目錄
LCR 095. 最長公共子序列
題解
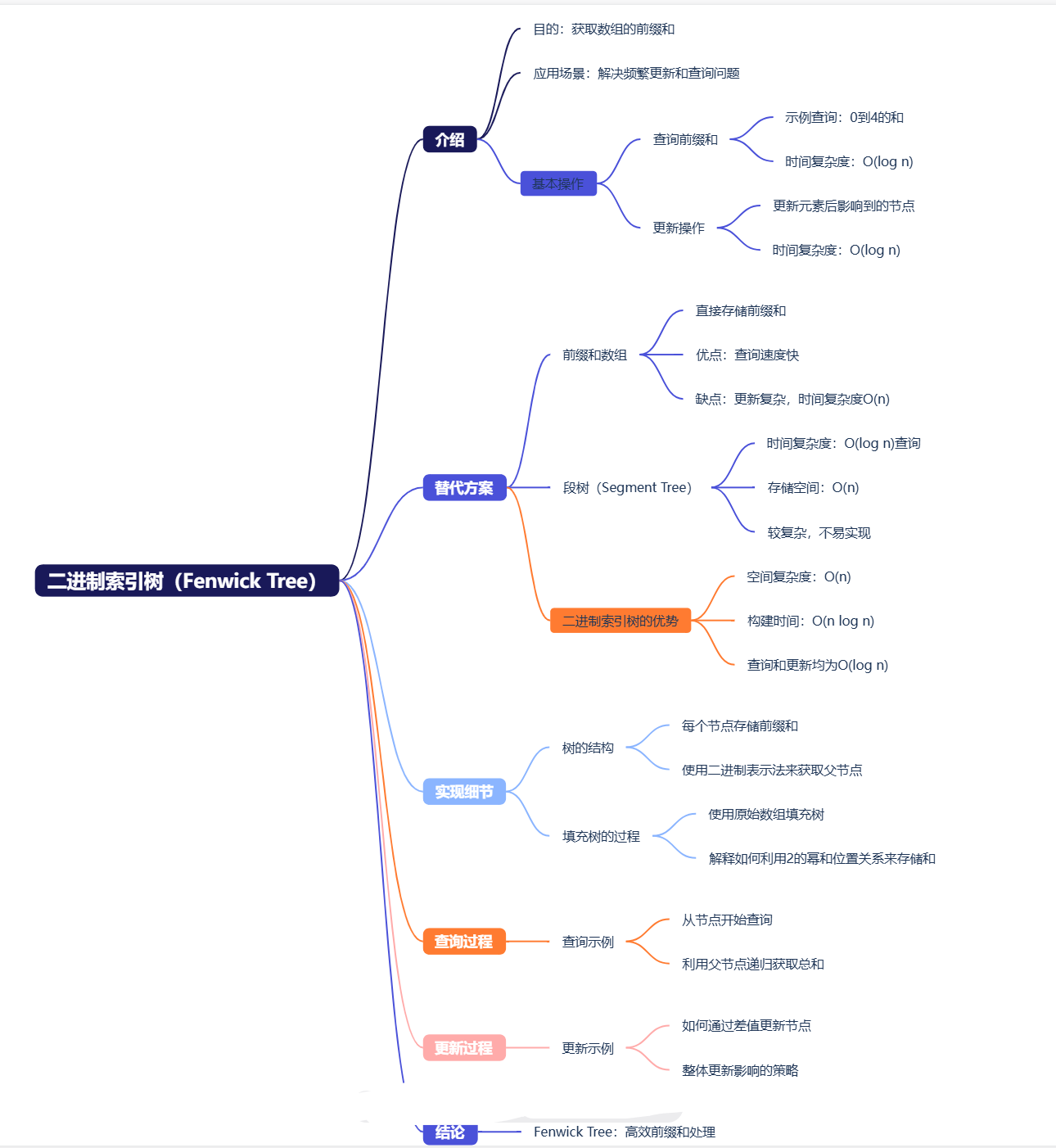
Fenwick Tree(樹狀數組):處理動態前綴和
一、問題背景:當傳統方法遇到瓶頸
二、Fenwick Tree核心設計
2.1 二進制索引的魔法
2.2 關鍵操作解析
更新操作(O(log n))
查詢操作(O(log n))
三、實現細節精要
3.1 初始化優化
3.2 空間壓縮技巧
四、性能對比分析
五、進階應用場景
六、實現注意事項
七、與其他數據結構的配合
延伸閱讀
LCR 095. 最長公共子序列
給定兩個字符串 text1 和 text2,返回這兩個字符串的最長 公共子序列 的長度。如果不存在 公共子序列 ,返回 0 。
一個字符串的 子序列 是指這樣一個新的字符串:它是由原字符串在不改變字符的相對順序的情況下刪除某些字符(也可以不刪除任何字符)后組成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
兩個字符串的 公共子序列 是這兩個字符串所共同擁有的子序列。
示例 1:
輸入:text1 = "abcde", text2 = "ace"
輸出:3
解釋:最長公共子序列是 "ace" ,它的長度為 3 。題解
兩個字符串可能存在多個公共子序列,題目要求計算最長公共子序列的長度,因此可以考慮使用動態規劃來解決。
二維DP數組
- 用函數 f(i, j) 表示字符串 s1 中下標從 0 開始到 i 的子字符串 s1[0...i] 和字符串 s2 中下標從 0 開始到 j 的子字符串 s2[0...j] 的最長公共子序列的長度。
- 對于 f(i, j),如果 s1[i] == s2[j],那么相當于在 s1[0...i - 1] 和 s2[0...j - 1] 的最長公共子序列的后面添加一個公共字符,也就是 f(i, j) = f(i - 1, j - 1) + 1。
- 如果 s1[i] != s2[j],那么這兩個字符不可能出現在 s1[0...i] 和 s2[0...j] 的公共子序列中。
- 此時 s1[0...i] 和 s2[0...j] 的最長公共子序列是s1[0...i - 1] 和 s2[0...j] 的最長公共子序列和s1[0...i] 和 s2[0...j - 1] 的最長公共子序列中的較大值,即 f(i, j) = max(f(i - 1, j), f(i, j - 1))。 (子序列的特性,決定了可以這么寫
- 所以轉移狀態方程為
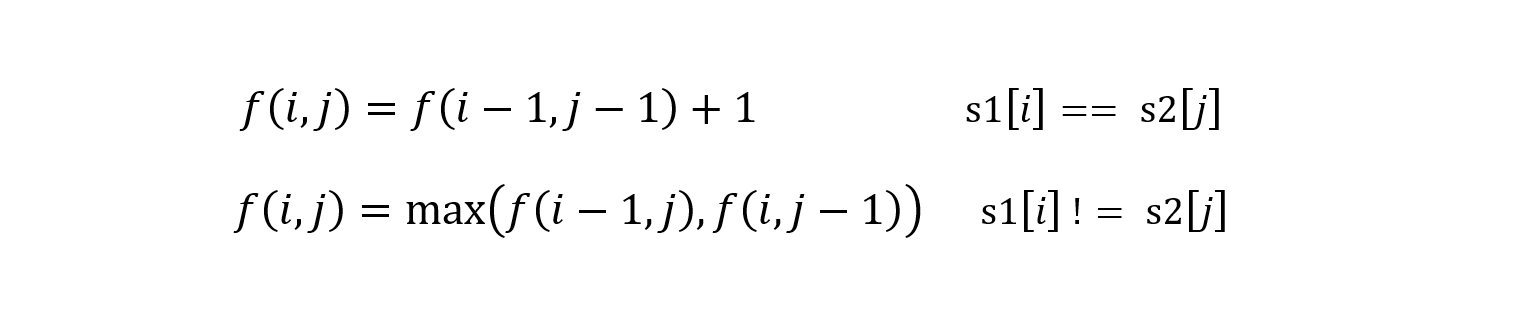
因為狀態方程有兩個變量,所以需要使用二維矩陣保存。同時上述方程會出現 i 或者 j 出現 -1 的情況,代表出現 -1 下標的字符串的子串目前是空的,那么就不會有公共子序列,所以 f(i, -1) = f(-1, j) = 0。
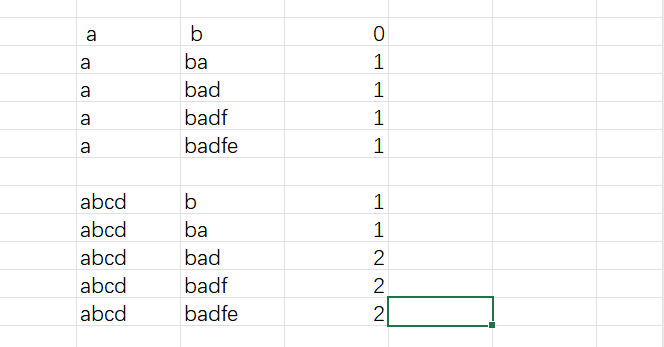
以 "abcde" 和 "badfe" 為例子,二維狀態矩陣如下圖
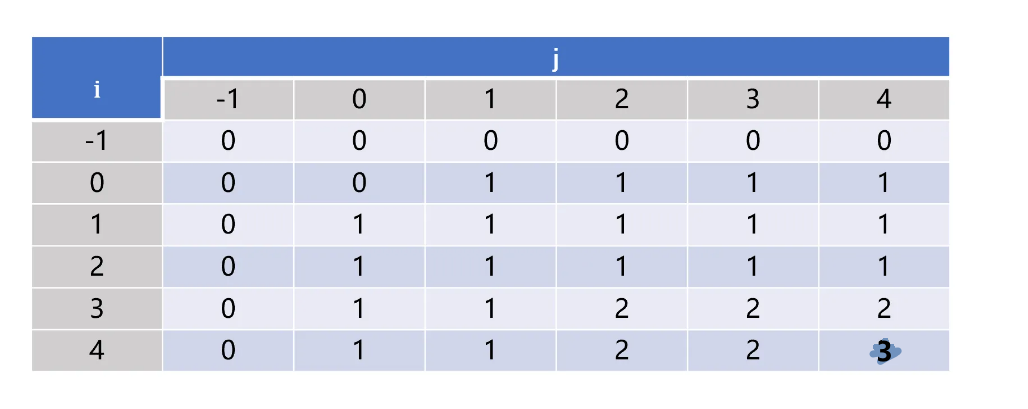
一開始先完成 f(i, -1) = f(-1, j) = 0 初始化,之后二維矩陣按照從左往右逐行向下遍歷填充。
- 推薦使用逐行而不是逐列,雖然不影響算法,但是考慮到二維數組本身是按照一維數組存儲以及計算機緩存的運行機制,按照逐行遍歷的方式效率更高點。
- 完整的代碼如下,若 s1 和 s2 的長度分別為 m 和 n,那么時間復雜度為 O(mn),空間復雜度為 O(mn)。
class Solution {
public:int longestCommonSubsequence(string text1, string text2) {int n1 = text1.size();int n2 = text2.size();vector<vector<int>> dp(n1 + 1, vector<int>(n2 + 1));for (int i = 0; i < n1; ++i) {for (int j = 0; j < n2; ++j) {if (text1[i] == text2[j]) {dp[i + 1][j + 1] = dp[i][j] + 1;} else {dp[i + 1][j + 1] = max(dp[i][j + 1], dp[i + 1][j]);}}} return dp[n1][n2];}
};- 當前==,就f(i - 1, j - 1) + 1
- 當前不等,就存遍歷過的最大max(f(i - 1, j), f(i, j - 1))
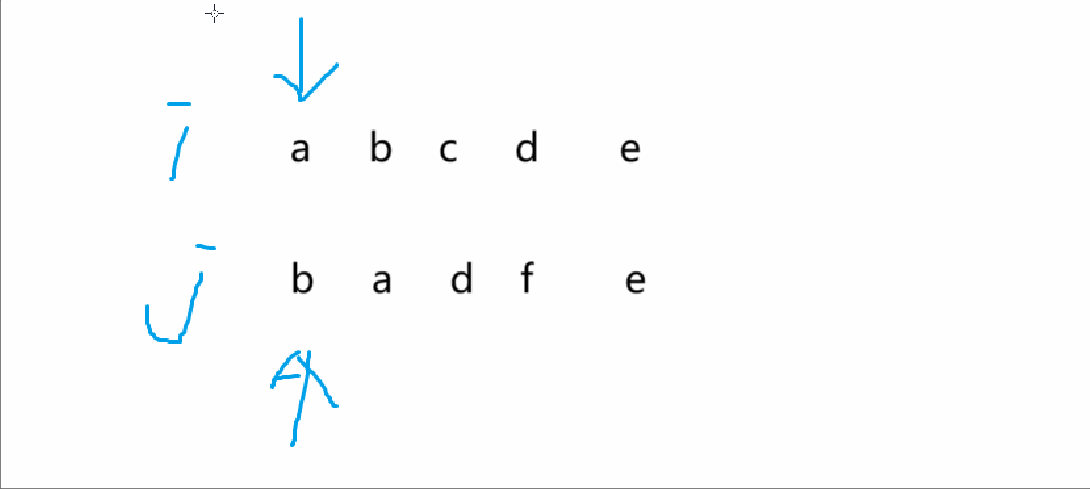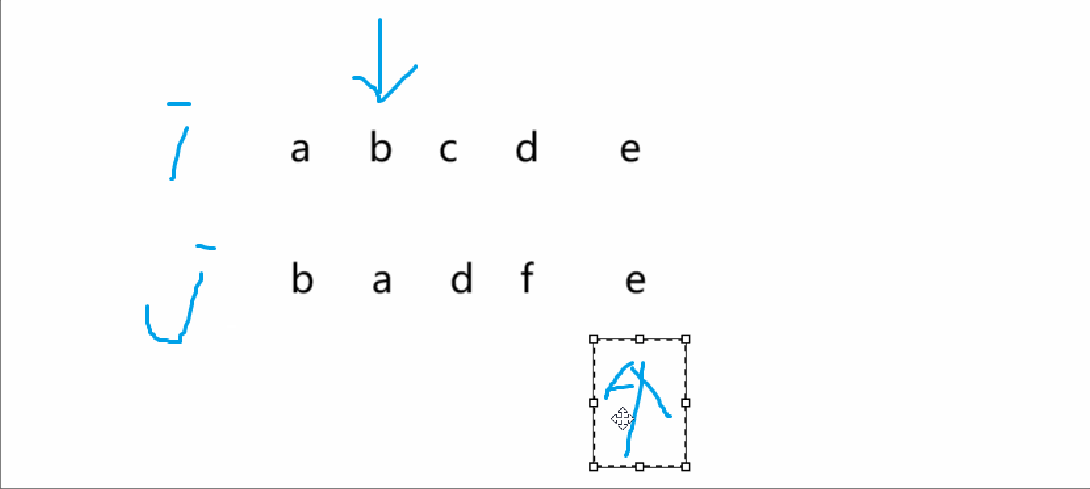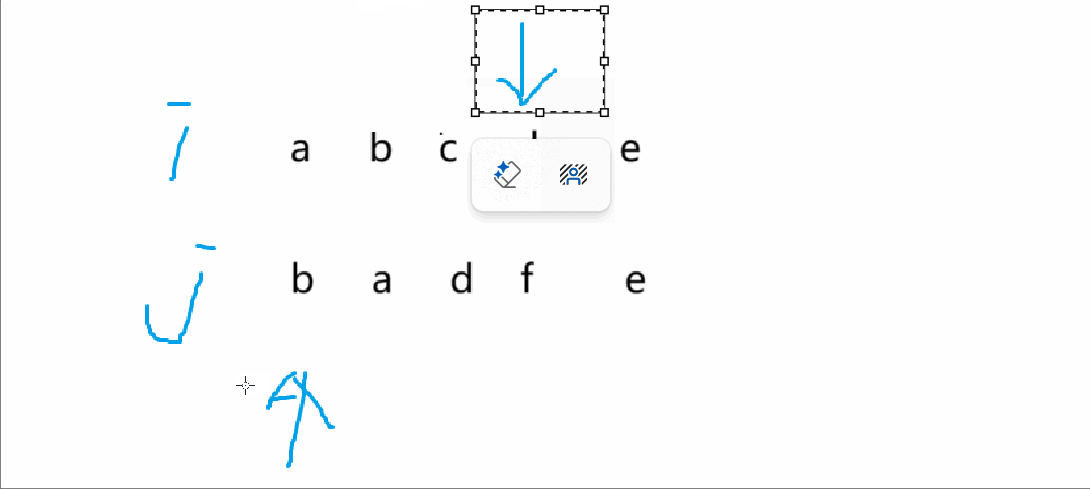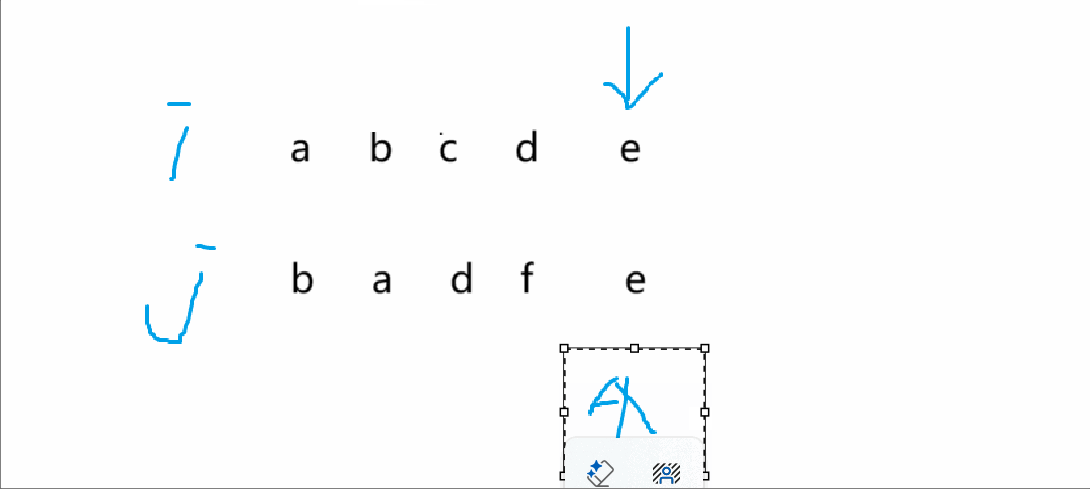
遍歷
將 i==0 和 i==3 的情況來查看一下
2179. 統計數組中好三元組數目
給你兩個下標從 0 開始且長度為 n 的整數數組 nums1 和 nums2 ,兩者都是 [0, 1, ..., n - 1] 的 排列 。
好三元組 指的是 3 個 互不相同 的值,且它們在數組 nums1 和 nums2 中出現順序保持一致。換句話說,如果我們將 pos1v 記為值 v 在 nums1 中出現的位置,pos2v 為值 v 在 nums2 中的位置,那么一個好三元組定義為 0 <= x, y, z <= n - 1 ,且 pos1x < pos1y < pos1z 和 pos2x < pos2y < pos2z 都成立的 (x, y, z) 。
請你返回好三元組的 總數目 。
示例 1:
輸入:nums1 = [2,0,1,3], nums2 = [0,1,2,3]
輸出:1
解釋:
總共有 4 個三元組 (x,y,z) 滿足 pos1x < pos1y < pos1z ,分別是 (2,0,1) ,(2,0,3) ,(2,1,3) 和 (0,1,3) 。
這些三元組中,只有 (0,1,3) 滿足 pos2x < pos2y < pos2z 。所以只有 1 個好三元組。示例 2:
輸入:nums1 = [4,0,1,3,2], nums2 = [4,1,0,2,3]
輸出:4
解釋:總共有 4 個好三元組 (4,0,3) ,(4,0,2) ,(4,1,3) 和 (4,1,2) 。下標比較相當于是一種映射規則。現在我在這種映射規則上再施加一種映射規則,讓在nums1中滿足下標遞增這種性質映射為鍵值遞增這種性質。
同樣的對nums2施加這種規則,下標遞增也應該映射為鍵值遞增。有一點點往這方面想,不看題解根本無法完全想出來。
template<typename T>
class FenwickTree {vector<T> tree;public:// 使用下標 1 到 nFenwickTree(int n) : tree(n + 1) {}// a[i] 增加 val// 1 <= i <= nvoid update(int i, T val) {for (; i < tree.size(); i += i & -i) {tree[i] += val;}}// 求前綴和 a[1] + ... + a[i]// 1 <= i <= nT pre(int i) const {T res = 0;for (; i > 0; i &= i - 1) {res += tree[i];}return res;}
};class Solution {
public:long long goodTriplets(vector<int>& nums1, vector<int>& nums2) {int n = nums1.size();vector<int> p(n);for (int i = 0; i < n; i++) {p[nums1[i]] = i;}long long ans = 0;FenwickTree<int> t(n);for (int i = 0; i < n - 1; i++) {int y = p[nums2[i]];int less = t.pre(y);ans += (long) less * (n - 1 - y - (i - less));t.update(y + 1, 1);}return ans;}
};
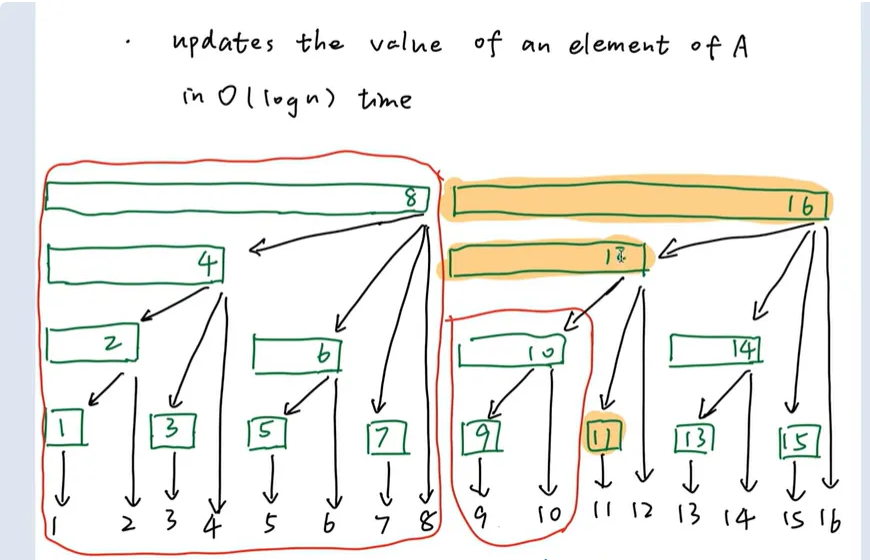

Fenwick Tree(樹狀數組):處理動態前綴和
一、問題背景:當傳統方法遇到瓶頸
在數據處理場景中,我們常需要快速計算數組的前綴和(Prefix Sum)。
傳統的前綴和數組方法雖然能在O(1)時間完成查詢,但面對頻繁更新的動態數據時,其O(n)的更新時間復雜度將成為性能瓶頸。
想象一個股票交易系統需要實時追蹤每分鐘的成交額統計,這種場景正是Fenwick Tree大顯身手的戰場。
二、Fenwick Tree核心設計
2.1 二進制索引的魔法
該數據結構的核心創新在于將數組索引的二進制表示轉化為層次結構。每個索引對應的二進制最低有效位(LSB)決定了其管理的數據范圍:
- 索引i的LSB位置k(從1開始計數)
- 該節點負責管理區間[i - 2^{k-1} + 1, i]的數據
2.2 關鍵操作解析
更新操作(O(log n))
def update(i, delta):while i <= n:tree[i] += deltai += i & -i # 找到下一個父節點查詢操作(O(log n))
def query(i):res = 0while i > 0:res += tree[i]i -= i & -i # 剝離最低有效位return res三、實現細節精要
3.1 初始化優化
# 最優初始化方式(時間復雜度O(n))
def build(arr):n = len(arr)tree = [0]*(n+1)for i in range(1, n+1):tree[i] += arr[i-1]j = i + (i & -i)if j <= n:tree[j] += tree[i]return tree3.2 空間壓縮技巧
通過將原始數組映射到樹狀數組的奇數索引位置,可以節省約50%的內存空間。這種優化在嵌入式系統或處理海量數據時尤為重要。
四、性能對比分析
| 操作類型 | 前綴和數組 | Fenwick Tree |
| 初始化 | O(n) | O(n) |
| 單點更新 | O(n) | O(log n) |
| 范圍查詢 | O(1) | O(log n) |
| 空間復雜度 | O(n) | O(n) |
適用場景選擇指南:
- 靜態數據:優先選擇前綴和數組
- 動態數據:必選Fenwick Tree
- 混合操作:根據更新/查詢頻率比例決策
五、進階應用場景
- 逆序對統計:結合離散化技術,可在O(n log n)時間內完成
- 多維擴展:二維Fenwick Tree支持矩陣區域求和
- 頻率統計:實現高效的可變范圍頻率查詢
- 實時推薦系統:動態維護用戶行為熱度排名
六、實現注意事項
- 索引通常從1開始(避免處理0的特殊情況)
- 更新操作是增量式的(delta為變化量而非絕對值)
- 合理選擇數據存儲類型(防止整數溢出)
- 注意緩存友好性(順序訪問優于隨機訪問)
七、與其他數據結構的配合
- 與線段樹結合實現區間更新/區間查詢
- 聯合哈希表處理稀疏數據
- 配合持久化技術實現歷史版本查詢
延伸閱讀
- 原理解析視頻
- 《算法導論》第15章高級數據結構
- ACM競賽中的經典應用案例集

)

)







)


![LeetCode[541]反轉字符串Ⅱ](http://pic.xiahunao.cn/LeetCode[541]反轉字符串Ⅱ)




