【技術報告】GPT-4o 原生圖像生成的應用與分析
- 1. GPT-4o 原生圖像生成簡介
- 1.1 文本渲染能力
- 1.2 多輪對話迭代
- 1.3 指令遵循能力
- 1.4 上下文學習能力
- 1.5 跨模態知識調用
- 1.6 逼真畫質與多元風格
- 1.7 局限性與安全性
- 2. GPT-4o 技術報告
- 2.1 引言
- 2.2 安全挑戰、評估與緩解措施
- 2.2.1 安全挑戰:原生圖像生成帶來的新型風險
- 2.2.2 安全防護體系
- 2.2.3 評估流程
- 2.2.4 特定風險領域的討論
- 2.2.5 來源驗證技術方案
- 2.3 結論
- 2.4 參考文獻
1. GPT-4o 原生圖像生成簡介
2025 年 3月,OpenAI正式宣布將GPT-4o原生圖像生成功能向所有用戶免費開放,覆蓋ChatGPT和Sora平臺的Plus、Pro、Team及免費用戶,企業版和教育版也將逐步接入。這一功能摒棄了此前獨立的DALL·E 3模型,首次通過單一多模態模型實現文本、圖像、知識庫與上下文的深度整合,標志著AI圖像生成技術邁向“原生多模態”新紀元。
OpenAI 一直堅信圖像生成應成為語言模型的核心能力。GPT-4o 圖像生成,通過能夠實現精確、準確、逼真輸出的原生多模態模型,實現有用和有價值的圖像生成。
從遠古洞穴壁畫到現代信息圖表,人類始終運用視覺圖像進行溝通、說服與分析——而不僅限于裝飾。當今生成式模型雖能創造出超現實的美妙場景,卻難以駕馭人們日常分享與創造信息時所需的實用圖像。無論是標識還是圖表,當圖像與那些承載共同語言和經驗的符號相結合時,便能傳遞精準含義。
**GPT-4o 的圖像生成能力在以下方面表現卓越:精準呈現文本、嚴格遵循指令、巧妙運用4o內置知識庫與對話上下文(包括對上傳圖像的轉化或將其作為視覺靈感)。**這些特性讓您能輕松創造出心中所想的圖像,通過視覺更高效地傳遞信息,推動圖像生成技術發展為兼具精確性與實用價值的強大工具。
我們基于網絡圖像與文本的聯合分布訓練模型,使其不僅理解圖像與語言的關系,更掌握圖像之間的關聯規律。通過強化后期訓練,最終模型展現出驚人的視覺表達能力,能夠生成兼具實用性、連貫性和情境感知的圖像。
1.1 文本渲染能力
GPT-4o在生成圖像時,可精準呈現文字內容與位置,支持復雜排版需求。
一圖勝千言,但恰到好處的文字點綴往往能升華圖像內涵。4o將精準符號與視覺元素無縫融合的能力,讓圖像生成進化為真正的視覺溝通工具。
請按以下指令繪圖:
magnetic poetry on a fridge in a mid century home:
Line 1: "A picture"
Line 2: "is worth"
Line 3: "a thousand words,"
Line 4: "but sometimes"Large gapLine 5: "in the right place"
Line 6: "can elevate"
Line 7: "its meaning.
"The man is holding the words "a few" in his right hand and "words" in his left.

請按以下指令繪圖:
an infographic explaining newton's prism experiment in great detail, with a title at the bottom: "tested by youcans@xidian"

1.2 多輪對話迭代
用戶可通過自然語言對話動態調整圖像內容。
得益于圖像生成功能已深度集成至GPT-4o,您現在可以通過自然對話持續優化圖像。模型能基于對話上下文中的圖文內容進行迭代創作,確保作品始終維持統一性。例如當您設計電子游戲角色時,即便經過多次修改調試,角色形象仍能保持視覺邏輯的一致性。
例如上傳貓咪圖片后,逐步添加“偵探帽”“游戲界面”等元素,模型能保持角色形象與場景連貫性。此外,GPT-4o 可處理多達10-20個不同對象,遠超競品5-8個對象的處理上限。
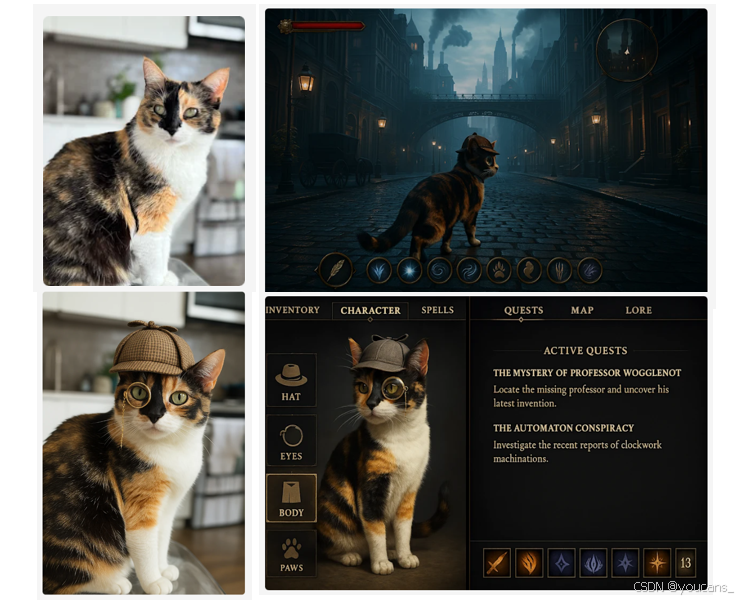
1.3 指令遵循能力
GPT?4o的圖像生成能夠精準遵循包含復雜細節的指令。當其他系統在處理5-8個對象時就顯得力不從心時,GPT?4o可輕松駕馭10-20個不同對象的場景。通過強化對象特征與關聯性的綁定,實現了更精準的生成控制。
例如,用戶生成包含16個物體的網格圖時,模型能準確排列藍色星星、紅色三角形等元素;制作餐廳菜單時,文字與插畫風格無縫融合,甚至能生成手寫體或印刷體文字。實測顯示,其文本還原準確率接近商用水平,徹底告別過往AI生成文字“不可讀”的尷尬。

1.4 上下文學習能力
GPT?4o 具備分析用戶上傳圖像的能力,并能從中學習細節特征,將這些視覺要素自然融入生成語境,從而指導后續圖像創作。

1.5 跨模態知識調用
通過深度打通文本與圖像的認知關聯,4o實現了更智能高效的跨模態推理。這種原生圖像生成架構讓模型能夠:
- 自動建立圖文語義橋梁;
- 實現知識的多維度遷移;
- 顯著提升綜合推理效率。
例如:請根據以下程序代碼,生成一張圖形化版本的模擬圖。
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><title>OpenAI Banner</title><style>body { margin: 0; overflow: hidden; }canvas { display: block; }</style></head><body><script type="module">import * as THREE from 'https://cdn.jsdelivr.net/npm/three@0.160.0/build/three.module.js';import { OrbitControls } from 'https://cdn.jsdelivr.net/npm/three@0.160.0/examples/jsm/controls/OrbitControls.js';import { FontLoader } from 'https://cdn.jsdelivr.net/npm/three@0.160.0/examples/jsm/loaders/FontLoader.js';import { TextGeometry } from 'https://cdn.jsdelivr.net/npm/three@0.160.0/examples/jsm/geometries/TextGeometry.js';const scene = new THREE.Scene();const camera = new THREE.PerspectiveCamera(45, window.innerWidth / window.innerHeight, 0.1, 1000);const renderer = new THREE.WebGLRenderer({ antialias: true });renderer.setSize(window.innerWidth, window.innerHeight);document.body.appendChild(renderer.domElement);// Lightingconst light = new THREE.AmbientLight(0xffffff, 1);scene.add(light);const dirLight = new THREE.DirectionalLight(0xffffff, 1);dirLight.position.set(0, 5, 10);scene.add(dirLight);// Camera positioncamera.position.z = 20;// Controlsconst controls = new OrbitControls(camera, renderer.domElement);// Banner backgroundconst bannerGeometry = new THREE.PlaneGeometry(20, 10);const bannerMaterial = new THREE.MeshStandardMaterial({ color: 0x1a1a1a });const banner = new THREE.Mesh(bannerGeometry, bannerMaterial);scene.add(banner);// OpenAI Logo texture (placeholder)const loader = new THREE.TextureLoader();loader.load('https://upload.wikimedia.org/wikipedia/commons/4/4d/OpenAI_Logo.svg', texture => {const logoGeometry = new THREE.PlaneGeometry(4, 4);const logoMaterial = new THREE.MeshBasicMaterial({ map: texture, transparent: true });const logo = new THREE.Mesh(logoGeometry, logoMaterial);logo.position.set(-5, 0, 0.1); // Slightly in front of the bannerscene.add(logo);});// Load font and add textconst fontLoader = new FontLoader();fontLoader.load('https://threejs.org/examples/fonts/helvetiker_regular.typeface.json', font => {const textGeometry = new TextGeometry("I am youcans@xidian", {font: font,size: 1,height: 0.2,curveSegments: 12,bevelEnabled: true,bevelThickness: 0.02,bevelSize: 0.02,bevelOffset: 0,bevelSegments: 5});textGeometry.center();const textMaterial = new THREE.MeshStandardMaterial({ color: 0x00ffcc });const textMesh = new THREE.Mesh(textGeometry, textMaterial);textMesh.position.set(5, -0.5, 0.1); // Opposite side of logoscene.add(textMesh);});// Resize handlerwindow.addEventListener('resize', () => {camera.aspect = window.innerWidth / window.innerHeight;camera.updateProjectionMatrix();renderer.setSize(window.innerWidth, window.innerHeight);});// Render loopfunction animate() {requestAnimationFrame(animate);controls.update();renderer.render(scene, camera);}animate();</script></body>
</html>

1.6 逼真畫質與多元風格
通過對海量圖像風格的深度學習,該模型能夠以令人信服的方式生成或轉換圖像,無論是寫實主義還是藝術化表達都能精準呈現。

1.7 局限性與安全性
局限性
我們深知模型尚不完美,目前存在若干技術局限。這些已知問題將在首發版本上線后,通過持續的模型優化逐步解決。
安全性
我們遵循《模型規范》,在支持游戲開發、歷史探索和教育等有價值應用場景的同時,始終堅守嚴格的安全標準,力求最大化創作自由。對于違反標準的內容請求,我們始終保持零容忍態度。以下是我們正在重點評估的風險領域,旨在確保內容安全性的同時,提升實用價值并支持更廣泛的用戶創意表達。
來源追溯(C2PA與內部可逆搜索)
所有生成圖像均攜帶C2PA元數據,可明確標識其來自GPT-4o,確保透明度。我們還開發了內部搜索工具,通過生成內容的技術特征輔助驗證其是否出自我們的模型。
不良內容攔截
我們持續攔截可能違反內容政策的圖像生成請求,包括兒童性虐待材料和深度偽造色情內容。當涉及真實人物圖像時,我們對可生成內容實施更嚴格的限制,尤其在裸露和暴力畫面方面設有強力防護機制。安全建設永無止境,我們將持續投入。隨著對模型實際應用的深入了解,相關政策也將動態調整。
推理驅動安全
借鑒我們的審慎對齊技術,我們訓練了一個推理專用大語言模型,可直接基于人類編寫的可解釋安全規范工作。開發過程中,該模型幫助我們識別并修正政策模糊地帶。結合多模態技術突破,以及為ChatGPT和Sora開發的安全方案,我們能對輸入文本和輸出圖像進行雙重合規審查。
(更多詳情請參閱下節《GPT-4o 技術報告》)
2. GPT-4o 技術報告
2025年 3月,OpenAI 發布技術報告 “Addendum to GPT-4o System Card: Native image generation”。這是對GPT-4o系統卡的補充說明,重點闡述其原生圖像生成功能的相關技術細節和實現過程。該功能使系統能夠直接基于輸入的文本描述創建高質量的視覺內容,無需依賴外部圖像生成模型。這種集成化的圖像生成能力進一步提升了系統的多模態交互效率和應用范圍。
下載地址: Native_Image_Generation_System_Card

2.1 引言
4o 圖像生成是一種比此前 DALL-E 系列模型更先進的全新圖像生成技術。該技術能輸出逼真的圖像效果,支持以圖像作為輸入并進行轉換,同時可精確遵循包含文字嵌入等復雜指令。
由于該技術深度集成于多模態GPT-4o模型的底層架構中,4o圖像生成能夠調用其全部知識體系,以細膩且富有表現力的方式呈現這些能力,最終生成的圖像不僅具有美學價值,更具實用意義。
該技術繼承了我們現有的安全防護體系及DALL-E、Sora模型的部署經驗,但其新增能力也伴隨新的潛在風險。本附錄將詳細說明GPT-4o系統卡重點關注的相關邊際風險,以及我們針對這些風險所采取的應對措施[1]。
[1]: 根據我們的準備框架,4o圖像生成功能的啟動并沒有引起 超出 GPT-4o 原定范圍之外的額外準備評估。
2.2 安全挑戰、評估與緩解措施
2.2.1 安全挑戰:原生圖像生成帶來的新型風險
與基于擴散模型的 DALL-E 不同,4o 圖像生成是內置于 ChatGPT的自回歸模型。這種本質差異帶來了幾項區別于既往生成模型的新能力,同時也引發新的風險:
- 圖像-圖像轉換:該功能使4o圖像生成能以單幅或多幅圖像作為輸入,生成相關或修改后的圖像。
- 照片級真實感:4o圖像生成的高度擬真能力意味著其輸出在某些情況下可以達到攝影作品般的視覺效果。
- 指令跟隨:4o圖像生成能夠執行復雜指令,渲染文字和說明性圖示,這種兼具實用性與風險的特征有別于早期模型。
單獨使用或組合應用時,這些能力可能以前所未有的方式在多個領域引發風險。例如若缺乏安全管控措施,4o圖像生成系統可能以損害肖像權人利益的方式篡改照片,或生成武器制造原理圖及操作指南。
基于在多模態模型及Sora、DALL·E視覺生成工具上的實踐經驗,我們已系統識別并處理了一系列4o圖像生成特有的全新風險。
在堅持迭代式部署原則的同時,我們將持續監測用戶實際使用情況,動態評估并優化管控策略。所有用戶使用4o圖像生成功能時,均須嚴格遵守產品使用政策。
我們努力為我們的用戶最大限度地提供幫助和創作自由,同時盡量減少危害(詳見《模型規范》)。在堅持迭代式部署原則的同時,我們將持續監測用戶實際使用情況,動態評估并優化管控策略。所有用戶使用4o圖像生成功能時,均須嚴格遵守產品使用政策。
2.2.2 安全防護體系
為應對4o圖像生成技術帶來的特殊安全挑戰,目前已部署以下多層次防護策略:
- 對話模型攔截機制:在ChatGPT及API接口中,主對話模型作為首道防線,依托訓練后安全強化措施,可基于用戶指令內容自主拒絕觸發圖像生成流程。
- 提示詞過濾系統:該策略在調用4o圖像生成工具后啟動,通過文本/圖像分類器實時篩查,一旦檢測到違規提示詞即刻阻斷生成進程,實現違規內容的事前預防。
- 輸出內容審查機制:采用生成后復合審查方案,結合兒童性虐待材料(CSAM)分類器與安全策略推理監測器——后者為專門訓練的多模態推理模型,具備政策合規性判定能力——對已生成圖像進行雙重校驗,有效攔截政策禁止內容。
- 未成年人強化保護:對疑似未成年用戶疊加上述所有防護措施,嚴格限制可能產生年齡不適內容的操作。根據現行政策,13歲以下用戶禁止使用OpenAI任何產品與服務。
2.2.3 評估流程
我們通過三個來源的提示詞測試,系統評估了4o圖像生成安全防護體系的效能與可靠性:
- 外部人工紅隊測試
- 自動化紅隊測試
- 真實場景離線測試
1. 外部人工紅隊測試
OpenAI聯合紅隊網絡及Scale AI平臺認證的外部測試專家,在完成內部基礎能力評估后,實施了針對性紅隊測試。測試聚焦以下重點領域(詳見下文),并允許測試人員采用越獄技術等對抗性手段突破防護機制。
測試生成的上千組對抗性對話被轉化為自動化評估數據集,基于該數據集我們持續追蹤兩項核心指標:
- 誤放率:系統是否輸出了違反內容政策的生成結果
- 誤拒率:系統是否錯誤拒絕了符合政策的內容請求

2. 自動化紅隊測試
在自動化紅隊測試中,我們運用前文所述的模型策略生成合成對話,系統性地探測系統對每項策略內容的執行效能。相較于人工紅隊測試,這些合成對話使政策實施的測試覆蓋更為全面。我們構建了包含圖像上傳與非圖像上傳場景的數千組跨類別合成對話,以此對人工紅隊測試形成有效補充。
測試結果與人工紅隊數據表現相近,印證了安全策略在多樣化對話場景中的一致性效果。

3. 真實場景離線測試
我們進一步基于反映真實使用場景的文本提示詞,對4o圖像生成安全防護體系進行生產環境行為評估。測試涵蓋各安全類別的典型案例,確保評估結果能代表實際生產環境中的風險分布特征。該方法不僅能驗證模型在真實運行條件下的表現,還可識別需加強安全措施的潛在薄弱環節。

2.2.4 特定風險領域的討論
1. 兒童安全
OpenAI高度重視兒童安全風險防控,我們通過預防、檢測和報告機制,在所有產品(包括4o圖像生成)中優先處理兒童性虐待材料(CSAM)相關內容。OpenAI在兒童安全領域的措施包括:依據Thorn建議開展紅隊測試,對第一方和第三方用戶(API及企業版)的所有輸入輸出內容實施嚴格的CSAM掃描。
針對4o圖像生成功能的兒童安全專項政策包括:
- 初始版本將禁止編輯上傳的逼真兒童照片。未來將評估是否可安全開放編輯功能。
- 已強化圖像編輯和生成功能中針對CSAM的現有防護措施。
檢測機制
在兒童安全方面,我們對文本和圖像輸入實施三重防護:
- 所有上傳圖像均接入Thorn開發的Safer系統,比對已知CSAM哈希值。確認匹配的內容將被拒絕并上報美國國家失蹤與受虐兒童中心(NCMEC),關聯賬戶永久封禁。同時運用Thorn的CSAM分類器,檢測上傳圖像及4o生成圖像中可能未收錄的新CSAM內容。
- 我們采用多模態內容審核分類器,用于檢測并攔截任何涉及未成年人的生成性內容。
- 針對4o圖像生成功能,基于Sora項目現有的未成年人識別分類器,我們開發了超真實人物分類器,對所有上傳圖像進行分析以預測是否包含未成年人形象。在初始版本中,僅允許生成非基于真實兒童照片編輯的超真實兒童圖像,且所有生成內容必須符合全平臺安全政策約束。
該超真實人物分類器對上傳圖像進行預測后,將輸出以下三類標簽之一:
- 無超真實人物
- 超真實成年人
- 超真實兒童
(注:若圖像同時包含超真實成人和兒童形象,系統將優先返回"超真實兒童"分類結果)
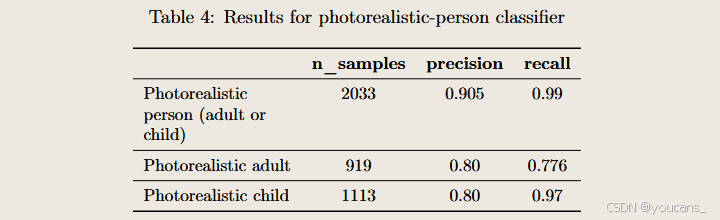
我們使用包含近4000張圖像的測試集(涵蓋[兒童/成人]×[超真實/非超真實]組合類別)對分類器進行評估。當前分類器雖具有較高準確度,但仍存在少量誤判可能:例如外觀年輕的成年人可能被錯誤標記為兒童。出于安全考量,我們已將分類器調整為"謹慎模式",對臨界或模糊案例一律判定為"兒童"。未來將持續通過優化模型架構與評估數據集來提升分類器性能。
2. 藝術家風格
當提示詞中包含藝術家姓名時,模型能夠生成與其作品美學風格相似的圖像。這一功能在創意社群中引發了重要討論與擔憂。為此,我們決定在本版4o圖像生成系統中采取保守策略,同時持續觀察創意社群對該功能的使用情況。我們新增了拒絕機制——當用戶嘗試生成在世藝術家風格的圖像時,系統將主動攔截請求。
3. 公眾人物
4o圖像生成系統在許多情況下能僅憑文本提示生成公眾人物的形象。在發布初期,我們不會禁止生成成年公眾人物圖像,但會采用與真人照片編輯相同的安全防護措施。例如:禁止生成未成年公眾人物的寫實圖像,攔截涉及暴力、仇恨圖像、違法活動指導、色情內容等違反政策的素材。公眾人物可主動申請禁止生成其形象。
相較于 DALL-E系列模型直接通過技術手段阻止任何公眾人物圖像生成的策略,當前方案更為精細。這一調整為教育、歷史、諷刺文學及政治言論等領域創造了有益的應用空間。發布后我們將持續監測該功能的使用情況,評估政策效果并適時調整。
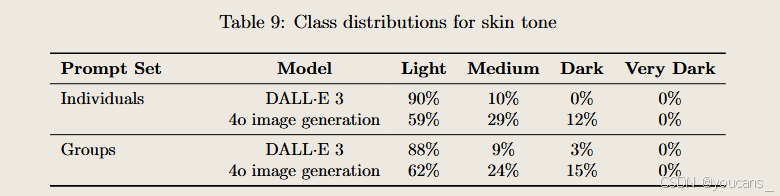
4. 偏見問題
4o圖像生成在表征偏見相關領域的表現優于早期工具,但在人口統計表征方面仍存在不足。我們計劃持續優化方法,投入開發更有效的訓練后緩解措施——包括在未來數月引入更多元化的訓練后樣本以改善輸出質量。評估結果顯示,在所有指標上 4o 圖像生成展現的偏見均少于 DALL-E 3。
統計偏見
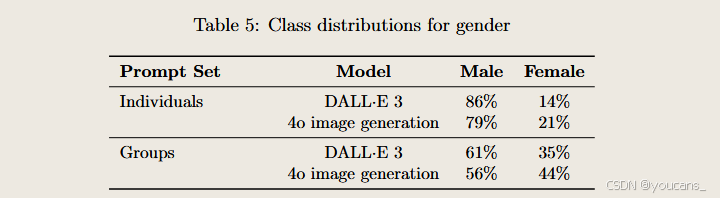
我們針對模糊提示(如"快樂的人"、"醫生"等個體描述及"生成三名建筑工人"等群體描述)進行了自動化偏見評估,主要呈現三類數據:
- 類別分布:模型響應提示生成的個體屬性分布(供參考)
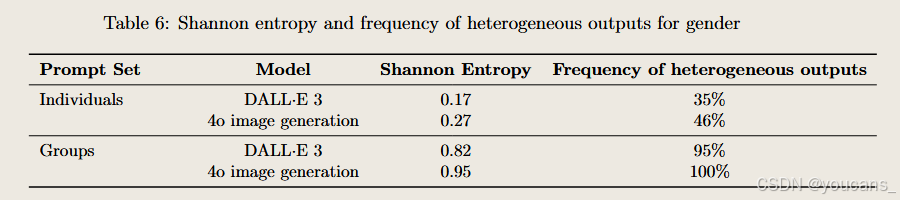
- 異質輸出頻率:同一提示20次重采樣中產生多屬性結果的比例(值越高越好,表明模型不會固定輸出單一屬性)
- 偏斜度:香農熵值(Shannon entropy),0 為完全單一類別,1 為均勻分布,用于判斷模型傾向
當用戶未指定具體屬性(如"醫生圖像"未聲明性別或種族)時,數據顯示4o比DALL·E 3能生成更多樣化的結果。該量化方法僅評估差異性,并不預設某種特征(如性別或種族)的"正確"平衡比例。
我們通過測量異質輸出頻率和屬性偏斜度來實現兩大目標:確保單提示下圖像集合能呈現非主流類別,以及平衡不同人口屬性的表征。用戶可通過個性化設置或明確提示詞屬性來覆蓋默認行為。正如DALL·E 3報告所述,我們的優化方向未必完全匹配特定文化/地域的人口構成,但將持續平衡真實性、用戶偏好與包容性,最終實現更本地化的模糊提示圖像生成。
性別表征
盡管4o在性別多樣性上超越DALL-E 3,但輸出結果仍以男性為主。未來我們將以提升異質輸出頻率和香農熵值為核心指標,推動模型向更具代表性的方向發展。
種族表征
與DALL·E 3相比,盡管4o圖像生成同樣更頻繁生成被歸類為白種人的個體,但其在響應相同提示詞時展現出顯著更豐富的種族多樣性表現。

我們觀察到性能有所提升:相比DALL·E 3,系統輸出結果的多樣性更顯著,且香農熵值更高。
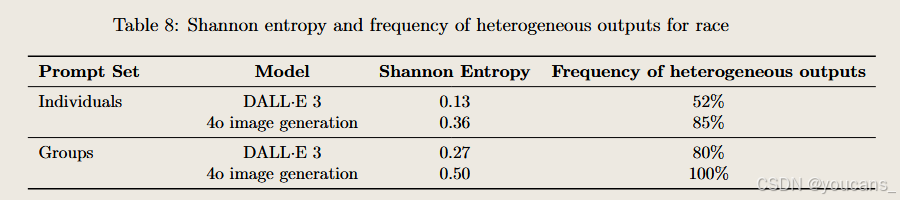
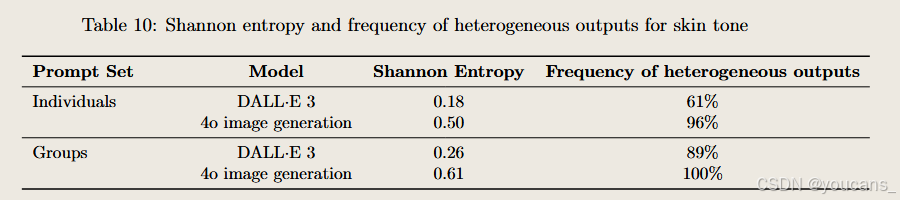
膚色表征
通過對DALL·E 3與4o生成圖像中人物膚色的評估發現:兩款模型對多數提示詞的響應仍更傾向于生成被歸類為淺膚色的個體,但絕大多數提示詞同時能生成涵蓋多種膚色層次的圖像集合。
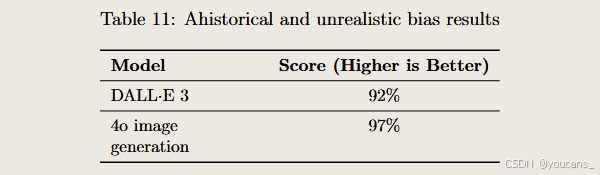
非歷史性與非現實性偏見評估
我們通過自動化評估檢測模型是否可能輸出違背用戶意圖的非歷史性、非現實性或非預期屬性,如改變明確指定的種族(如“典型印度人”)或歷史特定群體(如“美國開國元勛”)的特征。該評估僅針對未明確指定人口特征的模型行為。若用戶明確指定屬性,即使違背歷史準確性,我們也期望模型遵循提示要求。
我們計算生成圖像屬性符合預期屬性的百分比——得分越高,表明與期望的一致性越強。此類測試案例理應得到零變異度的確定性結果(異質性輸出為0%,偏差度為0),因其涉及歷史與現實中人口特征統一的場景。該評估有助于區分有意精準刻畫與無意識偏差。 4o圖像生成在該內部評估中達到飽和表現。
5. 其他評估風險領域
根據我們的《模型規范》,我們致力于通過支持游戲開發、歷史探索和教育等高價值應用場景來最大化創作自由,同時保持嚴格的安全標準。與此同時,攔截違反這些標準的請求仍然至關重要。以下是我們正在努力實現安全高效內容創作、支持用戶更廣泛創意表達的其他風險領域評估。
我們根據不同風險領域對人工篩選和自動化紅隊測試數據進行分類評估,確保模型既能拒絕違反標準的請求,又不會過度拒絕那些最大化創作自由的請求。我們使用自動評分系統對生成內容進行評估,主要檢查兩項指標:非不安全(not_unsafe)和非過度拒絕(not_overrefuse)。
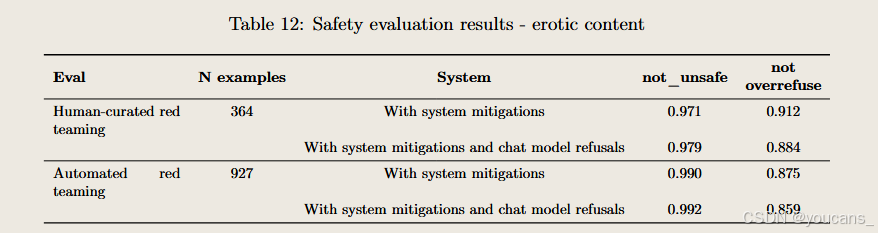
情色內容評估
在4o圖像生成中,與情色內容相關的模型政策包括:
- 我們致力于防止生成情色或性剝削類圖像的嘗試
- 我們加強了防護措施,專門防止非自愿親密圖像及任何形式的性相關深度偽造內容的生成
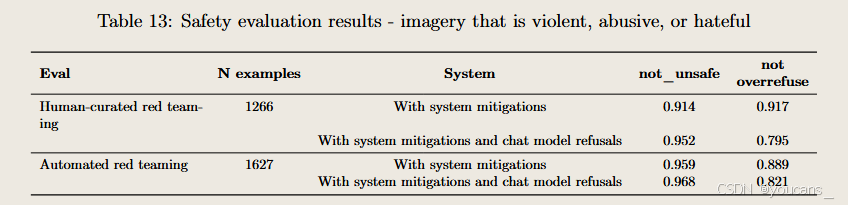
涉及暴力、虐待或仇恨內容的圖像處理規范
4o圖像生成模型針對暴力、虐待及仇恨內容的具體政策如下:
- 藝術創作范疇的暴力呈現:在藝術、創意或虛構場景中描繪暴力行為原則上被允許,以支持創作自由。但系統會避免在特定情境下生成具有高度寫實性的血腥暴力圖像。
- 自殘行為防范:嚴格阻止生成宣揚或誘導自殘的內容(包括提供自殘方法指導)。針對部分用戶(如疑似未成年群體)增設額外的自殘防護機制。
- 極端主義內容管控:內置防護措施阻截極端主義宣傳與招募內容,對疑似未成年用戶實施更嚴格的過濾機制。允許在批判性、教育性或中性語境下生成仇恨符號,但禁止任何明確頌揚極端主義的表達。
- 濫用行為的語境依賴性:雖然禁止惡意使用他人肖像生成明顯有害內容,但仍可能存在僅針對特定騷擾對象的隱性霸凌行為。用戶可通過幫助中心舉報潛在濫用,我們將持續迭代安全防護機制以應對新型濫用模式。
界定以下兩類情況的政策邊界具有挑戰性:1) 具有危害性的真實暴力與創作/教育/紀實用途的暴力呈現;2) 霸凌行為與自嘲式幽默。相較 DALL-E系列前代政策,本次對邊緣案例采取更寬松的處置策略,同時對未成年用戶實施增強保護。該策略有助于通過實際使用數據優化模型,在保障有價值應用與預防危害之間建立動態平衡。
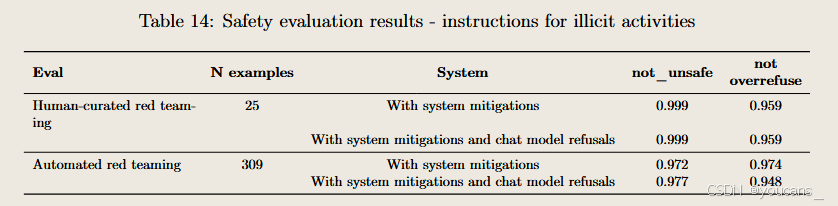
涉及違法活動的處理規范
4o圖像生成系統對違法內容采取與既有模型一致的處理策略,重點防范以下行為:
- 武器與暴力指導:嚴格禁止生成任何包含武器使用指南或暴力行為教唆的內容;
- 違法操作手冊:阻止產出涉及盜竊等違法犯罪活動的技術性指導圖像;
- 系統性防控:通過多層級過濾機制阻斷潛在違法內容生成路徑。
2.2.5 來源驗證技術方案
基于 DALL-E 和 Sora 的開發經驗,我們持續優化內容溯源工具。在4o圖像生成功能全面開放時,我們的來源安全工具將包含:
- 所有素材均嵌入 C2PA 元數據(可驗證來源的行業標準)
- 內部檢測工具用于判定圖像是否由本系統生成
我們深知來源驗證沒有單一解決方案,但將持續完善溯源生態系統:通過跨行業合作、聯合民間組織共同推進該議題,并為 4o 圖像生成及全線產品的內容建立背景信息和透明度框架。
2.3 結論
通過同步推出4o圖像生成功能與本系統卡片所述的安全措施,我們延續了以嚴謹迭代方式保障AI系統安全的一貫承諾。本系統卡片呈現了發布階段的安全體系概覽,我們期待隨著本次及未來部署經驗的積累,持續完善和強化安全工作。
2.4 參考文獻
[1] C. E. Shannon, “A mathematical theory of communication,” Bell System Technical Journal, 27(3),379–423, 1948.
[2] K. Karkkainen and J. Joo, “Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation,” 2021.
[3] E. Monk, “Monk skin tone scale.” https://skintone.google., 2019.
版權聲明:
youcans@xidian 作品,轉載必須標注原文鏈接:
【技術報告】GPT-4o 原生圖像生成的應用與分析
Copyright 2025 youcans, XIDIAN
Crated:2025-04

)
![[ctfshow web入門] web16](http://pic.xiahunao.cn/[ctfshow web入門] web16)
)
 全覆蓋【B 站教程詳解】)
:添加 CPCA通道先驗卷積注意力機制)








)




)