目錄
前言
一,Redis架構
1.1 本地緩存
1.2 遠程緩存
二,強大的Redis優點
2.1 支持多種數據類型
2.2 內存過期策略
2.3 內存淘汰策略
2.4 持久化
三,Redis是什么
前言
我是一個程序員,維護了一個商品服務,它的背后直連Mysql數據庫,假設商品服務對外每秒需要提供1萬次查詢,但背后的mysql每秒只能提供每秒5K次的查詢,那mysql肯定頂不住,分分鐘壓垮,這種大流量場景很常見,比如雙十一購物,春節搶車票.

那么問題來了?有沒有什么辦法在Mysql不被壓垮的同時,讓商品服務支持每秒!萬次的查詢?當然有!沒有什么是加一層中間層不能解決的,如果有,那就再加一層,這次我們要加的中間層就是Redis.

一,Redis架構
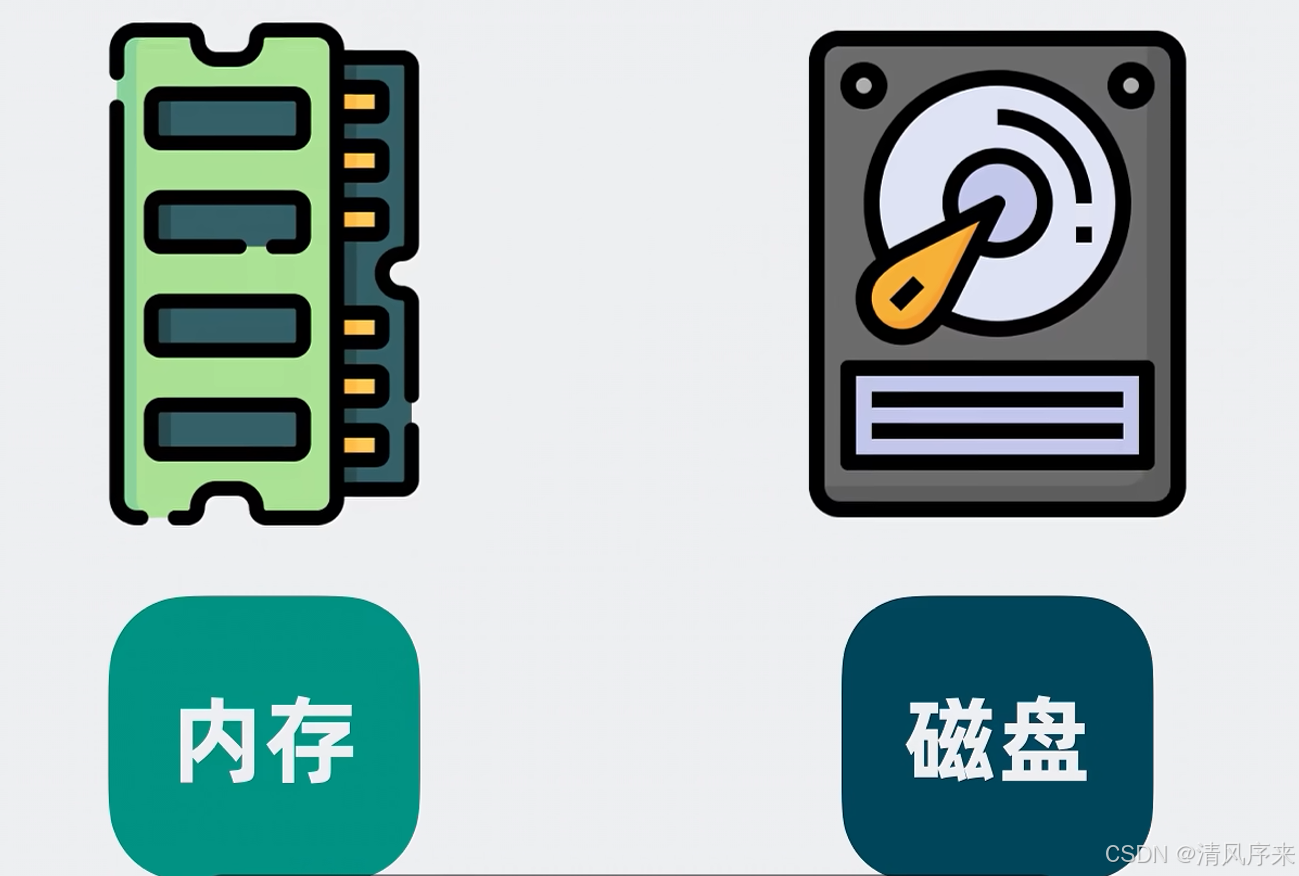
我們知道查詢內存的速度要比查詢磁盤要快,Mysql的數據主要存放在磁盤里,如果能將Mysql的數據放在內存里,完全不走磁盤,那必然能大大提升查詢性能
1.1 本地緩存
對于上面的問題,我們很容易想到,在我們商品服務中申請一個內存字典,python中就是dict,java中就是map,其中Key是商品ID,value是商品數據,通過商品ID就能查到商品數據
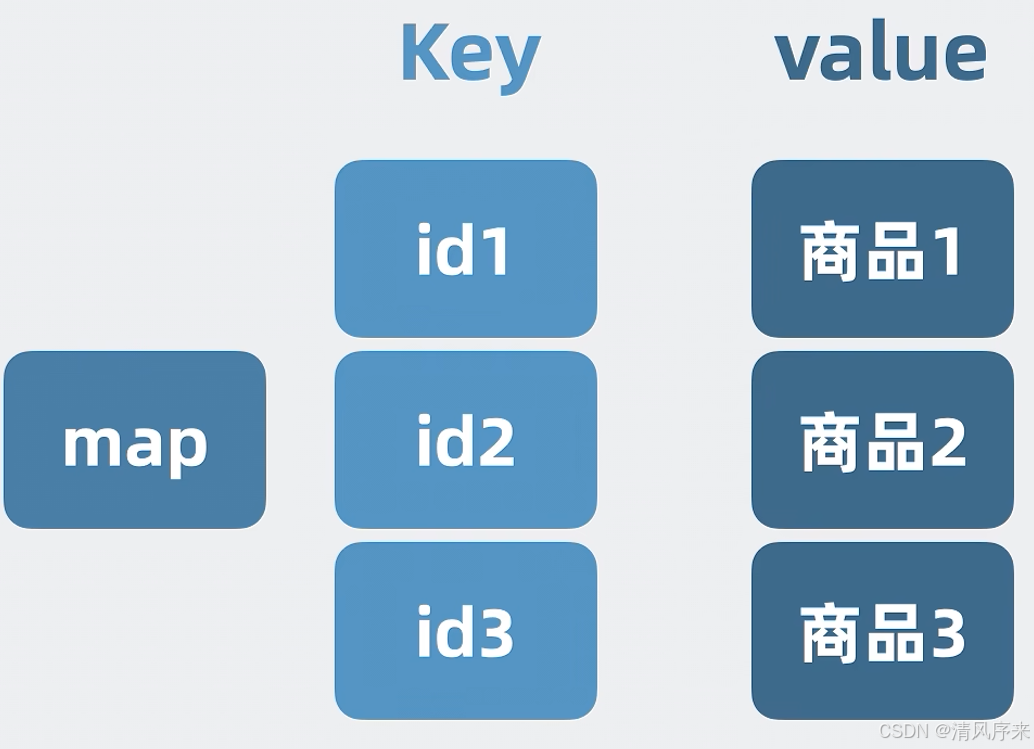
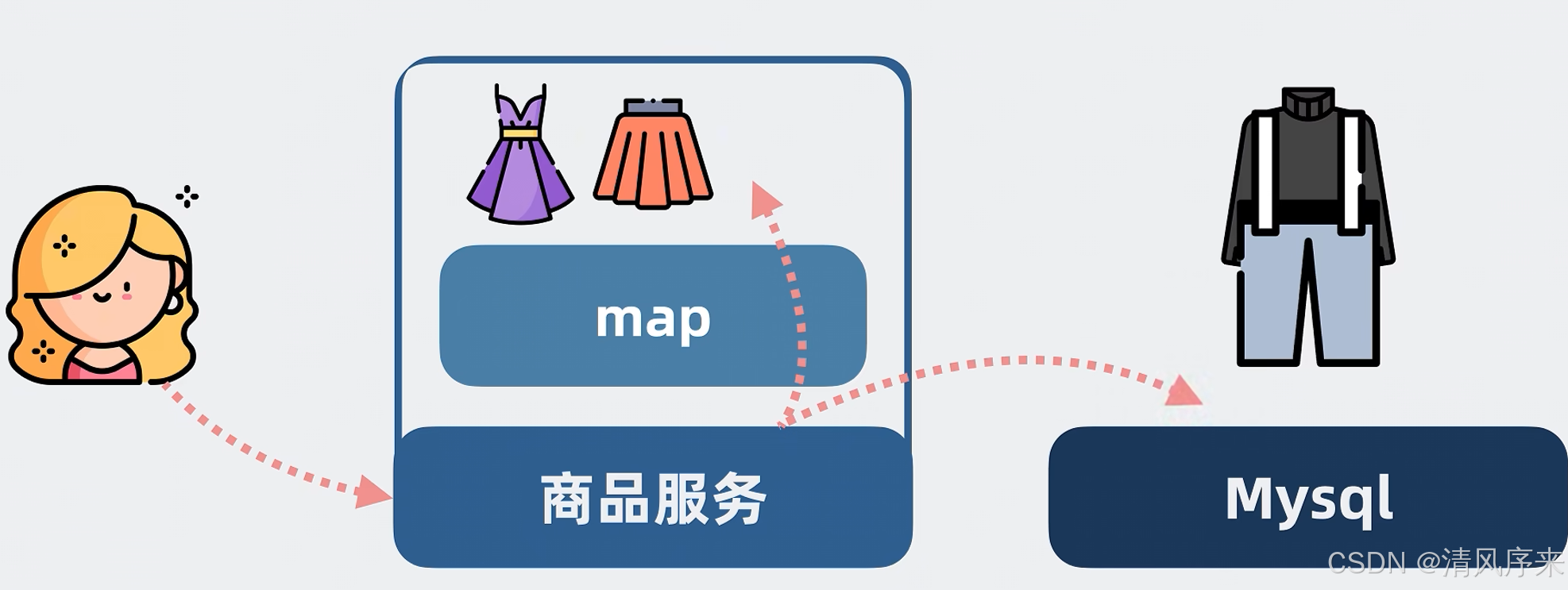
當我們發生查詢時,優先去查詢內存字典,沒有結果再跑到Mysql的數據庫里查詢,并將查詢到的結果放在我們的數據字典里面,并返回給用戶,這樣下次就能從內存里面查出來啦,像這種在服務內存放數據的內存,就是所謂的本地緩存,有了本地緩存的加持,真正打到Mysql的查詢就會少很多
1.2 遠程緩存
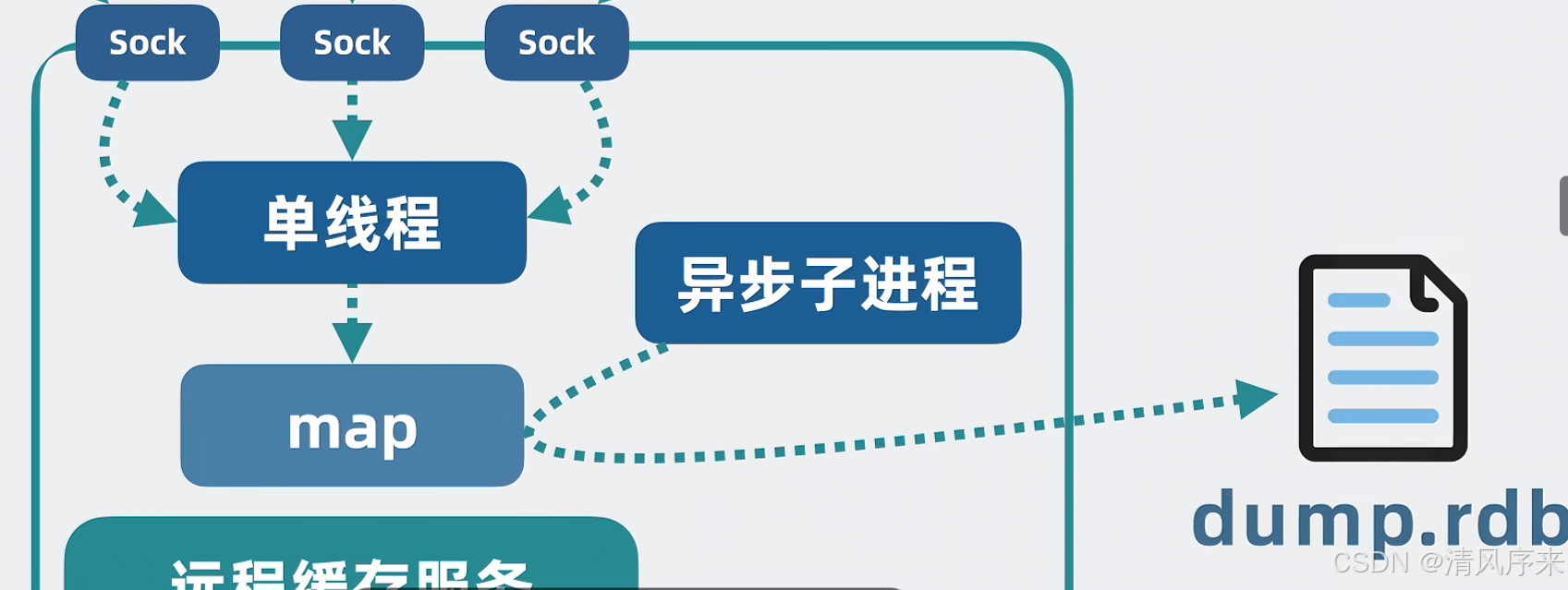
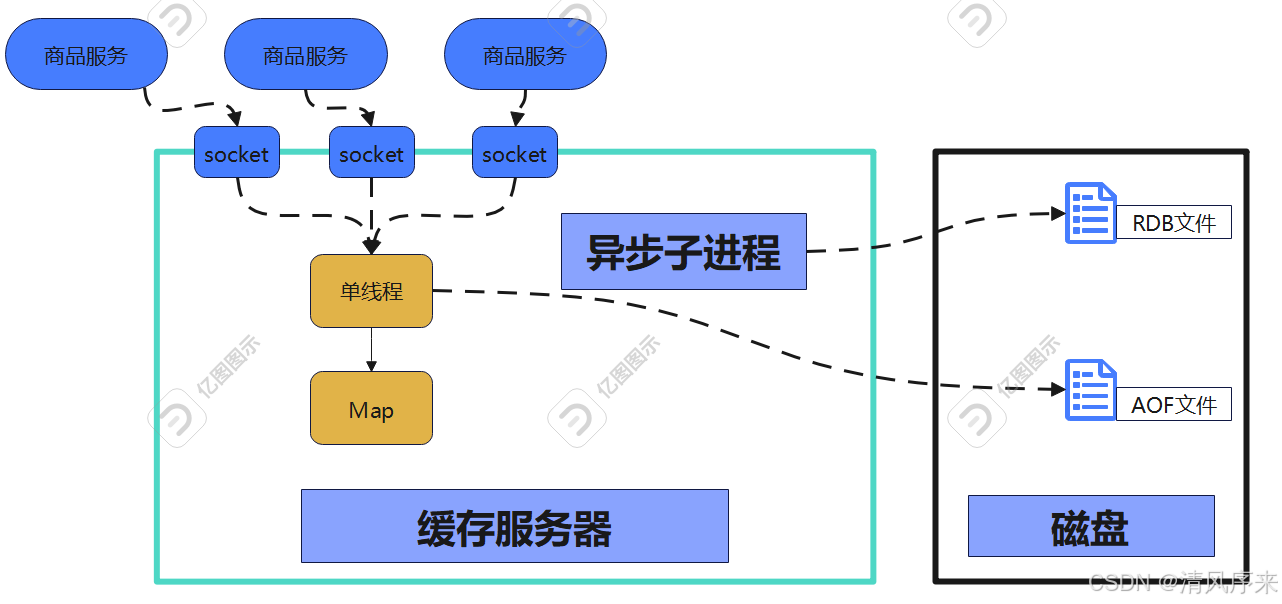
為了保證服務高可用,商品服務經常不止一個實例,如果每個實例都重復緩存一份本地內存,那就有些浪費內存條,所以更好的解決方案就是,將這部分字典內存抽出來,單獨做一個服務,他就是遠程緩存服務.
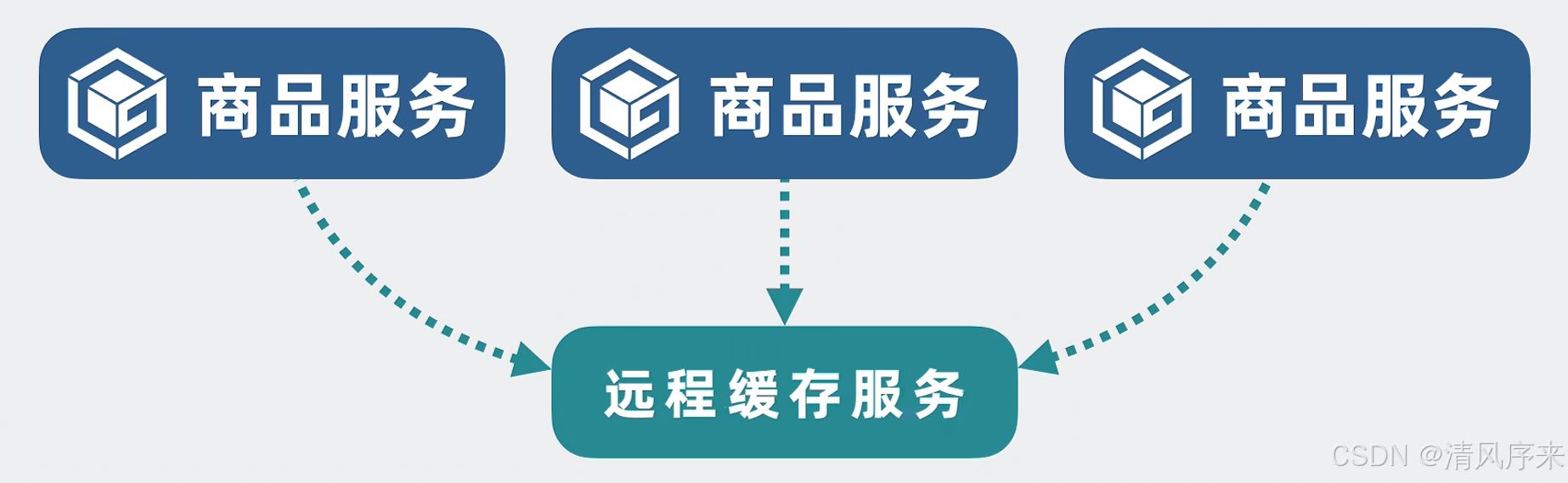
但問題又來了,多個商品服務,去讀寫同一分遠程緩存,會存在并發問題,那怎么辦?很簡單,對外我們不管有多少個網絡連接,收到讀寫命令后,都統一塞到一個線程上,再一個線程上對字典進行讀寫,這樣什么并發問題,線程切換開銷,完全不存在
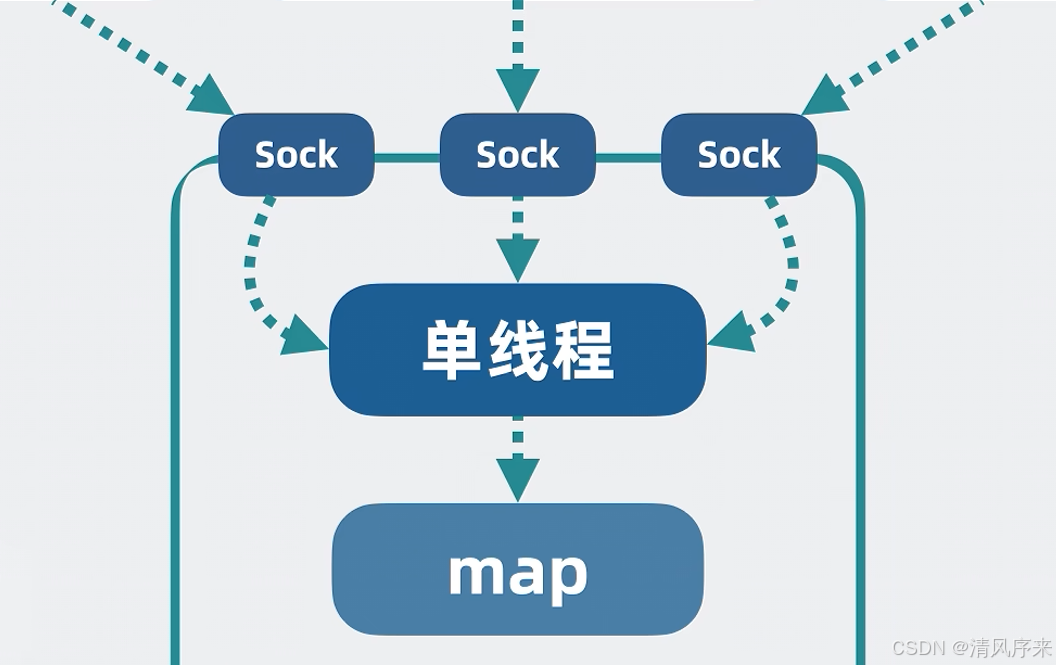
這個遠程緩存服務足以滿足大部分場景,但是他過于簡陋,下來我們看如何優化它!!!
二,強大的Redis優點
2.1 支持多種數據類型
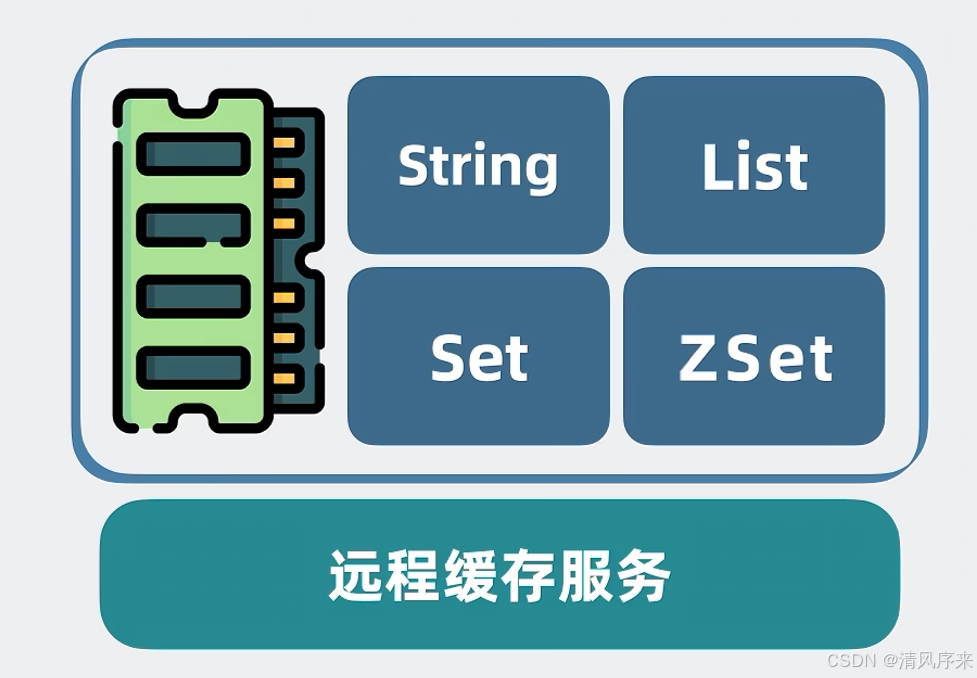
如上面所說的遠程緩存服務里只有一個字典類型,key和value都是字符串,但是我們平時寫代碼的時候還會用到其他內存里的數據結構,例如python的list,set,因此在Redis中對value進行了擴展
? ? ? ? 1,支持先進先出的隊列List
? ? ? ? 2,支持去重的Set
? ? ? ? 3,支持排序的ZSet
這樣緩存服務就更強了
2.2 內存過期策略
當我們的緩存服務支持的數據結構類型變多了之后,塞到內存里的數據就會越來越多,內存又小又貴,那該怎么辦呢?
我們可以給緩存里的數據加一個過期時間,一旦數據過期就從內存里刪掉,可以很大程度上延緩內存增長速度,那么那些數據該設置多長時間過期?這個就交給用戶方去做判斷,讓用戶通過EXPIRED命令來指定那些數據多久過期
2.3 內存淘汰策略
但如果大家都不設置過期時間,內存還是會爆炸!這該如何解決?就是在內存接近上限的時候,根據一些策略刪除一些內存,比如可以將最近最少使用的內存刪掉,這樣不僅解決了內存問題,還能讓緩存里面的數據都是熱點數據,一箭雙雕
2.4 持久化
MySql之所以過得這么舒服,那是因為前面有個緩存服務擋住了大部分流量,一旦緩存服務重啟,那內存數據就丟了,這時候流量就會全部打到Mysql身上,這時候Mysql又就原地爆炸了.
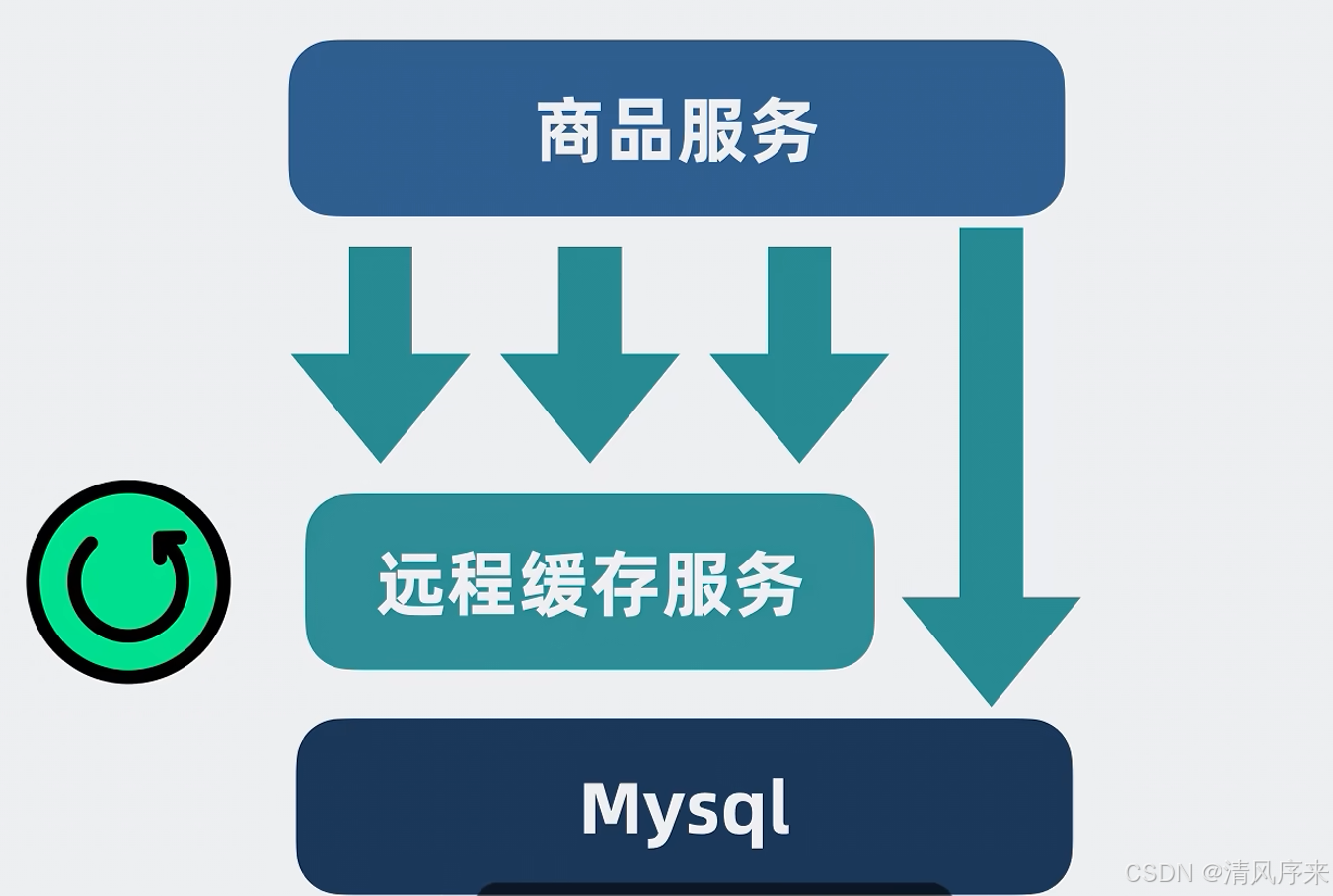
因此我們還需要給內存服務加入最大程度的持久化保證,確保服務重啟后什么數據都沒有,于是可以在緩存服務里面加一個異步子進程,定期將全量內存數據持久化到磁盤文件里,當重啟服務的時候就會加載之前的內存數據
三,Redis是什么
上面我們說了這么多,再回頭來看看Redis到底是什么?我們從開始的一個簡陋的緩存服務慢慢就變成了一個高性能,高可用,支持多種數據類型,支持各種緩存淘汰策略,并提供一定持久化能力的超強緩存服務,這就是我們常說的Redis







)








,源碼可白嫖!)


