文章目錄
- 前言
- 一、多頭注意力機制介紹
- 1.1 工作原理
- 1.2 優勢
- 1.3 代碼實現概述
- 二、代碼解析
- 2.1 導入依賴
- 序列掩碼函數
- 2.2 掩碼 Softmax 函數
- 2.3 縮放點積注意力
- 2.4 張量轉換函數
- 2.5 多頭注意力模塊
- 2.6 測試代碼
- 總結
前言
在深度學習領域,注意力機制(Attention Mechanism)是自然語言處理(NLP)和計算機視覺(CV)等任務中的核心組件之一。特別是多頭注意力(Multi-Head Attention),作為 Transformer 模型的基礎,極大地提升了模型對復雜依賴關系的捕捉能力。本文通過分析一個完整的 PyTorch 實現,帶你深入理解多頭注意力的原理和代碼實現。我們將從代碼入手,逐步解析每個函數和類的功能,結合文字說明,讓你不僅能運行代碼,還能理解其背后的設計邏輯。無論你是初學者還是有一定經驗的開發者,這篇博客都將幫助你更直觀地掌握多頭注意力機制。
完整代碼:下載鏈接
一、多頭注意力機制介紹
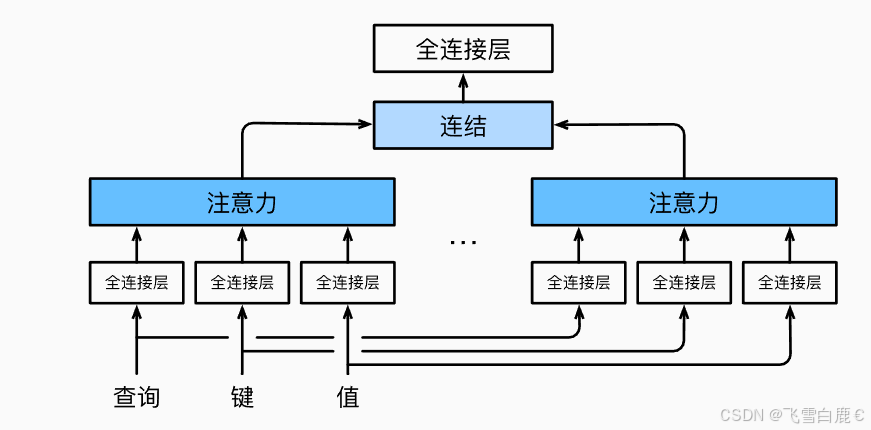
多頭注意力(Multi-Head Attention)是 Transformer 模型的核心組件之一,廣泛應用于自然語言處理(NLP)、計算機視覺(CV)等領域。它通過并行運行多個注意力頭(Attention Heads),允許模型同時關注輸入序列中的不同部分,從而捕捉更豐富的語義和上下文依賴關系。相比單一的注意力機制,多頭注意力極大地增強了模型的表達能力,能夠處理復雜的模式和長距離依賴。
1.1 工作原理
多頭注意力的核心思想是將輸入的查詢(Queries)、鍵(Keys)和值(Values)通過線性變換映射到多個子空間,每個子空間由一個獨立的注意力頭處理。具體步驟如下:
- 線性變換:對輸入的查詢、鍵和值分別應用線性層,將其映射到隱藏維度(
num_hiddens),并分割為多個頭的表示。 - 縮放點積注意力:每個注意力頭獨立計算縮放點積注意力(Scaled Dot-Product Attention),即通過查詢和鍵的點積計算注意力分數,再與值加權求和。
- 并行計算:多個注意力頭并行運行,每個頭關注輸入的不同方面,生成各自的輸出。
- 合并與變換:將所有頭的輸出拼接起來,并通過一個線性層融合,得到最終的多頭注意力輸出。
這種設計允許模型在不同子空間中學習不同的特征,例如在 NLP 任務中,一個頭可能關注句法結構,另一個頭可能關注語義關系。
1.2 優勢
- 多樣性:多頭機制使模型能夠從多個角度理解輸入,捕捉多樣化的模式。
- 并行性:多頭計算可以高效并行化,提升計算效率。
- 穩定性:通過縮放點積(除以特征維度的平方根),緩解了高維點積導致的數值不穩定問題。
1.3 代碼實現概述
在本文的實現中,我們使用 PyTorch 構建了一個完整的多頭注意力模塊,包含以下關鍵部分:
- 序列掩碼:處理變長序列,屏蔽無效位置。
- 縮放點積注意力:實現單個注意力頭的計算邏輯。
- 張量轉換:通過
transpose_qkv和transpose_output函數實現多頭分割與合并。 - 多頭注意力類:整合所有組件,完成并行計算和輸出融合。
接下來的代碼解析將詳細展示這些部分的實現,幫助你從代碼層面深入理解多頭注意力的每一步計算邏輯。
二、代碼解析
以下是代碼的完整實現和詳細解析,代碼按照 Jupyter Notebook(在最開始給出了完整代碼下載鏈接) 的結構組織,并附上文字說明,幫助你理解每個部分的邏輯。
2.1 導入依賴
首先,我們導入必要的 Python 包,包括數學運算庫 math 和 PyTorch 的核心模塊 torch 和 nn。
# 導入包
import math
import torch
from torch import nn
- math:用于計算縮放點積注意力中的歸一化因子(即特征維度的平方根)。
- torch:PyTorch 的核心庫,提供張量運算和自動求導功能。
- nn:PyTorch 的神經網絡模塊,包含
nn.Module和nn.Linear等工具,用于構建神經網絡層。
序列掩碼函數
在處理序列數據(如句子)時,不同序列的長度可能不同,我們需要通過掩碼(Mask)來屏蔽無效位置,防止模型關注這些填充區域。以下是 sequence_mask 函數的實現:
def sequence_mask(X, valid_len, value=0):"""在序列中屏蔽不相關的項,使超出有效長度的位置被設置為指定值參數:X: 輸入張量,形狀 (batch_size, 最大序列長度, 特征維度) 或 (batch_size, 最大序列長度)valid_len: 有效長度張量,形狀 (batch_size,),表示每個序列的有效長度value: 屏蔽值,標量,默認值為 0,用于填充無效位置返回:輸出張量,形狀與輸入 X 相同,無效位置被設置為 value"""maxlen = X.size(1) # 最大序列長度,標量# 創建掩碼,形狀 (1, 最大序列長度),與 valid_len 比較生成布爾張量,形狀 (batch_size, 最大序列長度)mask = torch.arange(maxlen, dtype=torch.float32, device=X.device)[None, :] < valid_len[:, None]# 將掩碼取反后,X 的無效位置被設置為 valueX[~mask] = valuereturn X
解析:
- 輸入:
X:輸入張量,通常是序列數據,可能包含填充(padding)部分。valid_len:每個樣本的有效長度,例如[3, 2]表示第一個樣本有 3 個有效 token,第二個樣本有 2 個。value:用于填充無效位置的值,默認為 0。
- 邏輯:
maxlen獲取序列的最大長度(即張量的第二維)。torch.arange(maxlen)創建一個從 0 到maxlen-1的序列,形狀為(1, maxlen)。- 通過廣播機制,與
valid_len(形狀(batch_size, 1))比較,生成布爾掩碼mask,形狀為(batch_size, maxlen)。 mask表示哪些位置是有效的(True),哪些是無效的(False)。- 使用
~mask選擇無效位置,將其值設置為value。
- 輸出:修改后的張量
X,無效位置被設置為value,形狀不變。
作用:該函數用于在注意力計算中屏蔽填充區域,確保模型只關注有效 token。
2.2 掩碼 Softmax 函數
在注意力機制中,我們需要對注意力分數應用 Softmax 操作,將其轉換為概率分布。但由于序列長度不同,需要屏蔽無效位置的貢獻。以下是 masked_softmax 函數的實現:
import torch
import torch.nn.functional as Fdef masked_softmax(X, valid_lens):"""通過在最后一個軸上掩蔽元素來執行softmax操作,忽略無效位置參數:X: 輸入張量,形狀 (batch_size, 查詢個數, 鍵-值對個數),3D張量valid_lens: 有效長度張量,形狀 (batch_size,) 或 (batch_size, 查詢個數),1D或2D張量,表示每個序列的有效長度,即每個查詢可以參考的有效鍵值對長度返回:輸出張量,形狀 (batch_size, 查詢個數, 鍵-值對個數),softmax后的注意力權重"""if valid_lens is None:# 如果沒有有效長度,直接在最后一個軸上應用softmaxreturn F.softmax(X, dim=-1)shape 














)



