如果將深度定義為網絡中信息傳遞路徑長度的話,循環神經網絡可以看作既“深”又“淺”的網絡。
一方面來說,如果我們把循環網絡按時間展開,長時間間隔的狀態之間的路徑很長,循環網絡可以看作一個非常深的網絡。
從另一方面來 說,如果同一時刻網絡輸入到輸出之間的路徑𝒙𝑡 → 𝒚𝑡,這個網絡是非常淺的。
因此,我們可以增加循環神經網絡的深度從而增強循環神經網絡的能力。增加循環神經網絡的深度主要是增加同一時刻網絡輸入到輸出之間的路徑 𝒙𝑡 → 𝑦𝑡,比如增加隱狀態到輸出 𝒉𝑡 → 𝒚𝑡,以及輸入到隱狀態 𝒙𝑡 → 𝒉𝑡 之間的路徑的深度。
本文我來學習兩種常見的增加循環神經網絡深度的做法。
一、堆疊循環神經網絡
堆疊循環神經網絡(Stacked RNN)是將多個循環神經網絡層級組合在一起的結構,也稱為循環多層感知器,相當于在時間序列上“堆疊”多層隱狀態,從而提高模型對信息的抽象能力和表達復雜性。
1. 基本概念
在傳統的單層 RNN 中,每個時間步的隱藏狀態 ht 的計算通常為:
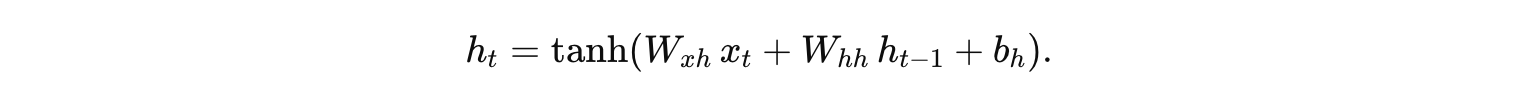
而在堆疊 RNN 中,我們將多個這樣的 RNN 單元按層級排列,通常稱為“深層 RNN”或“堆疊 RNN”。例如,假設我們有兩層 RNN:
-
第一層 RNN(低層)處理原始輸入序列 xt 產生隱層表示
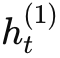 。
。 -
第二層 RNN(高層)以第一層的輸出作為輸入,進一步生成更高層次的表示
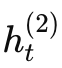 。
。
這種設計使得低層可以捕捉局部、短期的信息,而高層則能抽象出全局或更復雜的模式,特別適合于具有多層語義結構的任務,如自然語言處理、語音識別、時間序列預測等。
下圖給出了按時間展開的堆疊循環神經網絡:
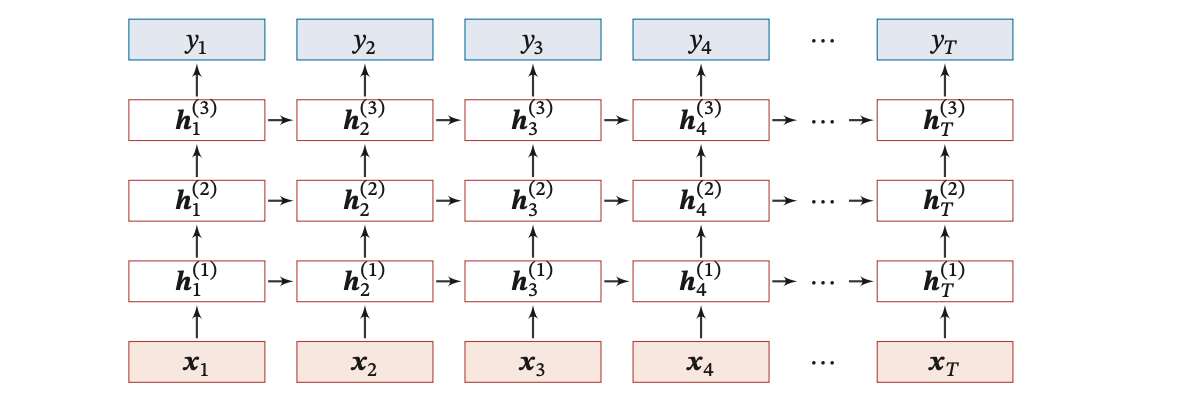
第 𝑙 層網絡的輸入是第 𝑙 ? 1 層網絡的輸出。我們定義 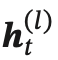 ?為在時刻 𝑡 時第 𝑙 層的隱狀態:
?為在時刻 𝑡 時第 𝑙 層的隱狀態:

2. 具體例子
任務: 對簡單數列進行預測——給定輸入序列 [1, 2, 3],目標輸出為 [2, 3, 4],即每個數字加 1。
模型設定:
-
輸入和輸出均為標量。
-
我們使用一個兩層 RNN,每層都有一個隱藏單元(為了便于示例,我們這里采用單隱藏單元,但后續擴展到多維也類似)。
第一層 RNN(層 1):
公式:
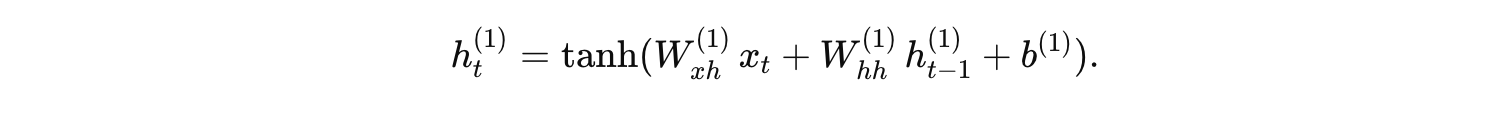
假設參數為:

計算過程:
-
時間步 1 (t=1):
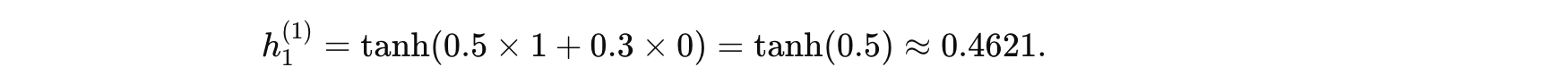
-
時間步 2 (t=2):
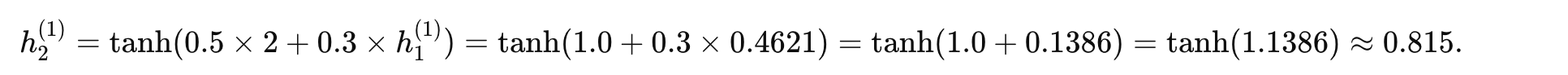
-
時間步 3 (t=3):
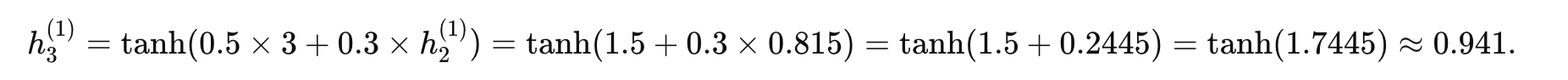
第二層 RNN(層 2):
公式:
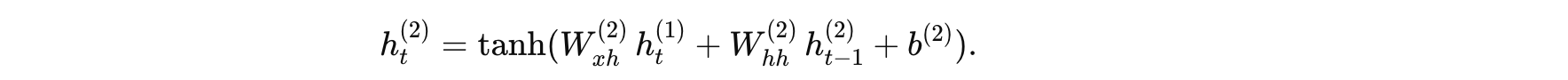
假設參數為:

計算過程:
-
時間步 1 (t=1):
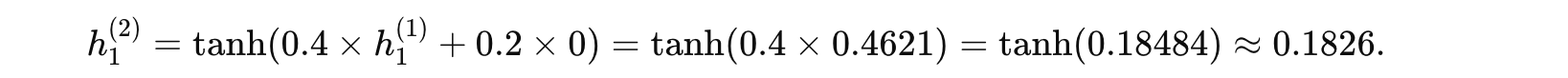
-
時間步 2 (t=2):
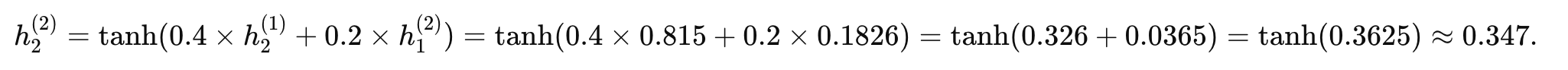
-
時間步 3 (t=3):
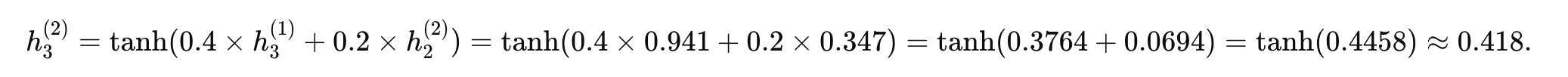
輸出層:
假設將第二層的隱藏狀態直接映射為輸出,公式為:
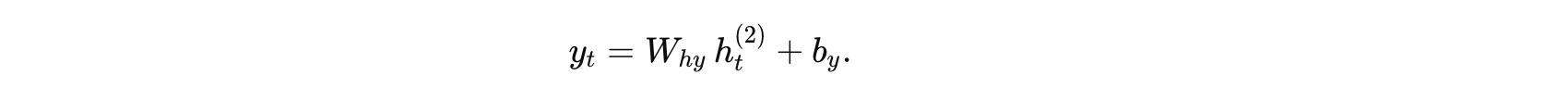
假設參數為:

則最終模型輸出:
-
y1≈0.1826
-
y2≈0.347
-
y3≈0.418
為使輸出反映“每個數字加 1”,假設目標輸出應該為 [2, 3, 4],當前輸出與目標有較大差距。通過反向傳播(例如均方誤差損失)計算梯度,再結合 BPTT,將誤差信息逐層反傳,從第二層到第一層,對各層參數 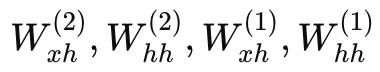 進行更新。
進行更新。
經過多輪迭代后,模型逐漸學會如何利用低層提取到的局部特征和高層傳遞到整體抽象信息,使得輸出能夠更準確地逼近目標(例如最終輸出 [2, 3, 4])。
3. 為什么使用堆疊 RNN?
-
抽取多層次特征:
低層可以捕捉輸入中局部、短期的模式,比如簡單的數值變化;高層則能捕捉更抽象的全局信息,如序列整體趨勢、結構關系等。 -
提高模型表現:
對于復雜任務,例如機器翻譯或情感分析,堆疊 RNN 能夠實現更深入的信息處理,進而提升性能。
4. 應用場景
-
自然語言處理:
在語句建模、語言翻譯中,堆疊 RNN 能夠從詞匯級別到句子級別提取不同層次的語法和語義信息。 -
語音識別:
利用多層結構捕捉語音信號中局部發音和全局語調等特征,提升識別準確率。 -
時間序列預測:
在金融數據、傳感器數據等任務中,堆疊 RNN 能夠建模短期波動和長期趨勢,提高預測精度。
堆疊循環神經網絡通過在不同層次上堆疊多個 RNN 層,使模型能夠逐步抽象出從局部模式到全局語義的復雜表示。在以上例子中,我們以簡單的數字序列預測為例,通過兩層 RNN 分別提取原始輸入的低級特征和高級抽象信息,再通過輸出層映射得到預測結果。盡管示例中采用了非常簡單的數值和單隱藏單元,但在實際應用中,這種多層結構可以大幅提升模型對長序列和復雜依賴關系的表達能力,因此在 NLP、語音識別、時間序列預測等領域得到廣泛應用。
二、雙向循環神經網絡?
在有些任務中,一個時刻的輸出不但和過去時刻的信息有關,也和后續時刻 的信息有關。比如給定一個句子,其中一個詞的詞性由它的上下文決定,即包含左右兩邊的信息。因此,在這些任務中,我們可以增加一個按照時間的逆序來傳遞信息的網絡層,來增強網絡的能力。即所謂的雙向循環神經網絡,由兩層循環神經網絡組成,它們的輸入相同,只是信息傳遞的方向不同:
假設第 1 層按時間順序,第 2 層按時間逆序,在時刻 𝑡 時的隱狀態定義為 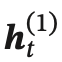 和
和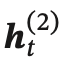 ,
,
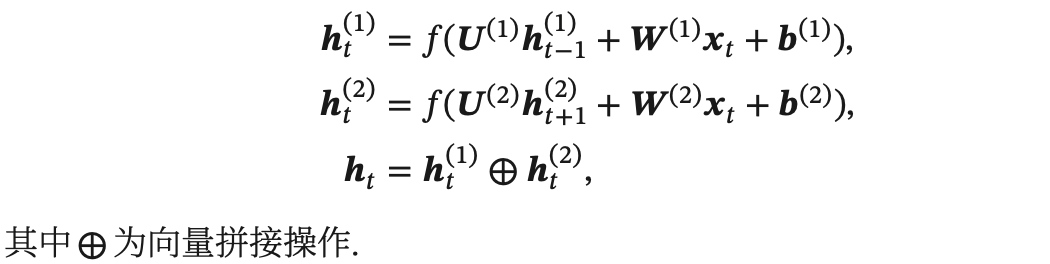
雙向循環神經網絡(Bidirectional RNN, Bi-RNN)是一種擴展自傳統RNN的架構,其基本思想是同時利用序列的正向和反向信息,從而使每個時間步的隱層狀態能夠綜合考慮前后文信息。這對于很多自然語言處理任務非常關鍵,因為理解一個詞語或字符往往不僅依賴于它之前的信息,也與它之后的語境密切相關。
下圖給出了按時間展開的雙向循環神經網絡:
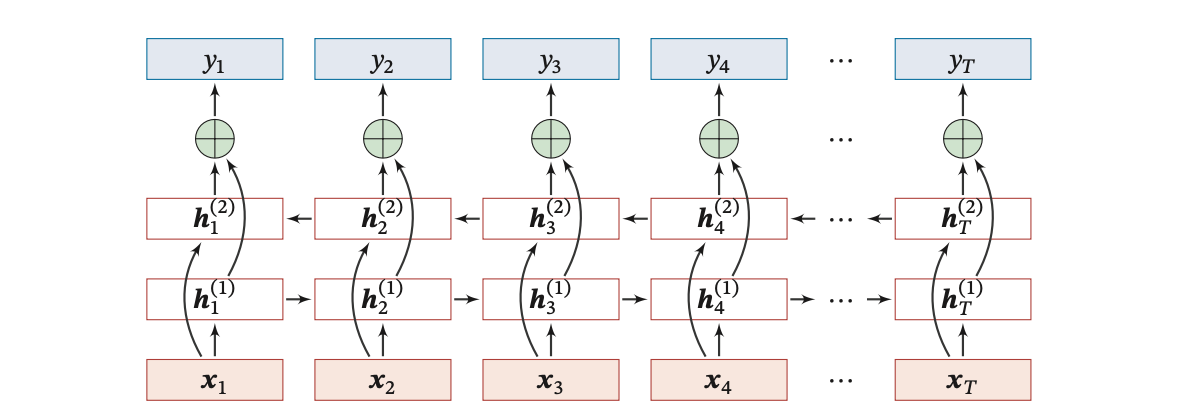
下面通過詳細的解釋和一個具體例子來說明雙向RNN的原理和應用。
1. 核心原理
在傳統的單向RNN中,隱藏狀態 ht 只依賴于從序列起點到時間步 t?的信息,這意味著對于當前時間步的輸出,只能利用其歷史信息。這在某些任務中可能不足以捕捉上下文的全部信息。
雙向RNN的關鍵在于構建兩個RNN子網絡:

最后,把正向和反向隱藏狀態進行合并(例如拼接、加權平均或求和),形成每個時間步的綜合表示 ht=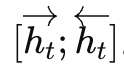 。這種綜合表示既包含了過去的信息,也包含了未來的信息,為后續任務(如分類、標注、生成)提供了更完整的上下文。
。這種綜合表示既包含了過去的信息,也包含了未來的信息,為后續任務(如分類、標注、生成)提供了更完整的上下文。
2. 詳細例子:命名實體識別(NER)
任務說明:
在命名實體識別任務中,我們需要從一段文本中識別出人名、地點、組織等實體。正確判斷一個詞是否為實體,往往需要綜合該詞前后的上下文信息。
輸入示例:
假設有一句話:"Barack Obama visited Berlin last summer."
我們對這句話進行分詞,得到:
["Barack",?"Obama",?"visited",?"Berlin",?"last",?"summer"]
雙向RNN建模:
-
正向處理:
正向RNN從第一個單詞 "Barack" 開始,一直向后計算隱藏狀態:
其中 f?表示 RNN 單元的前向更新函數,這里可理解為典型的 tanh?(Wx+Uh+b) 形式。
-
反向處理:
反向RNN從最后一個單詞 "summer" 開始,往回計算隱藏狀態:
-
合并隱藏狀態:

模型訓練和輸出:
-
訓練過程中,模型會在每個時間步計算一個預測(例如通過 softmax 輸出每個詞的實體類別標簽)。
-
損失函數(如交叉熵)被計算在整個序列上,反向傳播時兩個方向的梯度分別求出,再根據參數共享機制更新網絡參數。
-
經過訓練,模型能學習到如何利用正向和反向信息共同對每個詞進行分類,從而提高命名實體識別的準確率。
3. 應用場景
-
命名實體識別、序列標注等 NLP 任務
例如,翻譯、情感分析、對話系統中,詞的含義往往受其前后文影響,雙向RNN可以同時捕捉兩側上下文信息,從而提升模型性能。 -
語音識別
在語音識別中,雙向模型可以利用未來和過去的信息提高語音轉寫的準確率,尤其是在需要后處理來消除噪音的場景中更為有效。 -
視頻分析任務
在一些需要同時考慮前后幀信息的任務(如視頻中的動作識別)中,雙向信息也能提供更全面的時間上下文。
雙向循環神經網絡通過并行計算正向和反向隱藏狀態,并將它們合并為每個時間步的最終表示,使得每個時間步的輸出不僅利用了過去信息,也利用了未來信息。以命名實體識別任務為例,雙向RNN能夠為每個單詞提供全局上下文的特征,顯著提升了序列標注的準確性。這種方法廣泛應用于需要全局語境理解的自然語言處理、語音識別和視頻分析任務中,成為提升序列模型性能的重要技術之一。

讀寫操作、文件類型轉換、數據分析代碼講解)








)
?? 風險)







![[Lc] 最長公共子序列 | Fenwick Tree(樹狀數組):處理動態前綴和](http://pic.xiahunao.cn/[Lc] 最長公共子序列 | Fenwick Tree(樹狀數組):處理動態前綴和)