nuscenes數據集分析
標注與總體介紹
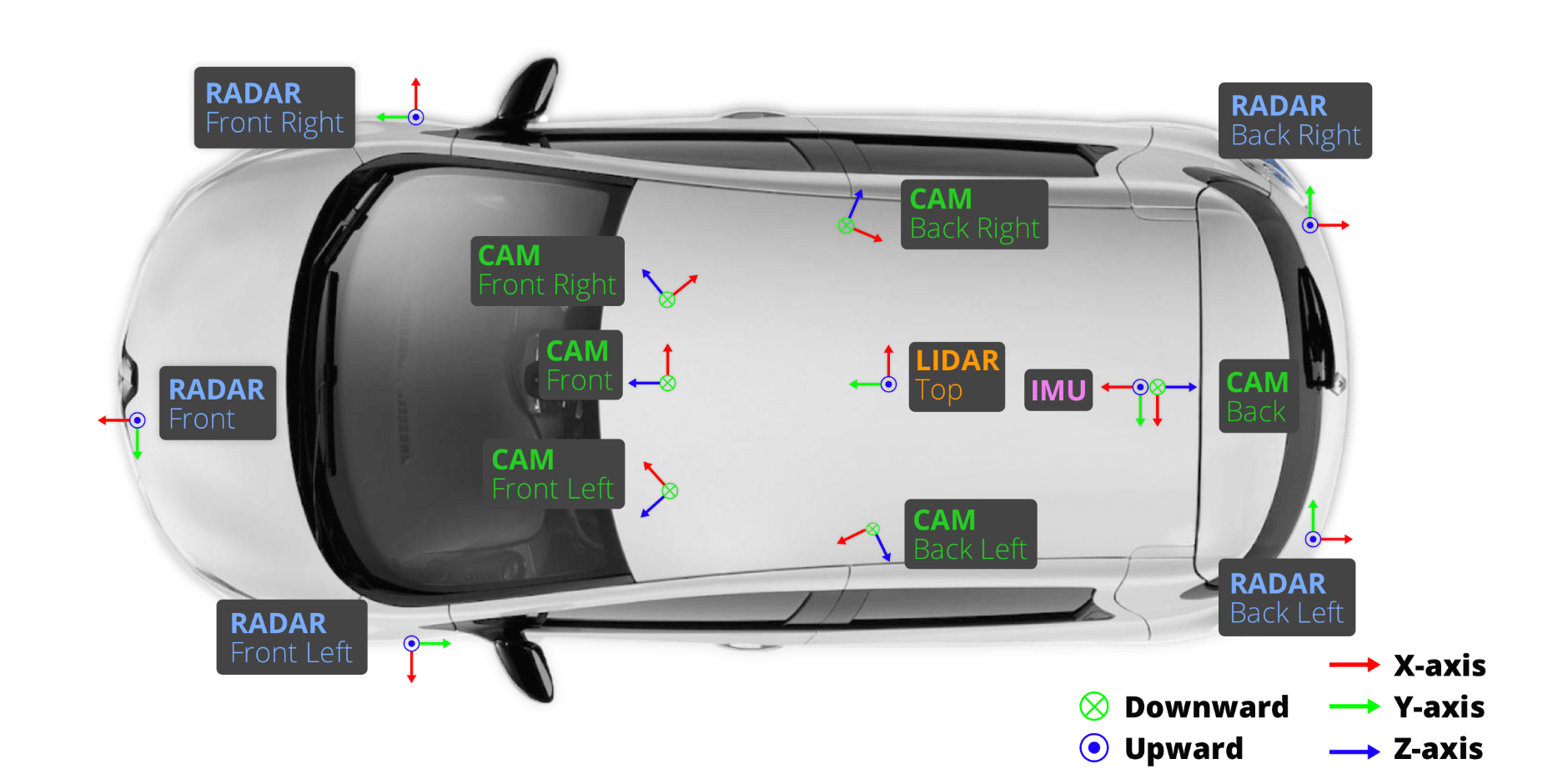
nuscenes包含有相機、激光雷達、毫米波雷達、IMU與GPS等設備提供的數據。它的數據采集了1000個場景,每個場景大約有20s,針對目標檢測任務,對23類物體進行標注,且以2Hz的頻率提供精確的三維目標框標注。此外,還有物體級別的屬性如可見度、姿態、活動狀態等。
具體來說,對于標注數據,標注的要求有以下幾點:
- 一個物體不超過一個框,確保所有點在框中且在圖像視角看著正常。
- 如果對于一個物體能夠判斷出他的位置形狀等,且至少有一個點云,就標注它。
- 框要緊湊,如果目標物體有外延如胳膊腿等要包含進來,但像車的側邊鏡或超過一定高度的外延不需要考慮。如果目標攜帶其他物體,需要包含進來,若多個目標攜帶一個東西,則這個東西只能包含在一個框中。
- 如果由于定位誤差導致一個靜止的物體移動,同樣要標注框。對于點云稀疏的物體,用圖像輔助框進行調整。
標注的物體類別有23類,
- 此外他們還有屬性
Visibility,它代表該物體在全景視角下的可見程度。 - 對于有四個輪子以上的汽車有屬性
Vehicle Activity,它有三種選擇,Parked代表靜止的,Stopped代表靜止的,但是司機在上面,Moving代表在移動。 - 對于自行車、摩托車與個人便攜移動工具,有屬性
Has Ride,它有Yes與No代表是否有人在上面。 - 對于場景中的人有屬性
Human Activity,可以有Sitting or Lying Down,Standing與Moving三種。
在元數據中,maps文件夾就是我們采集場景的4張地圖。
數據格式介紹
所有的標注數據與元數據都以關系數據庫的形式組織起來,接下來將分別介紹。
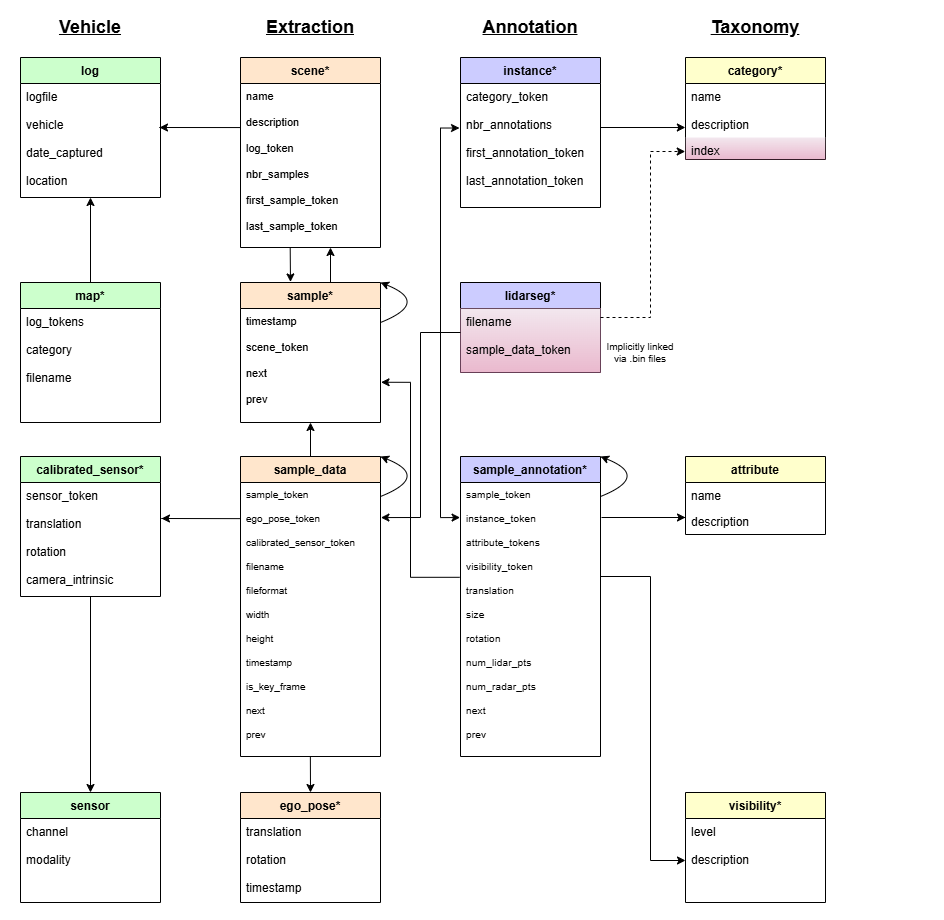
下面三個記錄了我們需要標注的屬性
- 對于
visibility.json,記錄了四種不同程度的可見程度。 - 對于
attribute.json,記錄了動態物體的運動狀態,也就是上一節說到的Vehicle Activity等等,通過token進行標識。 - 對于
category,記錄的就是類別信息,一共有23類。
下面四個則是我們汽車的一些記錄信息,如傳感器參數,地圖等。
- 對于
log,記錄的是數據采集的日志信息,它包含以下的信息,vehicle代表車名,date_captured代表數據采集日期,location代表采集地點,logfile代表數據日志文件名,可能多個場景對應同個日志。 - 對于
map,它描述了每段數據采集的語義地圖,包含有category表示語義先驗圖,filename代表地圖文件路徑,log_tokens為一個列表,包含所有在該地圖下進行數據采集的log_token。 - 對于
sensor,它記錄了我們的傳感器,即6個相機,lidar與radar等,包含有channel表示它具體的通道,如CAM_FRONT,CAM_BACK_LEFT等等,modality標識它的傳感器類別。 - 對于
calibrated_sensor,他記錄了對傳感器標定的參數信息,其中的sensor_token定義傳感器對象,translation與rotation則是外參,camera_intrinsic則是相機內參矩陣。
下面四個是關于具體采集數據時的一些信息記錄。
- 對于
ego_pose,他記錄了具體時間戳下的車輛相對于世界坐標系的外參,即translation與rotation,還有timestamp記錄時間戳。 - 對于
scene,他是從log中提取的連續的20s長的連續幀,可能多個scene取自一個log。包含的信息有,log_token告訴我們來自哪個log,nbr_samples告訴我們samples的數量,first_sample_token代表該場景下第一個sample的token,last_sample_token代表該場景下最后一個sample,name即場景的名字,description是場景詳細描述。 - 對于
sample,它代表關鍵采樣幀,頻率為2HZ,包含以下信息,timestamp代表時間戳信息,prev與next代表前一個與下一個sample的token,scene_token對應的是該sample屬于的場景token。 - 對于
sample_data,代表傳感器采集的原始數據。sample_token為所屬的sample的token,要選擇時間上最接近的;ego_pose_token代表汽車位姿信息;calibrated_sensor_token代表傳感器內外參信息;filename代表文件的相對路徑;fileformat為數據文件的格式;width與height代表如果是圖片,它的寬高;timestamp為時間戳;is_key_frame代表sample_data是否是關鍵幀。next與prev代表在該場景下該傳感器順著時間向前向后的一個Sample data。
下面是標注信息的介紹
- 對于
instance,代表的就是單個物體實例。category_token指向類別,nbr_annotations為該實例被標注的數量。first_annotation_token與last_annotation_token指向sample_annotation,代表第一次與最后一次被標注的token,指向sample_annotation。 - 對于
sample_annotation,它是坐標框信息,定義了在sample中看到的物體的位置,所有位置信息都是全局坐標系下的,sample_token代表對應的sample,instance_token代表對應的實例,attribute_tokens與attribute_tokens即屬性,translation代表框的中心位置,size代表框的大小,rotation代表框的朝向,num_lidar_pts代表此邊界框內的激光雷達點數,next與prev指向自身,代表同一物體之前之后的下一個標注token。
nuscenes數據集的使用
在這里以mini數據集為例
#導入nuscenes開發包,并把數據集加載進來,得到對象nusc。
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version='v1.0-mini', dataroot='/data/sets/nuscenes', verbose=True)
#可以使用nusc訪問我們的場景,具體展示如下
my_scene = nusc.scene[0]
print(my_scene)

#接下來獲得該場景下的第一個sample
first_sample_token = my_scene['first_sample_token']
my_sample = nusc.get('sample', first_sample_token)
print(my_sample)
#展示如下所示,它提功了該sample對應的數據sample_data以及所需要的標注信息sample_annotation。

#接下來看data數據是什么樣子的
sensor = 'CAM_FRONT'
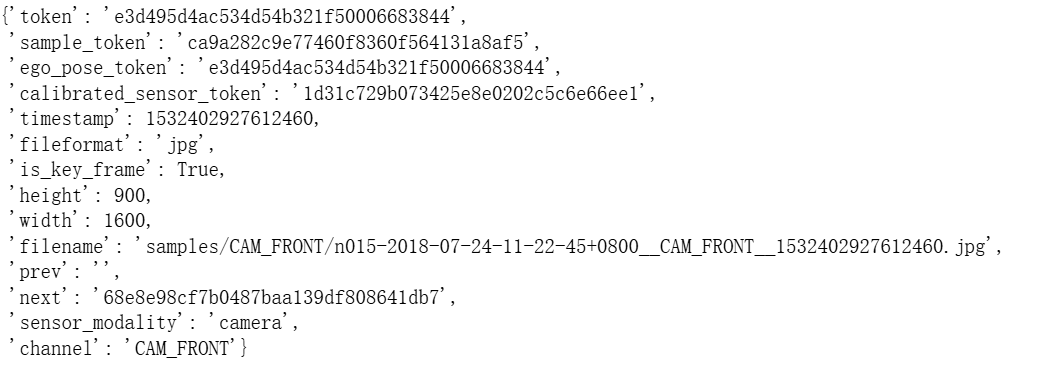
cam_front_data = nusc.get('sample_data', my_sample['data'][sensor])
print(cam_front_data)
#此外,還可以對此進行渲染,如圖所示
nusc.render_sample_data(cam_front_data['token'])
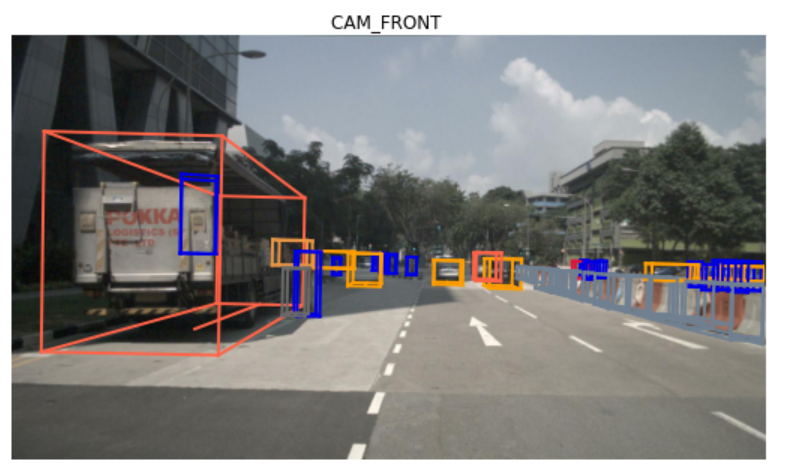
#這個則是獲取標注信息,同樣可以可視化。
my_annotation_token = my_sample['anns'][18]
my_annotation_metadata = nusc.get('sample_annotation', my_annotation_token)
nusc.render_annotation(my_annotation_token)
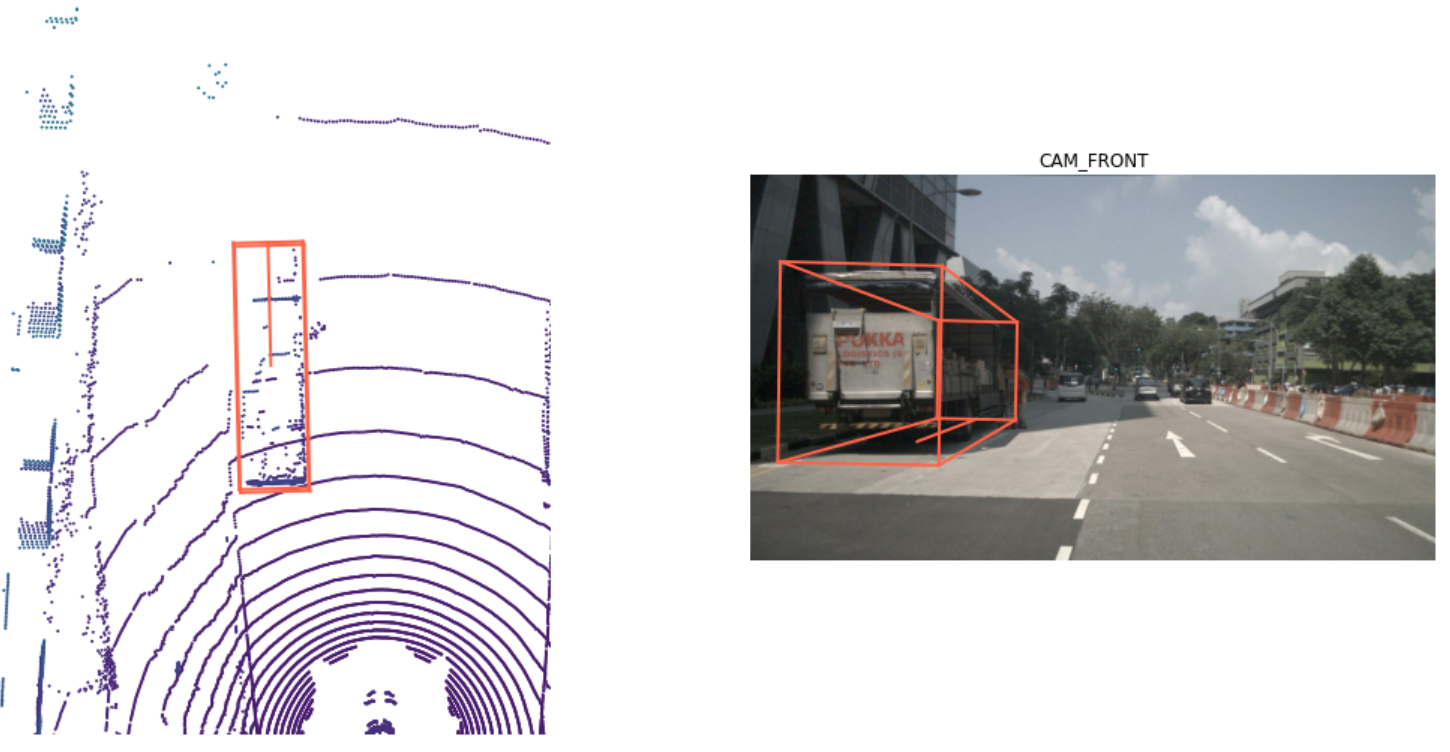
總結
nuscenes的開發工具主要就是加載數據集并讓你可以用字典的方式訪問它,并且可以對其進行渲染,并通過token標識獲取你想要的東西。具體的操作可以在官網查看,本篇文章講述了一些核心的方法,最主要還是數據庫的架構得看懂。
)








 的全新角色模組 - 女巫)
)



(vscode))



)
