我上一篇文章已經講解過了如何使用公開的AI模型來優化SQL.但這個優化方法存在一定的局限性.因為公開的AI模型并不了解你的數據表結構是什么從而導致提供的優化建議不太準確.而sql表結構又是至關重要的安全問題,是不能泄露出去的.所以在此背景下我決定搭建一個自己的AI應用在內網環境下實現SQL優化.
?1:所需軟件?Dify + Ollama+ docker? AI模型:?DeepSeek +?bge-m3
如果之前不了解Dify的話. 強烈建議參考我的另一篇文章安裝所需要的環境https://blog.csdn.net/wang5701071/article/details/146207226?spm=1001.2014.3001.5501
1:為什么要搭建自己的AI應用進行sql優化?
1:準確性
目前主流的AI模型deepseek chatGPT等模型對于復雜sql的優化其實存在一定局限性.比如索引創建后,還是會提示讓你重復創建索引,并不能提高sql性能.?
原因1:有可能是sql的字數太多,導致AI模型無法準確識別優化計劃
原因2: 也有可能是AI不知道具體的表結構,給出的索引建議與已經存在的索引沖突
2:安全性
給AI模型提供表結構會讓AI提供的建議更加準確,但是很多企業內部或者內網辦公環境下,表結構是無法提供給公開的AI的,否則會導致泄密風險.
3:提高效率
定制自己的AI應用可以通過編排AI工作流和提示詞達到一次詢問即可得到想要的答案.避免了公共AI模型的多次詢問才能獲取想要的結果.能提高工作效率.
2:創建自己的SQL表知識庫
2.1:打開navicat數據庫->右鍵需導出數據庫->轉儲SQL文件->僅結構;
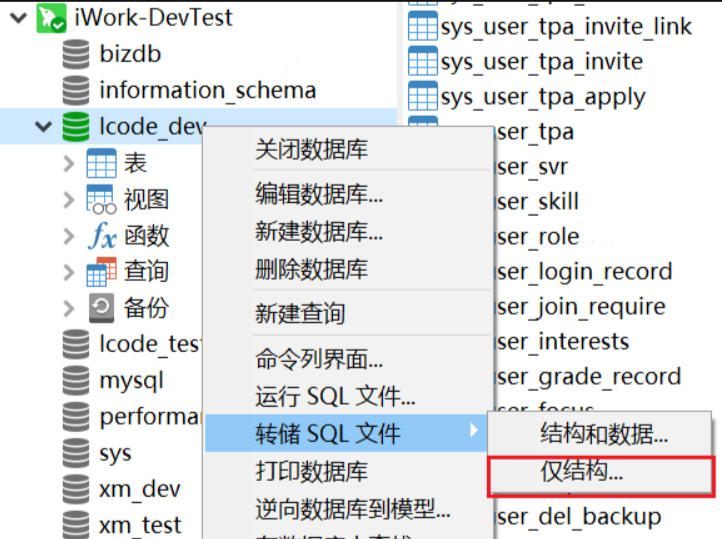
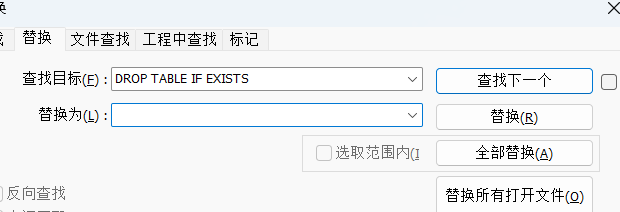
打開剛剛導出的.sql文件就會出現這種.這個時候需要批量刪掉文本中存在的 DROP TABLE IF EXISTS . 這句話不刪掉會影響知識庫的識別.然后修改后綴為.txt文本就行了.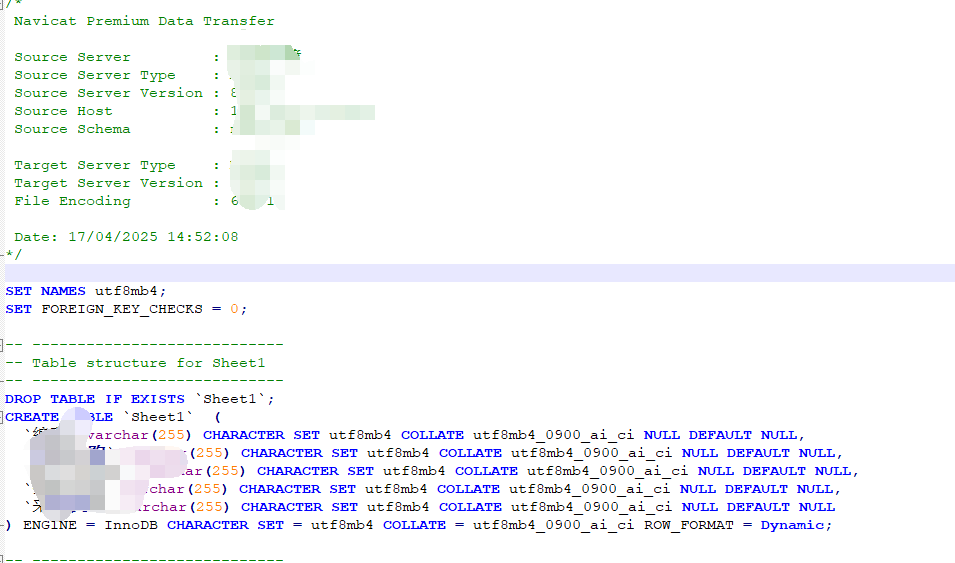
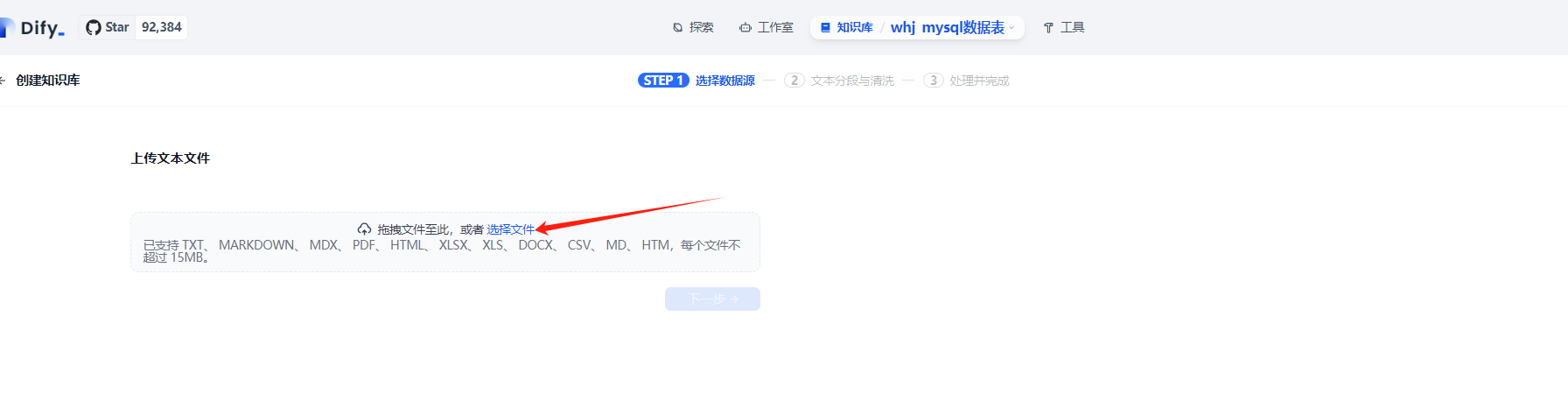
這個時候就可以在dify創建自己的sql知識庫了.注意我這里的知識庫AI模型使用的是?bge-m3
其他都保持默認.進行下一步就創建成功了.
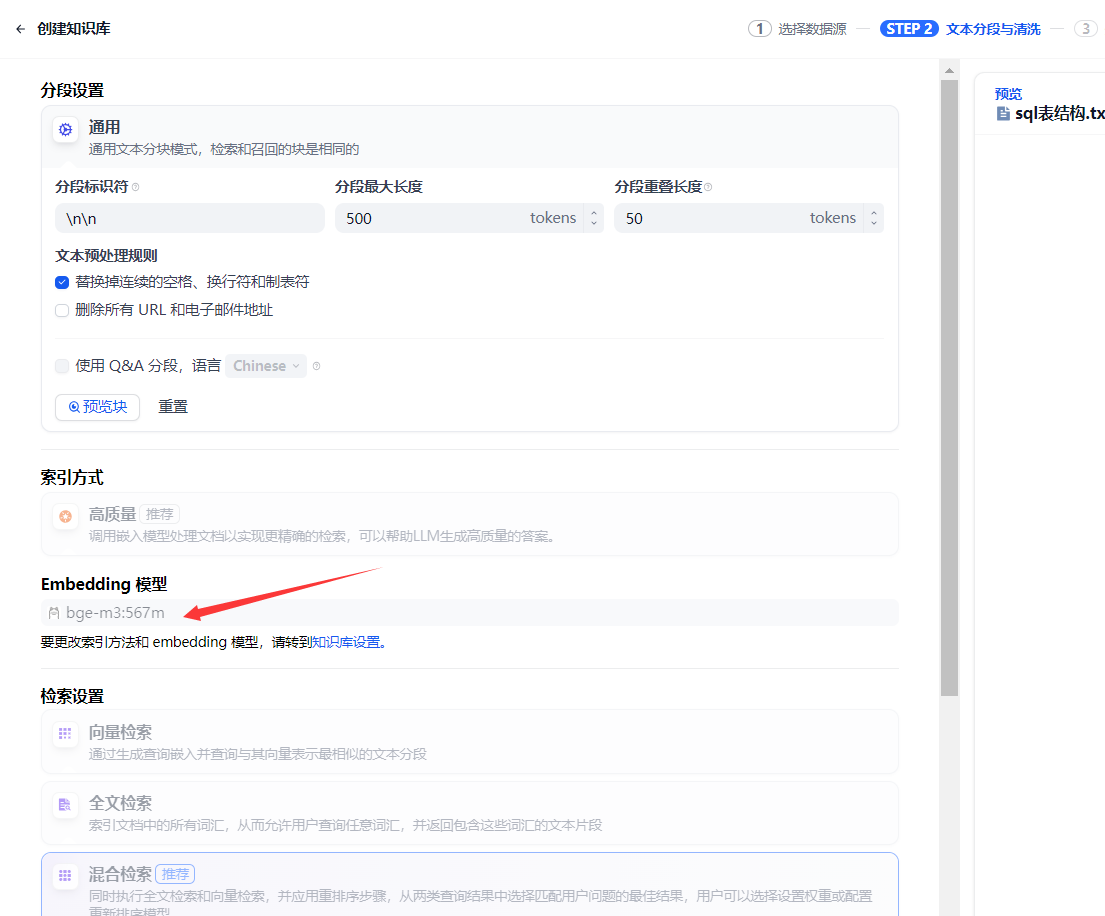
出現這些代表自己的SQL知識庫分析完成了.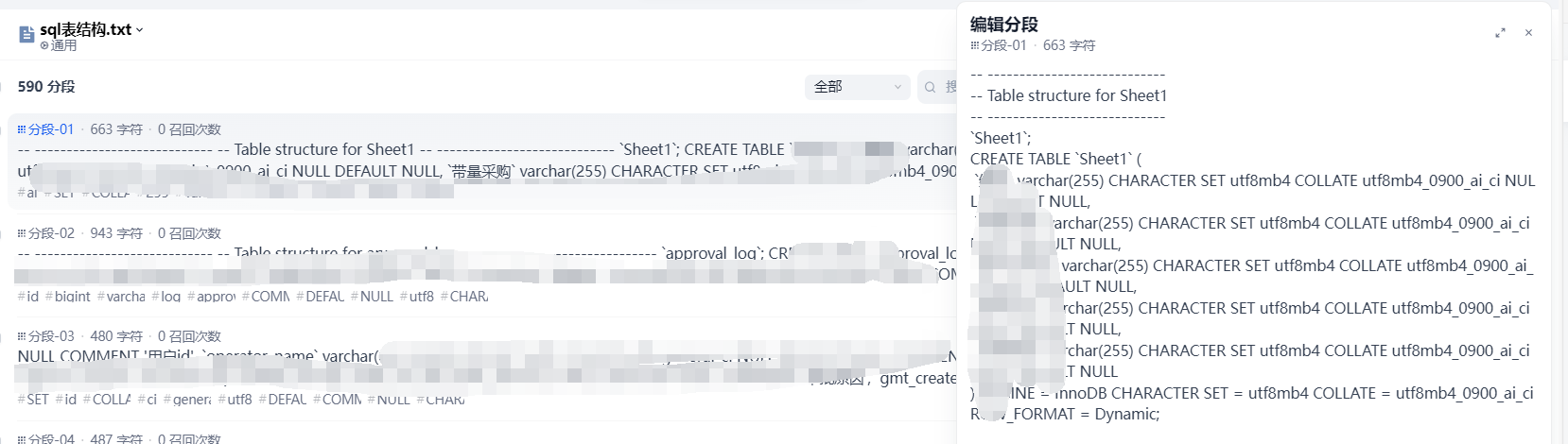
3:搭建AI應用
3.1:在dify里的探索頁面找到問題分類 + 知識庫 + 聊天機器人?并添加到工作區.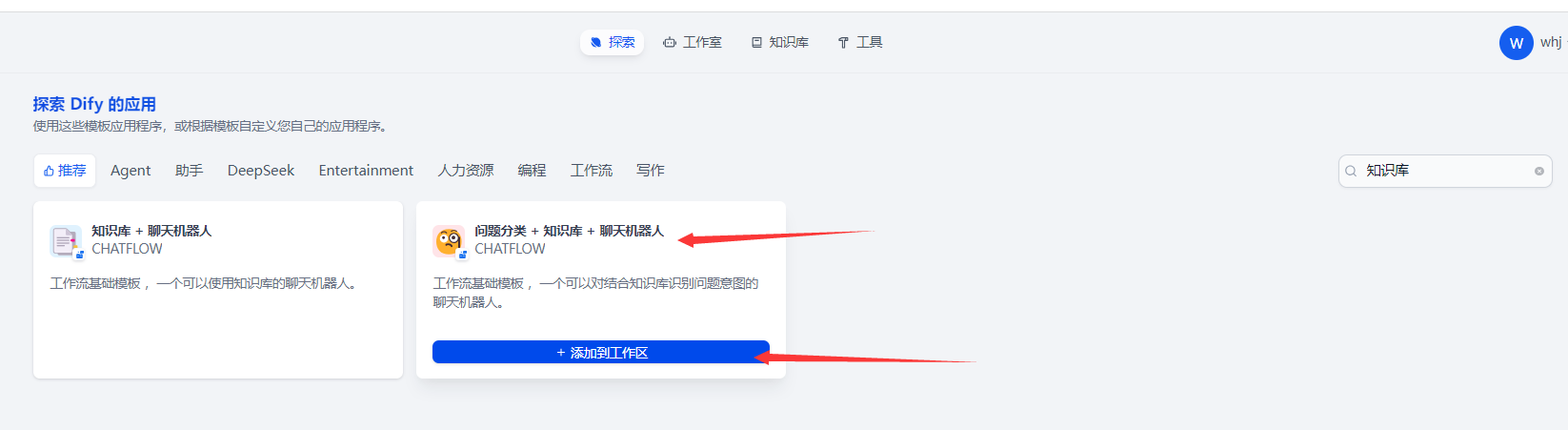
3.2對AI應用進行編排
右擊節點.刪掉不想要的節點,只保留一條AI工作流即可.
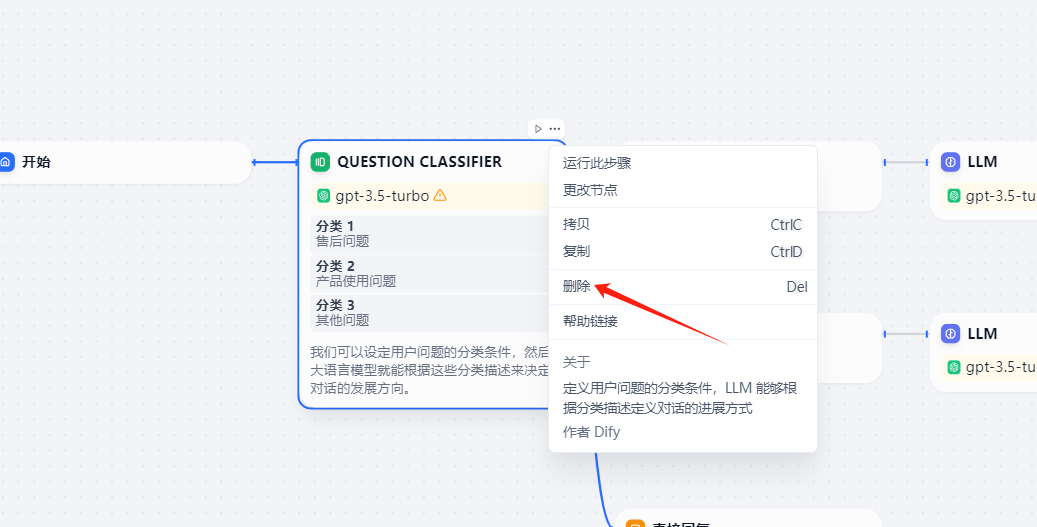
這個是我編排后的AI工作流
 3.3:節點的詳細設置
3.3:節點的詳細設置
開始節點: 增加了一個參數table (可加可不加看個人需求)
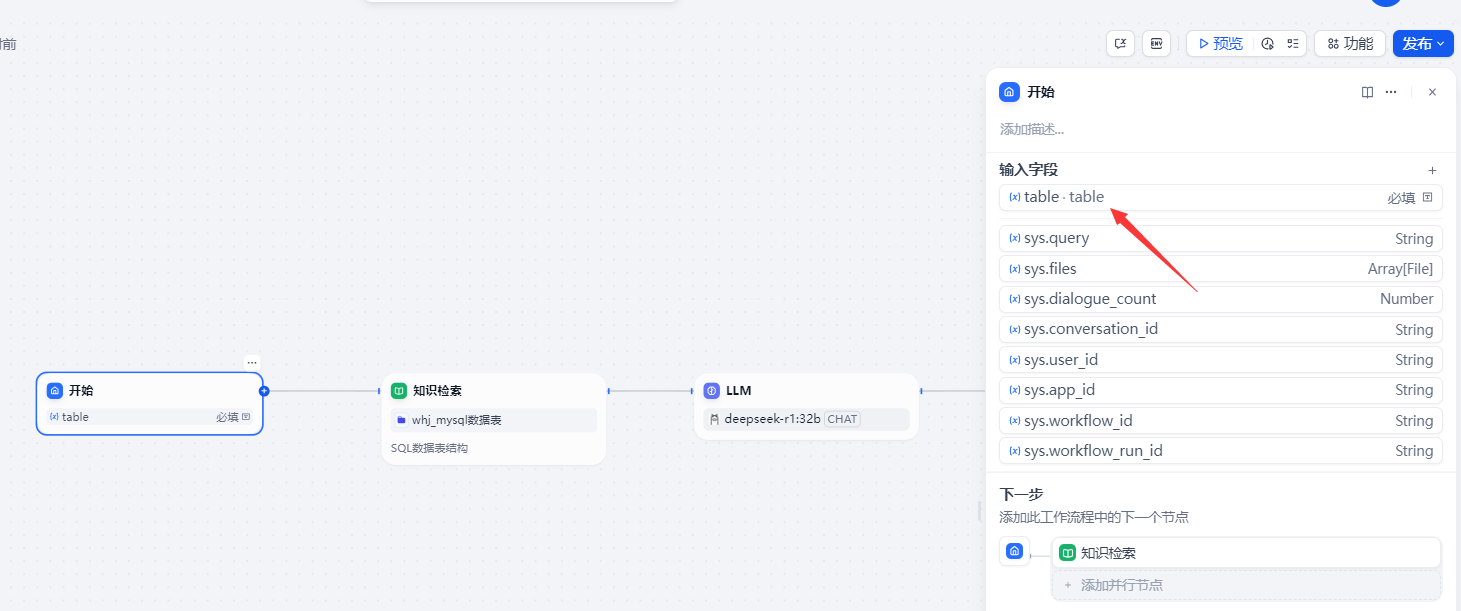
3.4 知識檢索節點:?添加剛剛創建好的知識庫
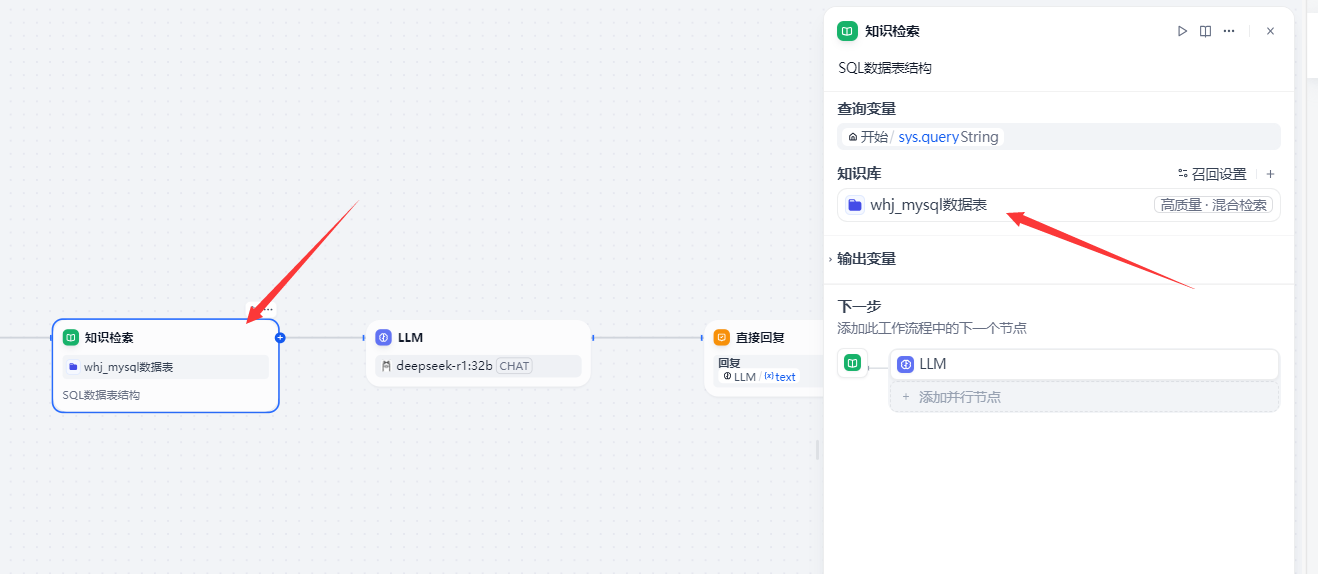 3.5 LLM節點:對deepseek進行提示詞優化
3.5 LLM節點:對deepseek進行提示詞優化
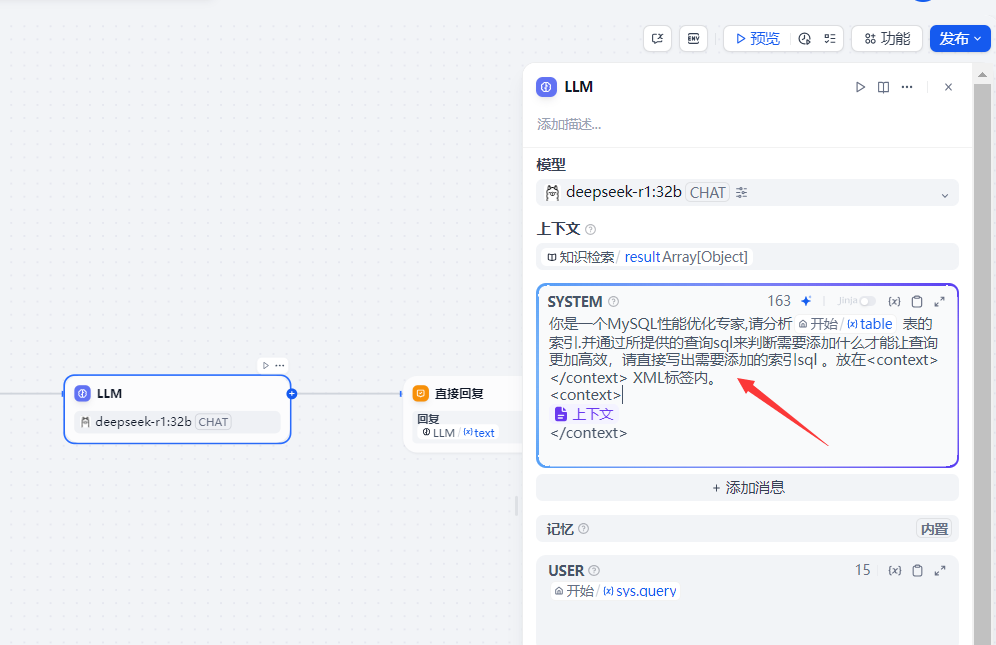
注意: 如果開始節點沒有新增table參數.這個地方的table是沒有的.可以去掉.改成自己想要的提示詞
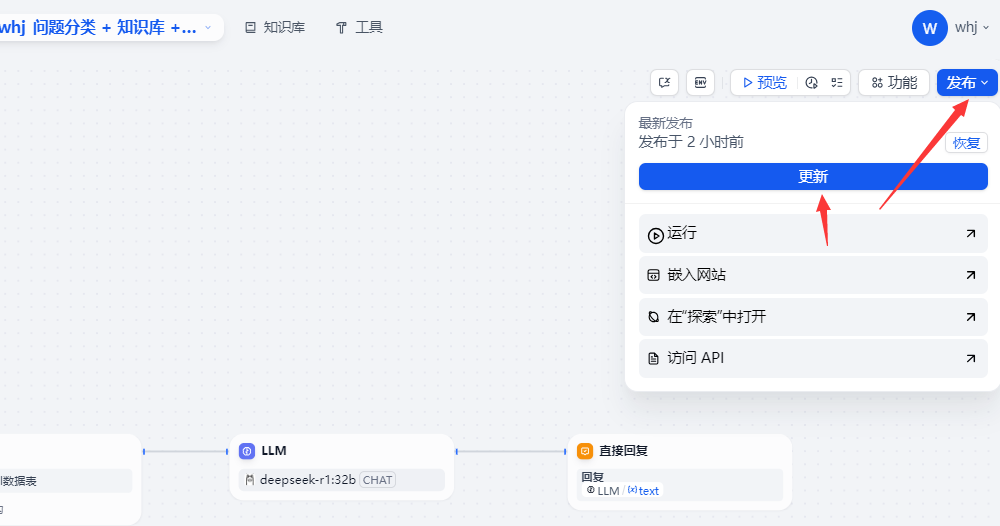
然后發布AI應用.就可以使用了.
4:當前AI應用工作流介紹
步驟一:開始節點:對AI進行多參數提問。可以直接輸入sql語句,或者explain執行計劃
步驟二:知識庫檢索:知識庫對提問的問題進行檢索,通過關鍵字獲取到表結構和索引數據。
步驟三:將表結構,索引數據 sql語句匯總起來發給deepseek模型。進行分析如何進一步優化
步驟四:數據分析后的結果。
5:優化sql
例如:使用?EXPLAIN ANALYZE +慢SQL語句進行查詢, 然后將獲得的結果復制給AI應用即可.
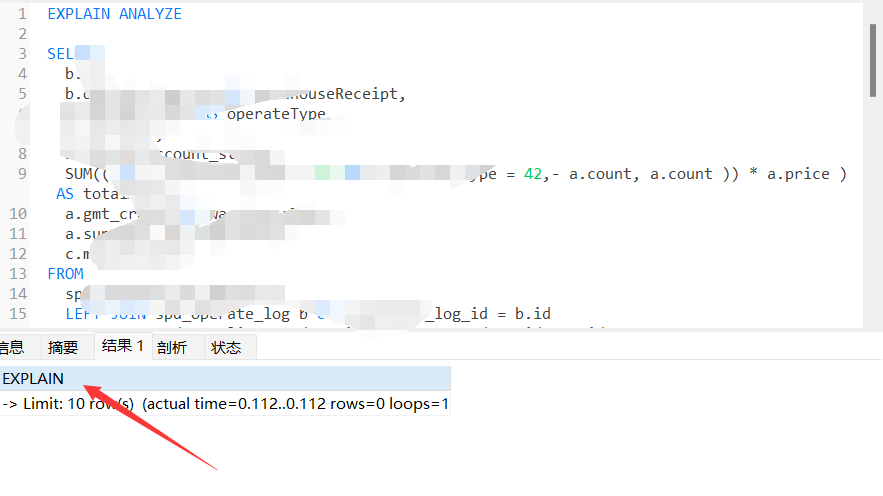
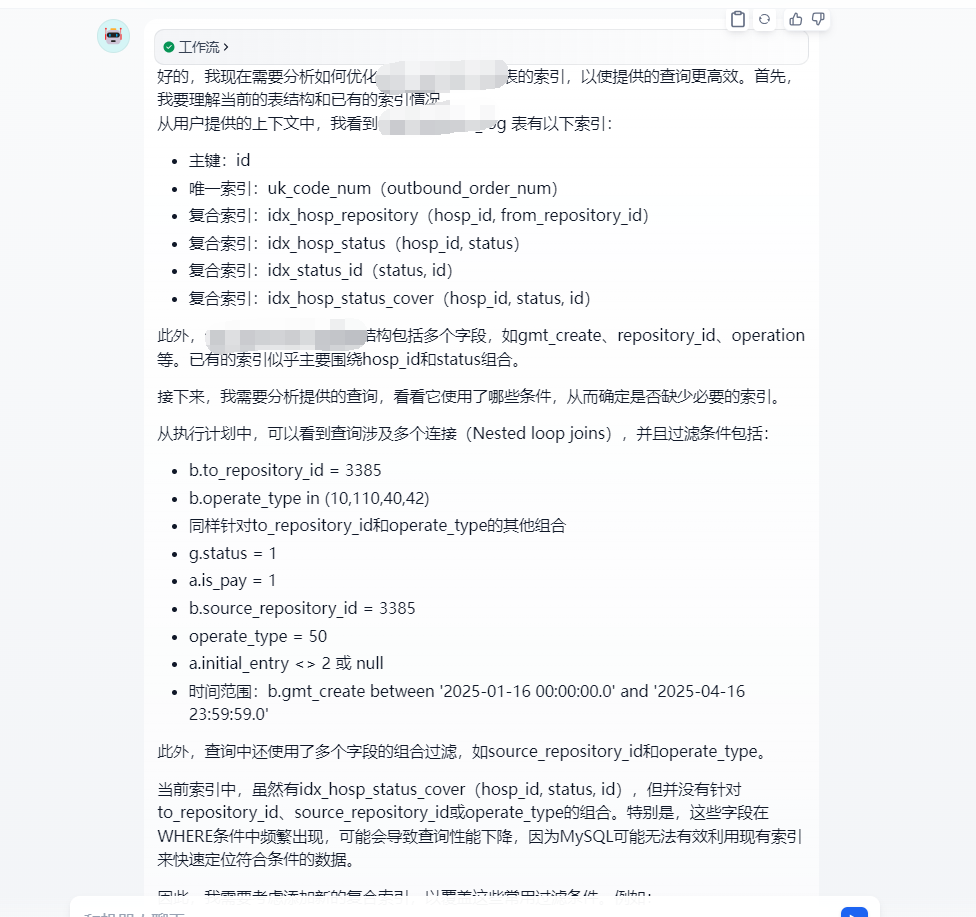 可以看到,即使剛剛沒有提供sql表結構,但通過知識庫的分析AI依然獲取到了已經存在的索引.提高了回答的準確性.而且全程都是本地部署的AI+知識庫.所以不用擔心數據泄露的問題.能夠放心的進行SQL優化.
可以看到,即使剛剛沒有提供sql表結構,但通過知識庫的分析AI依然獲取到了已經存在的索引.提高了回答的準確性.而且全程都是本地部署的AI+知識庫.所以不用擔心數據泄露的問題.能夠放心的進行SQL優化.
到這個地方.你已經學會了如何使用本地搭建AI+SQL知識庫.趕快去試試吧.









 -> impl Fn(y)` 的同學點進來!)









