目錄
一、跳表的概念
為什么要使用隨機值來確定層高
二、跳表的分析
(1)查找過程
(2)性能分析
三、跳表的實現
四、與紅黑樹哈希表的對比
skiplist本質上也是一種查找結構,用于解決算法中的查找問題,跟平衡搜索樹和哈希表的價值是
一樣的,可以作為key或者key/value的查找模型。
一、跳表的概念
跳表是受到有序鏈表的啟發上發展而來的。
 但是可以看到鏈表查找的效率是O(N)。那么有人就在想了,能不能讓他每間隔幾個節點就升高一層,這樣可以更快的跳到后面,從而提高查找效率。
但是可以看到鏈表查找的效率是O(N)。那么有人就在想了,能不能讓他每間隔幾個節點就升高一層,這樣可以更快的跳到后面,從而提高查找效率。
????????假如每相鄰兩個節點升高一層,增加一個指針,讓指針指向下下個節點,如圖b。這樣所有新增加的指針連成了一個新的鏈表,但它包含的節點個數只有原來的一半。由于新增加的指針,我們不再需要與鏈表中每個節點逐個進行比較了,需要比較的節點數大概只有原來的一半。
此時的效率就變成了O(logN)
那是不是意味著層數越高,查找的效率也就越高。我們可以在第二層新產生的鏈表上,繼續為每相鄰的兩個節點升高一層,增加一個指針,從而產生第三層鏈表。如下圖c,這樣搜索效率就進一步提高了。


????????但是人們發現,這樣效率雖然極高。但是一旦涉及到插入和刪除操作,就會改變該節點后面的所有節點的層高,因為我們規定了必須每隔幾個就提高一層。這樣即使在查找的時候效率很高,但是會由于插入操作,重新遍歷后面的節點進行層高重構,導致效率又回歸了O(N)。? ? ? ??
為什么要使用隨機值來確定層高
? ? ? ? 如果我們插入和刪除不會改變后面的層高呢?舉個例子,本來每次間隔1個要提高一層,但是現在我不再改變后面節點的層高了,我插入的新節點是多高就把他直接鏈接到鏈表中,是不是就規避了重構結構的損耗。
? ? ? ? 但是如果插入的高度是固定的,這就相當于沒有利用到跳表的優化。最開始我想能不能給一個數組來決定該節點有多少層呢?答案發現是不行的。
所以這里我們采取的是隨機值的辦法來決定新節點到底有多高。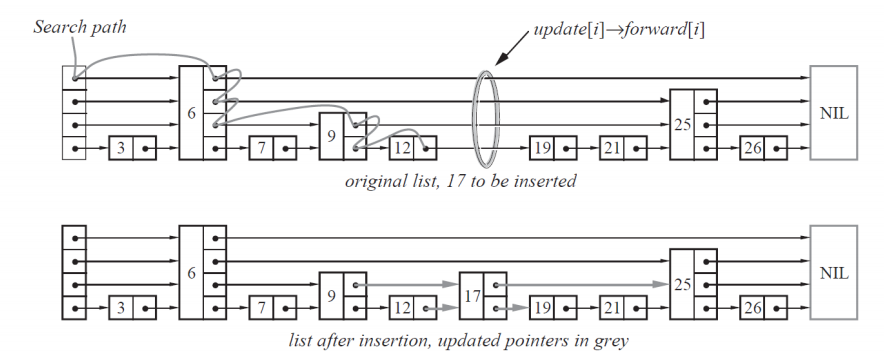
二、跳表的分析
(1)查找過程

查找19分析:
從頭節點的最上面的節點開始, next=6,19大于6.直接向右跳到6. next=空,向下走,next=25.25大于19.再向下走. next=9.19大于9,向右走到9. next=17. 19大于17, 向右跳到17. next=25. 25大于19.向下走. next=19.找到19. 總結: 比它大, 向右走. 比它小, 向下走
插入/刪除分析:
插入和刪除操作的關鍵都是, 找到此位置的每一層節點的前一個和后一個節點. 插入和刪除和其他節點無關, 只需要修改每一層的next指針指向即可. 比如現在要在節點7和9之間插入節點8. 節點8假設是三層. 那么插入只需要考慮節點8的第一層和第二層的前一個節點是6,而第三層的前一個節點是7. 第一層的后一個節點是25.第二層的后一個節點是9.第三次的后一個節點也是9. 依次改變指針知曉即可.
(2)性能分析
????????skiplist插入一個節點時隨機出一個層數,聽起來怎么這么隨意,如何保證搜索時的效率呢?這里首先要細節分析的是這個隨機層數是怎么來的。一般跳表會設計一個最大層數maxLevel的限制,其次會設置一個多增加一層的概率p。那么計算這個隨機層數的偽代碼如下圖:



當數據量足夠大的時候,他的時間復雜度就是O(logN),這個效率是和紅黑樹等搜索樹相當的,非常可觀。
三、跳表的實現
struct SkipListNode {int _val;vector<SkipListNode*> _nextv;SkipListNode(int val, int height) :_val(val), _nextv(height, nullptr){}
};
class Skiplist {typedef SkipListNode node;
public:Skiplist() {//頭節點層數先給1層_head = new node(-1, 1);srand(time(0));}bool search(int target) {node* cur = _head;int level = _head->_nextv.size() - 1;while (level >= 0){//和cur->next[level]比較,比它小就向下走,比它大向右走if (cur->_nextv[level] && cur->_nextv[level]->_val < target)cur = cur->_nextv[level];//下一個節點是空,即是尾,也要向下走else if (!cur->_nextv[level] || cur->_nextv[level]->_val > target)level--;else return true;}return false;}vector<node*> FindPrevNode(int num){node* cur = _head;int level = _head->_nextv.size() - 1;vector<node*> prev(level + 1, _head);//用于保存每一層的前一個while (level >= 0){//一旦要向下走了,就可以更新了,向右走不需要動if (cur->_nextv[level] && cur->_nextv[level]->_val < num)cur = cur->_nextv[level];else if (cur->_nextv[level] == nullptr || cur->_nextv[level]->_val >= num){prev[level] = cur;--level;}}return prev;}void add(int num) {vector<node*> prev = FindPrevNode(num);int n = RandomLevel();node* newnode = new node(num, n);if (_head->_nextv.size() < n){_head->_nextv.resize(n, nullptr);prev.resize(n, _head);}//鏈接前后節點即可for (int i = 0; i < n; i++){//新節點的下一個是prev的下一個newnode->_nextv[i] = prev[i]->_nextv[i];prev[i]->_nextv[i] = newnode;}}bool erase(int num) {//要刪除你,先找到此節點的每層的前一個,和插入時相似vector<node*> prev = FindPrevNode(num);//代表這個值不存在, 最下層找不到它,它就一定不存在if (prev[0]->_nextv[0] == nullptr || prev[0]->_nextv[0]->_val != num)return false;node* del = prev[0]->_nextv[0];for (int i = 0; i < del->_nextv.size(); i++)prev[i]->_nextv[i] = del->_nextv[i];delete del;return true;}int RandomLevel(){int level = 1;while (rand() < RAND_MAX * _p && level < _max)level++;return level;}void Print(){int level = _head->_nextv.size();for (int i = level - 1; i >= 0; --i){node* cur = _head;while (cur){printf("%d->", cur->_val);cur = cur->_nextv[i];}printf("\n");}}
private:node* _head;size_t _max = 32;double _p = 0.5;
};
四、與紅黑樹哈希表的對比

總結:
- 平均空間開銷:
- 跳表的額外空間主要用于存儲多層指針,平均每個節點增加的指針數為?O(log n)。
- 相比平衡樹(如紅黑樹),跳表的空間開銷更可控。(因為紅黑樹是一個三叉鏈,每一個節點都要要存儲3個節點)
- 對比哈希表:
- 哈希表需要額外的空間存儲哈希桶和處理沖突,空間開銷可能更高。
- 極端情況下哈希表會退化成鏈表,從而要使用紅黑樹。
- 哈希表一旦擴容,則需要對原來的每一個元素重新映射,并且還要拷貝到新表中。如果擴容策略較為激進,則會導致空間開銷較大。





)


機器學習---邏輯回歸及其Python實現)










——微信小程序學習筆記)