超越基于常識的基準
除了不同的評估方法,你還應該了解的是利用基于常識的基準。訓練深度學習模型,你聽不到也看不到。你無法觀察流形學習過程,它發生在數千維空間中,即使投影到三維空間中,你也無法解釋它。唯一的反饋信號就是驗證指標。在開始處理一個數據集之前,你總是應該選擇一個簡單的基準,并努力去超越它。如果跨過了這道門檻,你就知道你的方向對了—模型正在使用輸入數據中的信息做出具有泛化能力的預測,你可以繼續做下去。這個基準既可以是隨機分類器的性能,也可以是你能想到的最簡單的非機器學習方法的性能。
比如對于MNIST數字分類示例,一個簡單的基準是驗證精度大于0.1(隨機分類器)?;對于IMDB示例,基準可以是驗證精度大于0.5。對于路透社示例,由于類別不均衡,因此基準約為0.18~0.19。對于一個二分類問題,如果90%的樣本屬于類別A,10%的樣本屬于類別B,那么一個總是預測類別A的分類器就已經達到了0.9的驗證精度,你需要做得比這更好。在面對一個全新的問題時,你需要設定一個可以參考的基于常識的基準,這很重要。如果無法超越簡單的解決方案,那么你的模型毫無價值—也許你用錯了模型,也許你的問題根本不能用機器學習方法來解決。這時應該重新思考解決問題的思路。
模型評估的注意事項
數據代表性(data representativeness)?。訓練集和測試集應該都能夠代表當前數據。假設你要對數字圖像進行分類,而初始樣本是按類別排序的,如果你將前80%作為訓練集,剩余20%作為測試集,那么會導致訓練集中只包含類別0~7,而測試集中只包含類別8和9。這個錯誤看起來很可笑,但非常常見。因此,將數據劃分為訓練集和測試集之前,通常應該隨機打亂數據。時間箭頭(the arrow of time)?。如果想根據過去預測未來(比如明日天氣、股票走勢等)?,那么在劃分數據前不應該隨機打亂數據,因為這么做會造成時間泄露(temporal leak)?:模型將在未來數據上得到有效訓練。對于這種情況,應該始終確保測試集中所有數據的時間都晚于訓練數據。
數據冗余(redundancy in your data)?。如果某些數據點出現了兩次(這對于現實世界的數據來說十分常見)?,那么打亂數據并劃分成訓練集和驗證集,將導致訓練集和驗證集之間出現冗余。從效果上看,你將在部分訓練數據上評估模型,這是極其糟糕的。一定要確保訓練集和驗證集之間沒有交集。有了評估模型性能的可靠方法,你就可以監控機器學習的核心矛盾—優化與泛化之間的矛盾,以及欠擬合與過擬合之間的矛盾。
改進模型擬合
為了實現完美的擬合,你必須首先實現過擬合。由于事先并不知道界線在哪里,因此你必須穿過界線才能找到它。在開始處理一個問題時,你的初始目標是構建一個具有一定泛化能力并且能夠過擬合的模型。得到這樣一個模型之后,你的重點將是通過降低過擬合來提高泛化能力。在這一階段,你會遇到以下3種常見問題。訓練不開始:訓練損失不隨著時間的推移而減小。訓練開始得很好,但模型沒有真正泛化:模型無法超越基于常識的基準。訓練損失和驗證損失都隨著時間的推移而減小,模型可以超越基準,但似乎無法過擬合,這表示模型仍然處于欠擬合狀態。我們來看一下如何解決這些問題,從而抵達機器學習項目的第一個重要里程碑:得到一個具有一定泛化能力(可以超越簡單的基準)并且能夠過擬合的模型。
調節關鍵的梯度下降參數
有時訓練不開始,或者過早停止。損失保持不變。這個問題總是可以解決的—請記住,對隨機數據也可以擬合一個模型。即使你的問題毫無意義,也應該可以訓練出一個模型,不過模型可能只是記住了訓練數據。出現這種情況時,問題總是出在梯度下降過程的配置:優化器、模型權重初始值的分布、學習率或批量大小。所有這些參數都是相互依賴的,因此,保持其他參數不變,調節學習率和批量大小通常就足夠了。我們來看一個具體的例子。
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255model = keras.Sequential([layers.Dense(512, activation="relu"),layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1.),loss="sparse_categorical_crossentropy",metrics=["accuracy"])
model.fit(train_images, train_labels,epochs=10,batch_size=128,validation_split=0.2)
這個模型的訓練精度和驗證精度很快就達到了30%~40%,但無法超出這個范圍。下面我們試著把學習率降低到一個更合理的值1e-2。
代碼清單 使用更合理的學習率訓練同一個模型
model = keras.Sequential([layers.Dense(512, activation="relu"),layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-2),loss="sparse_categorical_crossentropy",metrics=["accuracy"])
model.fit(train_images, train_labels,epochs=10,batch_size=128,validation_split=0.2)
現在模型可以正常訓練了。如果你自己的模型出現類似的問題,那么可以嘗試以下做法。降低或提高學習率。學習率過大,可能會導致權重更新大大超出正常擬合的范圍,就像前面的例子一樣。學習率過小,則可能導致訓練過于緩慢,以至于幾乎停止。增加批量大小。如果批量包含更多樣本,那么梯度將包含更多信息且噪聲更少(方差更小)?。最終,你會找到一個能夠開始訓練的配置。
利用更好的架構預設
你有了一個能夠擬合的模型,但由于某些原因,驗證指標根本沒有提高。這些指標一直與隨機分類器相同,也就是說,模型雖然能夠訓練,但并沒有泛化能力。這是怎么回事?這也許是你在機器學習中可能遇到的最糟糕的情況。這表示你的方法從根本上就是錯誤的,而且可能很難判斷問題出在哪里。下面給出一些提示。
首先,你使用的輸入數據可能沒有包含足夠的信息來預測目標。也就是說,這個問題是無法解決的。試圖擬合一個標簽被打亂的MNIST模型,它就屬于這種情況:模型可以訓練得很好,但驗證精度停留在10%,因為這樣的數據集顯然是不可能泛化的。其次,你使用的模型類型可能不適合解決當前問題。你會在第10章看到,對于一個時間序列預測問題的示例,密集連接架構的性能無法超越簡單的基準,而更加合適的循環架構則能夠很好地泛化。模型能夠對問題做出正確的假設,這是實現泛化的關鍵,你應該利用正確的架構預設。
提高模型容量
如果你成功得到了一個能夠擬合的模型,驗證指標正在下降,而且模型似乎具有一定的泛化能力,那么恭喜你:你就快要成功了。接下來,你需要讓模型過擬合。考慮下面這個小模型,它是在MNIST上訓練的一個簡單的logistic回歸模型。
model = keras.Sequential([layers.Dense(10, activation="softmax")])
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["accuracy"])
history_small_model = model.fit(train_images, train_labels,epochs=20,batch_size=128,validation_split=0.2)
import matplotlib.pyplot as plt
val_loss = history_small_model.history["val_loss"]
epochs = range(1, 21)
plt.plot(epochs, val_loss, "b--",label="Validation loss")
plt.title("Effect of insufficient model capacity on validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
模型得到的損失曲線。
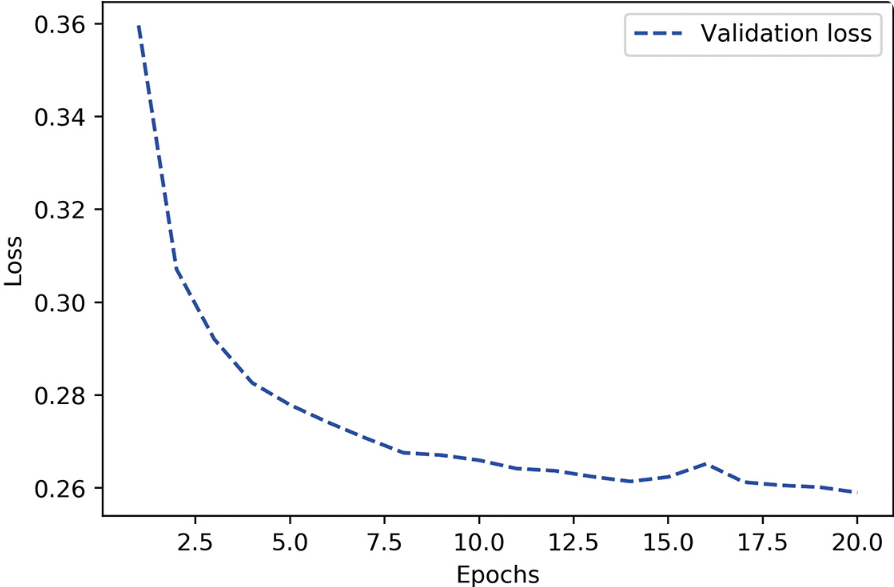
驗證指標似乎保持不變,或者改進得非常緩慢,而不是達到峰值后扭轉方向。驗證損失達到了0.26,然后就保持不變。你可以擬合模型,但無法實現過擬合,即使在訓練數據上多次迭代之后也無法實現。在你的職業生涯中,你可能會經常遇到類似的曲線。請記住,任何情況下應該都可以實現過擬合。與訓練損失不下降的問題一樣,這個問題也總是可以解決的。如果無法實現過擬合,可能是因為模型的表示能力(representational power)存在問題:你需要一個容量(capacity)更大的模型,也就是一個能夠存儲更多信息的模型。若要提高模型的表示能力,你可以添加更多的層、使用更大的層(擁有更多參數的層)?,或者使用更適合當前問題的層類型(也就是更好的架構預設)?。我們嘗試訓練一個更大的模型,它有兩個中間層,每層有96個單元。
model = keras.Sequential([layers.Dense(96, activation="relu"),layers.Dense(96, activation="relu"),layers.Dense(10, activation="softmax"),
])
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["accuracy"])
history_large_model = model.fit(train_images, train_labels,epochs=20,batch_size=128,validation_split=0.2)
現在驗證曲線看起來正是它應有的樣子:模型很快擬合,并在8輪之后開始過擬合
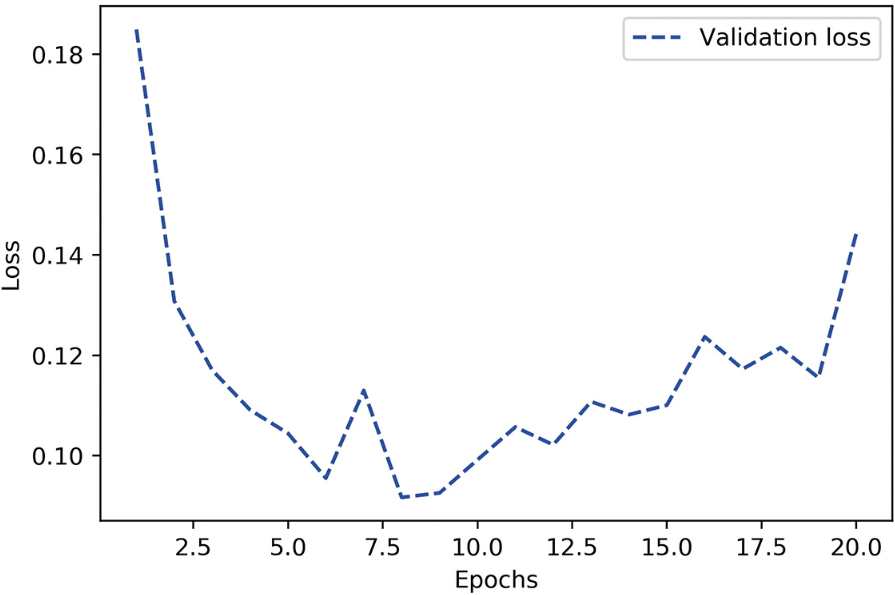
)
)




:解讀字節跳動提出主題定制視頻生成技術Phantom)



:數字電路設計的「前后端」到底是什么?)



![[蒼穹外賣 | 項目日記] 第三天](http://pic.xiahunao.cn/[蒼穹外賣 | 項目日記] 第三天)




