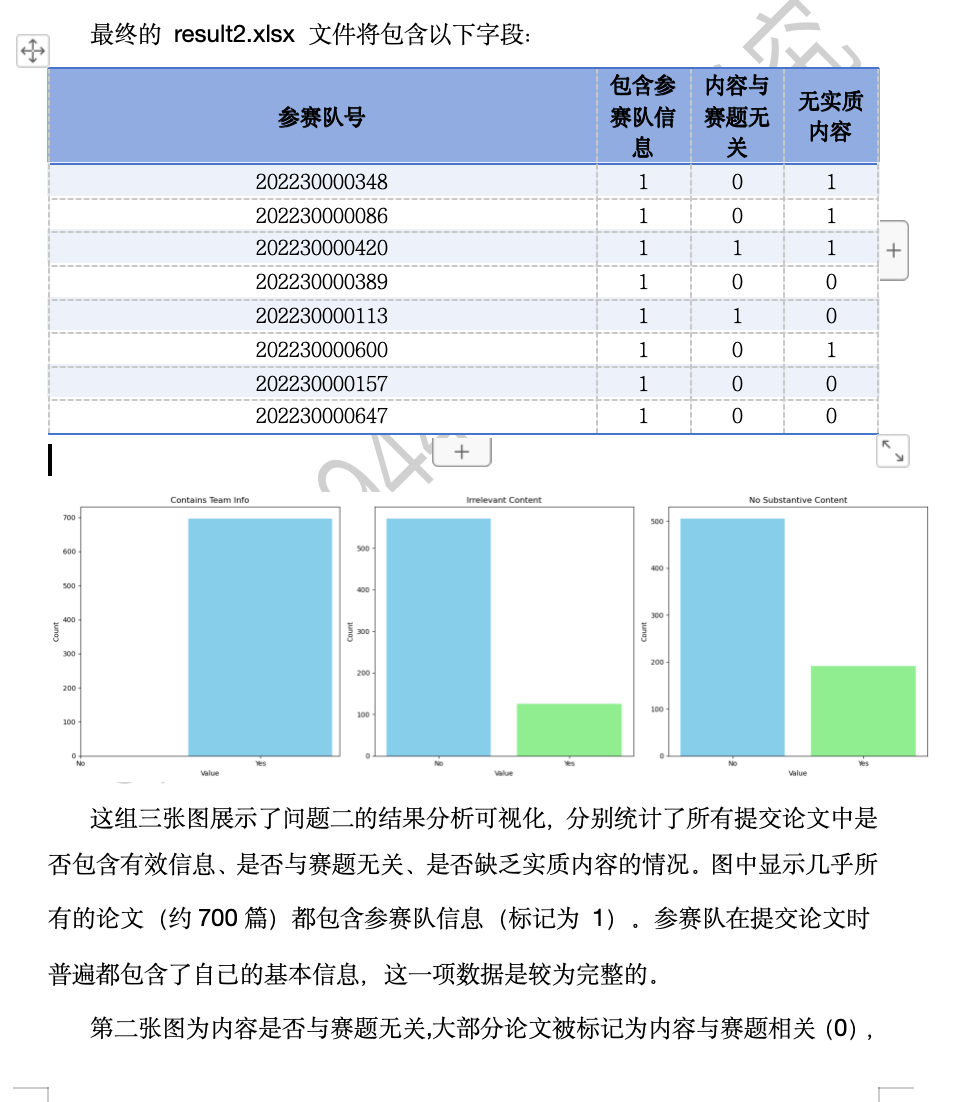
問題三結果
我們首先需要計算競賽論文之間的文本相似度,衡量文本的重復率。該過程使用 余弦相似度 方法,計算每篇論文與其他論文的相似度,并得到最大相似度作為論文的重復率。基于pdfminer函數從PDF文件中提取出每篇論文的正文內容,排除參考文獻、附錄等部分。使用 TF-IDF(詞頻-逆文檔頻率)對每篇論文的文本進行向量化,將每篇論文表示為一個向量。TF-IDF 是衡量單詞在文本中的重要性的常用方法。使用 余弦相似度(Cosine Similarity) 計算兩篇文本的相似度,公式如下:
其中,( A ) 和 ( B ) 是文本的TF-IDF向量,( A \cdot B ) 是向量的內積,( |A| ) 和 ( |B| ) 是向量的模。
對于每篇論文 ( i ),計算它與其他論文的最大相似度,作為該論文的重復率。若論文 ( i ) 與論文 ( j ) 的相似度最大,則該論文的重復率 ( R_i ) 可以表示為:
對于每篇論文 ( i ),其重復率 ( R_i ) 計算公式為:
其中 ( A_i ) 和 ( A_j ) 是第 ( i ) 和第 ( j ) 篇論文的 TF-IDF 向量。
接著我們需要檢測論文中的雷同圖片,檢查不同的論文是否使用了相同或相似的圖片。為此,我們使用 感知哈希算法 來計算圖片的哈希值,并比較圖片之間的相似度。
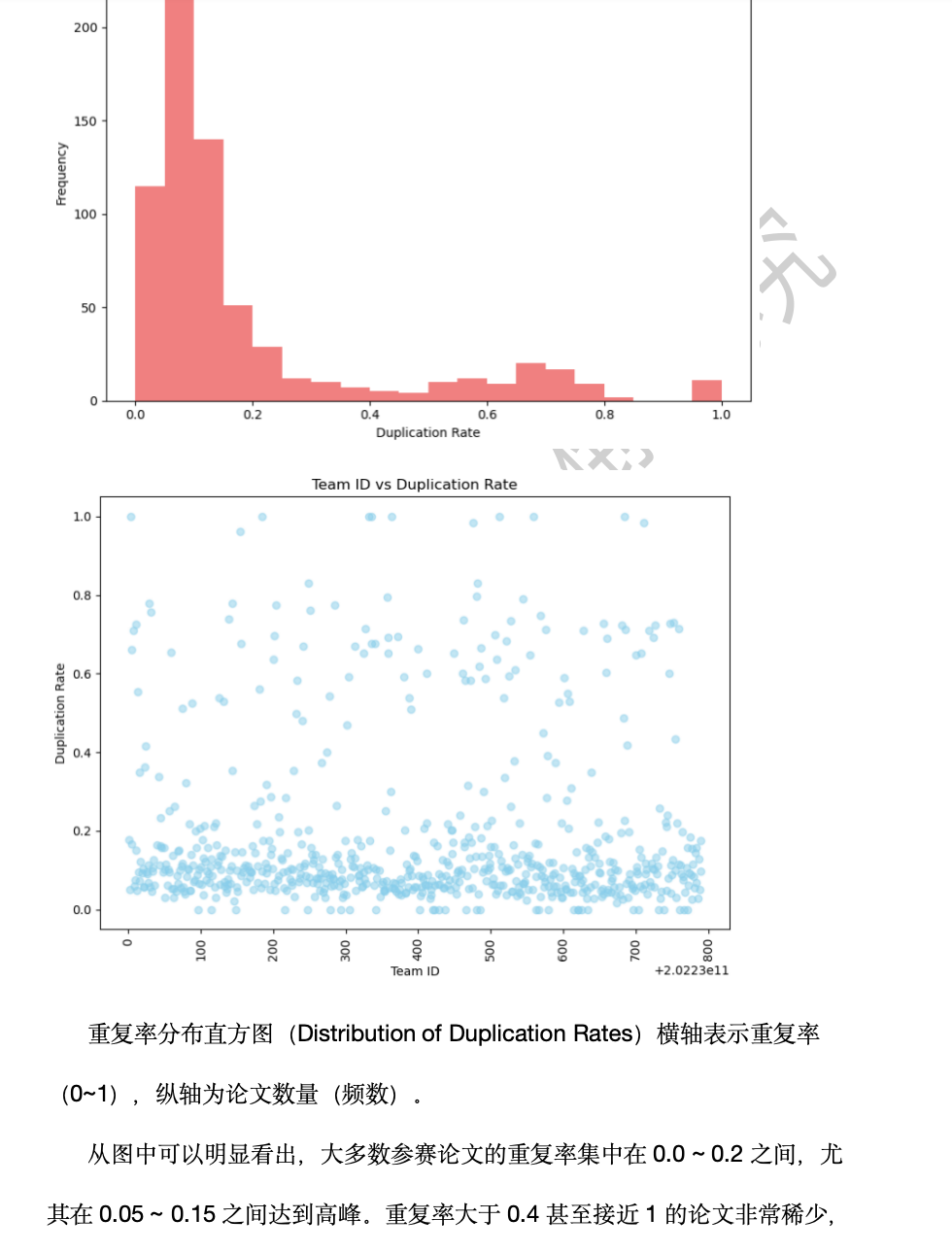
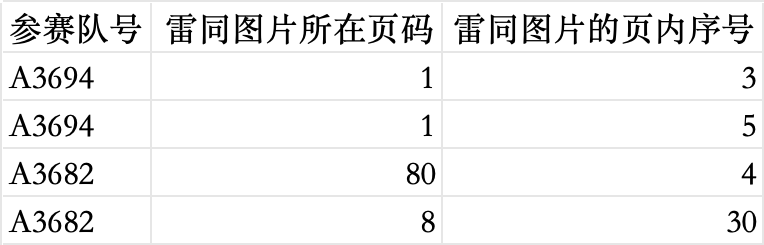
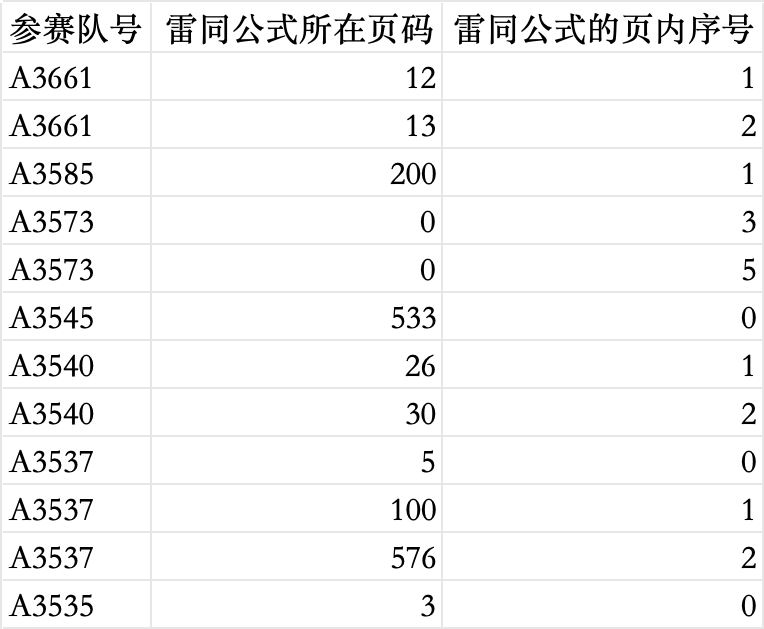
問題四結果
同時通過 pytesseract OCR技術提取圖片中的文字信息。對于每張圖片,計算其特征向量,使用 標準化處理(將圖片轉換為灰度圖像并調整大小)來提取圖片的特征向量,用于后續的圖片相似度分析。
對于每一張圖片,使用 感知哈希(Perceptual Hash) 來提取其特征向量。感知哈希的計算公式為:
其中 h§ 是圖片 p 的感知哈希值,表示圖片的特征。
我們需要綜合文本和圖片信息,計算每篇論文的相似度。為此,我們首先計算文本之間的余弦相似度,然后計算圖片之間的相似度,最后將兩者的相似度結合得到綜合相似度。
對每篇論文的正文內容進行 TF-IDF 向量化,并計算余弦相似度。余弦相似度公式如下:



 -> impl Fn(y)` 的同學點進來!)











![[區塊鏈lab2] 構建具備加密功能的Web服務端](http://pic.xiahunao.cn/[區塊鏈lab2] 構建具備加密功能的Web服務端)

—— 音頻/視頻服務)

