鋒哥原創的Pandas2?Python數據處理與分析 視頻教程:??
2025版 Pandas2 Python數據處理與分析 視頻教程(無廢話版) 玩命更新中~_嗶哩嗶哩_bilibili

Excel格式文件是辦公使用和處理最多的文件格式之一,相比CSV文件,Excel是有樣式的。Pandas2提供的read_excel()方法來讀取excel文件,提供了很多強大的功能參數支持,讓我們開發非常方便。
首先我們去看下read_excel()的方法的參數定義,很大一部分和csv參數一樣。
def read_excel(io,sheet_name: str | int | list[IntStrT] | None = 0,*,header: int | Sequence[int] | None = 0,names: SequenceNotStr[Hashable] | range | None = None,index_col: int | str | Sequence[int] | None = None,usecols: int| str| Sequence[int]| Sequence[str]| Callable[[str], bool]| None = None,dtype: DtypeArg | None = None,engine: Literal["xlrd", "openpyxl", "odf", "pyxlsb", "calamine"] | None = None,converters: dict[str, Callable] | dict[int, Callable] | None = None,true_values: Iterable[Hashable] | None = None,false_values: Iterable[Hashable] | None = None,skiprows: Sequence[int] | int | Callable[[int], object] | None = None,nrows: int | None = None,na_values=None,keep_default_na: bool = True,na_filter: bool = True,verbose: bool = False,parse_dates: list | dict | bool = False,date_parser: Callable | lib.NoDefault = lib.no_default,date_format: dict[Hashable, str] | str | None = None,thousands: str | None = None,decimal: str = ".",comment: str | None = None,skipfooter: int = 0,storage_options: StorageOptions | None = None,dtype_backend: DtypeBackend | lib.NoDefault = lib.no_default,engine_kwargs: dict | None = None,
) 所以我們這里講解一些read_excel獨有的方法參數:
-
io:
-
類型: str, bytes, ExcelFile, xlrd.Book, path object, 或 file-like object
-
作用: Excel 文件的路徑或文件對象
-
-
sheet_name:
-
類型: str, int, list, 或 None (默認 0)
-
作用: 指定要讀取的工作表
-
示例:
-
0: 讀取第一個工作表 -
"Sheet1": 讀取名為"Sheet1"的工作表 -
[0, 1]: 讀取前兩個工作表,返回字典 -
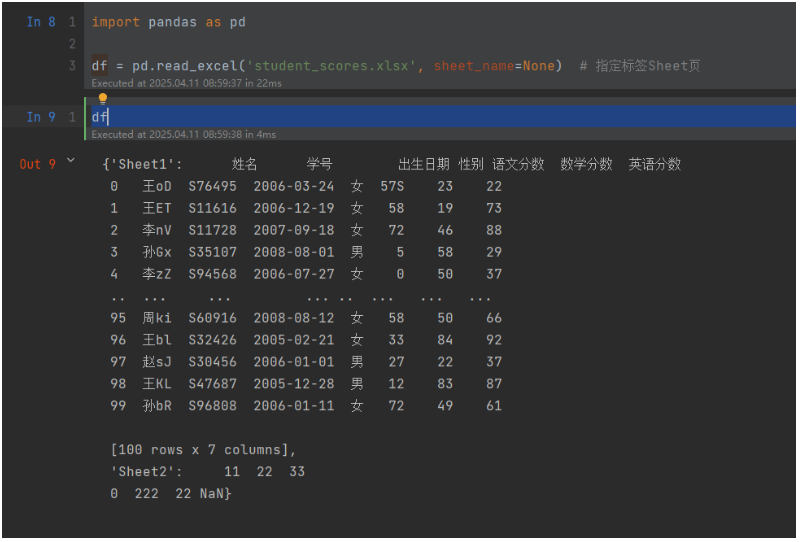
None: 讀取所有工作表,返回字典
-
-
參考代碼:
# 導入pandas庫,去別名pd
import pandas as pd
?
df = pd.read_excel('student_scores.xlsx', sheet_name="Sheet2") ?# 指定第二個標簽Sheet頁
# df = pd.read_excel('student_scores.xlsx', sheet_name=1) # 指定第二個標簽Sheet頁
# df = pd.read_excel('student_scores.xlsx', sheet_name=[0, 1]) # 讀取前兩個工作頁,返回字典
# df = pd.read_excel('student_scores.xlsx', sheet_name=None) # 讀取所有工作頁運行輸出:














——項目學習記錄)




