A learning-based multiscale method and its application to inelastic impact problems
摘要:
我們在工程應用中觀察和利用的材料宏觀特性,源于電子、原子、缺陷、域等多尺度物理機制間復雜的相互作用。多尺度建模旨在通過利用固有的層次化結構來理解這些相互作用——在更粗尺度上的行為會調控并平均化更細尺度的行為。這需要反復求解計算代價高昂的細尺度模型,且通常需預先知曉那些影響粗尺度的細尺度行為特征(如序參數、狀態變量、描述符等)。我們在雙尺度框架下應對這一挑戰:首先通過離線計算學習細尺度行為,然后將學習到的行為直接應用于粗尺度計算。該方法借鑒了深度神經網絡的最新成果,并結合了模型降階的思想,通過深度神經網絡在高維空間中的逼近能力與模型降階技術相結合,構建出高保真、低計算成本、無需先驗知識約束的神經網絡近似模型,可直接嵌入粗尺度計算中。我們以鎂材料(一種極具潛力的輕質結構和防護材料)的沖擊響應問題為例,驗證了該方法的有效性。
重要性:新材料的開發和優化具有挑戰性,因為材料的宏觀行為是在廣泛的長度和時間尺度上運行的機制的結果。傳統的經驗模型計算成本低,但無法描述這種行為的復雜性。另一方面,高保真的并發多尺度方法用第一性原理建模取代了對經驗信息的需求,但往往成本過高。我們提出了一種方法,通過將機器學習與模型降階相結合來近似細尺度模型的解算器,以經驗模型幾倍的計算成本提供了并發多尺度建模及更高的保真度。
材料的宏觀行為是跨越廣泛時空尺度的多種機制共同作用的結果,其中較大尺度的機制既對較小尺度機制進行篩選(平均化),又對其施加調控(設定邊界條件)。新材料的開發與優化需要理解不同尺度下的機制及其相互作用。傳統研究通過在單一尺度構建模型來分析特定機制,例如:電子尺度、原子尺度、納米尺度、亞晶粒尺度、工程尺度。近年來,多尺度建模成為研究熱點,其核心思想是:
尺度層級劃分:將材料行為分解為多個尺度層級;跨尺度信息傳遞:通過理論工具(如數學均勻化理論)在不同尺度間傳遞關鍵參數(如邊界條件、本構關系);機制協同分析:整合各尺度模型以揭示宏觀行為的形成機理。
多尺度建模方法主要分為兩類:順序多尺度(參數傳遞法)與并發多尺度法,兩者在精度與計算成本間存在顯著權衡。
1. 順序多尺度方法(參數傳遞法)通過下層模型(如原子尺度)計算參數,傳遞給上層模型(如宏觀尺度)以優化經驗模型參數。優勢是計算成本較低,可部分替代實驗參數標定。缺點是粗尺度模型需先驗假設(如本構方程形式),難以適應復雜非線性行為。參數傳遞可能導致跨尺度信息丟失(如瞬態過程的動態耦合效應)。
2. 并發多尺度方法是多尺度模型并行計算,實時交互數據(如邊界條件、狀態變量)。優勢高保真度,可捕捉跨尺度動態耦合效應。局限是計算成本極高:需同時求解多尺度方程,難以處理工程實際問題。描述符依賴:需預先定義跨尺度通信的描述符(如狀態變量、序參數),但其存在性與辨識方法尚不明確,尤其在瞬態現象中(如沖擊載荷下的相變演化)。
多尺度材料建模面臨兩大關鍵挑戰:其一,建模過程需依賴跨尺度交互的先驗經驗知識(如本構方程形式假設);其二,并發多尺度方法需反復求解計算昂貴的細尺度模型,卻僅利用其極小部分信息(如邊界條件),導致資源浪費。這引出了核心問題:如何利用細尺度模型的海量計算數據構建高效代理模型,使其解算器能直接嵌入粗尺度計算而無須額外建模?機器學習為此提供了新思路——深度神經網絡已在圖像識別與自然語言處理中展現出強大的特征提取與高維映射能力,并在材料科學中逐步應用:1)結合理論計算與高通量實驗,加速材料性能預測與優化(如高通量篩選高強鎂合金);2)實現跨尺度參數傳遞(如分子動力學到連續介質模型的彈性參數映射)與實驗數據反演(如通過力學響應識別微觀結構參數);3)構建材料本構行為代理模型(如神經網絡替代晶體塑性計算)及均質化建模(如基于微觀結構圖像預測宏觀彈性模量)。這些進展為多尺度建模的"保真度-效率"平衡提供了創新解決方案。
本研究提出了一種雙尺度建模框架,旨在解決多尺度材料建模中“高保真與低計算成本難以兼顧”的核心挑戰。以多晶非彈性固體沖擊響應問題為例,該框架通過結合模型降階技術與深度神經網絡,實現了宏觀力學問題的高保真求解(保真度達到甚至超越傳統并發多尺度方法),其計算成本僅比經驗模型高數倍。創新點在于:1)突破傳統方法對先驗狀態變量的依賴(如無需預設本構方程中的內變量);2)利用神經網絡直接學習函數空間映射關系(如平均應變歷史→應力響應的偏微分方程解算子),而非傳統離散化子空間,從而避免求解過程受網格分辨率制約;3)采用基于Bhattacharya等人發展的**“模型降階+神經網絡”混合方法**,實現跨尺度映射的高效近似,適用于非均勻材料動態響應等復雜場景。該框架為工程材料沖擊損傷、防護結構設計等實際問題提供了兼具精度與效率的計算工具。
實驗方法
(1)實驗數據驅動替代方案
原則上可直接從實驗數據學習宏觀本構映射Ψ(無需依賴單元胞模型的細尺度計算),但需充足實驗數據支持(如高時空分辨率的動態力學測試)。此外,可通過簡化單元胞模型(如泰勒模型假設單元胞內速度場為零)降低計算復雜度,但會犧牲微觀物理保真度。
(2)模型降階與架構靈活性
降維方法:采用主成分分析(PCA)壓縮輸入(應變歷史)與輸出(應力歷史)空間維度,但可替換為自動編碼器等非線性降維技術。
學習架構:當前使用全連接深度神經網絡,但可擴展為卷積網絡(適用于空間局部特征提取)或隨機特征模型(加速訓練)。
(3)時間依賴性與狀態建模限制
全局時間約束:需在預設的模擬總時長T內訓練模型,而實際工程問題中T可能未知或動態變化。
狀態信息缺失:當前模型僅關聯平均變形梯度與應力歷史,未顯式建模材料內部狀態(如位錯密度、損傷變量)。
記憶效應未假設:未引入記憶衰退假設(如Boltzmann疊加原理),需未來從單元胞數據中學習時序依賴性。
(4)成本分析
離線成本(一次性生成數據與訓練),與訓練時間步長 T 呈線性關系,與訓練數據集規模(模擬次數)及訓練輪次(epochs)正相關
效率對比:離線成本與傳統并發多尺度方法單次模擬成本相當(因所需訓練樣本數≈典型樣本積分點數)
潛在優化:訓練輪次與數據集規模可能受時間步長影響,需進一步研究
在線成本(模擬中神經網絡評估)
計算量級:低于宏觀時間積分成本,但隨模擬時長 T 呈平方增長(需評估完整歷史軌跡)
優勢:在線計算成本僅比經驗本構模型高數倍(如經驗模型為1單位,本文方法為3~5單位)
因已知完整軌跡,可大幅增加宏觀積分時間步長(如從 Δt=1μs 提升至 10μs),顯著提升整體效率。
算法1? 基于機器學習的多尺度建模方法

該算法通過結合離線訓練與在線預測,利用神經網絡替代傳統并發多尺度計算中的細尺度求解,顯著提升材料力學模擬效率。以下是分步解析:
第一階段:離線訓練(材料特性建模)
離線階段旨在通過細尺度模擬構建材料的本構響應數據庫,并訓練機器學習模型替代傳統經驗方程。具體步驟如下:
(1)單元胞問題求解:選取代表材料微結構的單元胞(如多晶體的晶粒集合),施加多種宏觀變形歷史 U(t)(如階梯加載、循環應變),通過有限元或分子動力學計算其響應,記錄平均Cauchy應力 ?σ?(t) 和變形梯度 F(t)。例如,模擬鎂合金在沖擊下位錯運動導致的應力演化。
(2)數據預處理與降維:對變形梯度歷史 F(t) 進行極分解 F=QU,提取右拉伸張量 U(t) 以消除旋轉效應;利用主成分分析(PCA)將高維應變-應力數據壓縮至低維特征空間,減少神經網絡輸入維度。
(3)神經網絡訓練:構建深度神經網絡(如全連接網絡或LSTM),輸入為降維后的變形歷史特征,輸出預測應力歷史。訓練時采用均方誤差損失函數,優化器選擇Adam,通過反向傳播調整權重。最終得到映射 Ψ:U(t)→?σ?(t),隱式編碼材料微觀物理機制。
第二階段:在線模擬(宏觀動力學計算)
在線階段利用訓練好的模型實時預測材料響應,嵌入宏觀有限元框架,實現高效多尺度計算:
問題離散化:將宏觀結構(如骨植入物)離散為有限元網格,每個積分點關聯一個材料響應模型;時間域采用顯式中心差分法離散,步長 Δt 滿足Courant條件。
時間步進循環:
步驟1:在時間步 tn?,積分點接收變形梯度歷史 {Fm?}m≤n?。
步驟2:極分解 Fm?=Qm?Um? 分離旋轉 Qm? 與純變形 Um?,消除剛體運動對應力的影響。
步驟3:插值生成連續變形軌跡 U(t)(如三次樣條擬合 {Um?}),輸入訓練好的神經網絡預測應力 ?σ?(t)。
步驟4:根據當前旋轉 Qn? 修正應力方向:σn?=Qn??σ?(tn?)QnT?,確保客觀性。
步驟5:將 σn? 傳遞至顯式積分器,更新節點位移和速度,推進至 tn+1?。
終止條件:當時刻 tn? 達到預設總時長 T,輸出位移、應力場及損傷演化結果。
?
實驗結果
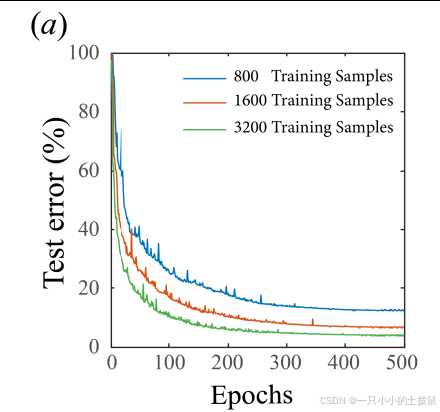
結果如圖1所示。圖1(a)顯示,隨著訓練數據量和訓練輪次的增加,測試誤差(所有測試樣本的平均值)逐漸減小,在3200個樣本、400輪次的訓練中,平均測試誤差降至5%。圖1(b,c)展示了使用3200個樣本和500輪次訓練的神經網絡對典型測試樣本和訓練樣本的輸入和輸出(包括真實值和近似值)。我們得出結論,我們的模型簡化方法能夠學習到地圖Ψ的非常精確的近似。


天牛須算法(Beetle Antennae Search, BAS)詳解與Python實現)
】筑牢家政平臺安全防線:安全測試與漏洞修復指南)













)
)
