目錄
一、投機采樣
二、投機采樣改進:美杜莎模型
流程
改進
三、Deepseek的投機采樣
流程
Ⅰ、輸入文本預處理
Ⅱ、引導模型預測
Ⅲ、候選集篩選(可選)
Ⅳ、主模型驗證
Ⅴ、生成輸出與循環
騙你的,其實我在意透了
????????????????????????????????—— 25.4.4
一、投機采樣
找到一種方式加速我們的推理過程 —— 投機采樣
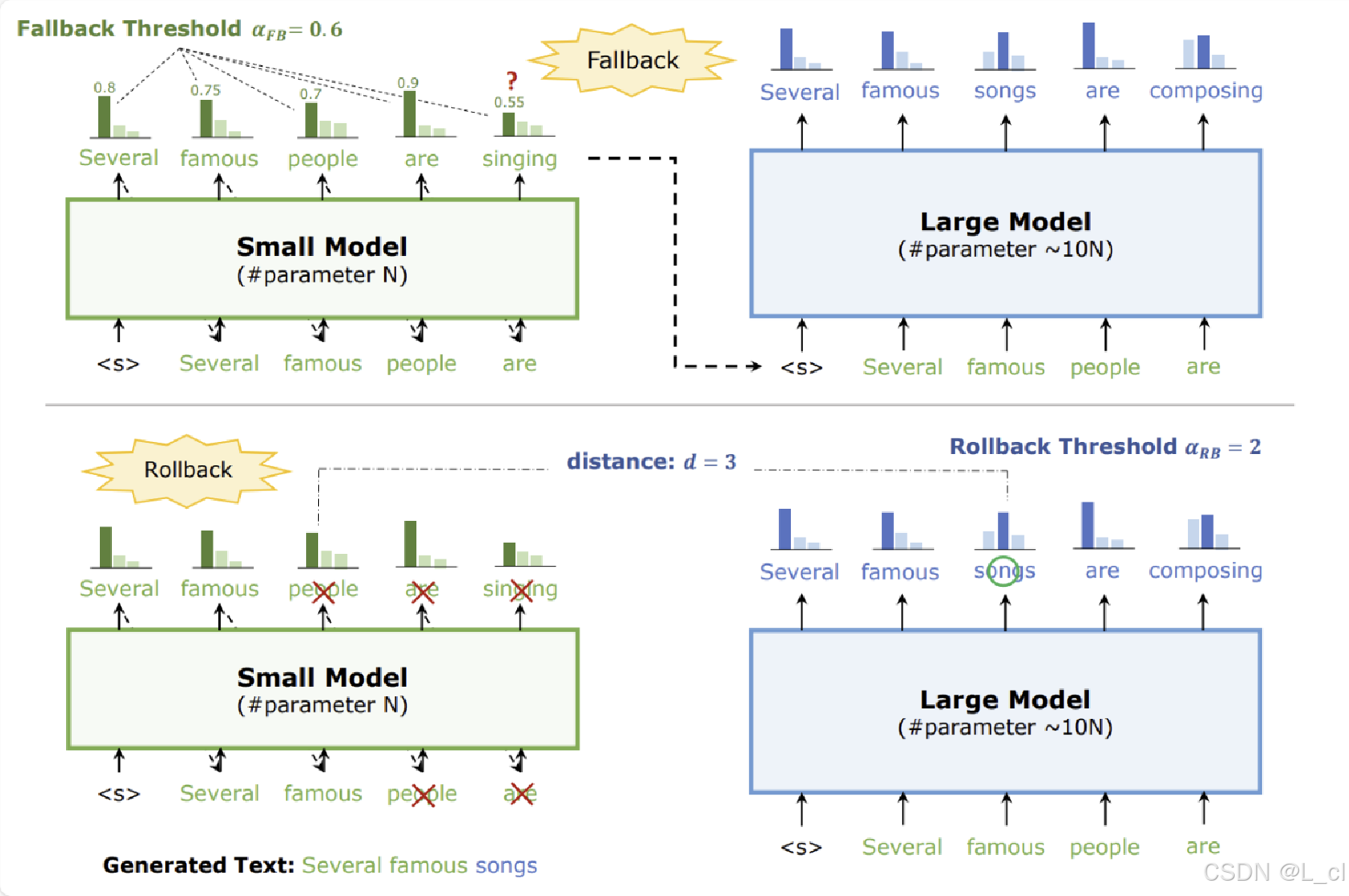
????????投機采樣(Speculative Sampling)是一種用于加速大語言模型推理的技術,它通過預測模型可能生成的下一個 token 來減少計算量,同時盡量保持生成文本的質量 。
分層預測:投機采樣基于這樣一個假設,即可以使用一個較小、更快的 “引導模型”(也稱為 “投機模型”)來對大語言模型(“主模型”)的生成進行預測。引導模型結構簡單、計算成本低,能快速生成可能的下一個 token 及其概率分布。
驗證與修正:引導模型提出若干可能的下一個 token 及其概率。這些預測結果被視為 “投機”。主模型隨后僅對這些投機結果中的部分或全部進行驗證,而不是對所有可能的 token 進行完整計算。如果引導模型的預測與主模型的驗證結果相符,那么就采用引導模型的預測作為生成的下一個 token ,從而跳過主模型對其他大量 token 的計算。如果預測不符,主模型則會按照常規方式計算出正確的下一個 token ,同時這一信息也可用于微調引導模型,使其后續預測更準確。
二、投機采樣改進:美杜莎模型
模型自帶多個頭,代替draft model (投機小模型) 起到打草稿的目的
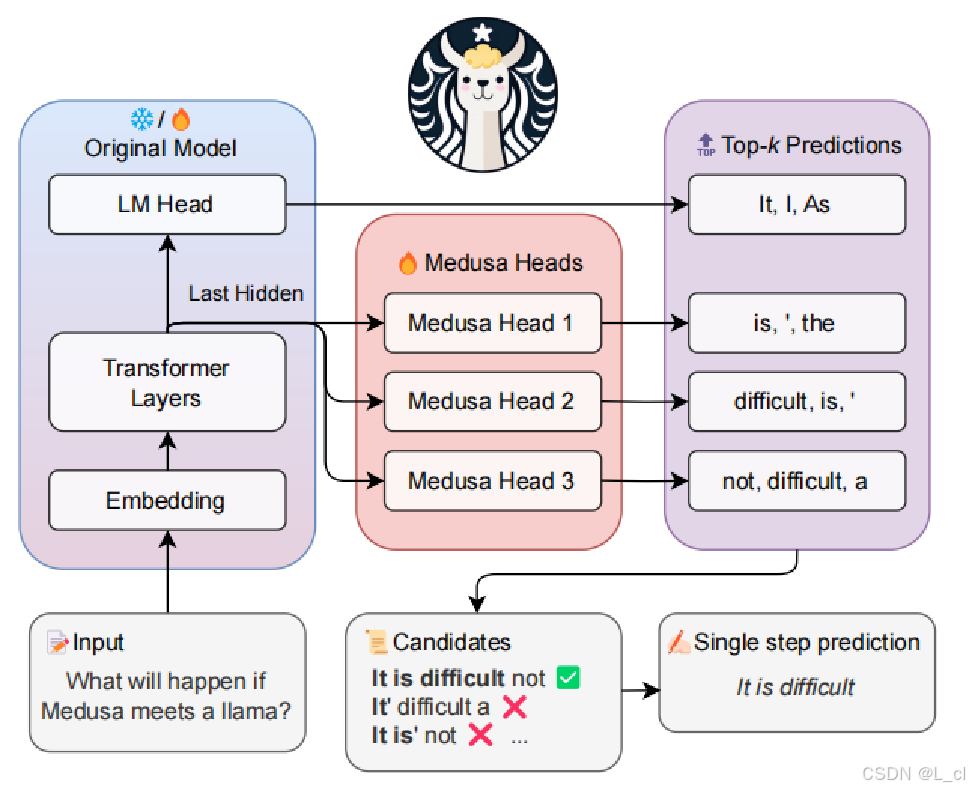
流程
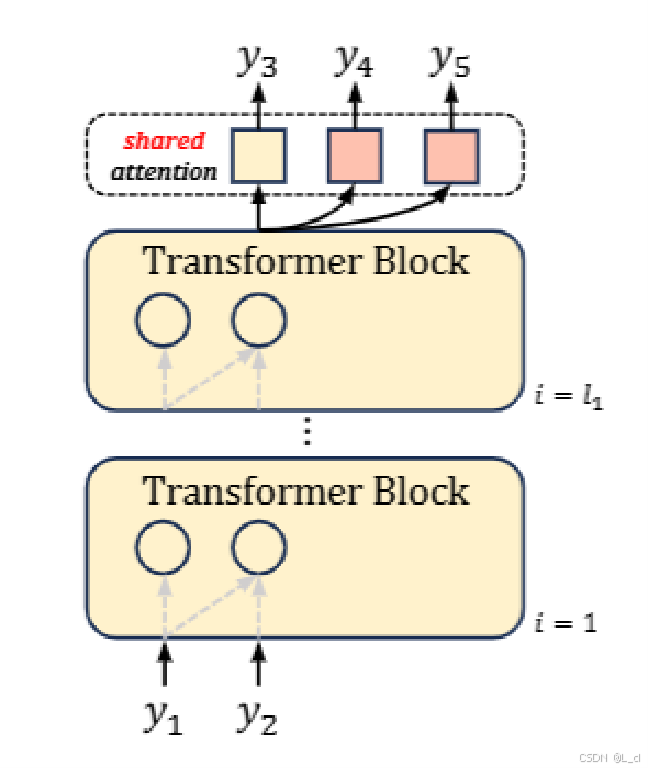
改進
把前一個頭的輸出,作為后一個頭的輸入的一部分;
把前一個頭的輸出當作下一個頭的輸入進行傳遞

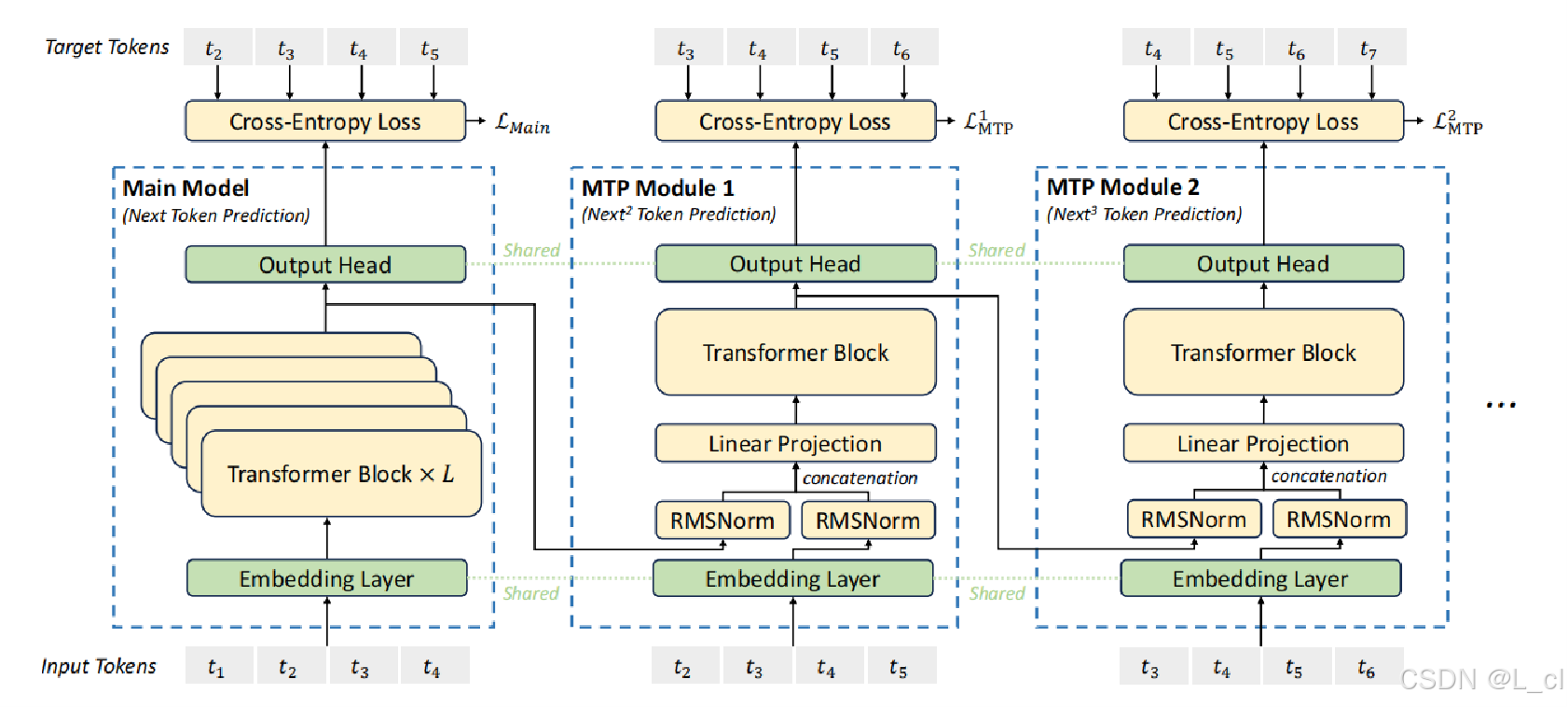
三、Deepseek的投機采樣
雙模型架構:與常見的投機采樣方法類似,Deepseek 采用主模型和引導模型的架構。主模型是具有強大語言處理能力的大型預訓練模型,負責生成高質量的文本。引導模型則相對輕量級,設計目的是快速預測主模型可能生成的下一個詞元(token)。引導模型經過優化,能夠以較低的計算成本對主模型的輸出進行近似預測。
分層預測與驗證:在推理過程中,引導模型首先基于輸入文本生成一系列可能的下一個 token 及其概率分布。這些預測并非隨意生成,而是通過引導模型對語言模式的學習以及對主模型行為的近似模擬得出。然后,主模型對引導模型提供的預測 token 進行驗證。主模型并非對詞匯表中的所有 token 進行全面計算,而是集中精力評估引導模型給出的候選集。若引導模型的預測與主模型的驗證結果匹配,就直接采用引導模型的預測作為生成結果,從而跳過主模型對其他大量 token 的計算,實現加速推理。若預測不匹配,主模型則以常規方式計算正確的下一個 token 。
流程
Ⅰ、輸入文本預處理
文本分詞:將輸入文本送入分詞器,把文本分割成一個個詞元(token)。這是語言模型處理文本的基礎步驟,不同的語言模型可能使用不同的分詞方法,如字節對編碼(Byte - Pair Encoding,BPE)等。通過分詞,將連續的文本轉化為模型能夠理解和處理的離散單元序列。
構建輸入表示:對分詞后的結果進行處理,添加必要的位置編碼、段編碼等信息(如果模型需要),將其轉換為適合模型輸入的張量形式。這個張量包含了文本的詞元信息以及位置等上下文信息,為模型后續的處理提供基礎。
Ⅱ、引導模型預測
快速前向傳播:輕量級的引導模型接收預處理后的輸入張量,通過其神經網絡結構進行快速的前向傳播計算。引導模型經過專門設計和訓練,旨在以較低的計算成本快速生成預測結果。
生成候選 token 及概率:引導模型輸出一組可能的下一個 token 及其對應的概率分布。這些候選 token 是引導模型基于對輸入文本的理解和對主模型生成模式的學習而預測出來的。引導模型通過其內部的參數和訓練學到的語言知識,評估每個可能 token 成為下一個生成詞元的可能性,并輸出概率值。例如,引導模型可能預測下一個 token 有 80% 的概率是 “蘋果”,10% 的概率是 “香蕉” 等。
Ⅲ、候選集篩選(可選)
根據概率排序與篩選:如果引導模型生成的候選 token 數量較多,可能會根據預測概率對候選集進行排序,然后篩選出概率較高的一部分 token 作為最終的候選集。例如,只選擇概率最高的前 5 個 token,這樣可以進一步減少主模型需要驗證的 token 數量,提高整體效率。這一步驟并非絕對必要,具體是否執行以及篩選的標準可能根據模型的設計和應用場景而定。
Ⅳ、主模型驗證
針對候選集計算:主模型接收輸入文本以及引導模型生成的候選 token 集,對這些候選 token 進行驗證。主模型會根據自身強大的語言理解和生成能力,對每個候選 token 在當前上下文下的合理性進行評估。與傳統生成方式不同,此時主模型無需對整個詞匯表中的所有 token 進行計算,大大減少了計算量。
確定最終 token:主模型通過計算,確定在候選集中哪個 token 是最符合當前文本上下文的下一個生成詞元。如果引導模型的預測準確,主模型驗證后選擇的 token 與引導模型預測概率最高的 token 一致,就直接采用該 token 作為生成結果;若主模型驗證后認為引導模型的預測均不準確,則按照常規方式,對整個詞匯表進行計算,確定正確的下一個 token。
Ⅴ、生成輸出與循環
輸出當前 token:將確定的下一個 token 輸出,作為文本生成的一部分。這個 token 可能會被添加到已生成的文本序列中,形成新的上下文。
循環進行下一輪預測:以新的文本序列作為輸入,重復上述步驟,繼續生成下一個 token,直到滿足預設的生成結束條件,如達到指定的文本長度、生成特定的結束標志 token 等。通過這樣的循環過程,逐步生成完整的文本。


](http://pic.xiahunao.cn/算法刷題記錄——LeetCode篇(2.2) [第111~120題](持續更新))












-E卷-200分)



