概述
在目標檢測領域,有一個指標被廣泛認為是衡量模型性能的“黃金標準”,它就是 mAP(Mean Average Precision,平均精確率均值)。如果你曾經接觸過目標檢測模型(如 YOLO、Faster R-CNN 或 SSD),那么你一定聽說過 mAP。但你是否真正理解 mAP 背后的含義?為什么研究人員如此信賴它?mAP@0.5 和 mAP@0.95 又有什么區別?本文將為你揭開 mAP 的神秘面紗。

1. 目標檢測比分類更難
在分類任務中,只需要預測一個標簽。而在目標檢測中,需要完成兩項任務:
- 找到目標的位置(定位:繪制邊界框)。
- 確定目標是什么(分類)。
那么,我們如何衡量成功呢?準確率在這里并不適用。我們需要更全面的指標,而 精確率、召回率 和它們的“老板”:mAP,正是為此而生。
2. 精確率與召回率
精確率:
衡量你的模型猜測有多準確。
- 在模型檢測到的所有目標中,有多少是正確的?
公式: T r u e P o s i t i v e s / ( T r u e P o s i t i v e s + F a l s e P o s i t i v e s ) True Positives / (True Positives + False Positives) TruePositives/(TruePositives+FalsePositives)
召回率:
衡量你的模型有多全面。
- 在所有實際存在的目標中,模型找到了多少?
公式: T r u e P o s i t i v e s / ( T r u e P o s i t i v e s + F a l s e N e g a t i v e s ) True Positives / (True Positives + False Negatives) TruePositives/(TruePositives+FalseNegatives)
但僅靠精確率和召回率并不能說明全部問題。如果模型在找到目標方面表現出色,但在繪制邊界框方面卻很糟糕怎么辦?
這就是交并比(IoU)的作用所在。
3. IoU:檢測質量的把關者
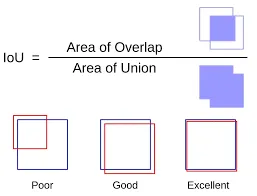
交并比(IoU) 是一個關鍵指標,用于衡量預測邊界框與真實邊界框(實際目標位置)的對齊程度。它的計算方法如下:
如何計算 IoU?
- 交集:預測框與真實框之間的重疊區域。
- 并集:兩個框覆蓋的總面積。
公式:IoU = 交集面積 / 并集面積
舉例說明:
- 如果模型預測的框與真實框完全重疊,IoU = 1.0。
- 如果沒有重疊,IoU = 0.0。
- 如果預測框覆蓋了真實框的一半,IoU ≈ 0.5。
為什么 IoU 閾值很重要?
i. IoU 閾值(例如 0.5)作為檢測的及格標準:
- 真正例(TP):IoU ≥ 閾值(例如 ≥0.5)。
- 假正例(FP):IoU < 閾值(例如預測框偏差過大)。
ii. 更高的閾值要求更好的定位精度:
- mAP@0.5 是寬松的(框只需要 50% 的重疊)。
- mAP@0.75 要求精確的定位(75% 的重疊)。
- mAP@0.95 是非常嚴格的(用于醫療影像等安全關鍵任務)。
讓我們用一個現實世界的類比來理解 IoU 閾值:
- 閾值為 0.5 就像考試中 50 分及格(適用于大多數情況)。
- 閾值為 0.9 就像需要 90 分才能及格(僅適用于精英表現)。
那么,現在我們該如何解讀模型的性能呢?我們有精確率、召回率和 IoU,但該如何利用它們呢?
答案是 平均精確率(AP)。
4. 平均精確率(AP)
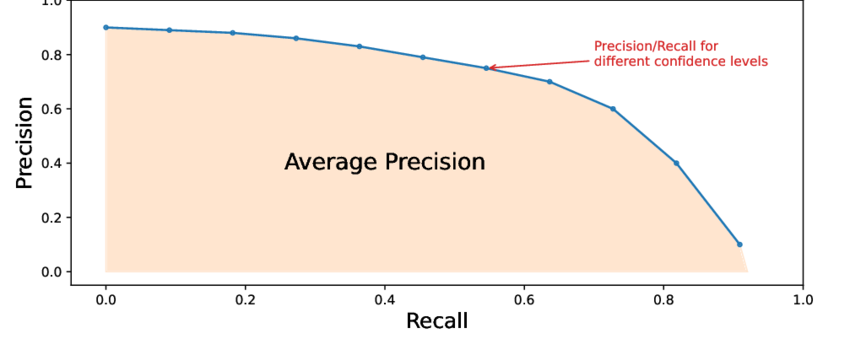
對于單一類別(例如“貓”),可以通過以下步驟計算 AP(Precision Recall 曲線下的面積):
i. 按置信度排序檢測結果:從模型最自信的預測開始。
ii. 在每一步計算精確率和召回率:隨著置信度閾值的降低,你:
- 增加召回率(找到更多目標,但可能會引入更多假正例)。
- 降低精確率(檢測數量增加,但其中一些可能是錯誤的)。
iii. 繪制精確率-召回率(PR)曲線:
- X軸 = 召回率(0 到 1)。
- Y軸 = 精確率(0 到 1)。
- 完美模型的 PR 曲線會緊貼右上角。
iv. 計算 AP(PR 曲線下的面積):
- AP 將整個 PR 曲線總結為一個數字(0 到 1)。
對于平均精確率,AUC 的計算方法如下:
- PR 曲線通過在固定召回率水平上插值精確率進行“平滑”。
- AP = 在 11 個等間距的召回率點(0.0, 0.1, …, 1.0)處的精確率值的平均值。
- 更簡單的方法:使用原始 PR 曲線下的積分(面積)。
完美的 PR 曲線下的面積 = AP = 1.0(在所有召回率水平上都達到 100% 的精確率)。
5.為什么 AP 如此重要
i. 平衡精確率和召回率:高 AP 意味著你的模型:
- 能夠檢測到大多數目標(高召回率)。
- 很少犯錯(高精確率)。
ii. 針對特定類別的洞察:AP 是按類別計算的。如果“貓”的 AP 很低,說明你的模型在檢測貓方面存在困難。
iii. 與閾值無關:與固定閾值指標(例如準確率)不同,AP 在所有置信度水平上評估性能。
舉例說明:
高平均精確率(例如 0.9):
- 在每個召回率水平上,精確率都保持很高。
- 如果模型檢測到 90% 的目標(召回率 = 0.9),精確率仍然為 90%。
低平均精確率(例如 0.3):
- 隨著召回率的增加,精確率急劇下降。
- 檢測到 80% 的目標(召回率 = 0.8)可能意味著精確率下降到 20%。
mAP(Mean Average Precision) 僅僅是所有類別 AP 的平均值。
- 例如:如果你的模型可以檢測貓、狗和汽車, m A P = ( A P c a t + A P d o g + A P c a r ) / 3 mAP = (AP_{cat} + AP_{dog} + AP_{car}) / 3 mAP=(APcat?+APdog?+APcar?)/3。
mAP@0.5 與 mAP@0.95
mAP@0.5:
- 使用寬松的 IoU 閾值(50% 的重疊)。
- 常用于通用目標檢測(例如 PASCAL VOC 數據集)。
- 傾向于檢測到目標的模型,即使邊界框有些偏差。
mAP@0.95:
- 使用嚴格的 IoU 閾值(95% 的重疊)。
- 傾向于具有近乎完美定位的模型。
- 用于高風險應用(例如醫療影像、機器人技術)。
COCO mAP:在 IoU 閾值從 0.5 到 0.95(以 0.05 為增量)的范圍內計算 mAP 的平均值。這平衡了嚴格性和寬松性。
為什么 mAP 是最終的信任指標?
- 平衡精確率與召回率:與準確率不同,mAP 會懲罰那些錯過目標(低召回率)或產生大量誤檢測(低精確率)的模型。
- 定位很重要:通過使用 IoU,mAP 確保邊界框不僅僅是“足夠好”,而是達到你設定的閾值精度。
- 類別無關:適用于多類別檢測,不會偏向頻繁出現的類別。
對于 YOLO 模型(既注重速度又注重精度),mAP 可以告訴你:
- 檢測的可靠性(精確率)。
- 漏掉的目標數量(召回率)。
- 邊界框的緊密程度(IoU)。
結論
目標檢測是一項復雜的任務,評估其性能需要一個能夠平衡精確率、召回率和定位精度的指標。這就是 mAP 的閃光點。它不僅僅是一個數字,而是衡量你的模型檢測目標、繪制邊界框以及處理多類別能力的綜合指標。
無論你使用的是 YOLO、Faster R-CNN 還是其他任何目標檢測框架,mAP 都為你提供了一個單一且可靠的指標,用于比較模型、調整超參數并將性能提升到更高水平。有了 mAP@0.5 和 mAP@0.95 等變體,你可以根據特定應用的精度要求定制評估。
所以,下次你訓練目標檢測模型時,不要只看 mAP 分數 —— 要理解它。因為當涉及到衡量檢測性能時,mAP 不僅僅是一個指標;它就是那個指標。


 的全新角色模組 - 女巫)
)



(vscode))



)







