24年11月來自清華、早稻田大學、明尼蘇達大學、多倫多大學、廈門大學馬來西亞分校、電子科大(成都)、智平方科技和河南潤泰數字科技的論文“FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback”。
確保安全、舒適和高效的導航是自動駕駛系統開發和可靠性的基礎。雖然在大型數據集上訓練的端到端模型在標準駕駛情況下表現良好,但它們往往難以應對罕見的長尾事件。大語言模型 (LLM) 的最新進展帶來改進的推理能力,但它們的高計算需求使自動駕駛汽車的實時決策和精確規劃變得復雜。本文的 FASIONAD,是一個受認知模型“思考,快與慢”啟發的雙-系統框架。快速系統通過快速的數據驅動路徑規劃有效地管理常規導航任務,而慢速系統則處理不熟悉或具有挑戰性的場景中的復雜推理和決策。由分數分布和反饋引導的動態切換機制,允許快速和慢速系統之間的無縫過渡。快速系統的視覺提示,促進慢速系統中類似人類的推理,這反過來又提供高質量的反饋以增強快速系統的決策。為了評估方法,引入一個源自 nuScenes 數據集的新基準,旨在區分快速和慢速場景。FASIONAD 為該基準設定新標準,開創一個區分自動駕駛中快速和慢速認知過程的框架。這種雙-系統方法為創建更具適應性和更像人類的自動駕駛系統提供一個有希望的方向。
自動駕駛有可能通過提高效率、減少人工工作量和最大限度地減少事故來改變交通運輸[26]。傳統的自動駕駛系統通常采用模塊化設計,具有用于感知、預測、規劃[26]和控制的獨立模塊。然而,這些系統在動態和復雜環境中的適應性較差,并且在解決長尾問題和冗余方面面臨挑戰[46, 63],這限制了它們的可擴展性和適用性。
為了解決這些限制,端到端(E2E)學習方法,如模仿學習(IL)[9, 23, 24, 39, 57]和強化學習(RL)[8, 27],已被廣泛探索。然而,模仿學習(IL)方法容易發生協變量漂移,導致在關鍵場景中缺乏魯棒性[32, 42],即使有從錯誤中學習(LfM)[2]等改進。強化學習(RL)方法雖然在模擬中有效,但在實際應用中面臨重大的安全問題并遇到挑戰,特別是由于獎勵設計和模擬-到-現實的遷移困難 [11]。最近的研究如 DriveCoT [55] 和 DriveInsight [28] 旨在提高可解釋性,但通常需要花費大量時間才能在不同場景中有效泛化。
隨著大語言模型 (LLM) 和視覺語言模型 (VLM) 的最新進展,研究人員已開始探索它們在自動駕駛中的應用,包括操控任務 [50]、空間落地 [48] 和技能學習 [49]。然而,盡管取得了這些進展 [45、47、56、58],LLM 和 VLM 仍然面臨空間落地和實時決策方面的挑戰 [60]。平衡安全性和性能仍然是一個關鍵問題 [54],這個限制它們在復雜的現實世界自動駕駛環境中的更廣泛應用。
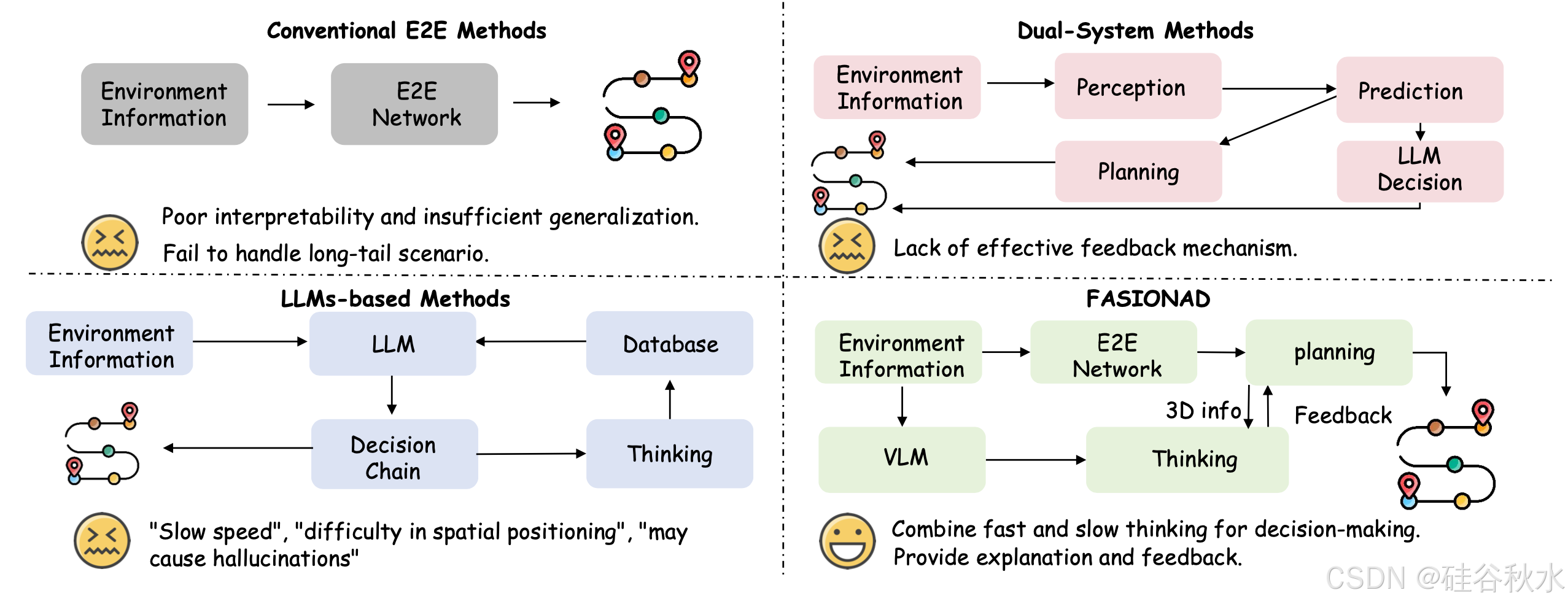
本文提出 FASIONAD,一種自適應反饋框架,無縫集成快速和慢速思維方法。如圖所示 FASIONAD 的動機:傳統的 E2E 方法在可解釋性和泛化方面存在困難,基于 LLM 的方法面臨決策速度慢、空間定位問題和潛在的幻覺。雙-系統流水線 [51] 使用 LLM 來融合規劃,但缺乏安全反饋機制。如圖比較不同的自動駕駛運動規劃方法,展示該方法能夠自適應上下文-覺察決策,提供更好的解釋和反饋。
如圖所示,FASIONAD 框架采用雙-路徑架構:快速路徑用于快速實時響應,慢速路徑用于在不確定或具有挑戰性的駕駛場景中進行全面分析和復雜決策。
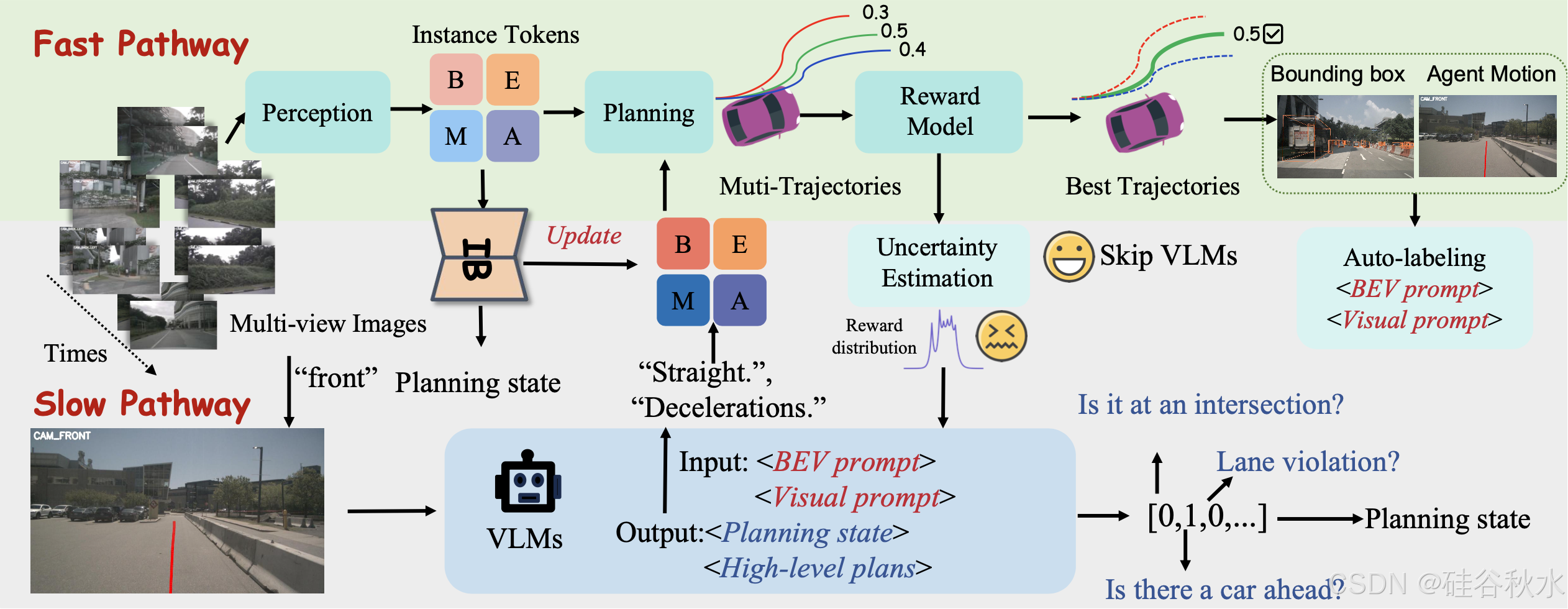
在快速路徑中,給定一組 N 個多視圖圖像 I_t = {I_1t, I_2t, …, I_Nt} 和高級導航命令 C_t,模型會生成一個航路點序列 W_t = {w_1t, w_2t, …, w_Mt},其中每個航路點 w_it = (x_it, y_it) 表示自車在時間 t + i 的預測鳥瞰圖 (BEV) 位置。該路徑可以表示為:
FASIONAD(快速路徑):(I_t, C_t) → W_t (1)
相比之下,慢速路徑僅處理多視圖圖像 I_t 以生成規劃狀態 P_t 和高級元動作 A_t,為復雜場景中的決策提供更詳細的評估和戰略指導。該路徑補充快速路徑,使其能夠在不確定或具有挑戰性的條件下進行更深入的分析。慢速路徑表示為:
FASIONAD(慢速路徑):I_t → (P_t, A_t) (2)
為了協調快速路徑和慢速路徑,引入基于不確定性的航點預測和軌跡獎勵。該機制根據環境背景和復雜性動態,激活任一路徑,優化響應性與準確性,從而在需要時實現即時反應和徹底分析。
快速路徑
快速通道的第一步是處理傳感器輸入,以獲得對周圍環境的高級描述。受人類駕駛員決策過程的啟發,將決策所需的信息分為兩個層次:低級感知信息(觀察到什么?)和高級感知信息(了解觀察元素之間的相互作用)。低級感知信息包括有關交通參與者和地圖特征的詳細信息,而高級感知信息則捕獲這些元素之間的相互作用,如圖所示。
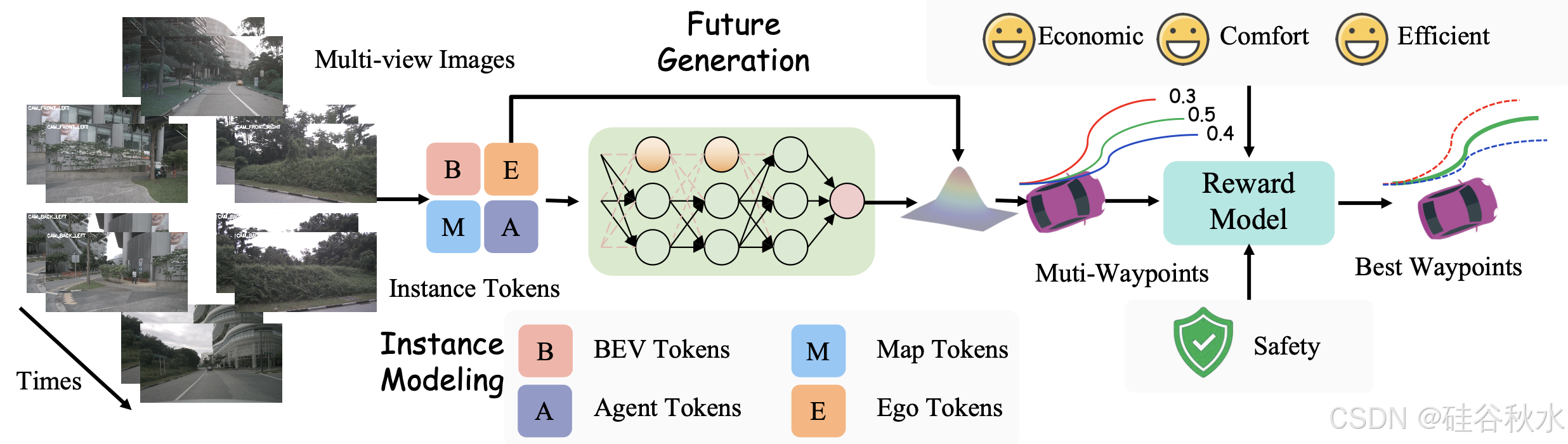
航點預測和獎勵評估
軌跡生成器。軌跡生成器輸出航點預測 W = {w_t},每個航點 w_t = (x_t, y_t) 表示 BEV 坐標中的空間位置。為了捕捉交通參與者之間的互動,采用受 GenAD [61] 啟發的生成框架,將軌跡預測建模為未來軌跡生成問題。
獎勵模型。該模型生成 N_C × N_K 條候選軌跡 T = {T_i},其中每條軌跡 T_i 表示在時間范圍 T_s 內的航點序列。這里,N_C 是導航命令的數量,N_K 表示前 K 個采樣的多模態軌跡。每個軌跡 T_i 由獎勵模型 F_Reward 分配一個獎勵 r_i,該模型綜合考慮安全性、舒適性、效率和經濟性等因素:
F_Reward = α_safety C_safety + α_comfort C_comfort + α_efficiency C_efficiency
+ α_economic C_economic (3)
其中 α_safety ,α_comfort ,α_efficiency, α_economic 是確定每個因素相對重要性的權重。
快速路徑損失函數。采用 [24, 61] 中的損失函數設計,它由規劃損失 L_plan、輔助 3D 檢測損失 L_det 和地圖分割損失 L_seg 組成。總損失函數為:
L_fast = λ_plan L_plan + λ_det L_det + λ_seg L_seg (4)
其中 λ_plan、λ_det 和 λ_seg 是平衡輔助損失的權重。
慢速路徑
在復雜場景中,準確解釋環境因素對于安全決策至關重要。慢速路徑模擬類似人類的推理來推斷背景并預測未來行動,類似于人類駕駛員。
面向規劃的 QA
提出一系列面向決策的問答 (QA) 任務,以促進自動駕駛系統中的類人推理。如圖說明 QA 問題的類型。
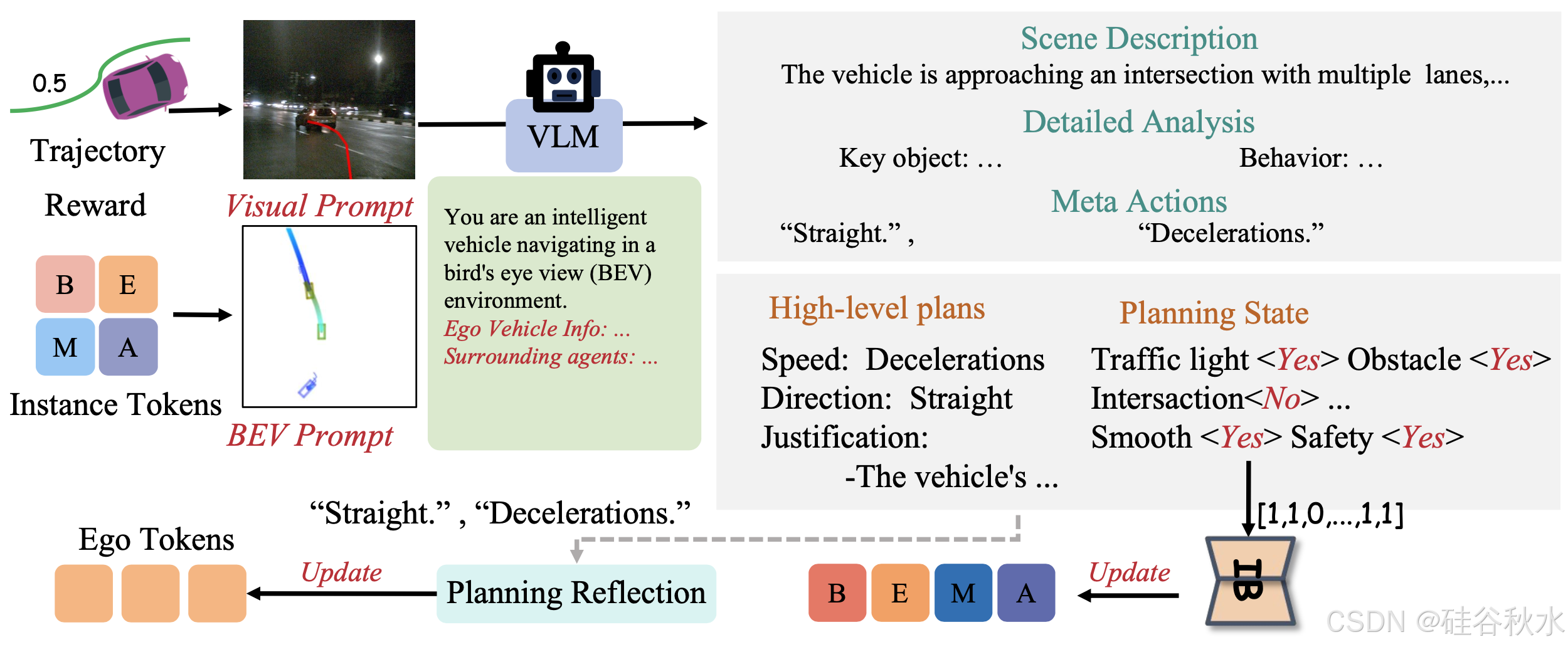
本研究解決通過提高系統對類人駕駛行為的理解和復制來增強自動駕駛系統穩健性的五個關鍵方面:
場景分析。這涉及評估環境因素,例如天氣條件(例如晴天、雨天、下雪天)、一天中的時間(早上、下午、傍晚、夜晚)、交通密度(輕或重)和道路狀況(潮濕、干燥、結冰)。徹底分析這些因素使系統能夠解釋更廣泛的背景,從而影響速度和機動選擇等關鍵決策。
交通標志識別。這項任務側重于識別和解釋各種交通標志,包括交通信號燈、停車標志、讓行標志和限速標志。準確的標志識別,對于法規遵從性和安全性至關重要,是類人駕駛行為的基本組成部分。
關鍵目標識別和行為分析。這涉及識別和分析環境中的關鍵目標,例如車輛、行人、騎自行車者和動物,并根據過去的動作預測它們未來的行為。準確的識別和行為預測對于預測危險和實現主動決策以避免碰撞至關重要。
規劃狀態。與規劃相關的狀態表示為 K 維二進制向量,描述與決策相關的當前環境背景。這種結構化表示通過允許系統優先考慮行動、優化路線和改進決策來支持高級規劃。
高級規劃和論證。此方面涉及制定路線選擇、車道變更和合并機動等動作的高級規劃,同時考慮長期目標和約束。通過論證這些決策,系統確保其動作既安全又高效,與總體駕駛目標保持一致。這一組件對于在自主系統中復制類似人類的決策至關重要。
數據收集和自動標記
為了生成這些問答 (QA) 任務,利用快速路徑的輸出(包括 3D 目標檢測框和跟蹤軌跡)進行自動注釋。此外,利用大型視覺語言模型 (LVLM)(例如 Qwen)來生成與觀察場景及其元素緊密相關的描述性 QA。受駕駛決策的認知需求的啟發,引入兩種類型的提示來增強 QA 生成:視覺提示,有助于以類似于人類感知的方式解釋視覺提示和場景元素;BEV 提示,提供自上而下的環境視圖,以改善對空間關系和智體交互的理解。
為了解決 VLM 輸出中的多變性(可能包含無關或不相關的信息),采用受自然語言處理 (NLP) 中少樣本學習啟發的正則化策略。但是,與一般的 NLP 應用不同,自動駕駛需要高可靠性和一致性。因此,通過簡化過程改進 VLM 輸出,確保對快速路徑規劃器的反饋保持簡潔有效,最終支持生成新的、準確的軌跡。
慢速通道流水線可以公式化如下:
P_t, A_t = Φ[E(V^front_t), E(B_t)] (5)
將軌跡視覺提示融入慢速路徑規劃中。具體來說,將快速路徑規劃器生成的航點投射到前視攝像頭上,從而創建軌跡的視覺表示。這種規劃路徑的視覺近似,有助于類似人類的推理過程,從而實現更直觀的決策評估和修改,從而產生更可靠、更有效的高級規劃。
基于車輛的 BEV 坐標系,BEV 提示清晰地描述自車輛與周圍智體之間的空間關系和動態交互。
提出一個高級規劃編碼器,記為 E_A,它將 VLM 中的高級決策轉換為元動作特征 A_t。由于高級規劃可以分解為結構化的元動作集,編碼器 E_A 使用一組可學習的嵌入 e_A 將這些元-動作與它們對應的元-動作特征進行一對一映射,N_A 表示元動作的數量。
傳統的 LLM 方法主要依賴于自回歸學習。相比之下,該方法將自回歸學習與最大似然估計 (MLE) 損失相結合以調整 VLM。為了提高復雜場景中的預測準確性,引入獎勵引導的回歸損失。與依賴人工反饋進行強化學習微調的 InstructGPT [37] 不同,系統利用自動生成的指導。目標是復制規劃狀態和高級規劃,這些規劃可在任務設置中直接訪問。因此,將真值定義為 [Y_P_t , Y_A_t]。
由于基于 GPT 模型通常在 token 級應用監督,而整個序列對于回歸來說都是有意義的,因此將近端策略優化 (PPO) [43] 與掩碼結合起來,以更有效地應用監督。調整損失表示為 L_rvlm,在策略梯度框架內計算為獎勵:
L_rvlm = Reward(s1:T_i ) · Φ(sT_i |s^1:T_i?1) (6)
其中 sT_i 表示時間步 T_i 處的預測 token,Reward(s^1:T_i ) 是 Fast Pathway 中航點預測的獎勵函數。最終訓練損失結合了標準語言損失和獎勵引導損失:
L_slow = λ_MLE LMLE + λ_rvlm L_rvlm (7)
快慢融合自動駕駛
如圖所示自適應反饋機制處理雙重輸入:軌跡-生成的圖像,和從實例 tokens 派生的 BEV 提示,兩者都輸入到 VLM 中。
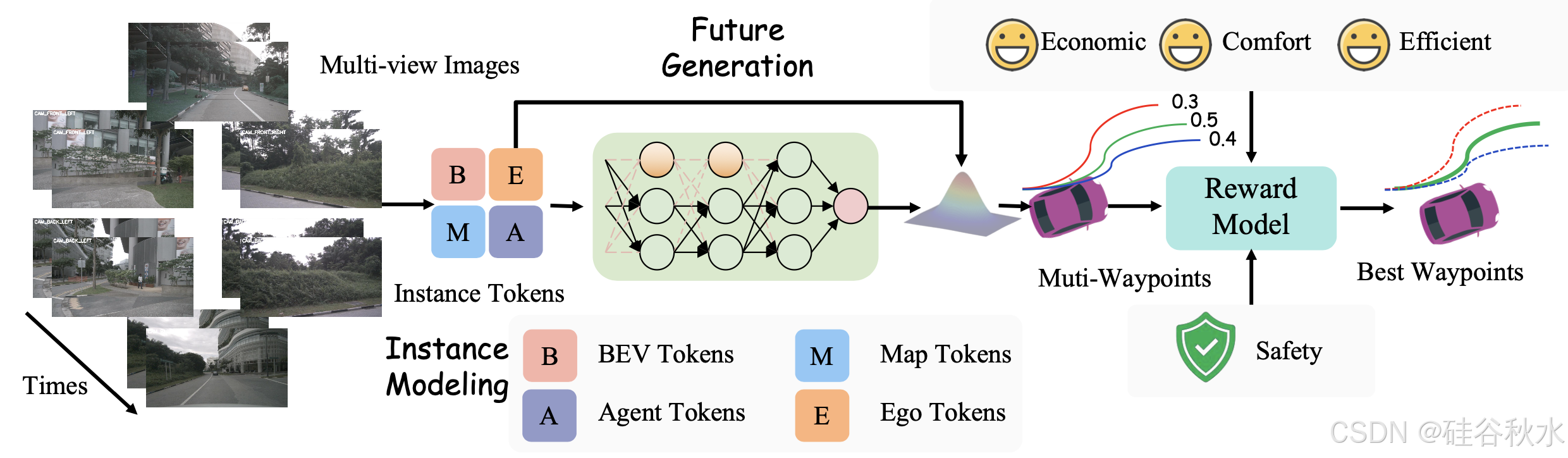
不確定性估計和決策機制
為了有效地駕馭動態和不可預測的環境,估計航點預測中的不確定性至關重要,因為它允許系統根據預測可靠性調整其決策。為了處理航點預測中的異常值和模型不確定性,采用拉普拉斯分布:
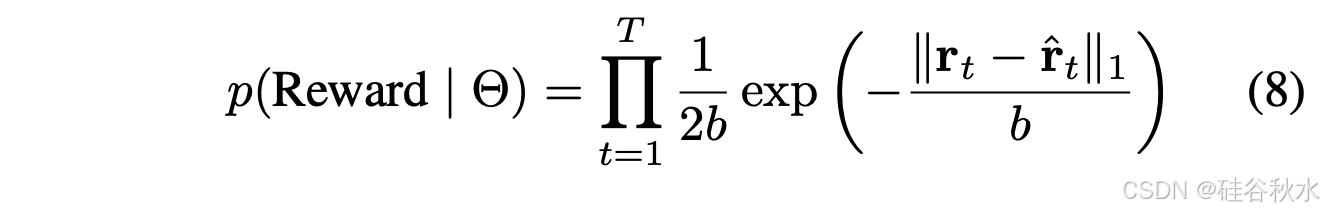
該分布的重尾使其對異常值具有魯棒性,這在動態駕駛環境中非常有利。
拉普拉斯分布的重尾和尖峰使其對異常值具有魯棒性,并且可有效估計動態駕駛環境中的不確定性。根據獎勵(R)和估計的不確定性,系統選擇用于瞬時導航的快速路徑(當獎勵超過閾值且不確定性較低時),或用于詳細分析的慢速路徑。
信息瓶頸反饋
駕駛環境通常包含大量無關或嘈雜的信息,這些信息對規劃沒有幫助。為了解決這個問題,應用信息瓶頸原理[18]來僅提取與決策相關的信息。這種方法可確保模型優先考慮導航的關鍵特征,從而有效地最大限度地減少無關數據的影響。
為了將實例-覺察特征 z 與 y_t 對齊,用 MLP f_MLP 將 z 映射到一維向量 y_i。知識蒸餾過程最小化以下目標:

其中 q_d(y_t|y_i) 是給定 y_i 的 VLM 派生向量 y_t 概率分布,q_e(y_i | z_current) 對當前狀態的實例-覺察特征進行編碼。這里,p(z) 是 z 上的先驗分布,β 是正則化參數。
反饋融合機制
慢速路徑由獎勵信號和不確定性激活,可以選擇性地深入分析基本 VLM 派生特征。集成通過可學習嵌入 e_A 和自我 token e_ego 之間的交叉注意進行,其中 e_ego 將 e_A 作為 K-V 對進行查詢。這歌捕獲上下文依賴關系,并將生成的融合狀態輸入到快速路徑中進行軌跡規劃,模仿人類在復雜駕駛場景中的決策。
實驗設置如下。
對 FASIONAD 的評估涵蓋開環和閉環性能指標。對于開環評估,用 nuScenes 數據集,該數據集提供來自城市駕駛場景的全面注釋數據。此評估側重于通過 L2 距離和碰撞率指標來衡量策略與專家演示的相似性。由于這些開環測量的計算效率和結果一致性,在消融研究中優先考慮它們。閉環評估采用 CARLA Closed-loop Town05 Short Benchmark,其特點是具有挑戰性的場景,包括狹窄的街道、密集的交通和頻繁的交叉路口。主要性能指標是駕駛分數 (DS),包括路線完成度 (RC)-違規分數的乘積和路線完成度本身。為了確保與現有方法的公平比較,圍繞基于學習的策略實施基于規則的包裹器,遵循基準評估中的標準做法。其有助于最大限度地減少測試期間的違規行為。
訓練過程分為三個階段:(1)訓練快速路徑以生成合理的軌跡和強大的獎勵函數,(2)微調視覺語言模型(VLM)以輸出結構化向量表示,以及(3)聯合訓練快速和慢速路徑以協調反饋并提高復雜場景下的性能。
第一階段,重點學習穩健的軌跡生成,并設計評估安全性、效率和舒適度的獎勵模型。
第二階段,專注于微調視覺語言模型 (VLM) 以生成結構化矢量表示,增強慢速通路為決策提供高質量反饋的能力。
最后一個階段,重點是將慢速路徑的基于推理反饋整合到快速路徑的實時軌跡生成中。此過程確保系統將快速路徑的效率與慢速路徑的上下文推理和適應性相結合,協調它們的輸出以提高整體性能。
快速路徑的實現細節如下。
采用 ResNet50[20] 作為主干網絡來提取圖像特征。將分辨率為 640 × 360 的圖像作為輸入,并使用 200 × 200 的 BEV 表示來感知周圍場景。為了公平比較,基本上使用與 VAD-tiny[24] 相同的超參。將 BEV token、地圖 token 和智體 token 的數量分別固定為 100 × 100,100 和 300。每個地圖 token 是包含 20 個點的 tokens,以表示 BEV 空間中的地圖點。將每個 BEV、點、智體、自我和實例 tokens 的隱藏維度設置為 256。在獎勵函數中設置 α_safety = 2、α_comfort = α_efficiency = α_economic = 1。
對于訓練,將損失平衡因子設置為 1,并使用 AdamW[35] 優化器和余弦學習率調度器[34]。將初始學習率設置為 2 × 10-4,權重衰減為 0.01。默認情況下,用 8 個 NVIDIA Tesla A100 GPU 對 FASIONAD 進行 30 個 epoch 的訓練,總批次大小為 8。
![【免費】YOLO[笑容]目標檢測全過程(yolo環境配置+labelimg數據集標注+目標檢測訓練測試)](http://pic.xiahunao.cn/【免費】YOLO[笑容]目標檢測全過程(yolo環境配置+labelimg數據集標注+目標檢測訓練測試))


















