目錄
前言?
一、數據集:圖像+文本,部分選取于DeepFashion
二、優化一,img2img
?三、優化二,微調sd參數
?四、優化三,dreamshaper優化
?五、優化四,sdv1.5+contronet
六、問題探索歷程
1. 從 SDXL 到輕量化模型:模型選擇的權衡
2. LoRA 下載受阻:轉向基礎模型優化
3. ControlNet 約束:提升結構一致性
4. 指標評估:文件名匹配與全黑圖處理
5. SSIM 計算錯誤:尺寸與數據范圍問題
6. LPIPS 歸一化調整
結果分析
總結
后續優化想法、可參考思路:
1. LoRA 微調
2. 超分辨率后處理
3. 自適應提示詞
4. 損失函數優化
5. 多模型融合
由于sd v1.5生成效果一般,主要在人物面部、手部等細節上很差,于是我尋求各種優化,今天最成功的是加入contronet,這的確是一個妥妥提升質量的思路,我用的約束是輪廓圖,想復現的思路除這個外,最近幾天在基于 Stable Diffusion v1.5模型做優化,旨在優化圖像生成質量,并通過 PSNR、SSIM 和 LPIPS 等指標對比評估不同優化方案的效果。在優化過程中,我遇到了一些技術問題,涉及模型選擇、代碼錯誤、指標計算等。以下是優化過程的詳細記錄,重點展示了技術問題、解決方案和實驗結果。
? Stable Diffusion v1.5:不換模型優化人體細節的實用技巧-CSDN博客
Stable Diffusion+Pyqt5: 實現圖像生成與管理界面(帶保存 + 歷史記錄 + 刪除功能)——我的實驗記錄(結尾附系統效果圖)-CSDN博客
基于前面搭建的sd v1.5,深度學習項目記錄·Stable Diffusion從零搭建、復現筆記-CSDN博客:
前言?
最近圍繞stable diffusion v1.5做了一系列實驗,尋求各種優化,前面發的一篇是優化思路,這一篇是sd v1.5 + contronet(我采用的是邊緣圖,先安裝opencv:pip install opencv-python依賴 cv2 來生成 Canny 邊緣圖),忙活幾天才徹底完成各優化模型評價指標的測定,最終三個指標均有所提升。模型基于sd v1.5微調,接下來是項目思路的還原:
一、數據集:圖像+文本,部分選取于DeepFashion
實驗環境:python3.11 Pytorch12.1? ?
?GPU:RTX4070? ?
二、優化一,img2img
基于原圖的風格統一或提示詞約束(添加細節提示)實現對生成圖像再優化,上一篇提到了Strength參數作用,主要是控制實際迭代步數。
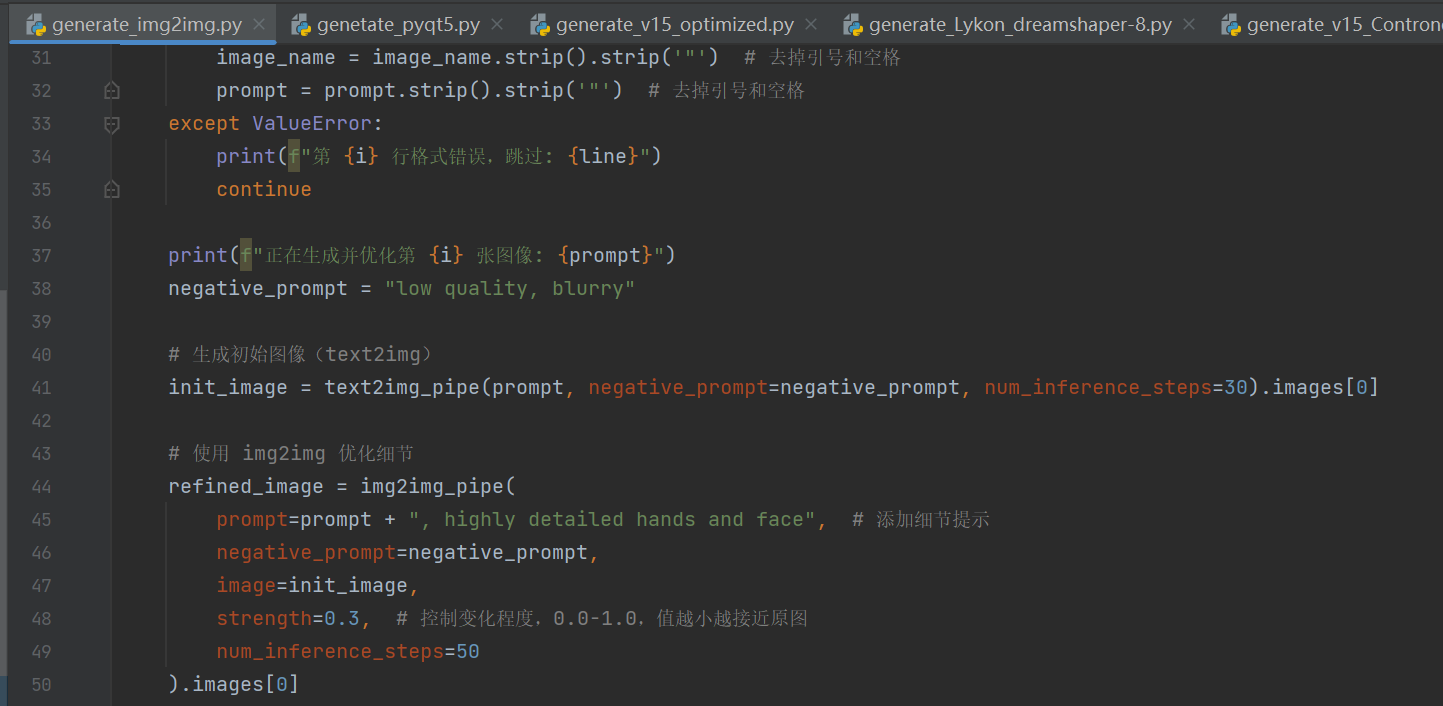
上一篇鏈接:Stable Diffusion+Pyqt5: 實現圖像生成與管理界面(帶保存 + 歷史記錄 + 刪除功能)——我的實驗記錄(結尾附系統效果圖)-CSDN博客
?文本描述:? "MEN-Denim-id_00000089-44_7_additional.jpg": "This man is wearing a short-sleeve shirt with pure color patterns. The shirt is with cotton fabric and its neckline is lapel. The trousers this man wears is of long length. The trousers are with cotton fabric and solid color patterns.",
效果:

?三、優化二,微調sd參數
optimized,主要是優化迭代步數和引導強度,附加提示詞優化
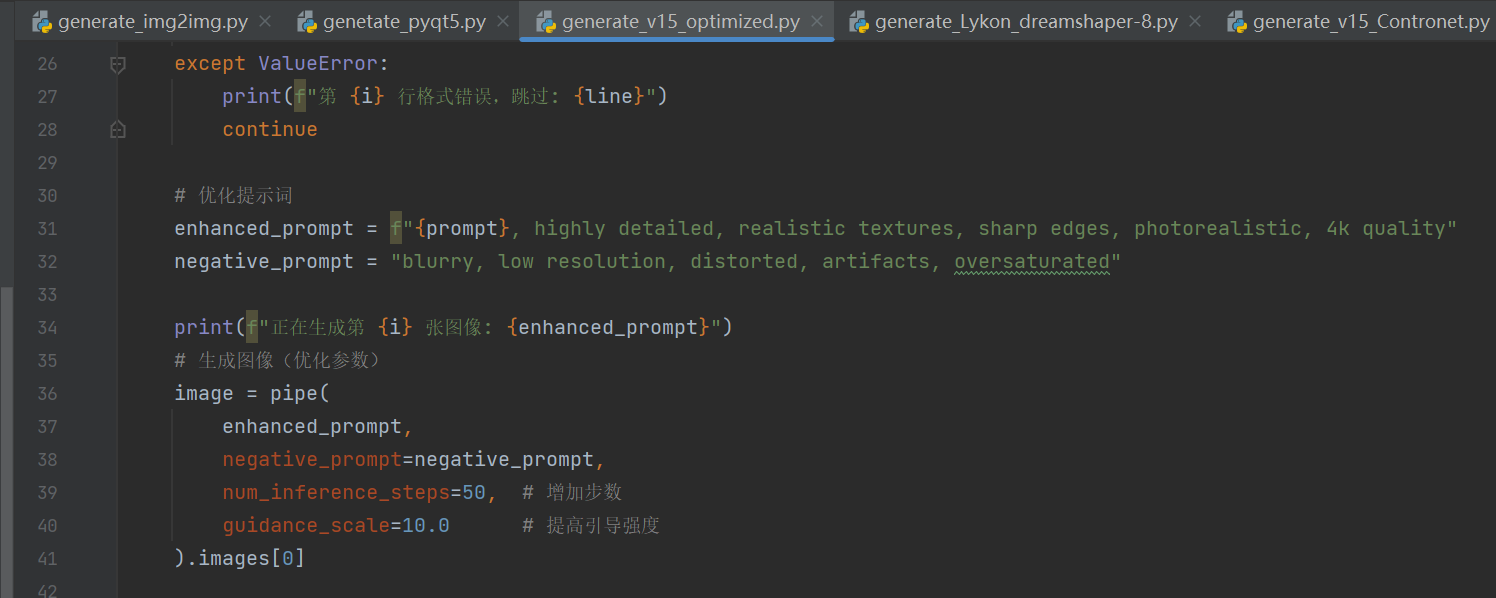
效果如下:

?
?四、優化三,dreamshaper優化
(重新加載模型速度最慢、耗時久)
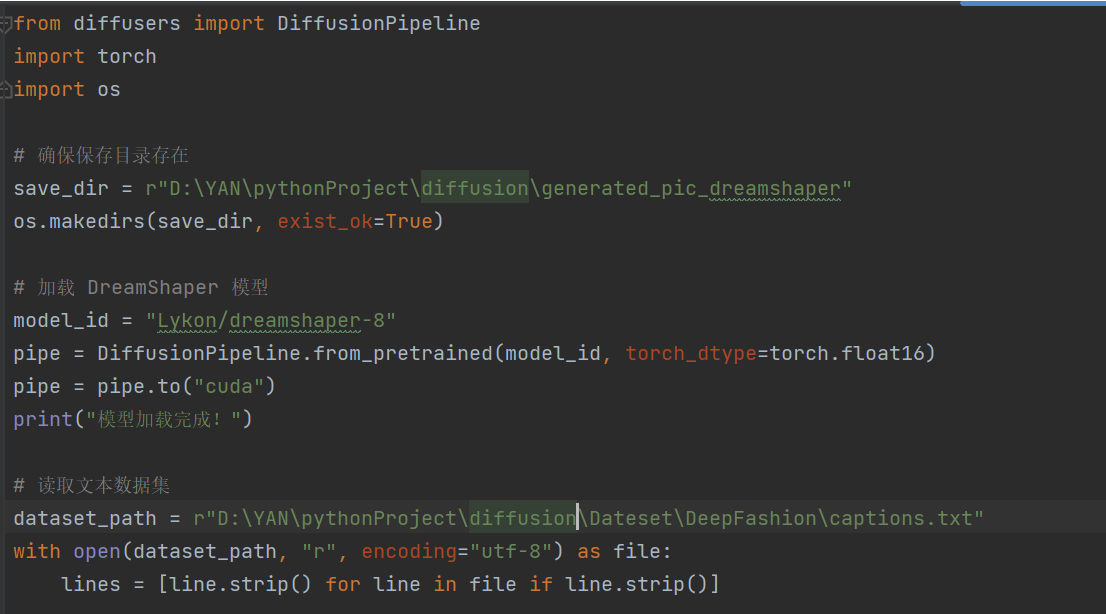

成功生成:
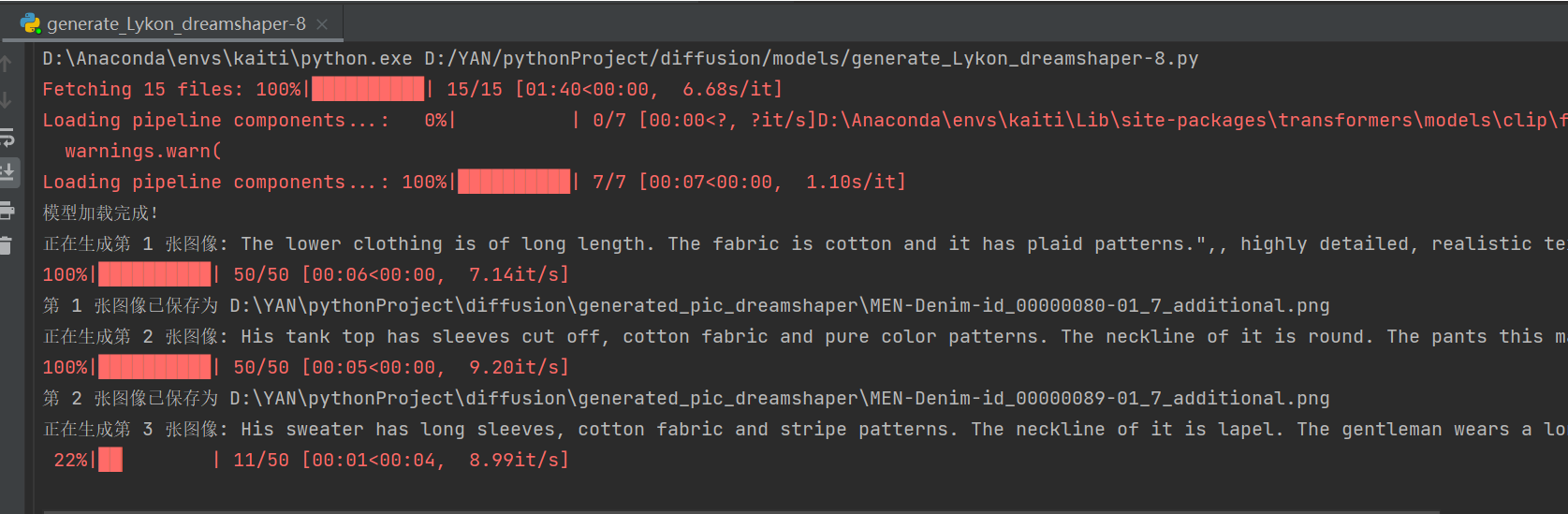
效果(可能是hugging face基礎模型的原因,風格化嚴重):

?五、優化四,sdv1.5+contronet
?邊緣圖約束+提示詞優化
需先下載庫:
?速度比前面慢接近十倍:(與原圖保持輪廓一致)


六、問題探索歷程
?
1. 從 SDXL 到輕量化模型:模型選擇的權衡
技術問題
最初,我計劃使用 Stable Diffusion XL (SDXL),因為它在圖像質量上表現優異。然而,由于 SDXL 模型體積較大(約 10GB)且對硬件要求高,下載困難并且運行復雜,最終選擇了更輕量的模型。
解決方法
轉向使用 runwayml/stable-diffusion-v1-5(約 4GB),該模型社區支持廣泛,且生成質量適中。為了提升生成效果,引入了 LoRA 微調技術。
技術細節
-
LoRA 微調:使用 LoRA 技術增強模型生成能力,通過加載小型權重文件(幾十 MB)進行微調。
-
代碼實現:
from diffusers import StableDiffusionPipeline pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16) pipe.load_lora_weights(r"D:\YAN\pythonProject\diffusion\lora\fashion-detail-lora.safetensors") -
參數調整:設置
num_inference_steps=50和guidance_scale=7.5來平衡生成質量和速度。
2. LoRA 下載受阻:轉向基礎模型優化
技術問題
由于網絡限制,我無法順利從 Civitai 或 Hugging Face 下載 LoRA 權重文件。
解決方法
放棄使用 LoRA,轉向通過提示詞工程和參數調整優化 runwayml/stable-diffusion-v1-5 的生成效果,并嘗試了其他輕量模型,如 Lykon/dreamshaper-8。
技術細節
-
提示詞優化:加入更具體的描述,如
highly detailed, realistic textures,并使用負面提示排除低質量元素。 -
代碼調整:
image = pipe(prompt, negative_prompt="blurry, low resolution", num_inference_steps=75, guidance_scale=10.0).images[0] -
DreamShaper 模型:使用
Lykon/dreamshaper-8,并手動下載模型文件避免網絡問題:model_id = r"D:\YAN\pythonProject\diffusion\models\dreamshaper-8" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
3. ControlNet 約束:提升結構一致性
技術問題
盡管生成圖像有了提升,但服裝結構和輪廓依然不夠精確。我希望通過 ControlNet 強化生成圖像的結構一致性。
解決方法
集成了 lllyasviel/sd-controlnet-canny 模型,利用 Canny 邊緣圖作為輸入,以此加強生成圖像的結構保持性。
技術細節
-
依賴安裝:安裝
opencv-python處理邊緣圖:pip install opencv-python -
ControlNet 實現:
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16) pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16) canny_image = cv2.Canny(cv2.imread(image_path, cv2.IMREAD_GRAYSCALE), 100, 200) image = pipe(prompt, image=canny_image, controlnet_conditioning_scale=1.0).images[0]
4. 指標評估:文件名匹配與全黑圖處理
技術問題
計算 PSNR、SSIM 和 LPIPS 時,出現了文件名匹配失敗的問題(圖像格式不一致)以及部分圖像為全黑圖,導致計算結果偏差。
解決方法
調整文件名匹配邏輯,去除擴展名匹配,同時加入全黑圖檢測,跳過不合適的圖像。
技術細節
-
文件名匹配:
base_name = os.path.splitext(gen_file)[0] original_file = original_files.get(base_name) -
全黑圖檢測:
def is_black_image(img):return np.all(img == 0) if is_black_image(generated_img):print(f" 跳過全黑圖: {gen_file}")continue
5. SSIM 計算錯誤:尺寸與數據范圍問題
技術問題
SSIM 計算報錯,主要是由于圖像尺寸過小或數據范圍不正確。
解決方法
添加尺寸檢查并為 SSIM 指定 data_range=1.0。
技術細節
-
尺寸檢查:
h, w = original_img.shape[:2] if h < 7 or w < 7:raise ValueError(f"圖像尺寸 {h}x{w} 太小,SSIM 需要至少 7x7") -
SSIM 參數調整:
ssim_value = ssim(original, generated, channel_axis=2, win_size=min(7, min(h, w)), data_range=1.0)
6. LPIPS 歸一化調整
技術問題
LPIPS 計算結果異常,原因是圖像數據范圍不符合期望。
解決方法
將圖像從 [0, 1] 轉換為 [-1, 1],以適應 LPIPS 計算。
技術細節
original_tensor = torch.from_numpy((original * 2 - 1).transpose(2, 0, 1)).float().unsqueeze(0).to('cuda')
generated_tensor = torch.from_numpy((generated * 2 - 1).transpose(2, 0, 1)).float().unsqueeze(0).to('cuda')
lpips_value = lpips_model(original_tensor, generated_tensor).item()
最終結果與分析
在優化和調參后,我生成了多個模型的圖像并計算了對應的 PSNR、SSIM 和 LPIPS 指標。以下是最終結果: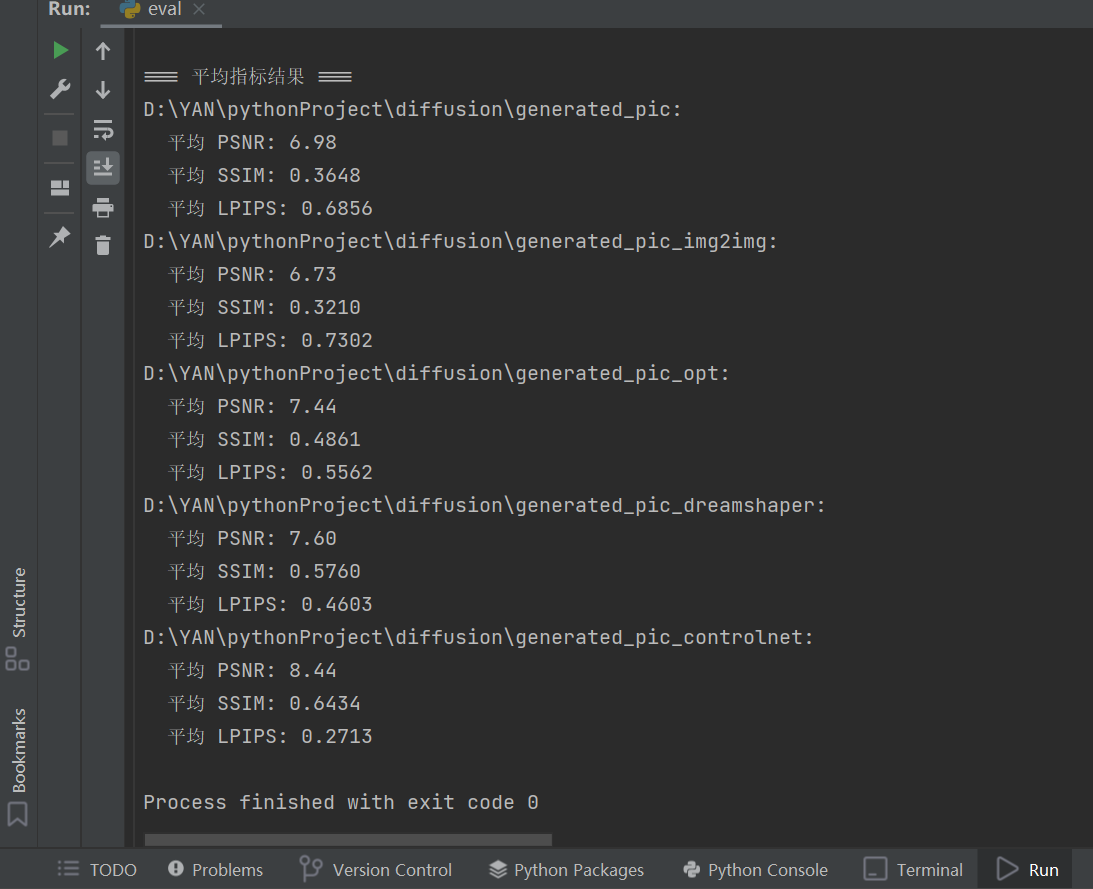
結果分析
-
PSNR:
generated_pic_controlnet的 8.44 最高,表示圖像與原圖差異最小。 -
SSIM:
generated_pic_controlnet的 0.6434 最高,結構相似性最優,驗證了 ControlNet 對結構的一致性控制能力。 -
LPIPS:
generated_pic_controlnet的 0.2713 最低,感知相似性最佳,符合人類視覺評價。
總結
通過從 SDXL 的放棄,到 LoRA 的失敗,再到 ControlNet 的成功集成,我逐步優化了圖像生成質量。最終,ControlNet 在所有指標上均表現優異,特別是在服裝生成任務上。
后續優化想法、可參考思路:
在 ControlNet 加入邊緣圖優化后,接下來可以考慮以下幾個改進方向,以進一步提升圖像生成質量和效果:
1. LoRA 微調
-
目標:若網絡問題得到解決,可以引入服裝特定的 LoRA 微調,以進一步優化細節(如紋理、材質),進而提升 SSIM 和 LPIPS 指標。
-
實現:下載和加載特定于服裝領域的 LoRA 權重文件,微調基礎模型,提升生成圖像的細節表現。
2. 超分辨率后處理
-
目標:通過超分辨率技術(如 ESRGAN 或 Real-ESRGAN)對生成的圖像進行后處理,提高 PSNR 和圖像清晰度。
-
實現:使用超分辨率網絡對生成的低分辨率圖像進行放大和細節恢復,從而提高圖像質量,減少模糊現象。
3. 自適應提示詞
-
目標:基于原始圖像的特征(如顏色、風格)動態生成提示詞,減少生成偏差,提升圖像與提示詞的匹配度和感知一致性。
-
實現:使用圖像分析模型提取圖像特征,生成與原圖風格和元素一致的提示詞,以便引導模型生成更符合預期的圖像。
4. 損失函數優化
-
目標:在訓練或微調中加入感知損失(如 LPIPS),使生成圖像更貼近人類視覺評價,提升圖像質量的感知效果。
-
實現:在訓練過程中加入感知損失函數,優化模型輸出,使生成圖像與目標圖像在視覺上更為相似。
5. 多模型融合
-
目標:結合 DreamShaper 和 ControlNet 等模型的優勢,通過模型集成提升圖像生成的綜合質量。
-
實現:在生成過程中融合多個模型的輸出,采用加權平均或其他融合策略,以平衡各模型的優缺點,生成更加細膩和多樣化的圖像。
這些優化方法為 ControlNet 和 Stable Diffusion 圖像生成模型提供了更多的潛力和改進空間。通過在細節、分辨率、提示詞自適應和模型融合等方面進行優化,能夠進一步提升服裝生成任務的質量和穩定性,探索更多可能性,有需要可以從以上五點做嘗試。
本篇基于sd v1.5:
深度學習項目記錄·Stable Diffusion從零搭建、復現筆記-CSDN博客
優化后續強相關:
? Stable Diffusion v1.5:不換模型優化人體細節的實用技巧-CSDN博客
Stable Diffusion+Pyqt5: 實現圖像生成與管理界面(帶保存 + 歷史記錄 + 刪除功能)——我的實驗記錄(結尾附系統效果圖)-CSDN博客





)


)



)

)




