目錄
1. AdaBoost 的核心思想
2. AdaBoost 的關鍵步驟
步驟 1:初始化樣本權重
步驟 2:迭代訓練弱分類器
步驟 3:組合弱分類器
3. 用例子詳解 AdaBoost
數據集:
迭代過程:
第1輪(t=1):
第2輪(t=2):
第3輪(t=3):
最終強分類器:
4. AdaBoost 的優缺點
優點:
缺點:
5. Python 實現(基于 Scikit-learn)
6. 總結
1. AdaBoost 的核心思想
一句話總結:
“知錯能改,逐步提升”
AdaBoost 是一種串行集成學習算法,通過迭代訓練多個弱分類器(如決策樹樁),每次重點關注前一個分類器分錯的樣本,最終將所有弱分類器組合成一個強分類器。
2. AdaBoost 的關鍵步驟
步驟 1:初始化樣本權重
- 初始權重:每個樣本的權重相同,總和為1。
例如:如果有10個樣本,初始權重均為0.1。
步驟 2:迭代訓練弱分類器
在每次迭代中:
- 訓練弱分類器:基于當前權重分布,找到一個分類誤差最小的弱分類器(如決策樹樁)。
- 計算分類誤差率:
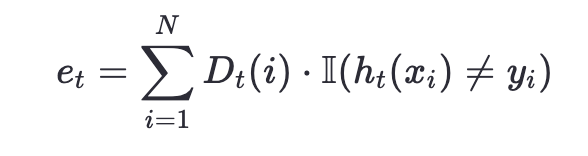
其中 (D_t(i)) 是第 (t) 輪樣本 (i) 的權重,II 是指示函數(分類錯誤時為1)。 - 計算弱分類器的權重:
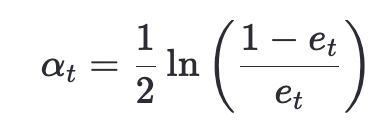
誤差率越低的分類器,權重 αt 越大。 - 更新樣本權重:
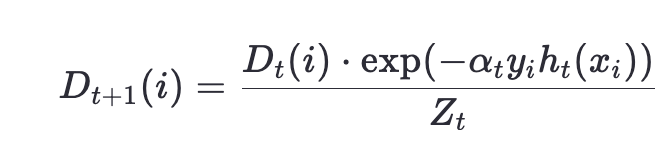
-
- 分類錯誤的樣本權重會被放大,分類正確的權重會被縮小。
- (Z_t) 是歸一化因子,確保權重總和為1。
步驟 3:組合弱分類器
最終強分類器為:
?
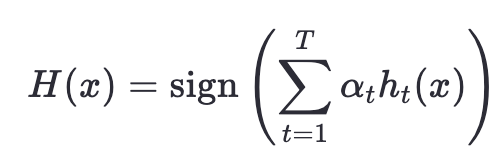
即所有弱分類器的加權投票結果。
3. 用例子詳解 AdaBoost
數據集:
| 序號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | +1 | +1 | +1 | -1 | -1 | -1 | +1 | +1 | +1 | -1 |
目標:通過 AdaBoost 組合多個決策樹樁(僅分裂一次的決策樹)。
迭代過程:
第1輪(t=1):
- 初始權重:所有樣本權重均為
0.1。 - 訓練弱分類器:選擇分裂點
x ≤ 2.5,將數據分為兩類:
-
- 左側(x ≤ 2.5)預測為
+1,右側預測為-1。
- 左側(x ≤ 2.5)預測為
- 計算誤差率:
-
- 分錯的樣本是序號7、8、9(真實標簽為
+1,但被預測為-1),誤差率: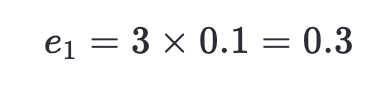
- 分錯的樣本是序號7、8、9(真實標簽為
- 計算分類器權重:
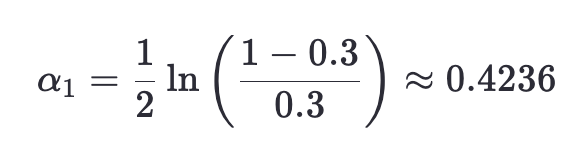
- 更新權重:
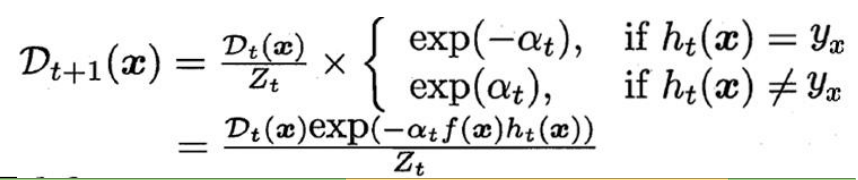
- 分錯的樣本權重放大,分對的縮小。新權重分布 (D_2) 如下:
| 序號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| D2 | 0.071 | 0.071 | 0.071 | 0.071 | 0.071 | 0.071 | 0.167 | 0.167 | 0.167 | 0.071 |
第2輪(t=2):
- 訓練弱分類器:選擇分裂點
x ≤ 8.5,將數據分為兩類:
-
- 左側(x ≤ 8.5)預測為
+1,右側預測為-1。
- 左側(x ≤ 8.5)預測為
- 計算誤差率:
-
- 分錯的樣本是序號4、5、6(真實標簽為
-1,但被預測為+1),誤差率:
- 分錯的樣本是序號4、5、6(真實標簽為
- 計算分類器權重:
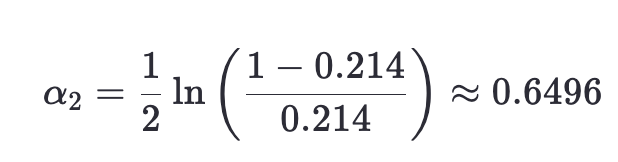
- 更新權重:
| 序號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| D3 | 0.045 | 0.045 | 0.045 | 0.167 | 0.167 | 0.167 | 0.106 | 0.106 | 0.106 | 0.045 |
-
- 分錯的樣本權重放大,新權重分布 (D_3) 如下:
第3輪(t=3):
- 訓練弱分類器:選擇分裂點
x > 5.5,將數據分為兩類:
-
- 右側(x > 5.5)預測為
+1,左側預測為-1。
- 右側(x > 5.5)預測為
- 計算誤差率:
-
- 分錯的樣本是序號10(真實標簽為
-1,但被預測為+1),誤差率:
- 分錯的樣本是序號10(真實標簽為
- 計算分類器權重:
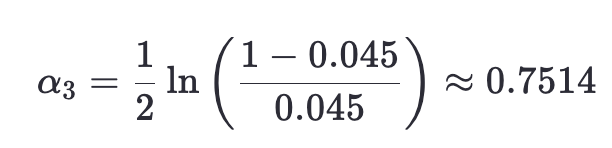
- 更新權重:
-
- 最終所有樣本被正確分類,訓練結束。
最終強分類器:
![]()
通過加權投票,最終分類器可以正確分類所有樣本。
4. AdaBoost 的優缺點
優點:
- 高精度:通過逐步優化,最終模型的泛化能力很強。
- 自動關注難樣本:分錯的樣本會被賦予更高權重,后續模型重點學習。
- 簡單高效:基分類器通常為決策樹樁,計算速度快。
缺點:
- 對噪聲敏感:異常值可能被過度關注,導致過擬合。
- 需調整參數:如迭代次數(
n_estimators)和學習率(learning_rate)。
5. Python 實現(基于 Scikit-learn)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split# 生成模擬數據
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# AdaBoost 模型(使用決策樹樁作為基分類器)
model = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=1), # 弱分類器n_estimators=50, # 迭代次數learning_rate=1.0, # 學習率(控制每個分類器的權重縮放)random_state=42
)# 訓練與預測
model.fit(X_train, y_train)
print("測試集準確率:", model.score(X_test, y_test))6. 總結
- 核心思想:通過迭代調整樣本權重,讓模型逐步關注難分類的樣本。
- 關鍵公式:誤差率 (e_t)、分類器權重 (\alpha_t)、權重更新公式。
- 應用場景:分類問題(如文本分類、圖像識別),尤其適合數據分布不均衡的情況。

7. 通俗比喻:班級考試
- 第1次考試 :所有學生權重相同,老師根據錯誤重點講解。
- 第2次考試 :之前錯題權重增加,學生更關注這些題。
- 最終成績 :多次考試成績加權平均,最終得分更準確。

,源碼可白嫖!)



](http://pic.xiahunao.cn/第二期:深入理解 Spring Web MVC [特殊字符](核心注解 + 進階開發))

)









教程)

