基于穿戴裝備的身體活動監測
摘要
本研究基于加速度計采集的活動數據,旨在分析和統計100名志愿者在不同身體活動類別下的時長分布。通過對加速度數據的處理,活動被劃分為睡眠、靜態活動、低強度、中等強度和高強度五類,進而計算每個志愿者在各類活動中的總時長。研究結果揭示了不同個體在活動強度上的差異,為后續的個性化健康管理和運動干預提供了重要數據支持。此外,結合可視化分析,進一步揭示了志愿者的活動模式,幫助更好地理解個體行為差異及群體健康趨勢。
本研究通過無監督學習方法,對志愿者的身體活動數據進行了聚類分析,旨在識別不同的活動模式。基于志愿者的加速度數據和MET 值,本文采用 KMeans 和高斯混合模型(GMM)兩種聚類算法進行活動模式識別。通過聚類分析,成功將志愿者的活動模式劃分為三類:睡眠模式三(深睡)、睡眠模式一(淺睡)和睡眠模式二(中度/REM)。這些活動模式的劃分為進一步理解志愿者的行為模式和睡眠結構提供了依據。通過計算每個模式下的時長,本研究揭示了不同個體在活動強度和睡眠階段上的差異,為后續的健康干預和個性化健康管理提供了數據支持。
本研究進一步對志愿者的久坐行為進行了識別和分析。通過滑動窗口方法,結合加速度數據和MET 值,我們成功識別出志愿者持續超過30分鐘的靜態行為,并計算了每位志愿者的總久坐時長。每個持續靜態狀態的行為段被標記為久坐行為,累計計算每位志愿者的久坐時長。通過隨機森林算法、CNN+LSTM組合算法進行預測。研究結果表明,不同志愿者的久坐行為存在顯著差異,某些個體表現出較高的久坐時長,提示可能需要更強的健康干預措施。通過這一分析,我們為個性化健康干預、久坐行為管理以及健康風險評估提供了有效的數據支持。
關鍵詞:身體活動監測、隨機森林、K-means聚類、GMM、滑動窗口
目錄
基于穿戴裝備的身體活動監測 1
摘要 1
一、 問題重述 3
1.1 問題背景 3
1.2 要解決的問題 3
二、 問題分析 5
2.1 任務一的分析 5
2.2 任務二的分析 5
2.3 任務三的分析 5
2.4 任務四的分析 5
三、 問題假設 7
四、 模型原理 8
4.1 隨機森林模型 8
4.2 K-means聚類算法 9
4.3 GMM模型 11
五、 模型建立與求解 14
5.1 問題一建模與求解 14
5.2 問題二建模與求解 19
5.3 問題三建模與求解 24
5.4 問題四建模與求解 28
六、 模型評價與推廣 31
6.1 模型的評價 31
6.1.1模型優點 31
6.1.2模型缺點 32
6.2 模型推廣 33
附錄【自行刪減】 35
任務 主要技術 關鍵步驟
-
統計分析 數據處理、MET 分類 時間計算、分類統計
-
MET 值預測 機器學習(XGBoost/LSTM) 特征提取、回歸建模
-
睡眠分析 深度學習(CNN/LSTM) 睡眠階段分類
-
久坐預警 滑動窗口分析 連續靜態行為檢測
-
統計分析志愿者的活動情況
目標:
根據 100 位志愿者的加速度數據,計算各項活動時長,并進行統計匯總。
數據說明:
數據存儲在 P[ID].csv 文件,每行包含:
時間戳(毫秒)
X/Y/Z 方向加速度(g)
活動標簽(MET 值)
Metadata1.csv 提供志愿者的性別和年齡信息。
解題思路:
數據讀取:
讀取 P[ID].csv 文件,解析時間戳轉換為小時級別。
讀取 Metadata1.csv,合并志愿者元數據。
計算各項時長:
計算 總記錄時長:時間戳轉換為小時后求總時長。
根據 MET 值分類:
MET ≥ 6.0 → 高強度運動
3.0 ≤ MET < 6.0 → 中等強度運動
1.6 ≤ MET < 3.0 → 低強度運動
1.0 ≤ MET < 1.6 → 靜態行為
MET < 1.0 → 睡眠
統計每種 MET 分類下的時間總量。
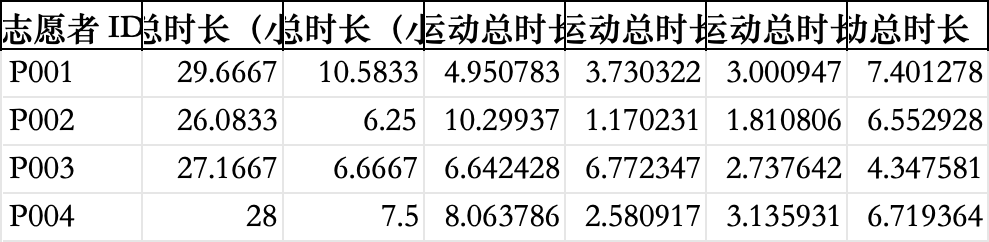
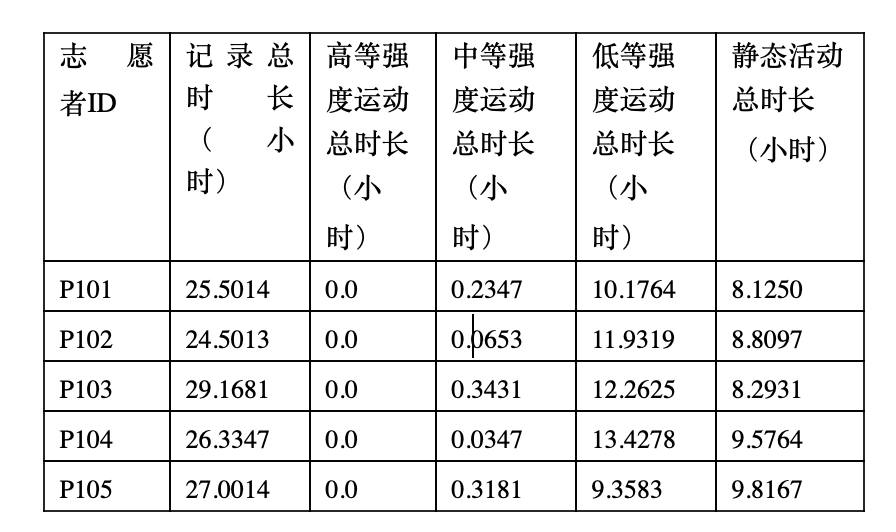
生成表格 result_1.xlsx,列格式: | 志愿者ID | 總時長 | 睡眠時長 | 高強度運動 | 中等強度 | 低強度 | 靜態活動 |
導出 Excel 文件。
遍歷每個志愿者文件
for pid in pids:
file_path = f'{pid}.csv' # 假設文件名為P001.csv格式# 讀取數據文件df = pd.read_csv(file_path, parse_dates=['time'])# 計算時間間隔(轉換為小時)df['duration'] = df['time'].diff().dt.total_seconds().fillna(0) / 3600# 提取MET值df['MET'] = df['annotation'].str.extract(r'MET (\d+\.?\d*)').astype(float)# 分類活動類型df['activity'] = df['MET'].apply(classify_activity)# 按活動類型匯總時長activity_duration = df.groupby('activity')['duration'].sum()# 構建結果行result = {'志愿者 ID': pid,'記錄總時長(小時)': df['duration'].sum().round(4),'睡眠總時長(小時)': activity_duration.get('sleep', 0).round(4),'高等強度運動總時長(小時)': activity_duration.get('high', 0),'中等強度運動總時長(小時)': activity_duration.get('medium', 0),'低等強度運動總時長(小時)': activity_duration.get('low', 0),'靜態活動總時長(小時)': activity_duration.get('static', 0)}results.append(result)
2.構建 MET 值估計模型
目標:
利用 100 名志愿者的數據,構建 機器學習模型,預測新的 20 名志愿者的 MET 值。
數據說明:
P[ID].csv:包含加速度計數據及 MET 值(用于訓練)。
Metadata1.csv:包含志愿者的性別、年齡信息。
T[ID].csv:20 位新志愿者的加速度計數據(用于預測)。
Metadata2.csv:包含 20 位新志愿者的性別、年齡信息。
解題思路:
數據預處理
解析加速度數據(X/Y/Z)。
計算時序特征:
時域特征(均值、標準差、最大值、最小值等)
頻域特征(FFT 分析)
結合年齡、性別數據,標準化特征。
特征工程
采用 滑動窗口(如 1 秒、5 秒窗口)進行特征提取:
平均加速度、方差、均方根(RMS)
瞬時速度估計
頻譜能量
目標變量為 MET 值。
模型選擇
回歸模型(目標變量為連續值):
XGBoost / LightGBM
隨機森林
LSTM / GRU(處理時序數據)
CNN+LSTM 組合模型
選擇 均方誤差(MSE)以及 平均絕對誤差(MAE) 作為損失函數。
模型訓練
劃分訓練集與驗證集(80% 訓練 / 20% 驗證)。
調參優化(交叉驗證)。
評估模型泛化能力。
預測新志愿者 MET 值
使用訓練好的模型預測 T[ID].csv 20 位志愿者的數據。
保存預測結果 result_2.xlsx。
5.2.2 特征工程與數據處理
1.時間窗口構造
將原始加速度數據按 5 秒為單位劃分為多個不重疊的時間窗口。設某志愿者的加速度數據為三維時間序列 ,時間窗口長度為 秒,則第 個窗口內包含的數據為:
在每個時間窗口中提取統計特征和頻域特征,構成特征向量 。
2.特征提取基本原理
在每個窗口 內,提取以下特征:
?時域特征:對每個軸向的加速度數據 ,計算其均值(mean)、標準差(std)、最大值(max)、最小值(min):
?加速度幅值(Magnitude)特征:定義三軸加速度的合成加速度為:
并提取其均值與標準差:
?頻域特征:對加速度幅值序列 進行離散傅里葉變換(DFT):

======================
數據準備
======================
def extract_features(accel_data):
"""從三軸加速度數據中提取特征"""features = {}# 時域特征for axis in ['x', 'y', 'z']:# 基本統計量features[f'{axis}_mean'] = accel_data[axis].mean()features[f'{axis}_std'] = accel_data[axis].std()features[f'{axis}_max'] = accel_data[axis].max()features[f'{axis}_min'] = accel_data[axis].min()#features[f'{axis}_mad'] = accel_data[axis].mad() # 平均絕對偏差# 幅值特征magnitude = np.sqrt(accel_data[['x', 'y', 'z']].pow(2).sum(axis=1))features['magnitude_mean'] = magnitude.mean()features['magnitude_std'] = magnitude.std()# 頻域特征fft = np.fft.fft(magnitude)features['dominant_freq'] = np.argmax(np.abs(fft)) # 主頻率return pd.Series(features)
遍歷每個志愿者文件
for _, row in tqdm(metadata.iterrows(), total=len(metadata)):
pid = row['pid']file_path = f'{pid}.csv'# 讀取加速度數據df = pd.read_csv(file_path)df['MET'] = df['annotation'].str.extract(r'MET (\d+\.?\d*)').astype(float)# 按時間窗口處理(5秒窗口)window_size = '5S'df['time'] = pd.to_datetime(df['time'])grouped = df.set_index('time').groupby(pd.Grouper(freq=window_size))# 窗口特征提取for _, window in grouped:if len(window) > 0:features = extract_features(window[['x', 'y', 'z']])features['age'] = row['age']features['sex'] = row['sex']all_features.append(features)all_targets.append(window['MET'].mean())
- 睡眠階段智能識別
目標:
設計睡眠階段分類算法,基于加速度數據識別不同的睡眠狀態。
數據說明:
P[ID].csv(訓練數據,包含 MET 值)。
T[ID].csv(測試數據,無 MET 值,需要進行預測)。
解題思路:
數據預處理
選取 睡眠數據(MET < 1.0) 作為分析對象。
計算 睡眠時段的加速度特征:
運動量(X/Y/Z 方向變化率)
姿態變化(角度計算)
低頻信號分析(檢測深度睡眠)
特征提取
使用 滑動窗口法(如 30s、60s 窗口)提取特征:
加速度均值、標準差
突發運動頻率
睡眠穩定性指標(基于 FFT 低頻功率)
模型選擇 分類模型:
傳統機器學習(Random Forest, SVM)
深度學習(LSTM、CNN)
目標:劃分 不同睡眠階段(如淺睡、深睡、REM)。
模型訓練與預測
訓練模型,調整超參數。
預測 20 名志愿者的睡眠階段,輸出 result_3.xlsx。
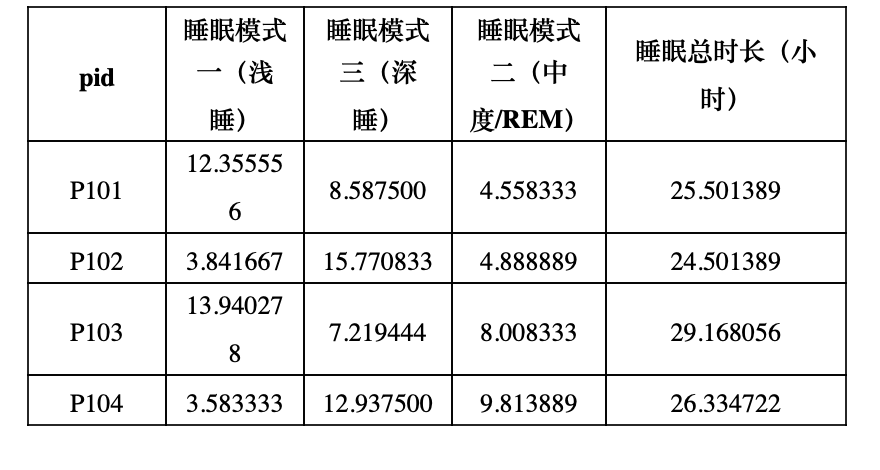
聚類結果的解釋與活動模式識別
為了評估不同聚類算法在本問題中的適用性與有效性,本文計算了
KMeans
與高斯混合模型(
GMM
)兩種聚類方法在標準化特征空間上的輪廓系數(
Silhouette Coefficient
)。輪廓系數是一種常用的無監督聚類性能評估指標,綜合衡量了簇內緊密度和簇間分離度。其取值范圍為
[
?
1,1][-1, 1][
?
1,1]
,值越接近
1
表示聚類結果越合理,聚類邊界越清晰;值接近
0
表示簇之間重疊較多,聚類效果模糊;若為負值,則可能存在簇劃分錯誤的情況。
本實驗結果如下:
KMeans 聚類輪廓系數:0.2296
GMM 聚類輪廓系數:0.0277
大多數志愿者的睡眠時長主要集中在
“睡眠模式三(深睡)”和“睡眠模式一(淺睡)”之間,表明深度睡眠和淺睡是大多數志愿者的主要睡眠階段。而“睡眠模式二(中度
/REM
)”的時間占比相對較低,但在一些志愿者中,可能由于特定生理特征或生活習慣,表現出較為明顯的中度睡眠模式。
- 久坐行為健康預警
目標:
檢測志愿者 久坐行為(單次靜態時間超過 30 分鐘,MET < 1.6)。
解題思路:
數據解析
解析時間戳,轉換為分鐘級別時間軸。
計算連續靜態行為(MET < 1.6)。
久坐檢測
采用 滑動窗口分析:
若 連續 30 分鐘以上 處于 MET < 1.6,則標記為久坐行為。
計算 久坐持續時間 及 久坐次數。
預警策略
若 單次久坐超過 1 小時 → 預警等級 1
若 每日久坐總時長 > 6 小時 → 預警等級 2
若 久坐超過 10 小時 → 預警等級 3(高風險)
生成結果
輸出每位志愿者的久坐時間及預警信息。









)
)



的詳細步驟)
![LINUX基礎 [二] - Linux常見指令](http://pic.xiahunao.cn/LINUX基礎 [二] - Linux常見指令)
,源碼可白嫖!)


