RDP 論文
- 通過 AR 提供實時觸覺/力反饋;
- 慢速擴散策略,用于預測低頻潛在空間中的高層動作分塊;快速非對稱分詞器實現閉環反饋控制。
ACT、 π 0 \pi_0 π0? 采取了動作分塊,在動作分塊執行期間處于開環狀態,無法及時響應環境變化,缺乏觸覺輸入,無法適應高精度(力控制)任務和及時響應。現有的觸覺輸入是側重于觀察方面,利用觸覺輸入提供視覺遮擋或接觸狀態判斷等信息。在數據上,MTDP(Mixed-Teleoperation Demonstration Policy)通過增強現實(AR)技術實現了兩大突破性改進:1)異構機器人兼容性 - 克服了傳統ALOHA雙邊控制系統必須使用同構機器人的限制;2)成本優化 - 相比基于專業力/扭矩傳感器的觸覺反饋方案,顯著降低了硬件成本。并且現有的觸覺輸入的方案均排除了視覺輸入。
- 力/扭矩傳感器——直接測量末端或關節的力/扭矩數值,高速運動時噪聲明顯且成本高。
- 觸覺傳感器
- 電學式觸覺傳感器——通過電容、電阻等原理感知,空間分辨率較低,且少數型號能直接輸出法向力與切向力,且需依賴力/扭矩傳感器標定;
- 光學式觸覺傳感器——通過相機捕捉凝膠變形的高分率圖像,追蹤凝膠表面的法向/剪切變形場,力/扭矩信息需通過剪切長間接表征。
MTDP 采取 GelSight Mini 和 MCTrac 兩種光學式觸覺傳感器和機器臂關節扭矩傳感器。將法向力、剪切力、視覺 RGB 輸入輸入為統一的visual-tactile policy。
數據集為利用 GelSIght Mini 收集的 30min 的隨機交互視頻和使用 MCTrac 為剝皮任務收集的 60 次演示,為擦拭任務收集的 80 次演示,為雙手抬舉任務收集的 50 次演示。
TactAR

25 Hz 是因為限制于 GelSight 幀速率限制。
從二維光流推算力數據依賴傳感器的標定,采用可視化三維變形場:
- 標記點提取:通過 OpenCV 從觸覺圖像 I t I_t It? 中提取歸一化標記點位置 D t D_t Dt?;
- 光流計算:基于得分追蹤算法(Gelsight SDK)計算初始幀 D 0 D_0 D0? 與當前幀 D t D_t Dt? 的二維光流 F t = [ d x , d y ] = F l o w ( D 0 , D t ) F_t=[d_x,d_y]=Flow(D_0,D_t) Ft?=[dx?,dy?]=Flow(D0?,Dt?);
- 三維變形場:將光流擴展為含 z 軸偏移 o z o_z oz? 的三維變形場 V t = [ f x , f y , f z ] V_t=[f_x,f_y,f_z] Vt?=[fx?,fy?,fz?];
通過 OpenCV 和輕量級追蹤算法,規避傳統光學傳感器的依賴,直接力矢量渲染。
構建流程:使用 Meta Quest3 的 color passthrough 在 Unity 中創建 AR 場景 -> SLAM 實時跟蹤頭顯和控制器位姿 -> 力矢量渲染 -> 根據機器人末端執行器(TCP)實時位姿,通過 ROS2 同步觸覺數據、機器人狀態和相機流
跟蹤算法延遲 10ms,Quest3 渲染延遲 10ms,網絡延遲 1-6ms,光學觸覺傳感器 10-60ms,力傳感器延遲 1ms
RDP

VISK 通過聚合同一時間步的多次迭代的預測結果實現實時反饋,但削弱了策略對多模態分布和非馬兒可夫動作的建模能力,且對平滑系數相當敏感。
AT 由一個 1D-CNN(建模時序性) 和 GRU decoder 組成。通過觸覺序列 F r e d u c e d F^{reduced} Freduced (經過 PCA 降維后——光學觸覺傳感器的變形場可以被分解為幾個高度可解釋的獨立成分)重建動作 A ^ = D ( c o n c a t ( [ Z , F r e d u c e d ] ) ) \hat{A}=\mathcal{D}\left(concat([\boldsymbol{Z},\boldsymbol{F}^{reduced}])\right) A^=D(concat([Z,Freduced])) ,采用 L1 重建損失和 Kullback-Leibler(KL)懲罰損失:(1ms)(通過插值的方式調整)
L A T = E A , F r e d u c e d ∈ D p o l i c y [ ∣ ∣ A ? A ^ ∣ ∣ 1 + λ K L L K L ] L_{AT}=\mathbb{E}_{\boldsymbol{A},\boldsymbol{F}^{reduced}\in\mathcal{D}_{policy}}\left[||A-\hat{A}||_1+\lambda_{KL}L_{KL}\right] LAT?=EA,Freduced∈Dpolicy??[∣∣A?A^∣∣1?+λKL?LKL?]
LDP 利用學習到的梯度場 ? E ( A ) \nabla E(A) ?E(A),通過隨機 Langevin 動力學,以較低的頻率預測動作。 (100ms)(DP 120ms)
L L D P = E ( O , A 0 ) ∈ D p o l i c y , k , ? k ∥ ? k ? ? θ ( O , Z 0 + ? k , k ) ∥ 2 L_{LDP}=\mathbb{E}_{(\mathbf{O},\mathbf{A}^0)\in\mathcal{D}_{policy},k,\epsilon^k}\|\epsilon^k-\epsilon_\theta(\mathbf{O},\mathbf{Z}^0+\epsilon^k,k)\|_2 LLDP?=E(O,A0)∈Dpolicy?,k,?k?∥?k??θ?(O,Z0+?k,k)∥2?

使用相對末端執行器軌跡進行動作表示,基準幀是動作塊的最后一個觀察幀,計算相對于基準幀的相對變換,將絕對軌跡轉化為相對軌跡。
實驗結果
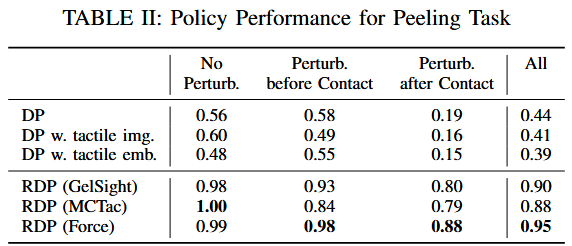
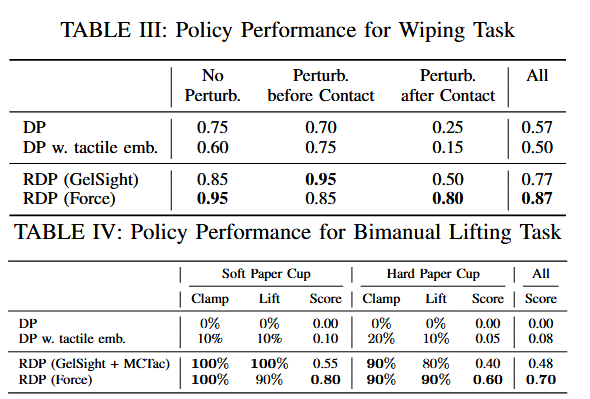





)










)


