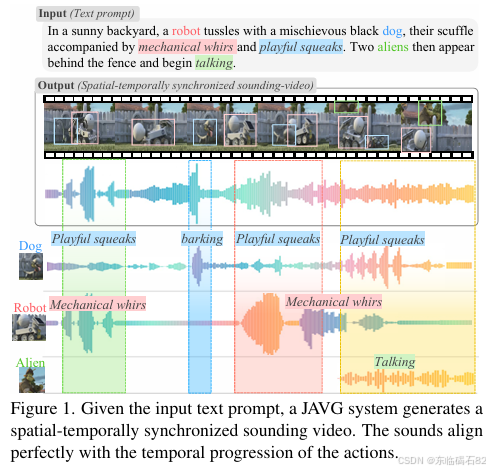
摘要:本文介紹了一種新型的聯合音頻-視頻擴散變換器JavisDiT,該變換器專為同步音頻-視頻生成(JAVG)而設計。 基于強大的擴散變換器(DiT)架構,JavisDiT能夠根據開放式用戶提示同時生成高質量的音頻和視頻內容。 為了確保最佳同步,我們通過分層時空同步先驗(HiST-Sypo)估計器引入了一種細粒度的時空對齊機制。 該模塊提取全局和細粒度的時空先驗,指導視覺和聽覺組件之間的同步。 此外,我們提出了一個新的基準測試JavisBench,由10140個高質量的文本字幕發聲視頻組成,這些視頻涵蓋了不同的場景和復雜的現實場景。 此外,我們專門設計了一個魯棒的指標來評估在現實世界復雜內容中生成的音頻-視頻對之間的同步。 實驗結果表明,JavisDiT在確保高質量生成和精確同步方面明顯優于現有方法,為JAVG任務設定了新的標準。 我們的代碼、模型和數據集將在https://javisdit.github.io/上公開發布。Huggingface鏈接:Paper page,論文鏈接:2503.23377
研究背景和目的
研究背景
隨著人工智能生成內容(AIGC)領域的快速發展,生成多模態內容,如圖像、視頻和音頻,已經吸引了廣泛的研究關注。特別是,同步音頻和視頻生成(JAVG)作為多模態內容生成的一個重要分支,具有廣泛的應用前景,如電影制作和短視頻創作。然而,現有的JAVG方法仍面臨諸多挑戰。一方面,如何確保高質量的單模態音頻和視頻生成是一個核心問題;另一方面,如何實現音頻和視頻之間的精確同步是另一個重要挑戰。
傳統的JAVG方法主要分為兩類:異步流水線方法和端到端的聯合音視頻生成(JAVG)方法。異步流水線方法通常先生成音頻,然后基于音頻合成視頻,或者反之。這種方法雖然簡單,但容易積累級聯噪聲。而端到端的JAVG方法則通過避免級聯噪聲積累吸引了更多研究關注,但仍存在一些問題。例如,大多數方法缺乏對同步的精細建模,無法實現音頻和視頻之間的精確時空對齊。
此外,現有的JAVG基準測試集也存在一些局限性,如音頻視頻內容過于簡單、場景多樣性不足等。這些局限性使得在復雜現實場景下的模型評估變得困難,限制了JAVG技術的進一步發展。
研究目的
針對上述挑戰,本文提出了JavisDiT,一種新型的基于擴散變換器(DiT)的JAVG系統。JavisDiT旨在解決兩個關鍵問題:一是如何生成高質量的音頻和視頻內容;二是如何實現音頻和視頻之間的精確同步。為了實現這一目標,本文設計了分層時空同步先驗(HiST-Sypo)估計器,以提取全局和細粒度的時空先驗,指導音頻和視頻之間的同步。同時,本文還構建了一個新的基準測試集JavisBench,包含10,140個高質量的文本字幕發聲視頻,涵蓋了多樣化的場景和復雜的現實場景。此外,本文還提出了一種魯棒的指標來評估生成的音頻視頻對在現實復雜內容中的同步性。
研究方法
JavisDiT系統架構
JavisDiT系統基于強大的DiT架構,由視頻生成分支、音頻生成分支和多模態雙向交叉注意力模塊組成。在每個分支中,采用了時空自注意力機制進行模態內信息聚合,通過粗粒度交叉注意力機制融入文本語義,通過細粒度時空交叉注意力機制融入時空先驗,并通過雙向交叉注意力機制增強視頻和音頻之間的信息聚合。
分層時空同步先驗估計器
為了實現音頻和視頻之間的精確同步,本文設計了HiST-Sypo估計器。該估計器通過文本編碼器提取輸入文本的全局和細粒度時空先驗,然后利用這些先驗指導視頻和音頻之間的同步。具體來說,HiST-Sypo估計器首先利用ImageBind的文本編碼器提取文本隱藏狀態,然后利用一個4層的Transformer編碼器-解碼器結構提取時空先驗。為了增強估計器的魯棒性,本文還采用了一種對比學習方法來優化HiST-Sypo估計器。
訓練策略
為了同時實現高質量的單模態生成和精確的時空同步,本文采用了一種三階段訓練策略。第一階段是音頻預訓練,利用OpenSora的視頻分支權重初始化音頻分支,并在大規模音頻數據集上進行訓練。第二階段是時空先驗訓練,利用同步的文本-視頻-音頻三元組和合成的異步負樣本訓練HiST-Sypo估計器。第三階段是聯合生成訓練,凍結視頻和音頻分支的自注意力模塊和HiST-Sypo估計器,只訓練時空交叉注意力模塊和雙向交叉注意力模塊,以實現同步的視頻和音頻生成。
新的基準測試集和評估指標
為了全面評估JAVG模型的性能,本文構建了一個新的基準測試集JavisBench,包含10,140個高質量的文本字幕發聲視頻,涵蓋了多樣化的場景和復雜的現實場景。同時,本文還提出了一種新的評估指標JavisScore,用于評估生成的音頻視頻對在現實復雜內容中的同步性。JavisScore通過計算視頻和音頻之間的語義對齊程度來評估同步性,比傳統的AV-Align指標更加魯棒和準確。
研究結果
實驗結果表明,JavisDiT在單模態生成質量和音視頻同步性方面均顯著優于現有方法。在JavisBench基準測試集上,JavisDiT在多個評估指標上均取得了最優性能,包括FVD、FAD、TV-IB、TA-IB、CLIP相似度和JavisScore等。此外,JavisDiT還能夠在復雜場景下實現精確的音視頻同步,這是現有方法所難以做到的。
通過消融實驗,本文還驗證了JavisDiT中各個模塊的有效性。結果表明,時空自注意力機制、細粒度時空交叉注意力機制和雙向交叉注意力機制均對JavisDiT的性能有重要貢獻。特別是細粒度時空交叉注意力機制,通過引入HiST-Sypo先驗顯著提高了音視頻同步性。
研究局限
盡管JavisDiT在JAVG任務上取得了顯著的性能提升,但仍存在一些局限性。首先,JavisDiT的訓練數據規模相對有限,只有0.6M的文本-視頻-音頻三元組。這限制了模型在更多樣化場景下的泛化能力。為了進一步提高模型的泛化能力,需要收集更多高質量的現實世界音視頻樣本。
其次,JavisScore評估指標雖然比傳統的AV-Align指標更加魯棒和準確,但其準確率仍有待提高。目前JavisScore的準確率為75%,仍有一定的提升空間。未來可以探索更多感知對齊評估方法或引入人工評估來進一步提高評估指標的準確性。
此外,基于擴散模型的生成方法通常計算量較大,生成速度較慢。雖然JavisDiT通過優化模型架構和訓練策略在一定程度上提高了生成效率,但仍難以滿足實時生成的需求。未來可以探索加速采樣策略或硬件優化來進一步提高生成效率。
未來研究方向
針對上述研究局限,未來可以在以下幾個方面開展進一步的研究:
-
擴大訓練數據規模:收集更多高質量的現實世界音視頻樣本,以訓練更大規模的模型,提高模型在更多樣化場景下的泛化能力。
-
提高評估指標準確性:探索更多感知對齊評估方法或引入人工評估來進一步提高評估指標的準確性,為模型優化提供更可靠的反饋。
-
提高生成效率:探索加速采樣策略或硬件優化來進一步提高生成效率,滿足實時生成的需求。例如,可以利用GPU并行計算、模型剪枝和量化等技術來加速生成過程。
-
跨分辨率和時長基準測試:開展跨分辨率和時長的基準測試,以更全面地評估模型在不同設置下的性能,為模型優化提供更全面的指導。
-
探索更多應用場景:將JavisDiT應用于更多實際場景,如電影制作、短視頻創作、虛擬現實和增強現實等,以驗證其在實際應用中的有效性和實用性。
總之,JavisDiT作為一種新型的基于DiT的JAVG系統,在單模態生成質量和音視頻同步性方面均取得了顯著的性能提升。未來可以通過擴大訓練數據規模、提高評估指標準確性、提高生成效率、開展跨分辨率和時長基準測試以及探索更多應用場景等方向來進一步推進JAVG技術的發展。
)







](http://pic.xiahunao.cn/算法刷題記錄——LeetCode篇(2.2) [第111~120題](持續更新))










