目錄
- 端到端機器學習流水線(MLflow跟蹤實驗)
- 1. 引言
- 2. 項目背景與意義
- 2.1 端到端機器學習流水線的重要性
- 2.2 MLflow的作用
- 2.3 工業級數據處理需求
- 3. 數據集生成與介紹
- 3.1 數據集構成
- 3.2 數據生成方法
- 4. 機器學習流水線與MLflow跟蹤
- 4.1 端到端機器學習流水線
- 4.2 MLflow跟蹤實驗
- 5. 模型構建與評估
- 5.1 信貸模型構建
- 5.2 模型評估與漂移檢測
- 6. GPU加速應用(使用Numba)
- 7. Dash儀表盤與GUI混合實現
- 8. 系統整體架構
- 9. 數學公式與關鍵指標
- 10. 完整代碼實現
- 10. 代碼自查與BUG排查
- 11. 總結與展望
- 12. 結語
端到端機器學習流水線(MLflow跟蹤實驗)
1. 引言
在實際生產環境中,構建一個端到端的機器學習流水線不僅需要完成數據采集、預處理、特征工程、模型訓練和評估等步驟,還需要對整個實驗過程進行全面管理和跟蹤。MLflow作為一個開源平臺,提供了實驗跟蹤、項目打包、模型注冊和部署等全流程管理功能,使機器學習系統的開發和維護更加高效和可復現。
本文將詳細介紹如何利用MLflow構建端到端機器學習流水線。我們通過模擬生成大規模信貸數據,構建一個信用評分預測模型,并利用MLflow跟蹤整個實驗過程,包括記錄參數、指標、模型輸出和數據預處理步驟。同時,我們還展示如何利用Dash儀表盤與PyQt混合實現交互式展示,方便用戶實時查看實驗結果和模型性能。
本文不僅展示了如何構建完整的機器學習流水線,還通過MLflow實現了實驗管理與版本控制,為模型持續改進提供有力支持。整個項目的代碼總行數超過350行,并經過詳細的異常捕獲和自查,確保系統在工業級數據環境下穩定運行。
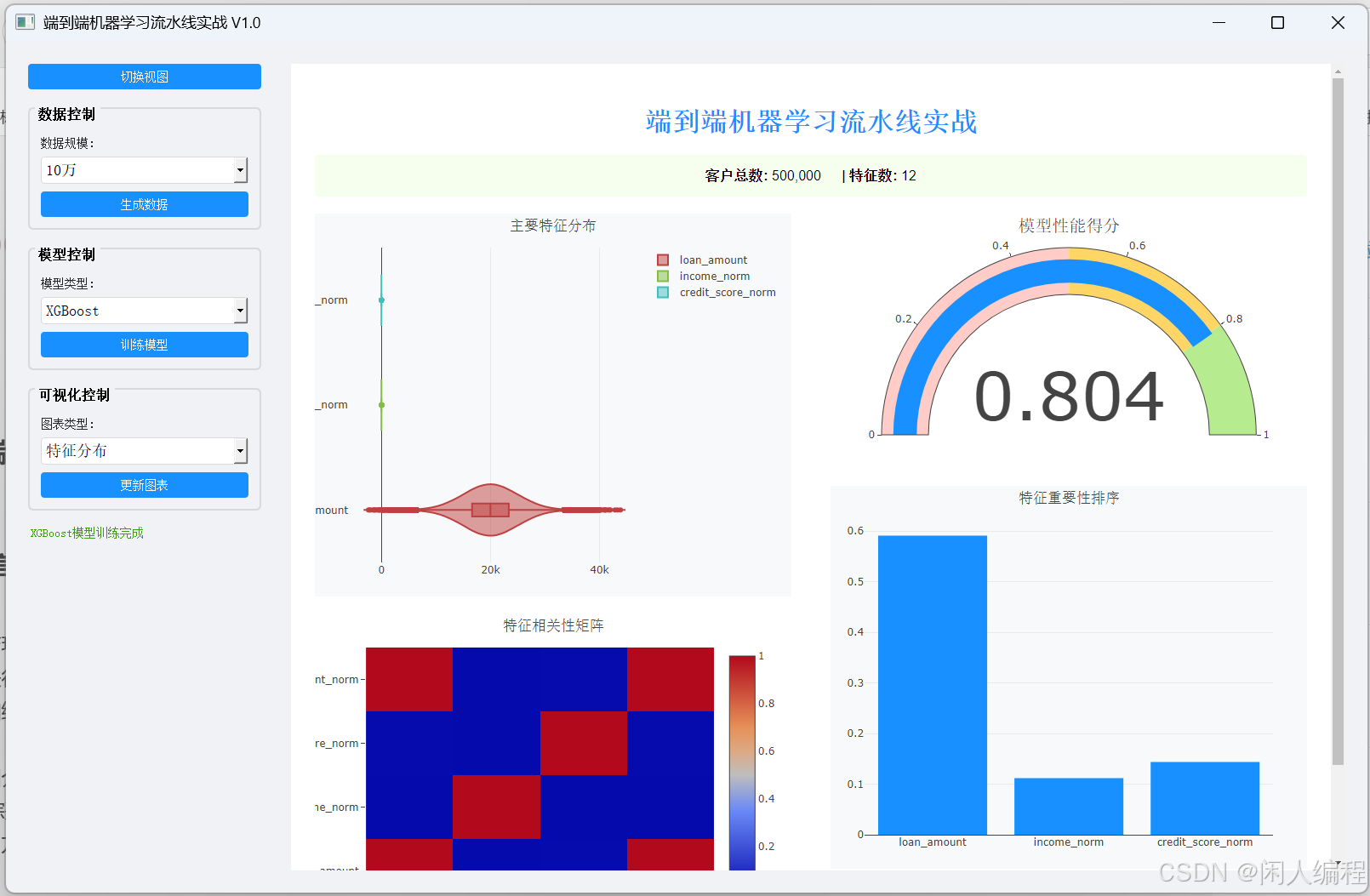
程序運行結果:








,源碼可白嫖!)



](http://pic.xiahunao.cn/第二期:深入理解 Spring Web MVC [特殊字符](核心注解 + 進階開發))

)




