?一、環境搭建
1.1 安裝paddle-gpu
需要根據安裝機器的cuda的版本,選擇合適的版本進行安裝
#安裝paddle-gpu 官網鏈接 https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/linux-pip.html
python -m pip install paddlepaddle-gpu==2.6.2.post120 -i https://www.paddlepaddle.org.cn/packages/stable/cu120/python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
或者:conda install paddlepaddle-gpu==3.0.0rc1 paddlepaddle-cuda=12.3 -c paddle -c nvidia
#驗證
安裝完成后您可以使用 python3 進入 python 解釋器,輸入import paddle ,再輸入 paddle.utils.run_check()
如果出現PaddlePaddle is installed successfully!,說明您已成功安裝。
查看paddleocr的版本使用的命令為:python -c "import paddle; print(paddle.__version__)"1.2 安裝paddlex
飛槳低代碼開發工具PaddleX,提供了兩種安裝模式:Wheel包安裝和插件安裝(插件安裝適合二次開發),具體的安裝方法可以參考以下鏈接。
安裝PaddleX - PaddleX 文檔
?我使用的是wheel安裝,因為只是為了快速的驗證檢測效果。
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0rc0-py3-none-any.whl?執行中遇到的問題:Can not import paddle core libstdc++.so.6: version `GLIBCXX_3.4.30' not found
解決方法:
最好的方法是conda虛擬環境安裝gcc,conda install -c conda-forge gcc=12.1.0
二、PaddleX概述
完整的PaddleX模型產線開發流程如下圖所示:

PaddleX 所提供的預訓練的模型產線均可以快速體驗效果,如果產線效果可以達到您的要求,您可以直接將預訓練的模型產線進行開發集成/部署,如果效果不及預期,可以使用私有數據對產線中的模型進行微調,直到達到滿意的效果。
PaddleX中每條產線都可以解決特定任務場景的問題如目標檢測、時序預測、語義分割等,您需要根據具體任務選擇后續進行開發的產線。例如此處為登機牌識別任務,對應 PaddleX 的通用OCR產線。更多任務與產線的對應關系可以在?PaddleX產線列表(CPU/GPU)查詢。
三、OCR產線
3.1 通用ocr產線
通用OCR產線 - PaddleX 文檔
OCR(光學字符識別,Optical Character Recognition)是一種將圖像中的文字轉換為可編輯文本的技術。它廣泛應用于文檔數字化、信息提取和數據處理等領域。OCR 可以識別印刷文本、手寫文本,甚至某些類型的字體和符號。
通用 OCR 產線用于解決文字識別任務,提取圖片中的文字信息以文本形式輸出,本產線集成了業界知名的 PP-OCRv3 和 PP-OCRv4 的端到端 OCR 串聯系統,支持超過 80 種語言的識別,并在此基礎上,增加了對圖像的方向矯正和扭曲矯正功能。基于本產線,可實現 CPU 上毫秒級的文本內容精準預測,使用場景覆蓋通用、制造、金融、交通等各個領域。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
通用OCR產線中包含必選的文本檢測模塊和文本識別模塊,以及可選的文檔圖像方向分類模塊、文本圖像矯正模塊和文本行方向分類模塊。
不想搭建環境,可快速的用以下的鏈接,進行在線驗證。
大模型社區-飛槳星河AI Studio大模型社區
環境搭建的方法可以參考上一個博文。
使用命令實現圖像的文本檢測:
paddlex --pipeline OCR \--input general_ocr_002.png \--use_doc_orientation_classify False \--use_doc_unwarping False \--use_textline_orientation False \--save_path ./output \--device gpu:0使用腳本實現的方法:
from paddlex import create_pipelinepipeline = create_pipeline(pipeline="OCR")output = pipeline.predict(input="./general_ocr_002.png",use_doc_orientation_classify=False,use_doc_unwarping=False,use_textline_orientation=False,
)
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/")
?3.2 通用表格識別
通用表格識別v2產線 - PaddleX 文檔
表格識別是一種自動從文檔或圖像中識別和提取表格內容及其結構的技術,廣泛應用于數據錄入、信息檢索和文檔分析等領域。通過使用計算機視覺和機器學習算法,表格識別能夠將復雜的表格信息轉換為可編輯的格式,方便用戶進一步處理和分析數據。
通用表格識別產線用于解決表格識別任務,對圖片中的表格進行識別,并以HTML格式輸出。本產線集成了業界知名的 SLANet 和 SLANet_plus 表格結構識別模型。基于本產線,可實現對表格的精準預測,使用場景覆蓋通用、制造、金融、交通等各個領域。
可以使用下面的鏈接進行快速的驗證。
大模型社區-飛槳星河AI Studio大模型社區

四、計算機視覺
4.1 開放詞匯檢測
開放詞匯檢測 - PaddleX 文檔
開放詞匯目標檢測是當前一種先進的目標檢測技術,旨在突破傳統目標檢測的局限性。傳統方法僅能識別預定義類別的物體,而開放詞匯目標檢測允許模型識別未在訓練中出現的物體。通過結合自然語言處理技術,利用文本描述來定義新的類別,模型能夠識別和定位這些新物體。這使得目標檢測更具靈活性和泛化能力,具有重要的應用前景。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。本產線目前不支持對模型的二次開發,計劃在后續支持。目前查看公開的模型的精度并不是很高。

測試命令及腳本:
paddlex --pipeline open_vocabulary_detection \--input open_vocabulary_detection.jpg \--prompt "bus . walking man . rearview mirror ." \--thresholds "{'text_threshold': 0.25, 'box_threshold': 0.3}" \--save_path ./output \--device gpu:0from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="open_vocabulary_detection")
output = pipeline.predict(input="open_vocabulary_detection.jpg", prompt="bus . walking man . rearview mirror .")
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/")?功能說明:在命令及腳本中,給出了要求檢測的目標為車,后視鏡,行走的人,執行后的結果如下圖所示:

4.2?開放詞匯分割
開放詞匯分割 - PaddleX 文檔
開放詞匯分割是一項圖像分割任務,旨在根據文本描述、邊框、關鍵點等除圖像以外的信息作為提示,分割圖像中對應的物體。它允許模型處理廣泛的對象類別,而無需預定義的類別列表。這項技術結合了視覺和多模態技術,極大地提高了圖像處理的靈活性和精度。開放詞匯分割在計算機視覺領域具有重要應用價值,尤其在復雜場景下的對象分割任務中表現突出。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。本產線目前不支持對模型的二次開發,計劃在后續支持。
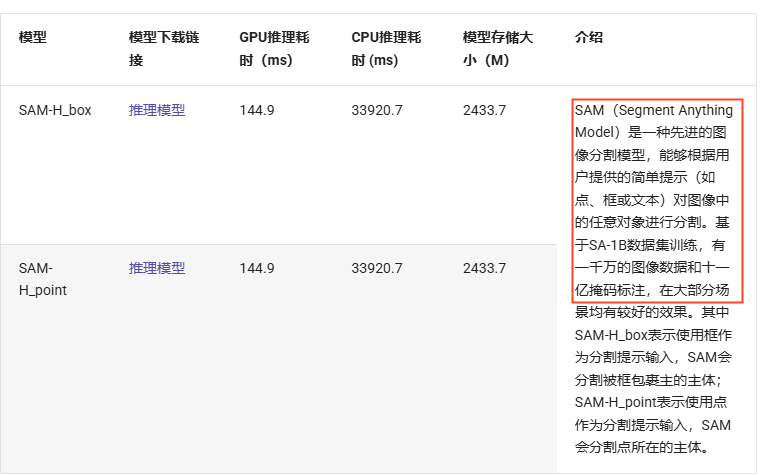
測試命令及腳本:
paddlex --pipeline open_vocabulary_segmentation \--input open_vocabulary_segmentation.jpg \--prompt_type box \--prompt "[[112.9,118.4,513.8,382.1],[4.6,263.6,92.2,336.6],[592.4,260.9,607.2,294.2]]" \--save_path ./output \--device gpu:0from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="open_vocabulary_segmentation")
output = pipeline.predict(input="open_vocabulary_segmentation.jpg", prompt_type="box", prompt=[[112.9,118.4,513.8,382.1],[4.6,263.6,92.2,336.6],[592.4,260.9,607.2,294.2]])
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/")測試原圖及結果如下:


4.3 旋轉目標檢測
旋轉目標檢測 - PaddleX 文檔
旋轉目標檢測是目標檢測模塊中的一種衍生,它專門針對旋轉目標進行檢測。旋轉框(Rotated Bounding Boxes)常用于檢測帶有角度信息的矩形框,即矩形框的寬和高不再與圖像坐標軸平行。相較于水平矩形框,旋轉矩形框一般包括更少的背景信息。旋轉目標檢測在遙感等場景中有重要的應用。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
測試命令及腳本:
paddlex --pipeline rotated_object_detection \--input rotated_object_detection_001.png \--threshold 0.5 \--save_path ./output \--device gpu:0 \from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="rotated_object_detection")
output = pipeline.predict(input="rotated_object_detection_001.png", threshold=0.5)
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/")

4.4?行人屬性識別
行人屬性識別 - PaddleX 文檔
行人屬性識別是計算機視覺系統中的關鍵功能,用于在圖像或視頻中定位并標記行人的特定特征,如性別、年齡、衣物顏色和款式等。該任務不僅要求準確檢測出行人,還需識別每個行人的詳細屬性信息。行人屬性識別產線是定位并識別行人屬性的端到端串聯系統,廣泛應用于智慧城市和安防監控等領域,可顯著提升系統的智能化水平和管理效率。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
paddlex --pipeline pedestrian_attribute_recognition --input pedestrian_attribute_002.jpg --device gpu:0 --save_path ./output/from paddlex import create_pipelinepipeline = create_pipeline(pipeline="pedestrian_attribute_recognition")output = pipeline.predict("pedestrian_attribute_002.jpg")
for res in output:res.print() ## 打印預測的結構化輸出res.save_to_img("./output/") ## 保存結果可視化圖像res.save_to_json("./output/") ## 保存預測的結構化輸出
4.5 車輛屬性識別
車輛屬性識別 - PaddleX 文檔
車輛屬性識別是計算機視覺系統中的重要組成部分,其主要任務是在圖像或視頻中定位并標記出車輛的特定屬性,如車輛類型、顏色、車牌號等。該任務不僅要求準確檢測出車輛,還需識別每輛車的詳細屬性信息。車輛屬性識別產線是定位并識別車輛屬性的端到端串聯系統,廣泛應用于交通管理、智能停車、安防監控、自動駕駛等領域,顯著提升了系統效率和智能化水平,并推動了相關行業的發展與創新。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成
paddlex --pipeline vehicle_attribute_recognition --input vehicle_attribute_002.jpg --device gpu:0 --save_path ./output/from paddlex import create_pipelinepipeline = create_pipeline(pipeline="vehicle_attribute_recognition")output = pipeline.predict("vehicle_attribute_002.jpg")
for res in output:res.print() ## 打印預測的結構化輸出res.save_to_img("./output/") ## 保存結果可視化圖像res.save_to_json("./output/") ## 保存預測的結構化輸出
4.6??人臉識別
人臉識別 - PaddleX 文檔
人臉識別任務是計算機視覺領域的重要組成部分,旨在通過分析和比較人臉特征,實現對個人身份的自動識別。該任務不僅需要檢測圖像中的人臉,還需要對人臉圖像進行特征提取和匹配,從而在數據庫中找到對應的身份信息。人臉識別廣泛應用于安全認證、監控系統、社交媒體和智能設備等場景。使用的前提需要構建人臉特征庫,才能進行人臉識別。
4.7 圖像異常檢測
圖像異常檢測 - PaddleX 文檔
圖像異常檢測是一種通過分析圖像中的內容,來識別與眾不同或不符合正常模式的圖像處理技術。圖像異常檢測能夠自動識別出圖像中潛在的缺陷、異常或異常行為,從而幫助我們及時發現問題并采取相應措施。
本產線集成了高精度的異常檢測模型 STFPM,提取圖像中的異常或缺陷區域,使用場景覆蓋工業制造、食品外觀質檢以及醫療影像分析等各個領域。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。


paddlex --pipeline anomaly_detection --input uad_grid.png --device gpu:0 --save_path ./outputfrom paddlex import create_pipelinepipeline = create_pipeline(pipeline="anomaly_detection")
output = pipeline.predict(input="uad_grid.png")
for res in output:res.print() ## 打印預測的結構化輸出res.save_to_img(save_path="./output/") ## 保存結果可視化圖像res.save_to_json(save_path="./output/") ## 保存預測的結構化輸出4.8??小目標檢測
小目標檢測 - PaddleX 文檔
小目標檢測是一種專門識別圖像中體積較小物體的技術,廣泛應用于監控、無人駕駛和衛星圖像分析等領域。它能夠從復雜場景中準確找到并分類像行人、交通標志或小動物等小尺寸物體。通過使用深度學習算法和優化的卷積神經網絡,小目標檢測可以有效提升對小物體的識別能力,確保在實際應用中不遺漏重要信息。這項技術在提高安全性和自動化水平方面發揮著重要作用。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
paddlex --pipeline small_object_detection \--input small_object_detection.jpg \--threshold 0.5 \--save_path ./output \--device gpu:0from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="small_object_detection")
output = pipeline.predict(input="small_object_detection.jpg", threshold=0.5)
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/")
4.9??通用圖像多標簽分類
圖像多標簽分類 - PaddleX 文檔
圖像多標簽分類是一種將一張圖像同時分配到多個相關類別的技術,廣泛應用于圖像標注、內容推薦和社交媒體分析等領域。它能夠識別圖像中存在的多個物體或特征,例如一張圖片中同時包含“狗”和“戶外”這兩個標簽。通過使用深度學習模型,圖像多標簽分類能夠自動提取圖像特征并進行準確分類,以便為用戶提供更加全面的信息。這項技術在智能搜索引擎和自動內容生成等應用中具有重要意義。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
paddlex --pipeline image_multilabel_classification --input general_image_classification_001.jpg --device gpu:0from paddlex import create_pipelinepipeline = create_pipeline(pipeline="image_multilabel_classification")output = pipeline.predict("general_image_classification_001.jpg")
for res in output:res.print() ## 打印預測的結構化輸出res.save_to_img("./output/") ## 保存結果可視化圖像res.save_to_json("./output/") ## 保存預測的結構化輸出
4.10?通用語義分割
語義分割是一種計算機視覺技術,旨在將圖像中的每個像素分配到特定的類別,從而實現對圖像內容的精細化理解。語義分割不僅要識別出圖像中的物體類型,還要對每個像素進行分類,這樣使得同一類別的區域能夠被完整標記。例如,在一幅街景圖像中,語義分割可以將行人、汽車、天空和道路等不同類別的部分逐像素區分開來,形成一個詳細的標簽圖。通用語義分割產線用于解決像素級別的圖像理解問題,這項技術廣泛應用于自動駕駛、醫學影像分析和人機交互等領域,通常依賴于深度學習模型(如SegFormer等),通過卷積神經網絡(CNN)或視覺變換器(Transformer)來提取特征并實現高精度的像素級分類,從而為進一步的智能分析提供基礎。
paddlex --pipeline semantic_segmentation \--input makassaridn-road_demo.png \--target_size -1 \--save_path ./output \--device gpu:0from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="semantic_segmentation")
output = pipeline.predict(input="makassaridn-road_demo.png", target_size = -1)
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/") ?
?
4.11??通用實例分割
通用實例分割 - PaddleX 文檔
實例分割是一種計算機視覺任務,它不僅要識別圖像中的物體類別,還要區分同一類別中不同實例的像素,從而實現對每個物體的精確分割。實例分割可以在同一圖像中分別標記出每一輛車、每一個人或每一只動物,確保它們在像素級別上被獨立處理。例如,在一幅包含多輛車和行人的街景圖像中,實例分割能夠將每輛車和每個人的輪廓清晰地分開,形成多個獨立的區域標簽。這項技術廣泛應用于自動駕駛、視頻監控和機器人視覺等領域,通常依賴于深度學習模型(如Mask R-CNN等),通過卷積神經網絡來實現高效的像素分類和實例區分,為復雜場景的理解提供了強大的支持。
paddlex --pipeline instance_segmentation \--input general_instance_segmentation_004.png \--threshold 0.5 \--save_path ./output \--device gpu:0from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="instance_segmentation")
output = pipeline.predict(input="general_instance_segmentation_004.png", threshold=0.5)
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/")

五、文本圖像智能分析
文檔場景信息抽取v4(PP-ChatOCRv4)是飛槳特色的文檔和圖像智能分析解決方案,結合了 LLM、MLLM 和 OCR 技術,一站式解決版面分析、生僻字、多頁 pdf、表格、印章識別等常見的復雜文檔信息抽取難點問題,結合文心大模型將海量數據和知識相融合,準確率高且應用廣泛。本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
?文檔場景信息抽取v4產線中包含版面區域檢測模塊、表格結構識別模塊、表格分類模塊、表格單元格定位模塊、文本檢測模塊、文本識別模塊、印章文本檢測模塊、文本圖像矯正模塊、文檔圖像方向分類模塊。其中相關的模型是以子產線的方式集成,您可以通過產線配置來查看不同模塊的模型配置。
該部分的快速體驗,需要個人賬戶獲得密鑰,具體的執行流程可以參看官方網站的鏈接執行:
?文檔場景信息抽取v4產線 - PaddleX 文檔









)









